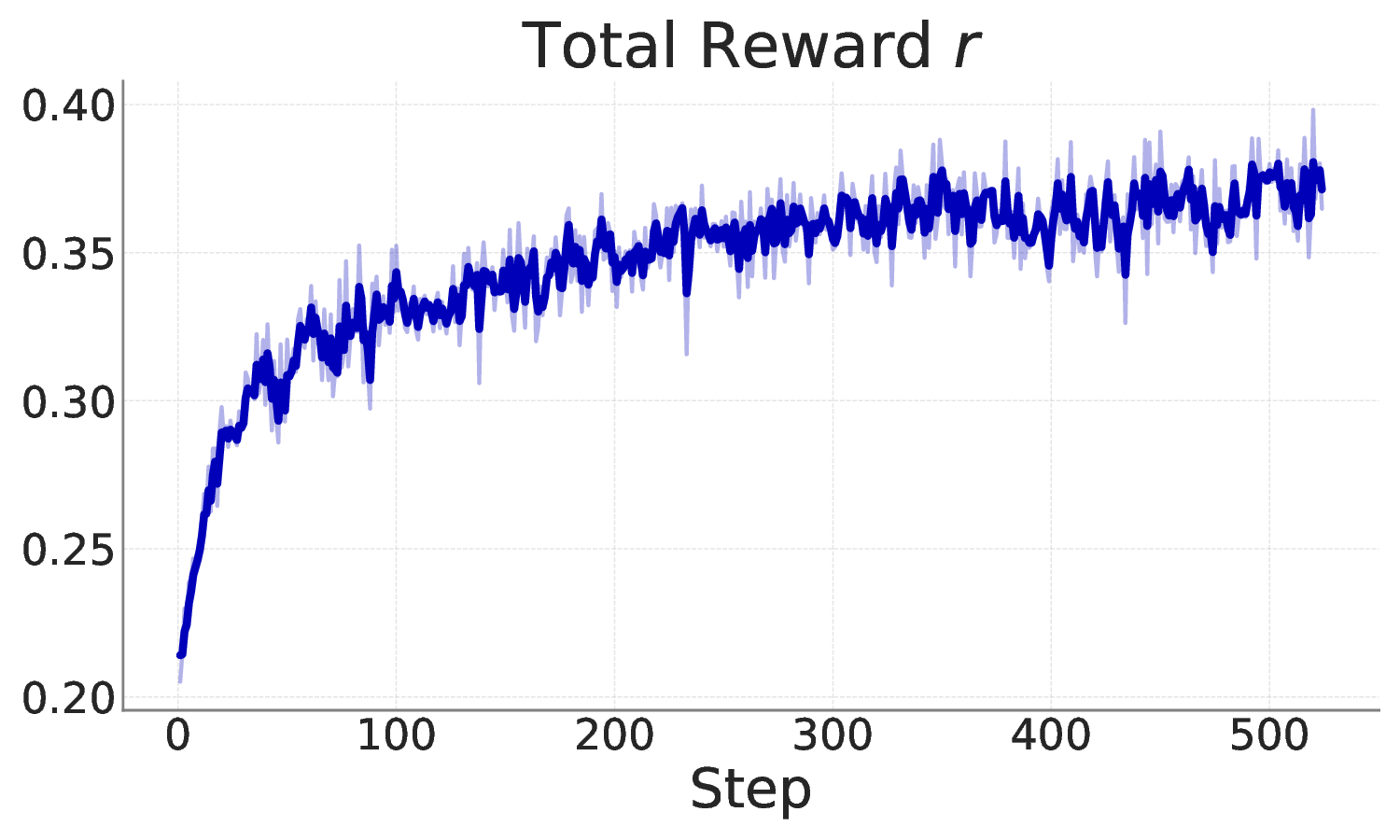
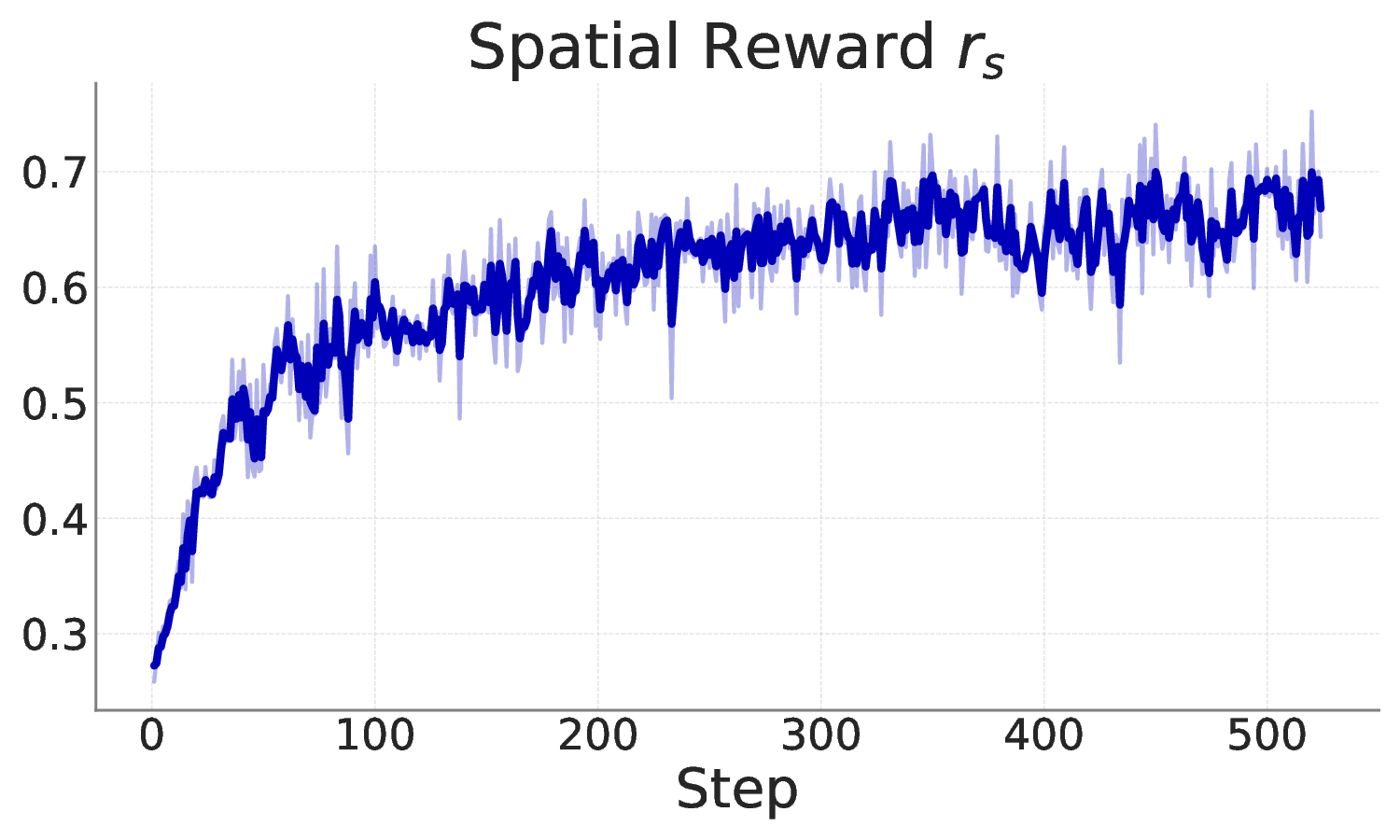
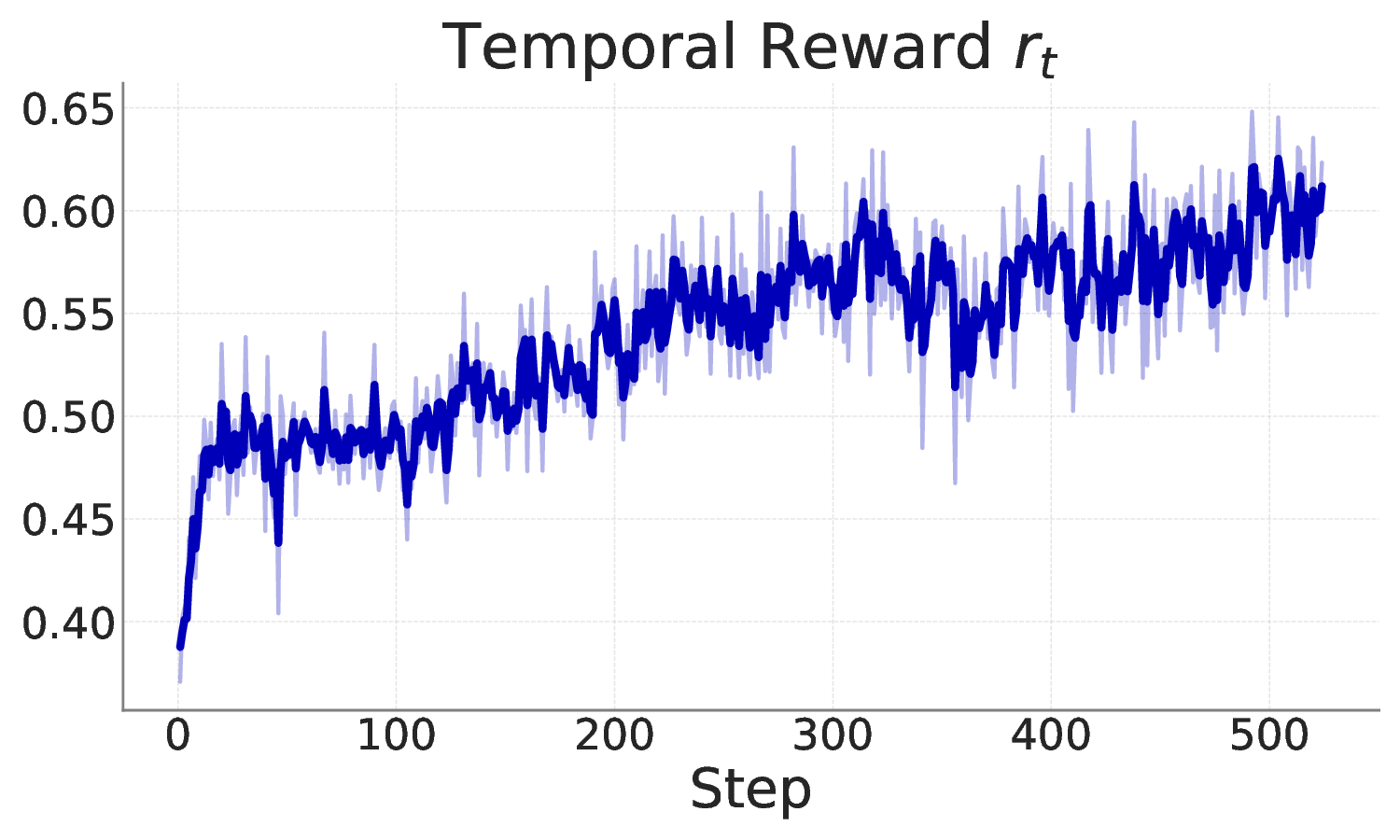
Reasoning-centric video object segmentation is an inherently complex task: the query often refers to dynamics, causality, and temporal interactions, rather than static appearances. Yet existing solutions generally collapse these factors into simplified reasoning with latent embeddings, rendering the reasoning chain opaque and essentially intractable. We therefore adopt an explicit decomposition perspective and introduce ReVSeg, which executes reasoning as sequential decisions in the native interface of pretrained vision language models (VLMs). Rather than folding all reasoning into a single-step prediction, ReVSeg executes three explicit operations -- semantics interpretation, temporal evidence selection, and spatial grounding -- aligning pretrained capabilities. We further employ reinforcement learning to optimize the multi-step reasoning chain, enabling the model to self-refine its decision quality from outcome-driven signals. Experimental results demonstrate that ReVSeg attains state-of-the-art performances on standard video object segmentation benchmarks and yields interpretable reasoning trajectories. Project page is available at https://clementine24.github.io/ReVSeg/ .
💡 Deep Analysis
📄 Full Content
ReVSeg: Incentivizing the Reasoning Chain for Video Segmentation
with Reinforcement Learning
Yifan Li1,2
Yingda Yin3*†
Lingting Zhu3†
Weikai Chen3
Shengju Qian3
Xin Wang3
Yanwei Fu1,2*
1Fudan University
2Shanghai Innovation Institute
3LIGHTSPEED
64.8
41.0
7.6
8.1
80.7
63.0
5.3
4.4
Sure, it is .
[USER]: While driving and turning right at an intersection, what moving thing should I
be most wary of to avoid a collision?
…the most likely candidate would be a pedestrian crossing the street or someone walking along the
sidewalk, …drivers need to be cautious of pedestrians when turning right at intersections… Object description: the pedestrian standing near the Steelers store
+23.8%
+ >55%
In-domain Test
Out-of-domain Test
VideoLISA
Ours
Base Model
Base Model + RL
Our Model
Our Model + RL
+17.7%
+ >75%
Ablation Study
Base Model
Base Model + RL
Our Model
Our Model + RL
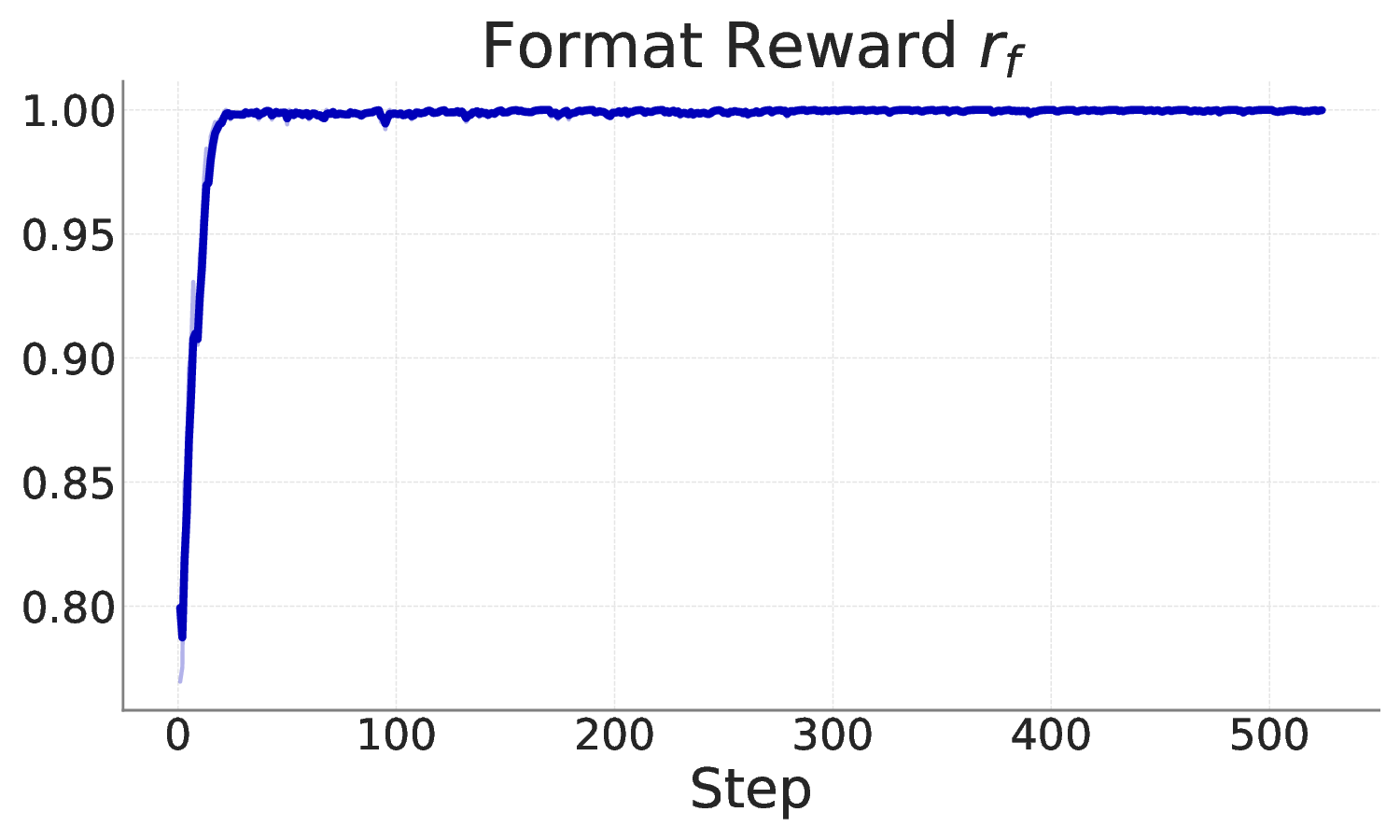
Figure 1. (Left) Through an explicit reasoning chain, our ReVSeg tackles reasoning-focused video object segmentation and accurately
grounds objects referenced by complex, abstract real-world queries. (Right) While the base model and its RL variant struggle on the
task, our method achieves strong performance, with RL post-training yielding a further substantial boost. We report the J &F metric on
Ref-DAVIS17 (in-domain) and ReasonVOS (out-of-domain) datasets in the chart.
Abstract
Reasoning-centric video object segmentation is an inher-
ently complex task: the query often refers to dynamics,
causality, and temporal interactions, rather than static ap-
pearances. Yet existing solutions generally collapse these
factors into simplified reasoning with latent embeddings,
rendering the reasoning chain opaque and essentially in-
tractable.
We therefore adopt an explicit decomposition
perspective and introduce ReVSeg, which executes reason-
ing as sequential decisions in the native interface of pre-
trained vision language models (VLMs). Rather than fold-
ing all reasoning into a single-step prediction, ReVSeg ex-
ecutes three explicit operations – semantics interpretation,
temporal evidence selection, and spatial grounding – align-
ing pretrained capabilities. We further employ reinforce-
ment learning to optimize the multi-step reasoning chain,
enabling the model to self-refine its decision quality from
outcome-driven signals. Experimental results demonstrate
that ReVSeg attains state-of-the-art performances on stan-
dard video object segmentation benchmarks and yields in-
* Corresponding authors.
† Project leads.
terpretable reasoning trajectories. Project Page.
1. Introduction
Human interpretation of videos relies on recognizing how
events unfold, why actions occur, and when key mo-
ments matter. Traditional video object segmentation (VOS)
methods, however, primarily exploit appearance-only or
category-level cues [3, 29, 40, 45, 46]. Reasoning VOS
elevates the task: the model must parse abstract, under-
specified instructions, draw on commonsense and causal
reasoning, integrate temporal dynamics with semantic
knowledge to identify the target (e.g., “the runner most
likely to win” or “the object causing the accident”).
While recent vision-language models (VLMs) have
shown promising capabilities for reasoning segmenta-
tion [2, 16, 50], current systems predominantly model rea-
soning VOS as a single-step latent prediction: inserting a
special token (e.g., ) and decoding it directly into
mask outputs [2, 8, 20, 35, 41, 42, 50, 53]. This collapses
the multi-step reasoning process — interpreting abstract
instructions, identifying candidates, and spatial-temporal
1
arXiv:2512.02835v1 [cs.CV] 2 Dec 2025
grounding — into a simple conclusion as well as opaque
embeddings. Such compactness comes at a great cost: inter-
pretability is bounded, distribution shift arises from forcing
VLMs into non-native output spaces, and substantial data is
required for supervised fine-tuning.
These challenges reflect a deep insight: effective video
reasoning unfolds through a sequence of deliberate choices,
not a single latent inference. A model must determine where
to focus, when to attend, and which entity the query refers
to.
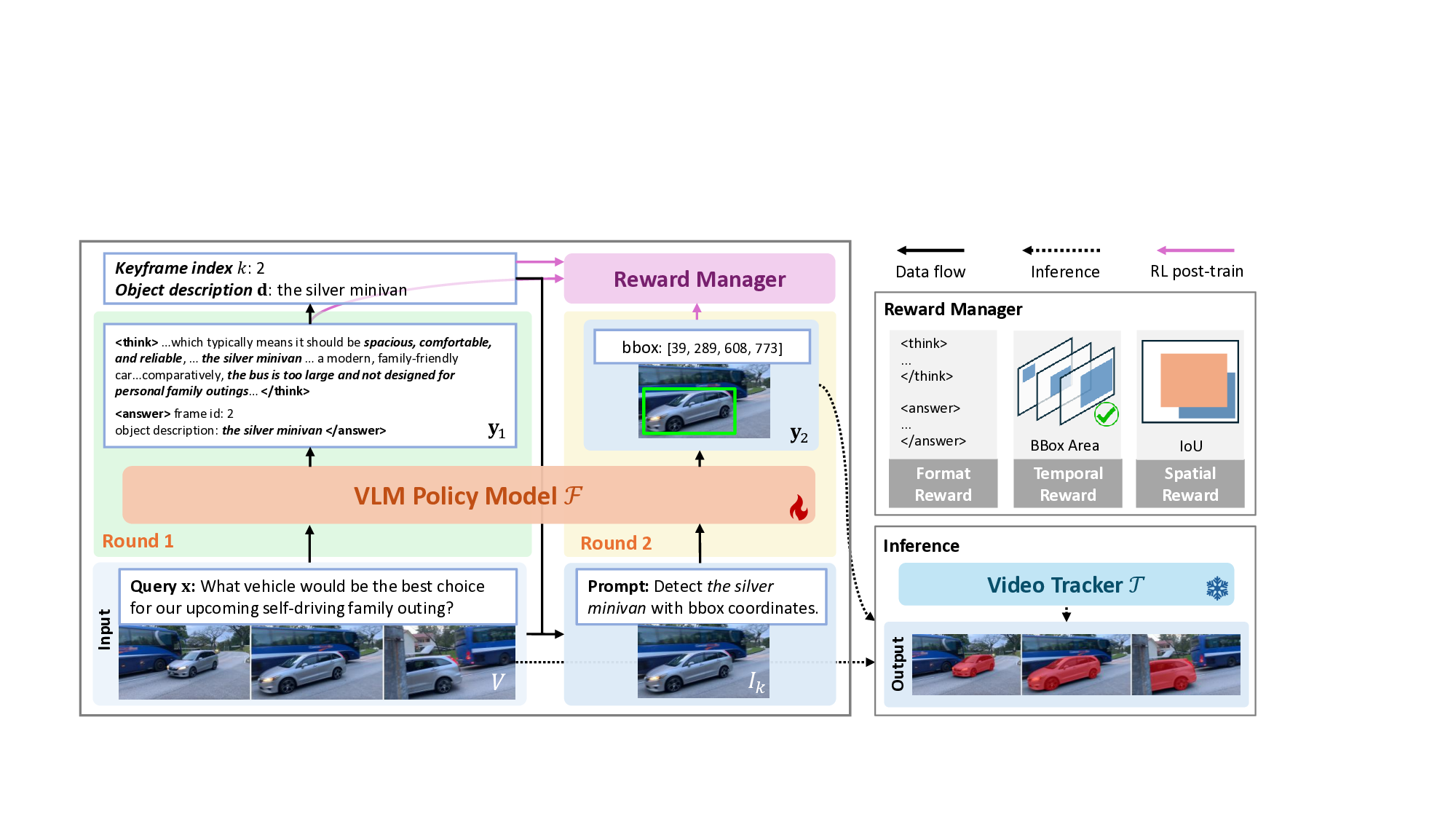
Motivated by this principle, we introduce ReVSeg,
which eliminates the use of latent segmentation tokens and
instead reformulates reasoning video segmentation as an ex-
plicit sequence of reasoning chain. In particular, ReVSeg
decomposes reasoning VOS into three actions aligned with
VLM-native capabilities: video understanding (interpreting
the query and assessing scene dynamics), temporal ground-
ing (identifying key frames or intervals pertinent to the
query), and spatial grounding (localizing the target objects
within selected frames). ReVSeg orchestrates these primi-
tives through multi-turn actions with a single VLM, ensur-
ing the semantic context established in early reasoning steps
seamlessly propagates to downstream localization. Execut-
ing reasoning through these native interfaces preserves pre-
training alig