Recent advances in 3D scene-language understanding have leveraged Large Language Models (LLMs) for 3D reasoning by transferring their general reasoning ability to 3D multi-modal contexts. However, existing methods typically adopt standard decoders from language modeling, which rely on a causal attention mask. This design introduces two fundamental conflicts in 3D scene understanding: sequential bias among order-agnostic 3D objects and restricted object-instruction attention, hindering task-specific reasoning. To overcome these limitations, we propose 3D Spatial Language Instruction Mask (3D-SLIM), an effective masking strategy that replaces the causal mask with an adaptive attention mask tailored to the spatial structure of 3D scenes. Our 3D-SLIM introduces two key components: a Geometry-adaptive Mask that constrains attention based on spatial density rather than token order, and an Instruction-aware Mask that enables object tokens to directly access instruction context. This design allows the model to process objects based on their spatial relationships while being guided by the user's task. 3D-SLIM is simple, requires no architectural modifications, and adds no extra parameters, yet it yields substantial performance improvements across diverse 3D scene-language tasks. Extensive experiments across multiple benchmarks and LLM baselines validate its effectiveness and underscore the critical role of decoder design in 3D multi-modal reasoning.
3D scene-language understanding aims to jointly interpret 3D environments and natural language, serving as a fundamental basis for multi-modal reasoning in applications such as robotic navigation and embodied agents. Traditionally, 3D scene-language tasks have relied on specialized, taskspecific models (e.g., grounding, captioning, and questionanswering). With the emergence of Large Language Mod- els (LLMs), research has moved toward unified frameworks capable of handling multiple tasks within a single model.
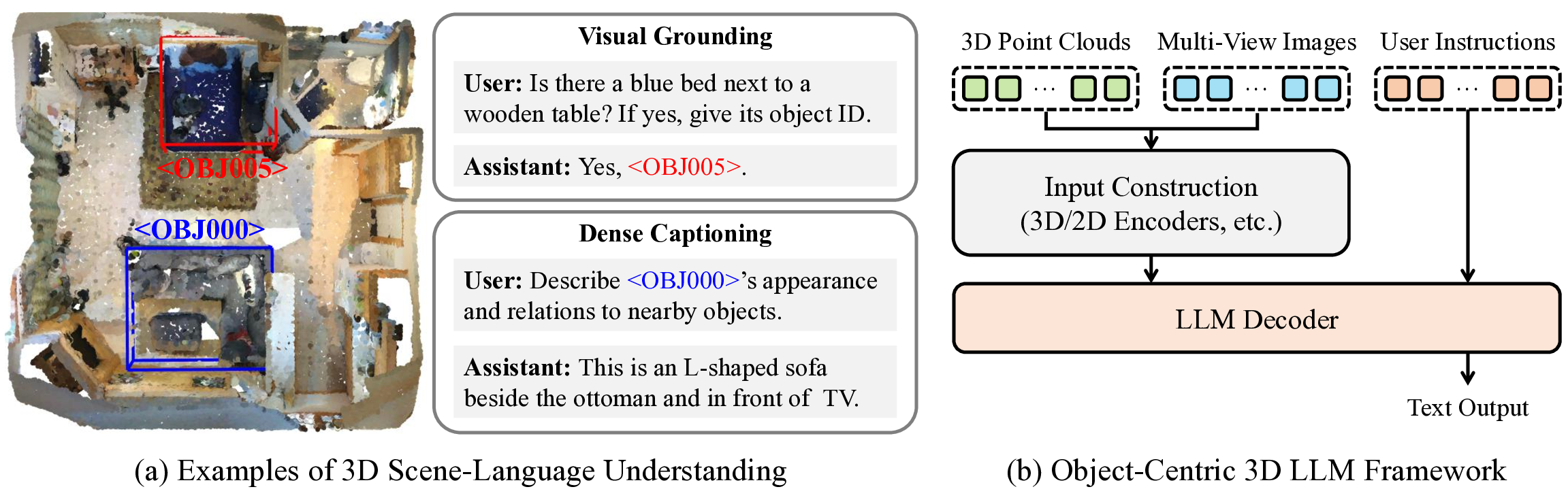
Recently, Chat-Scene [13] introduced an Object-Centric 3D LLM framework that decomposes an input 3D scene into a set of object proposals using a pretrained detector [21]. Each object is represented by an identifier token and its instance-level 3D and 2D features, enabling object-centric reasoning via LLMs [10,35]. Following this paradigm, Inst3D-LMM [30] incorporates 2D-3D feature interactions into object-level representations, and 3DGraphLLM [31] further models semantic relationships among objects. These works have achieved promising performance with compact yet expressive scene representations.
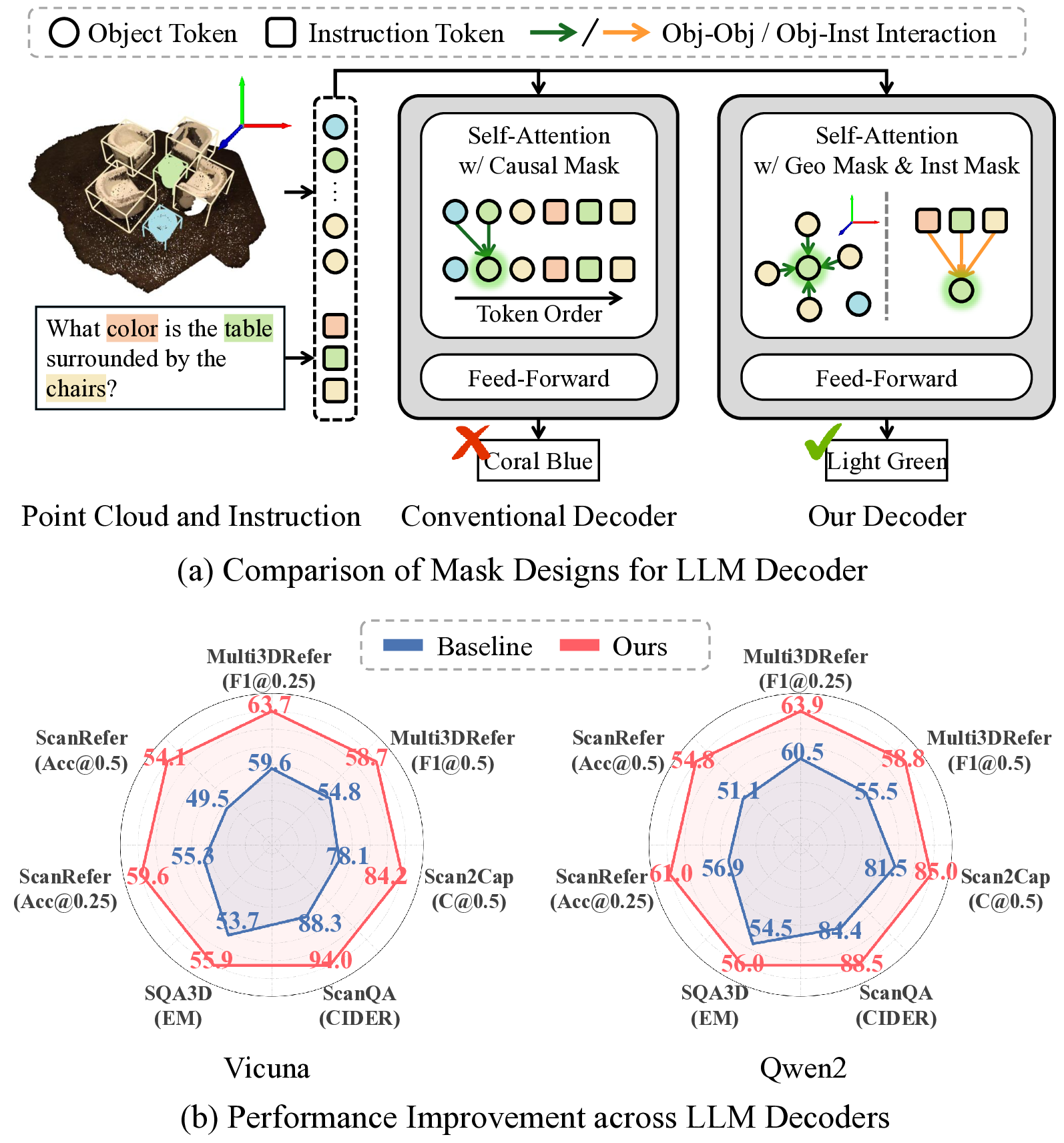
However, this significant progress has been largely confined to input representation, leaving the decoder architecture relatively underexplored. Current approaches borrow decoders directly from language modeling [10,35], neglecting their inherent mismatch with 3D data. We identify two fundamental conflicts arising from the standard causal mask. First, it imposes a sequential dependency on object tokens, which contradicts the order-agnostic nature of 3D scenes. This forces the model to learn spurious order-dependent correlations, although 3D scenes are intrinsically organized by spatial relationships rather than input order. Second, the causal mask limits essential interaction between object tokens and the instruction tokens, compelling the model to process the entire 3D scene before integrating the user’s instruction, leading to inefficient reasoning pathways.
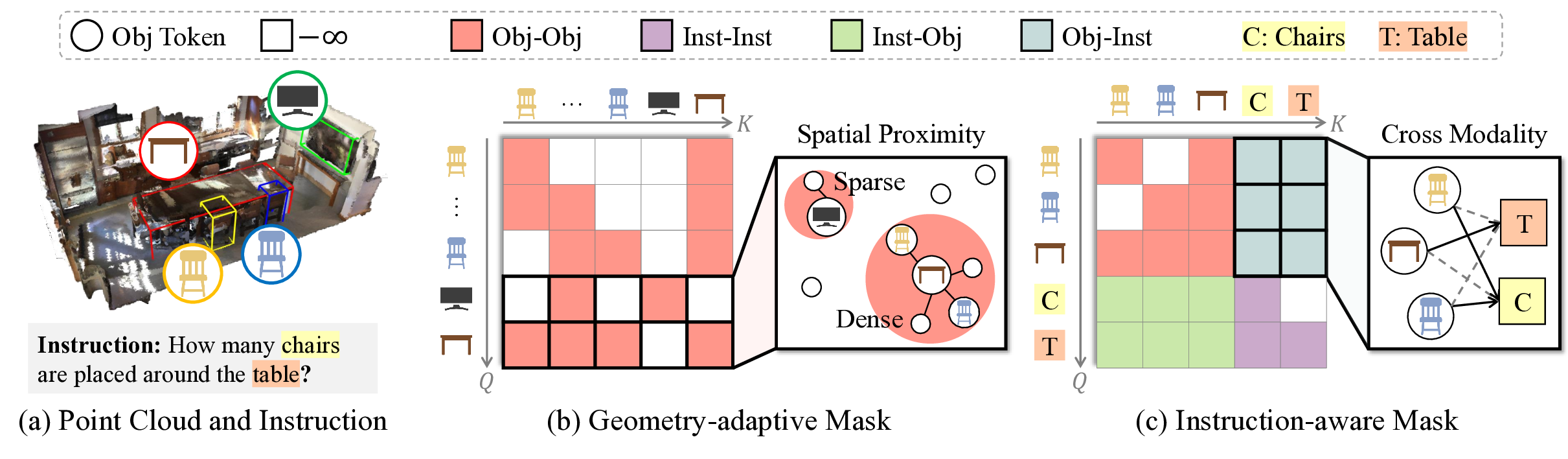
To overcome these limitations, we propose 3D Spatial Language Instruction Mask (3D-SLIM), a masking strategy that replaces the causal mask with an adaptive attention mask tailored to the spatial structure of 3D scenes, as illustrated in Fig. 1. We first introduce a Geometry-adaptive Mask (Geo Mask), which models local object relationships by adaptively determining the attention scope based on each object’s spatial density. This mask dynamically adjusts the attention range, permitting more accessible neighbors in object-dense areas to capture rich local context while restricting them in sparse areas to prevent attending to irrelevant, distant objects. Subsequently, we introduce an Instruction-aware Mask (Inst Mask) that enables direct attention from object tokens to the instruction tokens. This modification allows the model to leverage the instruction context during processing each object, thereby decoding the scene into an effective, task-adapted representation.
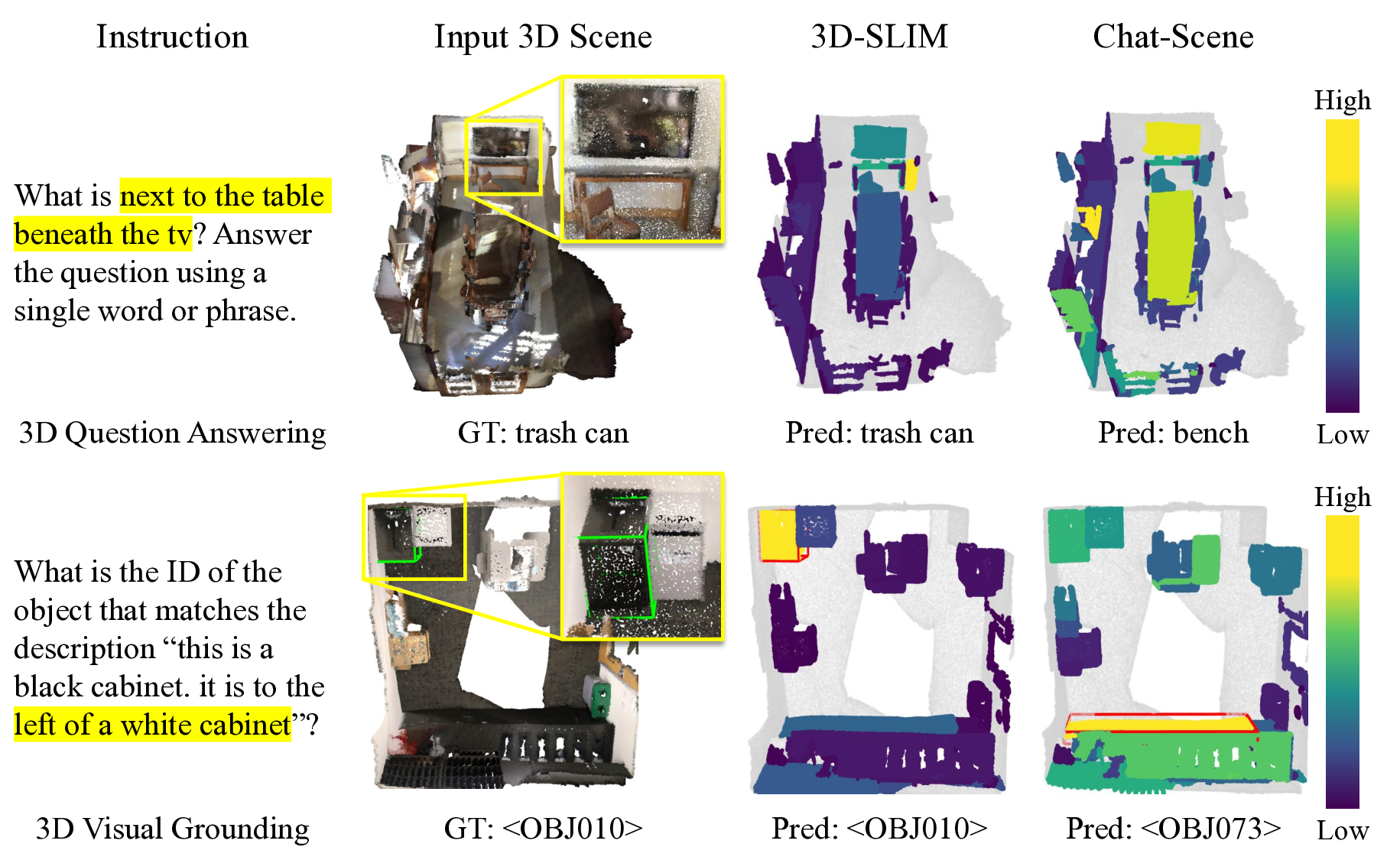
3D-SLIM is a simple yet highly effective masking strategy that directly substitutes the standard causal mask. This design enables seamless integration into various LLM decoders without any architectural modifications or additional parameters. The generality and effectiveness of our method have been validated through extensive experiments across diverse baselines on multiple 3D scene-language tasks, as shown in Fig. 1. We believe this work provides new insights into the underlying importance of decoder design for advancing 3D scene-language understanding.
Our key contribution can be summarized as follows: • We identify two major issues in the conventional LLM decoders: spurious order-dependent correlations and limited interaction between instruction and object tokens.
• We propose a 3D Spatial Language Instruction Mask (3D-SLIM), an efficient and easily integrable solution to address both issues.
• We demonstrate the effectiveness and high applicability of 3D-SLIM across various baselines and multiple 3D scene-language tasks.
3D Scene-Language Understanding. 3D scene understanding has emerged as a key computer vision task, enabling models to interpret complex 3D environments and solve diverse spatial reasoning problems based on user instructions. This field involves fundamental 3D vision-language tasks, such as 3D visual grounding [4,32], 3D dense captioning [7], and 3D question answering [2,18], which require a comprehensive understanding of spatial structures and semantic relationships within 3D scenes. Early approaches [5,17,29] tackled these challenges with task-specific models, while subsequent studies [3,15,37] proposed unified frameworks that jointly handle multiple tasks. However, these approaches still rely on task-specific heads, limiting their flexibility for more generalized user instructions.
Large Language Models for 3D Scene Understanding. Motivated by the powerful generalization capabilities of Large Language Models (LLMs) [1,10,35], numerous studies have investigated ex
This content is AI-processed based on open access ArXiv data.