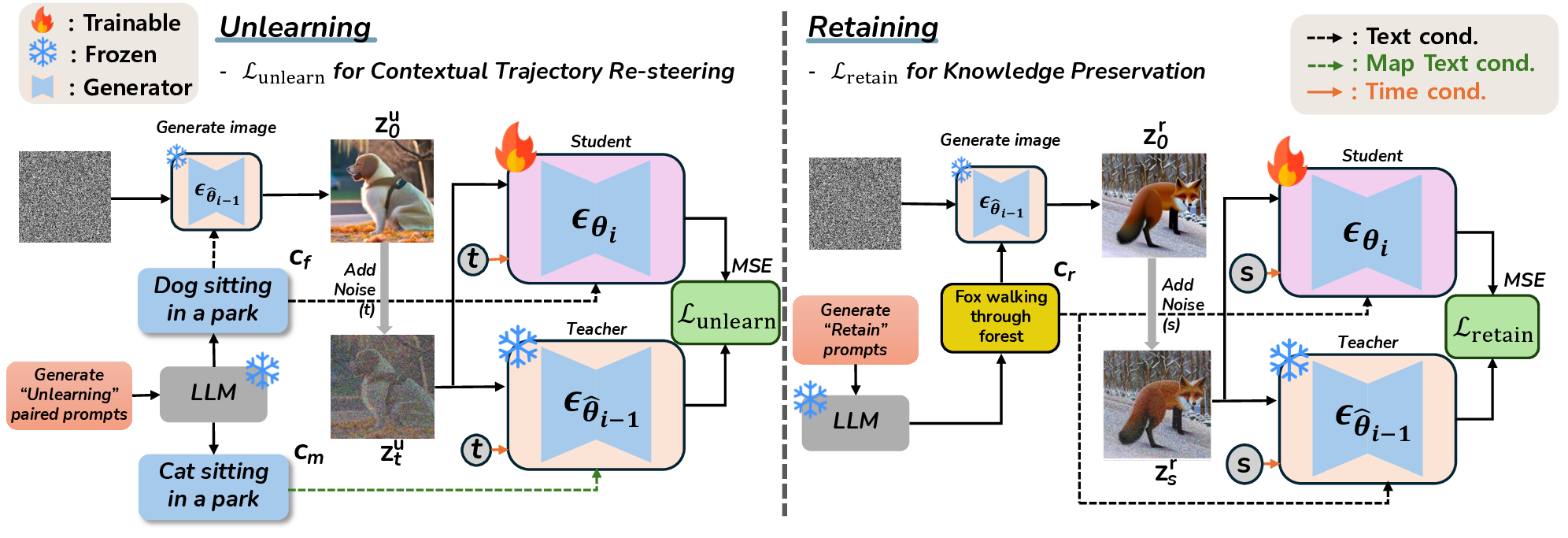
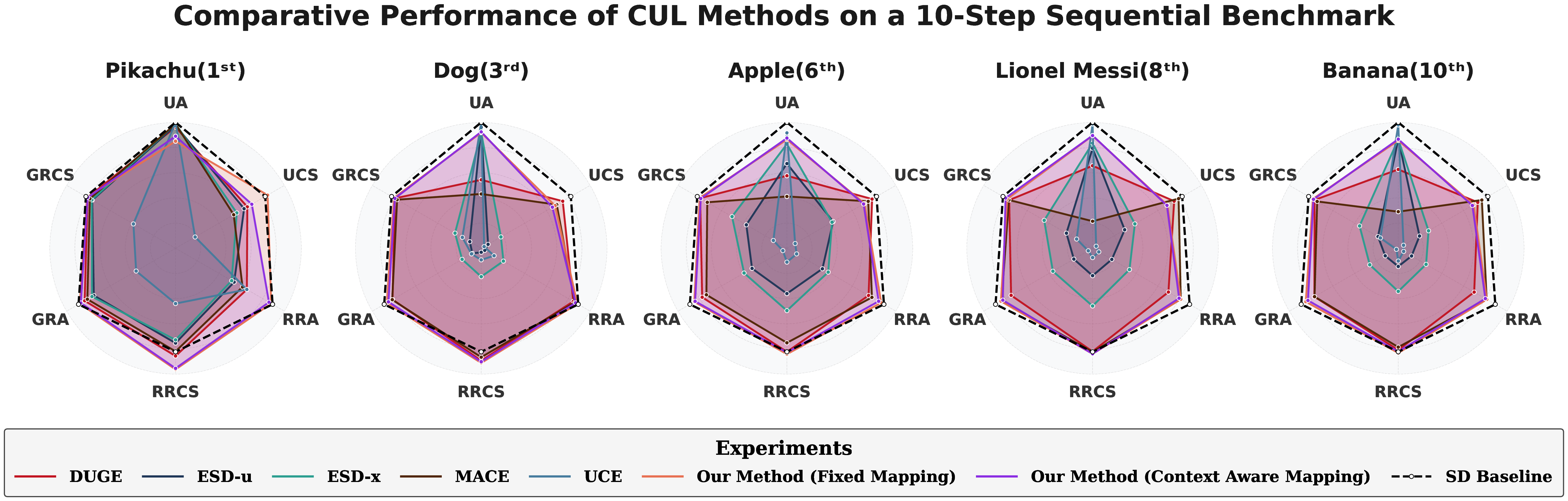
Title: Distill, Forget, Repeat: A Framework for Continual Unlearning in Text-to-Image Diffusion Models
ArXiv ID: 2512.02657
Date: 2025-12-02
Authors: ** Naveen George¹²,†, Naoki Murata², Yuhta Takida², Konda Reddy Mopuri¹, Yuki Mitsufuji²³ ¹ Indian Institute of Technology Hyderabad ² Sony AI ³ Sony Group Corporation **
📝 Abstract
The recent rapid growth of visual generative models trained on vast web-scale datasets has created significant tension with data privacy regulations and copyright laws, such as GDPR's ``Right to be Forgotten.'' This necessitates machine unlearning (MU) to remove specific concepts without the prohibitive cost of retraining. However, existing MU techniques are fundamentally ill-equipped for real-world scenarios where deletion requests arrive sequentially, a setting known as continual unlearning (CUL). Naively applying one-shot methods in a continual setting triggers a stability crisis, leading to a cascade of degradation characterized by retention collapse, compounding collateral damage to related concepts, and a sharp decline in generative quality. To address this critical challenge, we introduce a novel generative distillation based continual unlearning framework that ensures targeted and stable unlearning under sequences of deletion requests. By reframing each unlearning step as a multi-objective, teacher-student distillation process, the framework leverages principles from continual learning to maintain model integrity. Experiments on a 10-step sequential benchmark demonstrate that our method unlearns forget concepts with better fidelity and achieves this without significant interference to the performance on retain concepts or the overall image quality, substantially outperforming baselines. This framework provides a viable pathway for the responsible deployment and maintenance of large-scale generative models, enabling industries to comply with ongoing data removal requests in a practical and effective manner.
💡 Deep Analysis
📄 Full Content
Distill, Forget, Repeat: A Framework for Continual Unlearning
in Text-to-Image Diffusion Models
Naveen George1,2,†, Naoki Murata2, Yuhta Takida2, Konda Reddy Mopuri1, Yuki Mitsufuji2,3
1Indian Institute of Technology Hyderabad
2Sony AI
3Sony Group Corporation
ai23mtech12001@iith.ac.in, naoki.murata@sony.com
ESD-x
MACE
DUGE
Our
Method
Pikachu
Van Gogh Style
Spiderman Lionel Messi
Banana
“Pikachu paddles a
kayak downstream”
“A bakery counter in
Van Gogh Style”
“Spiderman stands
in a city alley”
“Lionel Messi greets
cheering supporters”
“A banana beside a
fish tank”
“Squirtle Figurine
On Office Desk”
“Comic book style
drawing on easel”
“Iron man figure on
desk.”
“Cristiano Ronaldo
arrives at stadium”
“Pineapple centerpiece
on dining table”
SD v1.5
Unlearning Performance in CUL
Pikachu
Van Gogh Style
Spiderman
Lionel Messi
Banana
Retaining Performance in CUL
Figure 1. Qualitative comparison of our method (bottom row) against SOTA baselines on 10 sequential unlearning steps. This figure
highlights the critical failure modes of existing methods in a continual setting. Baselines like ESD-x [9] and MACE [19] suffer from
catastrophic “retention collapse”, where generative quality completely breaks down on retained concepts (right panel). Other methods
like DUGE [32] avoid total collapse but still exhibit severe quality degradation and poor unlearning in later stages. In contrast, our
method demonstrates a superior ability to both effectively unlearn target concepts (left panel) and preserve general knowledge (right
panel), maintaining a good generative quality compared to the original SD model.
Abstract
The recent rapid growth of visual generative models trained
on vast web-scale datasets has created significant tension
with data privacy regulations and copyright laws, such as
GDPR’s “Right to be Forgotten.” This necessitates machine
unlearning (MU) to remove specific concepts without the
prohibitive cost of retraining. However, existing MU tech-
niques are fundamentally ill-equipped for real-world sce-
narios where deletion requests arrive sequentially, a setting
known as continual unlearning (CUL). Naively applying
one-shot methods in a continual setting triggers a stability
†Work done during an internship at Sony AI
crisis, leading to a cascade of degradation characterized by
retention collapse, compounding collateral damage to re-
lated concepts, and a sharp decline in generative quality. To
address this critical challenge, we introduce a novel genera-
tive distillation based continual unlearning framework that
ensures targeted and stable unlearning under sequences of
deletion requests. By reframing each unlearning step as
a multi-objective, teacher-student distillation process, the
framework leverages principles from continual learning to
maintain model integrity. Experiments on a 10-step sequen-
tial benchmark demonstrate that our method unlearns for-
get concepts with better fidelity and achieves this without
significant interference to the performance on retain con-
cepts or the overall image quality, substantially outperform-
1
arXiv:2512.02657v1 [cs.LG] 2 Dec 2025
ing baselines. This framework provides a viable pathway
for the responsible deployment and maintenance of large-
scale generative models, enabling industries to comply with
ongoing data removal requests in a practical and effective
manner.
1. Introduction
Recent visual generative models such as SORA [5], Gem-
ini [31], Imagen 3.0 [28], and DALL·E 3 [3] can synthesize
photorealistic media at scale. These models are trained on
massive web-scale datasets that often include sensitive per-
sonal data, NSFW material, and copyrighted content. Laws
such as GDPR [24] grant a “Right to be Forgotten”, but
retraining foundation models from scratch is prohibitively
expensive. The common workaround, post-generation fil-
tering, is superficial; the model retains underlying knowl-
edge, and filters can be bypassed by users [23, 36]. This
motivates machine unlearning (MU): directly editing model
weights to remove targeted concepts (objects, NSFW, artis-
tic styles, identities) from generative behavior. However,
deletion requests arrive sequentially rather than all at once.
In principle, an ideal unlearning method should satisfy
three desiderata: (I) Perfect unlearning, where forget con-
cepts are not produced; (II) No Ripple Effects [1], so that
related concepts remain intact (e.g., removing Brad Pitt
should not distort Angelina Jolie or Leonardo DiCaprio; un-
learning Van Gogh should not degrade other artistic styles);
and (III) Quality Preservation, maintaining overall im-
age quality.
Current approaches map forget concepts to
fixed placeholders (empty strings [9, 34], general con-
cepts [10, 18], or random concepts [8]), suppressing rather
than truly unlearning them. This leads to ripple effects (col-
lateral damage to related concepts [1, 40]).
These challenges are significantly amplified in continual
unlearning (CUL) [11, 32, 35], where deletion