ESACT: An End-to-End Sparse Accelerator for Compute-Intensive Transformers via Local Similarity
Reading time: 5 minute
...
📝 Original Info
Title: ESACT: An End-to-End Sparse Accelerator for Compute-Intensive Transformers via Local Similarity
ArXiv ID: 2512.02403
Date: 2025-12-02
Authors: Hongxiang Liu, Zhifang Deng, Tong Pu, Shengli Lu
📝 Abstract
Transformers, composed of QKV generation, attention computation, and FFNs,
have become the dominant model across various domains due to their outstanding performance.
However, their high computational cost hinders efficient hardware deployment.
Sparsity offers a promising solution,
yet most existing accelerators exploit only intra-row sparsity in attention,
while few consider inter-row sparsity.
Approaches leveraging inter-row sparsity often rely on costly global similarity estimation,
which diminishes the acceleration benefits of sparsity,
and typically apply sparsity to only one or two transformer components.
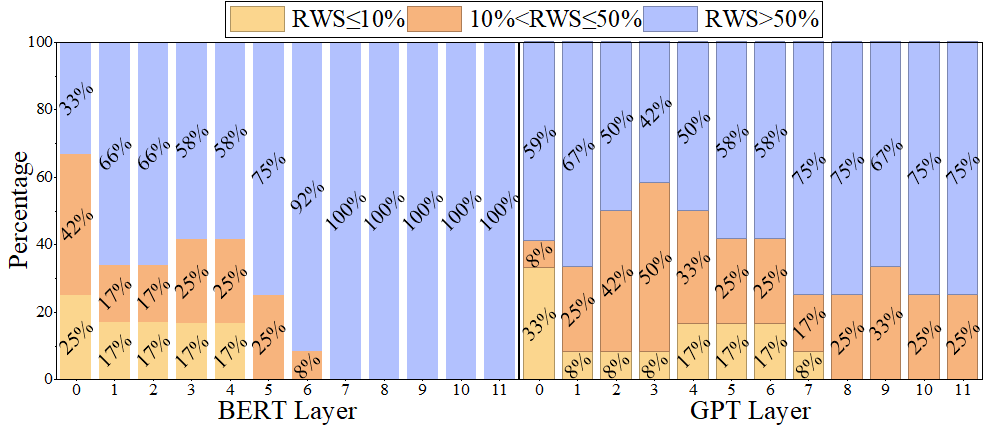
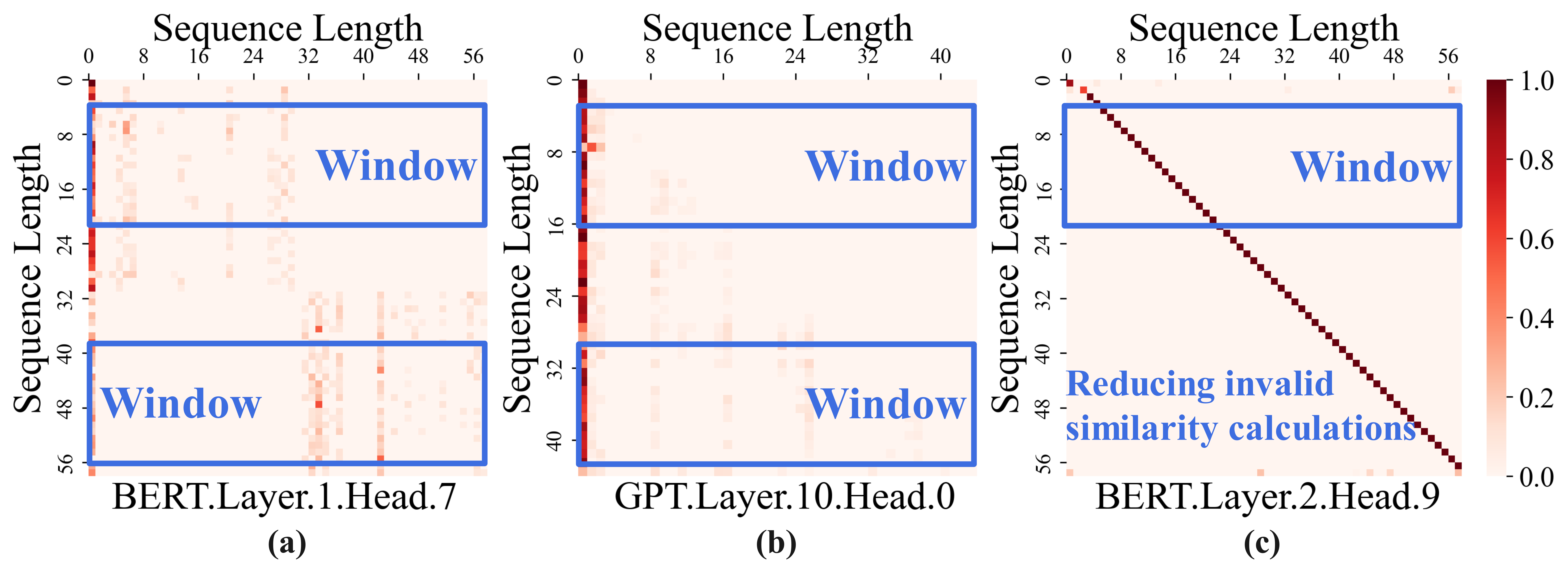
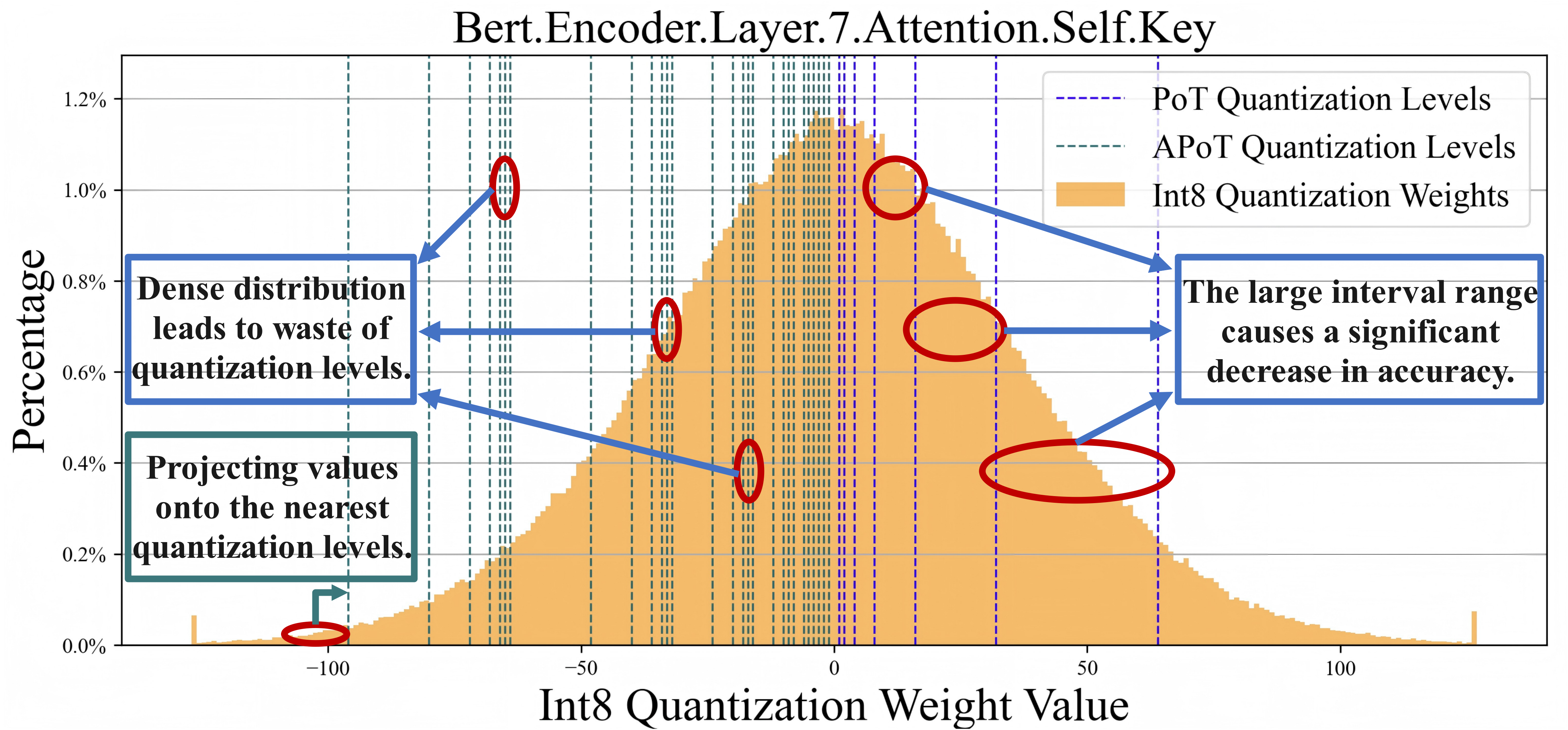
Through careful analysis of the attention distribution and computation flow,
we observe that local similarity allows end-to-end sparse acceleration with lower computational overhead.
Motivated by this observation, we propose ESACT,
an end-to-end sparse accelerator for compute-intensive Transformers.
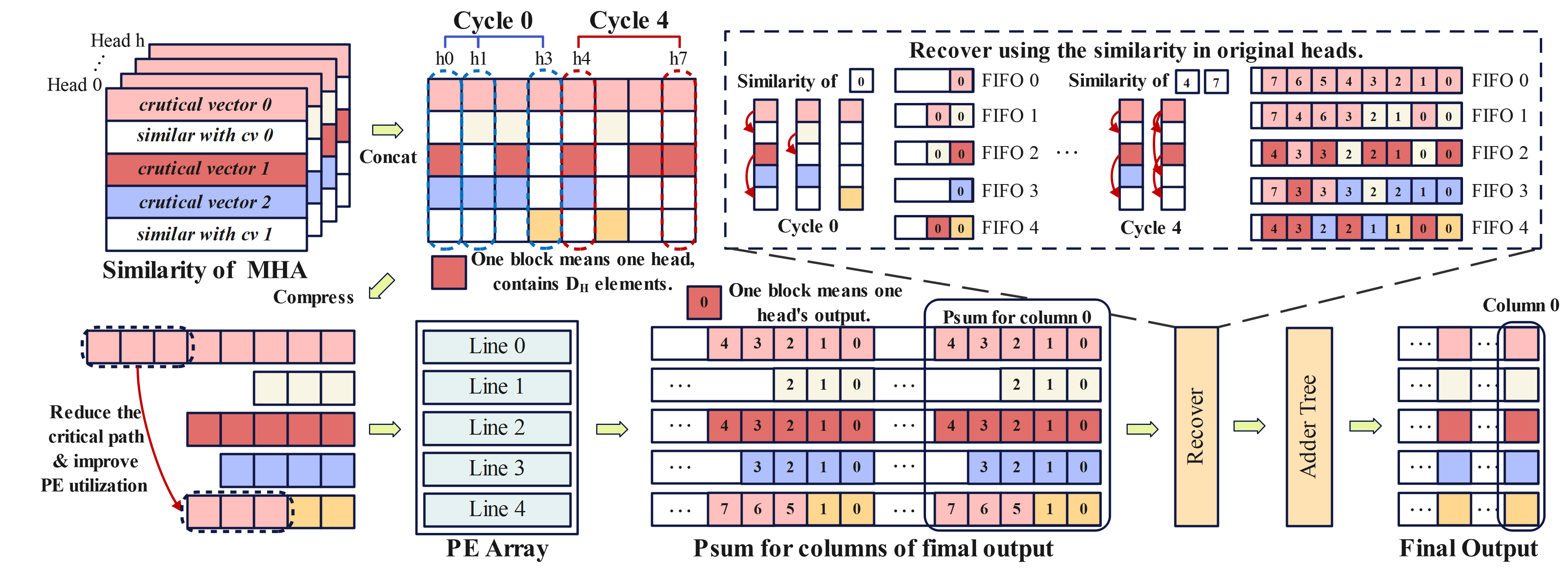
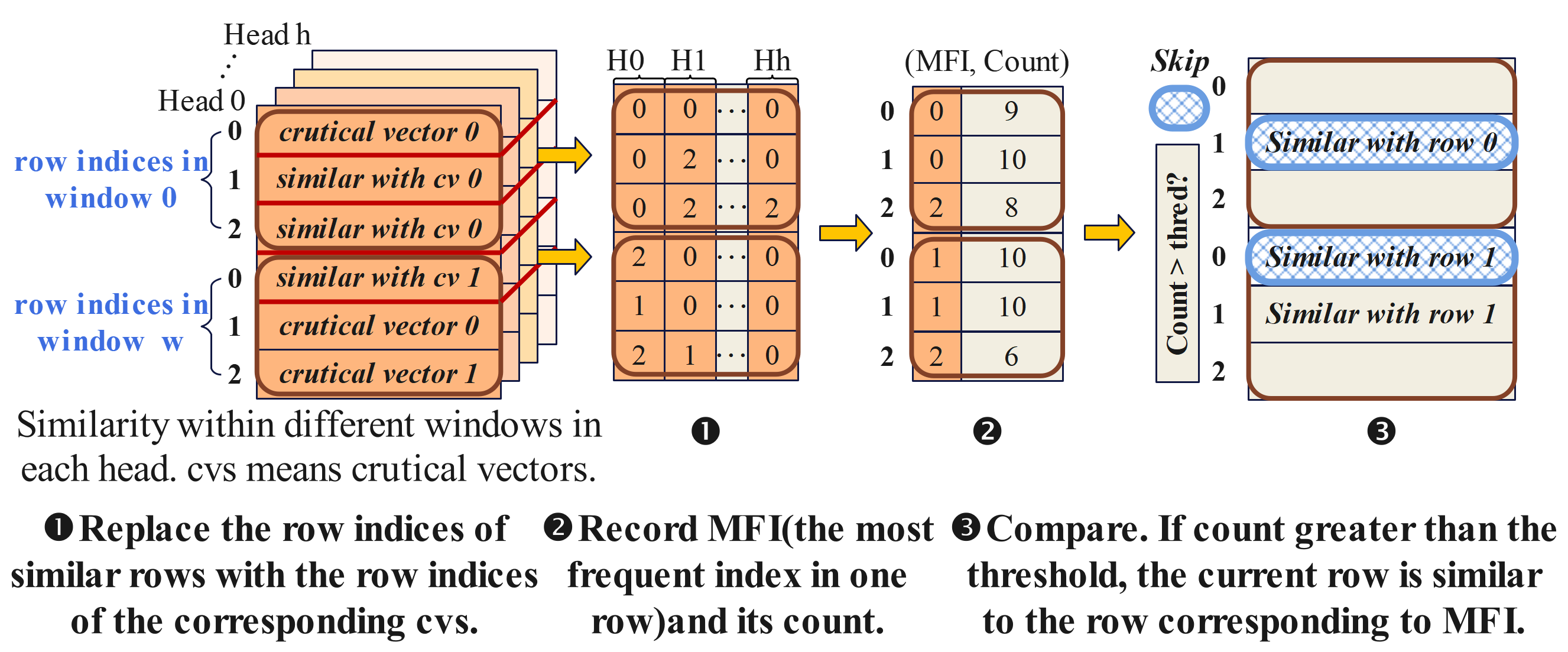
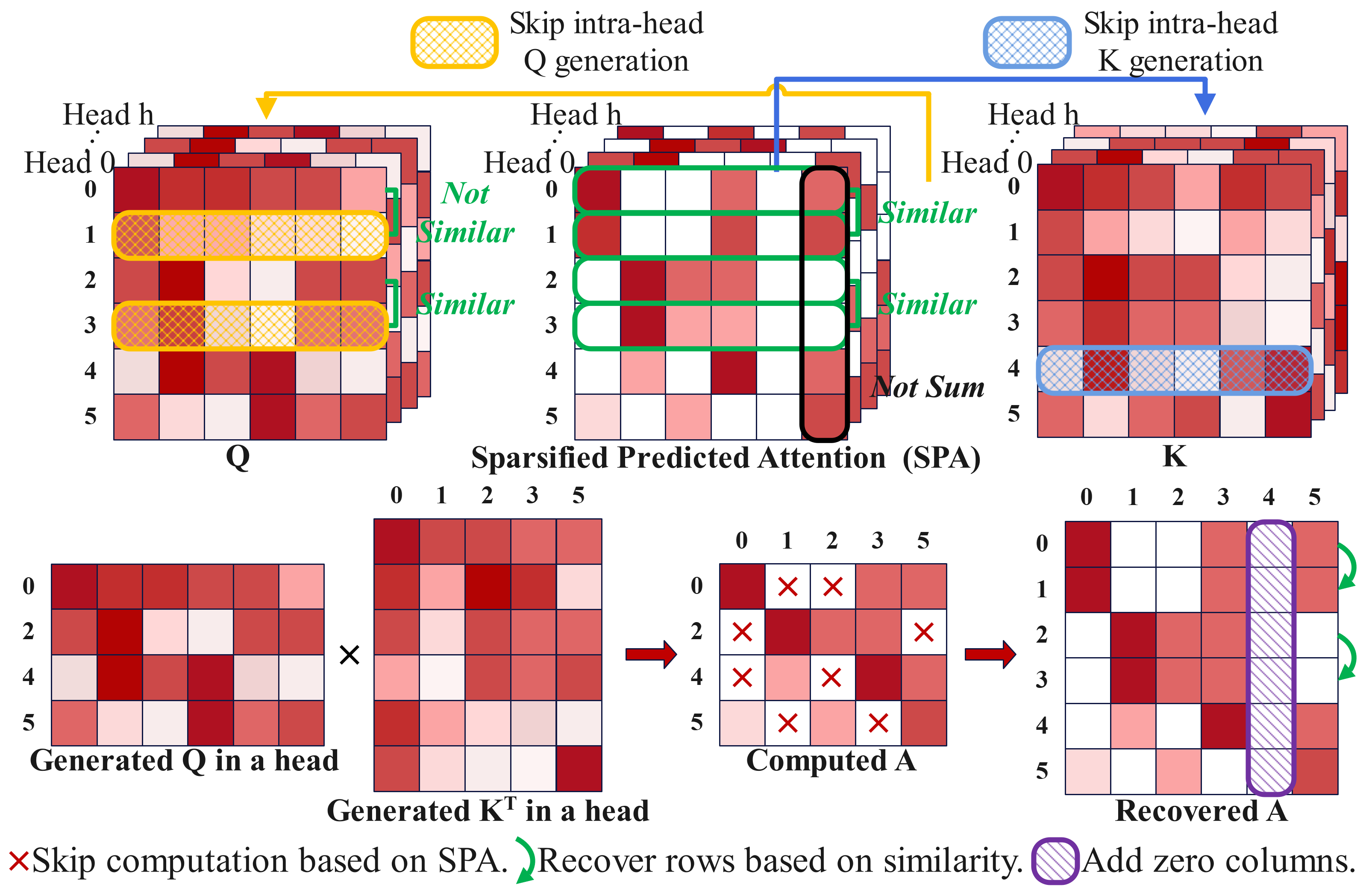
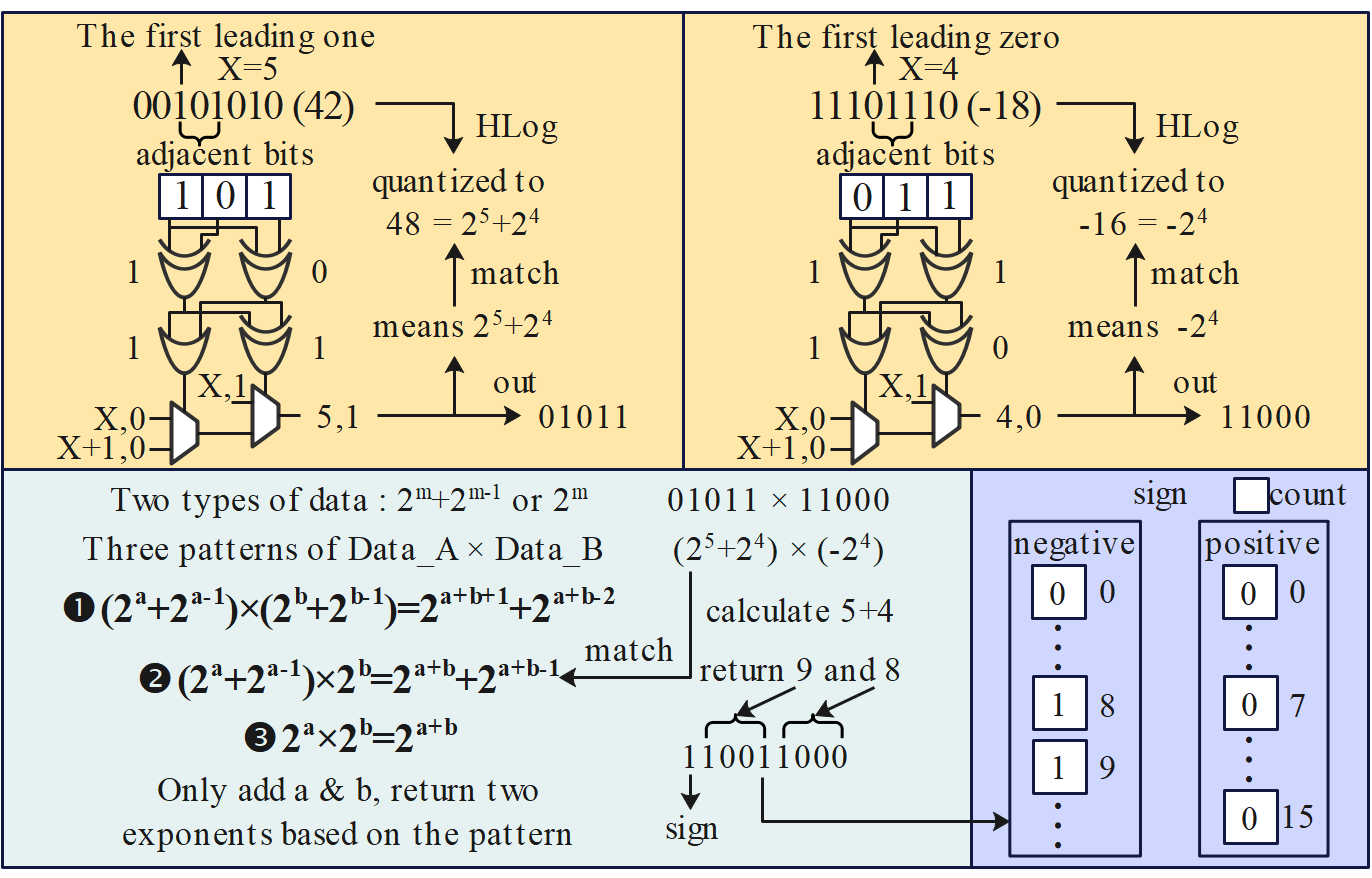
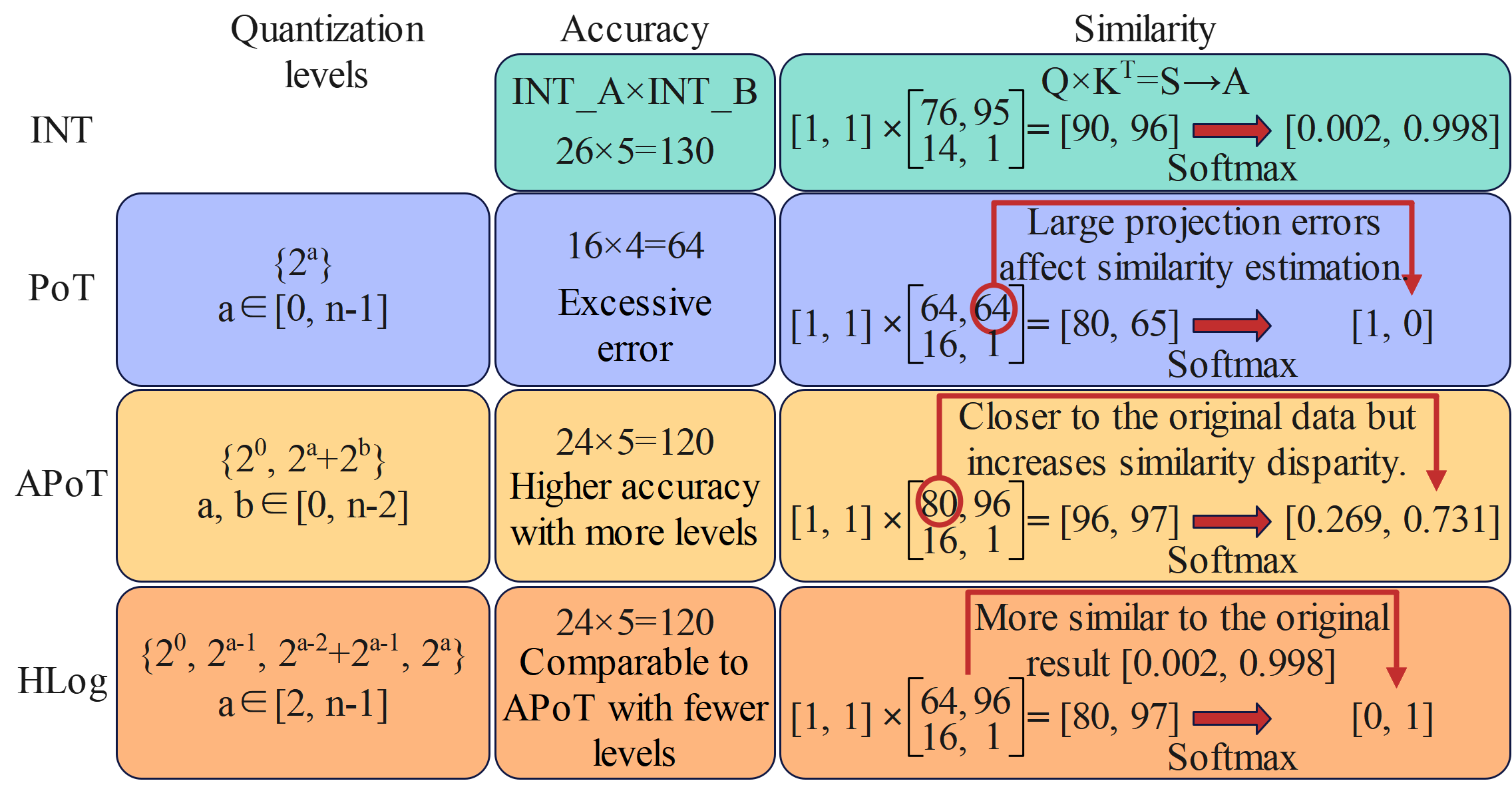
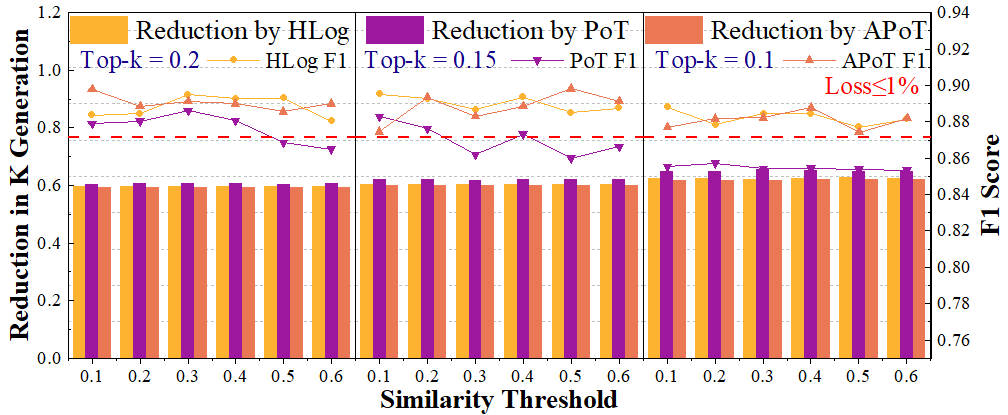
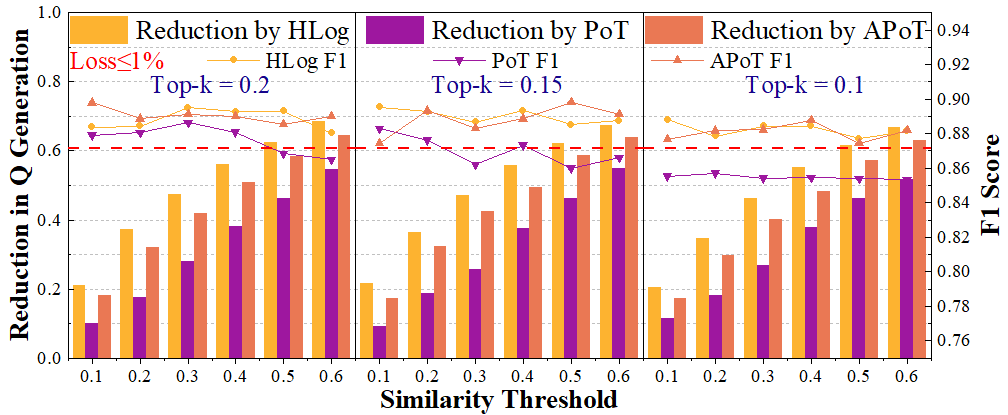
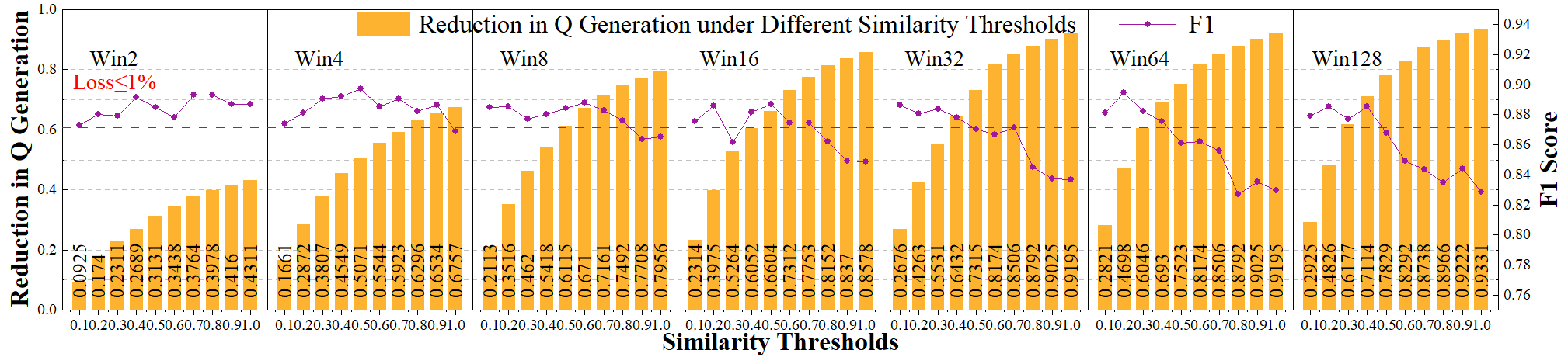
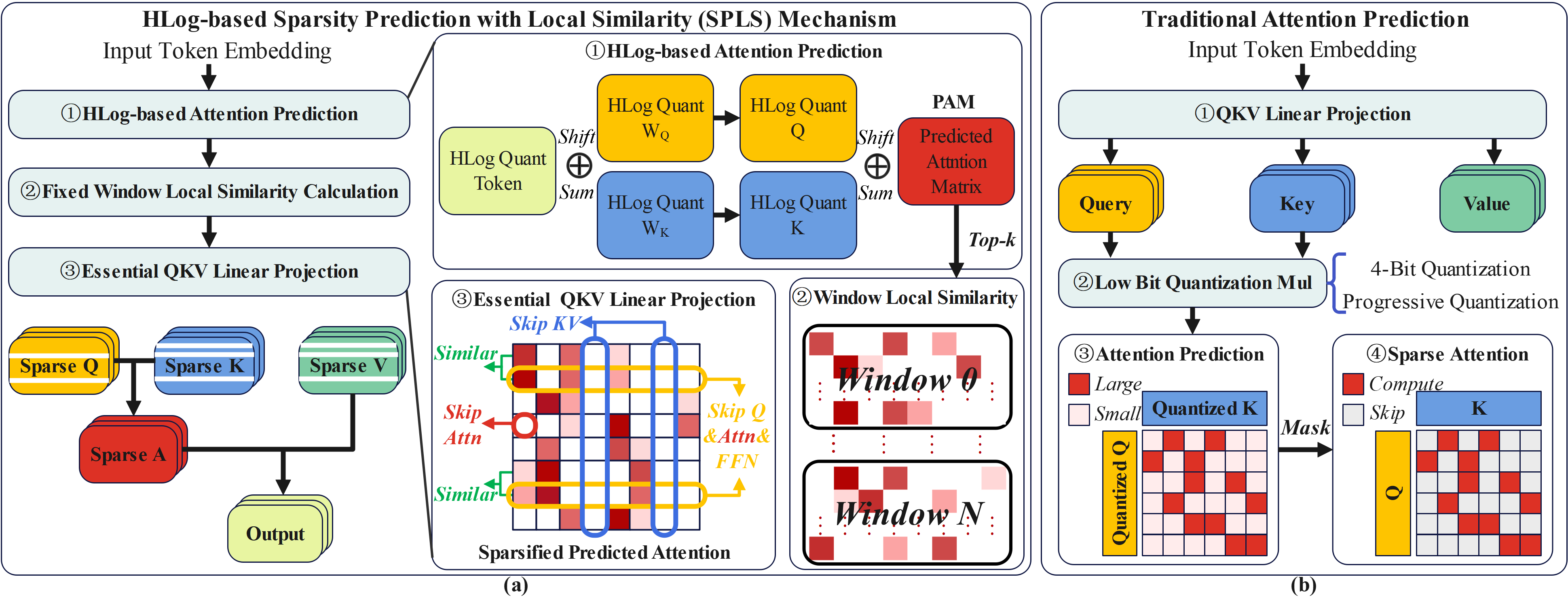
ESACT centers on the Sparsity Prediction with Local Similarity (SPLS) mechanism,
which leverages HLog quantization to accurately predict local attention sparsity prior to QK generation,
achieving efficient sparsity across all transformer components.
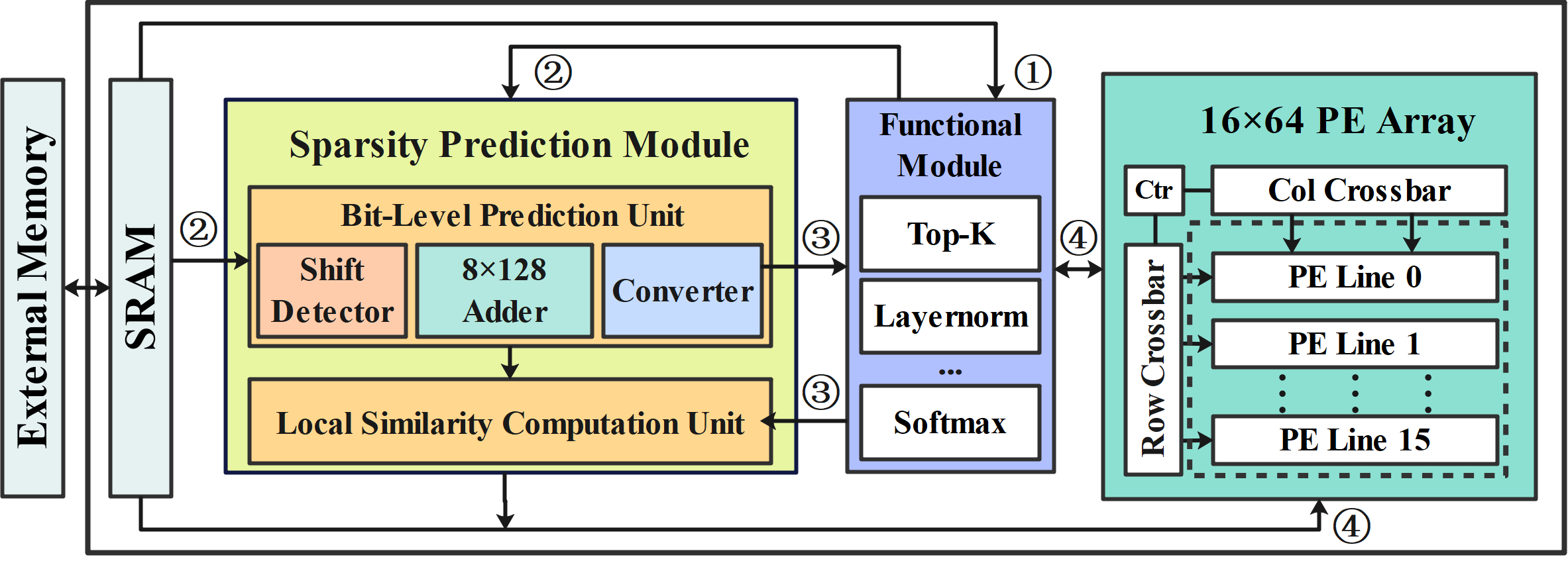
To support efficient hardware realization, we introduce three architectural innovations.
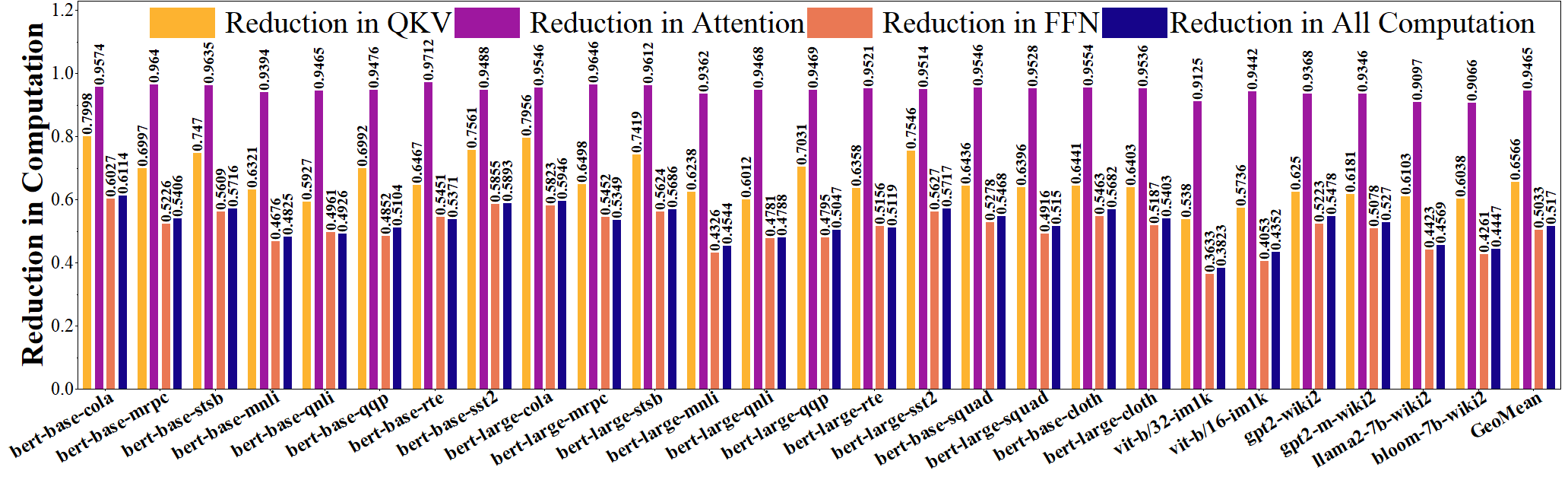
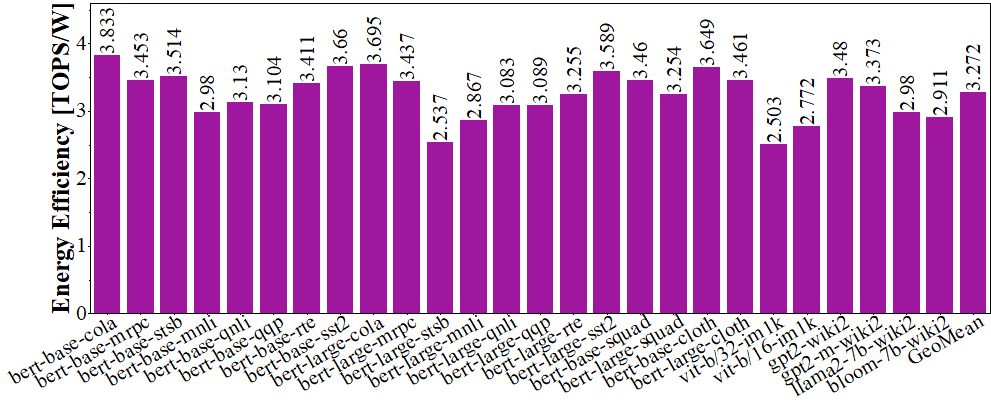
Experimental results on 26 benchmarks demonstrate that
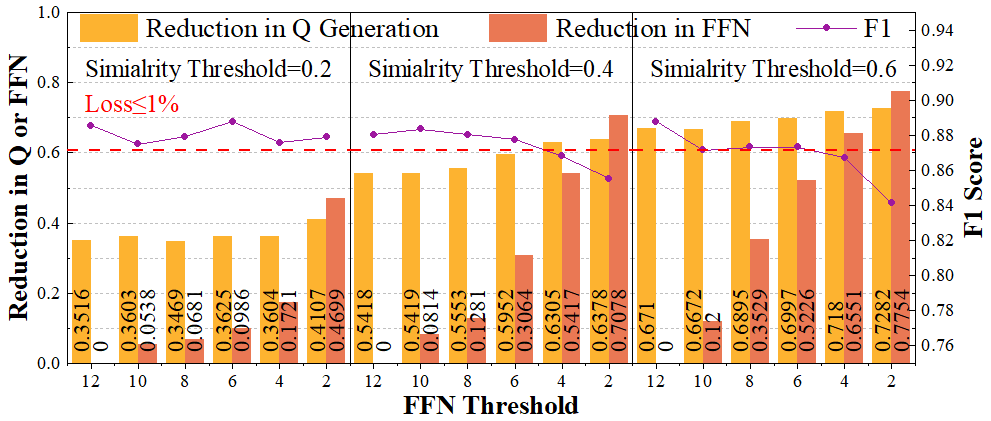
SPLS reduces total computation by 52.03% with less than 1% accuracy loss.
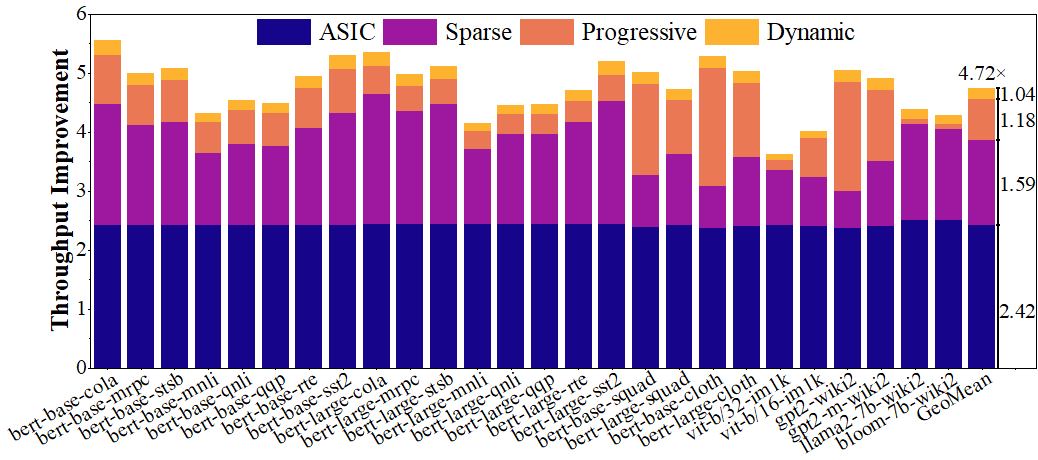
ESACT achieves an end-to-end energy efficiency of 3.29 TOPS/W,
and improves attention-level energy efficiency by 2.95x and 2.26x over
SOTA attention accelerators SpAtten and Sanger, respectively.
💡 Deep Analysis
📄 Full Content
JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021
1
ESACT: An End-to-End Sparse Accelerator for
Compute-Intensive Transformers via Local
Similarity
Hongxiang Liu , Zhifang Deng , Tong Pu , and Shengli Lu
Abstract—Transformers, composed of QKV generation, at-
tention computation, and FFNs, have become the dominant
model across various domains due to their outstanding perfor-
mance. However, their high computational cost hinders efficient
hardware deployment. Sparsity offers a promising solution, yet
most existing accelerators exploit only intra-row sparsity in
attention, while few consider inter-row sparsity. Approaches
leveraging inter-row sparsity often rely on costly global similarity
estimation, which diminishes the acceleration benefits of sparsity,
and typically apply sparsity to only one or two transformer com-
ponents. Through careful analysis of the attention distribution
and computation flow, we observe that local similarity allows end-
to-end sparse acceleration with lower computational overhead.
Motivated by this observation, we propose ESACT, an end-to-end
sparse accelerator for compute-intensive Transformers. ESACT
centers on the Sparsity Prediction with Local Similarity (SPLS)
mechanism, which leverages HLog quantization to accurately
predict local attention sparsity prior to QK generation, achieving
efficient sparsity across all transformer components. To support
efficient hardware realization, we introduce three architectural
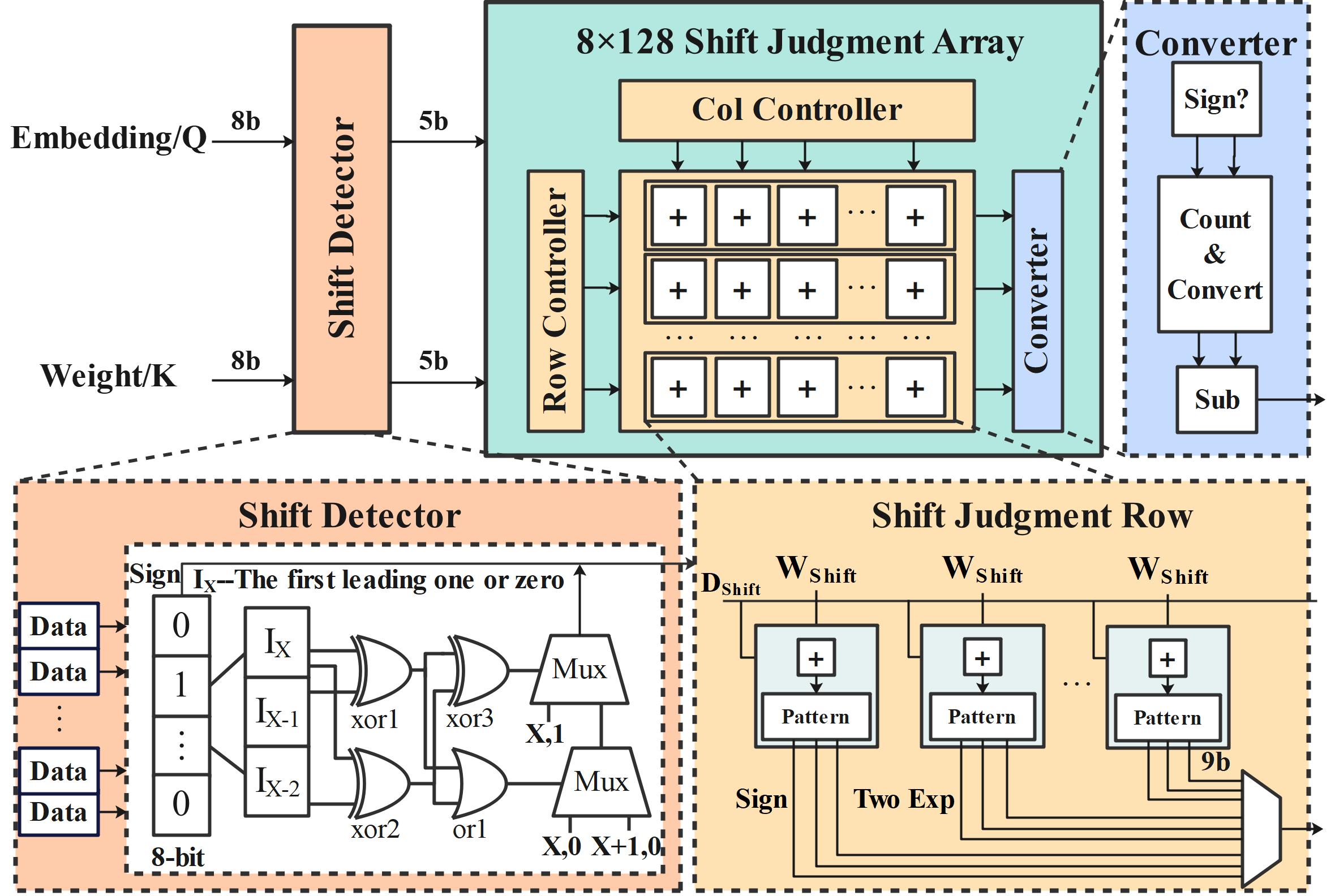
innovations. First, we design a bit-level prediction unit that
leverages bit-wise correlations to enable efficient quantization and
performs attention prediction using only additions, significantly
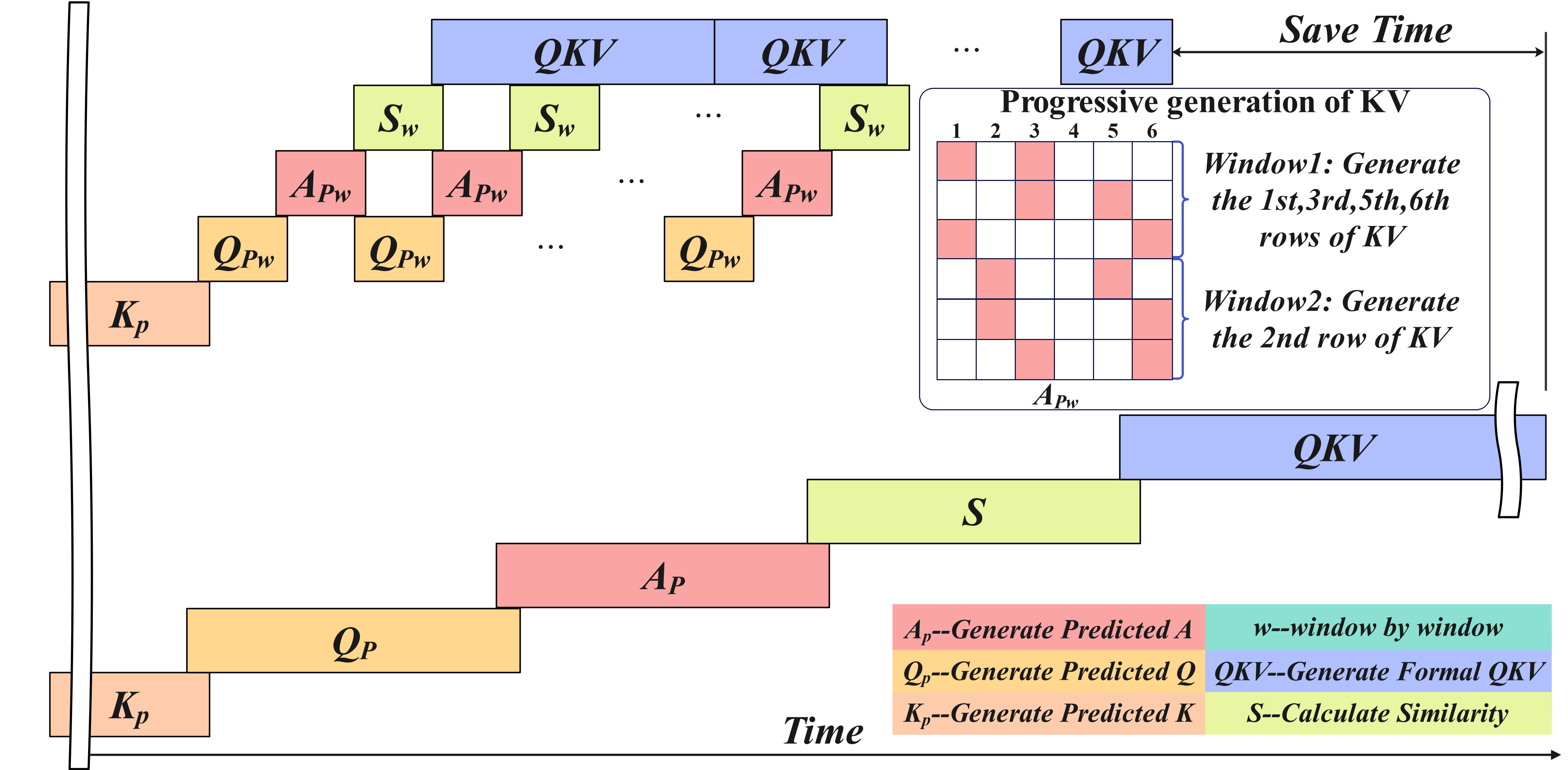
reducing power consumption. Second, we propose a progressive
generation scheme that overlaps QKV generation with sparsity
prediction, minimizing PE idle time. Third, a dynamic allocation
strategy is adopted to alleviate computation imbalance caused
by similarity-driven sparsity, improving overall PE utilization.
Experimental results on 26 benchmarks demonstrate that SPLS
reduces total computation by 51.7% with less than 1% accu-
racy loss. ESACT achieves an end-to-end energy efficiency of
3.27 TOPS/W, and improves attention-level energy efficiency by
2.95× and 2.26× over SOTA attention accelerators SpAtten and
Sanger, respectively.
Index Terms—Transformer, sparsity, local similarity, end-to-
end, hardware accelerator.
I. INTRODUCTION
T
RANSFORMER [1] is a powerful neural network that
has become a dominant model in various fields, including
natural language processing [2]–[8], computer vision [9]–
[14], and time series forecasting [15]–[19]. Its remarkable
performance is attributed to its innovative design features.
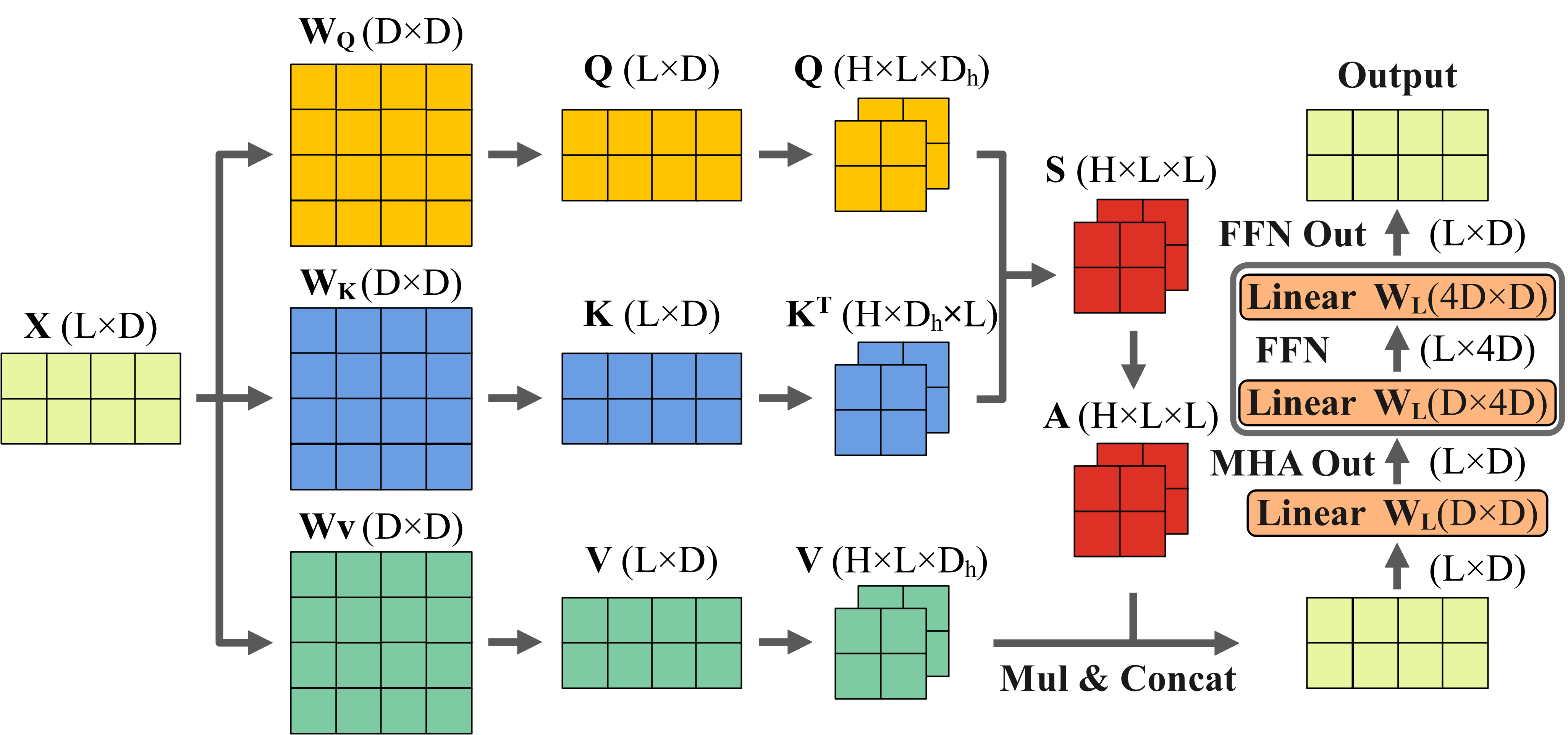
Specifically, Transformer consists of two core components:
the multi-head attention mechanism (MHA) and the feed-
forward network (FFN). The MHA involves query, key and
The authors are with the School of Integrated Circuits, Southeast University,
Nanjing 211189, China (e-mail: liuhx@seu.edu.cn; zhifangdeng@seu.edu.cn;
putong@seu.edu.cn; lsl@seu.edu.cn). Corresponding author: Shengli Lu.
value (QKV) generation and attention computation, allowing
the model to capture global dependencies while adaptively
adjusting the weights based on the input. Subsequently, the
FFN enhances the outputs from the MHA by performing
feature extraction and transformation, which improves the
model’s capacity to abstract and represent information effec-
tively. However, the performance improvement comes at the
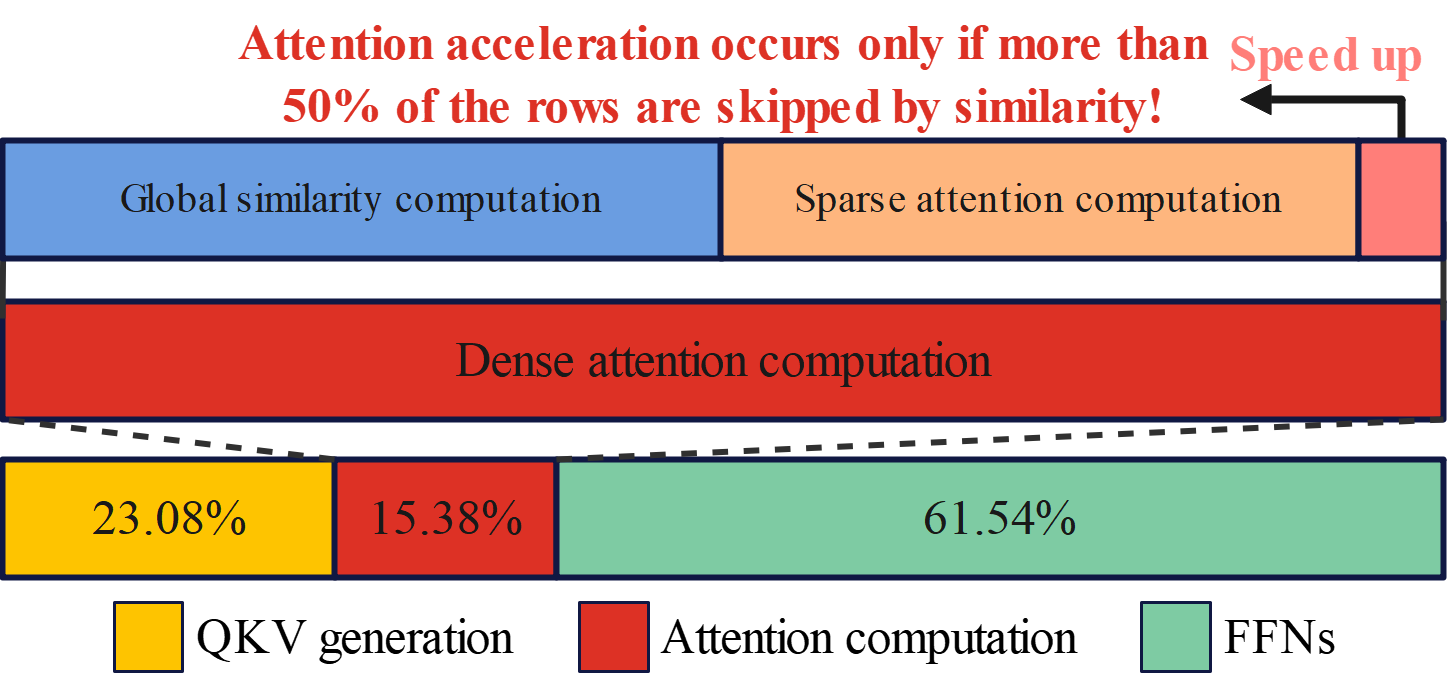
cost of increased computational complexity. As illustrated in
Figure 1, taking BERT-Large [2] as an example, when the
input sequence length is 512, the total computation of the
model is 167.5GFLOPs without any sparsity, of which the
MHA and the FFN account for 38.46% and 61.54%, respec-
tively. Therefore, it is essential to reduce the computation of
the two core components simultaneously.
Sparsity is one of the most direct and effective approaches
to addressing the computational bottleneck of a model by elim-
inating redundant operations, thereby reducing computational
load. However, since sparsity removes certain computations,
it may change the model’s structure and potentially degrade
its performance. Therefore, it is essential to apply sparsity in
a way that minimizes computational cost while maintaining
model accuracy.
We categorize existing effective sparsity methods for Trans-
formers into two types: one based on the relative magnitude
of data, and the other based on similarity relationships among
data. The former is the most common sparsity approach [20]–
[25], which typically predicts the attention matrix using
quantized Q and K to obtain the predicted attention matrix
(PAM). Importance is then evaluated based on the relative
magnitudes of elements in the PAM, and a mask is generated
accordingly to apply sparsity in the MHA or FFN during the
actual computation stage. However, this method only considers
intra-region relationships (e.g., selecting important positions
by