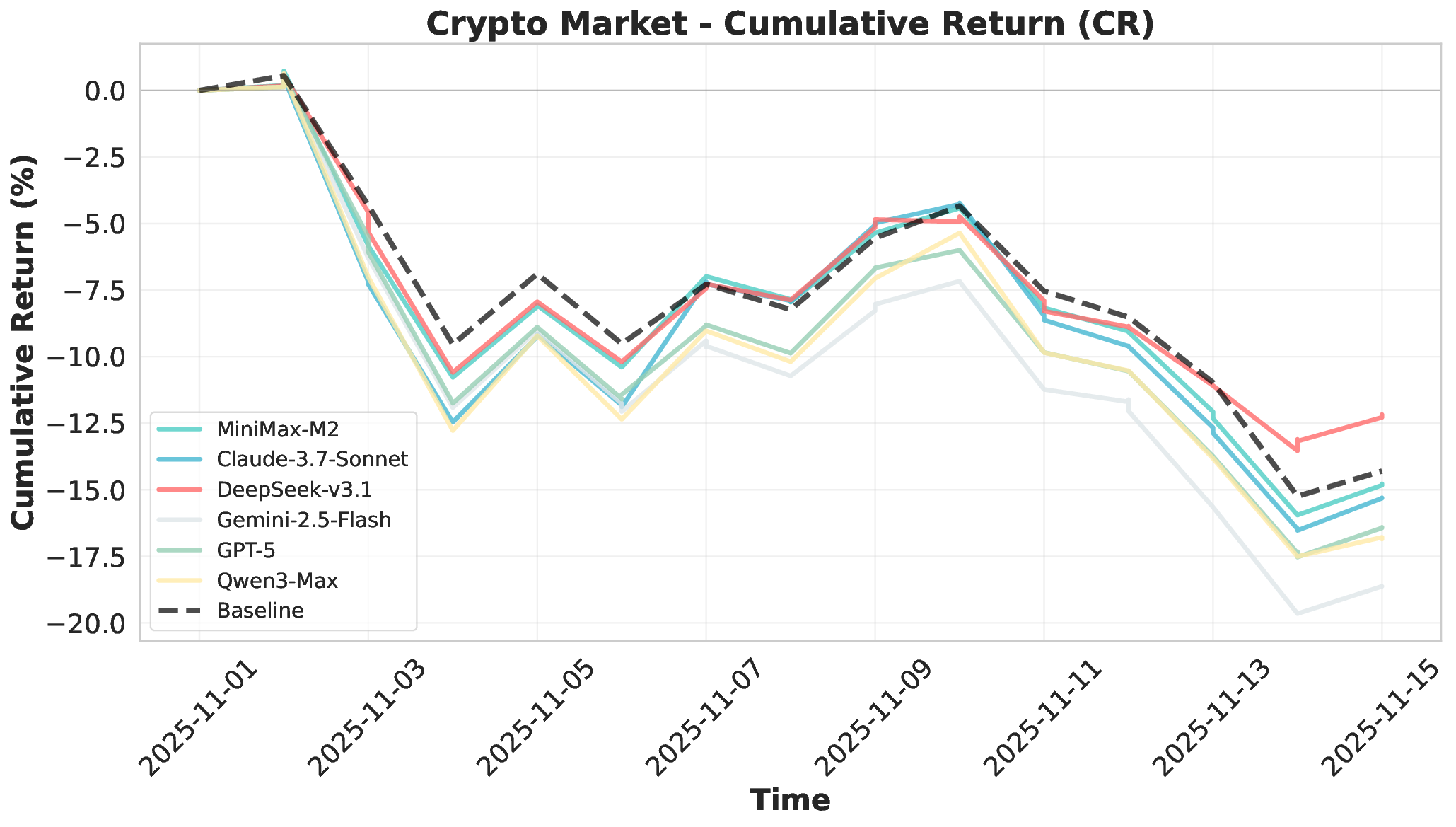
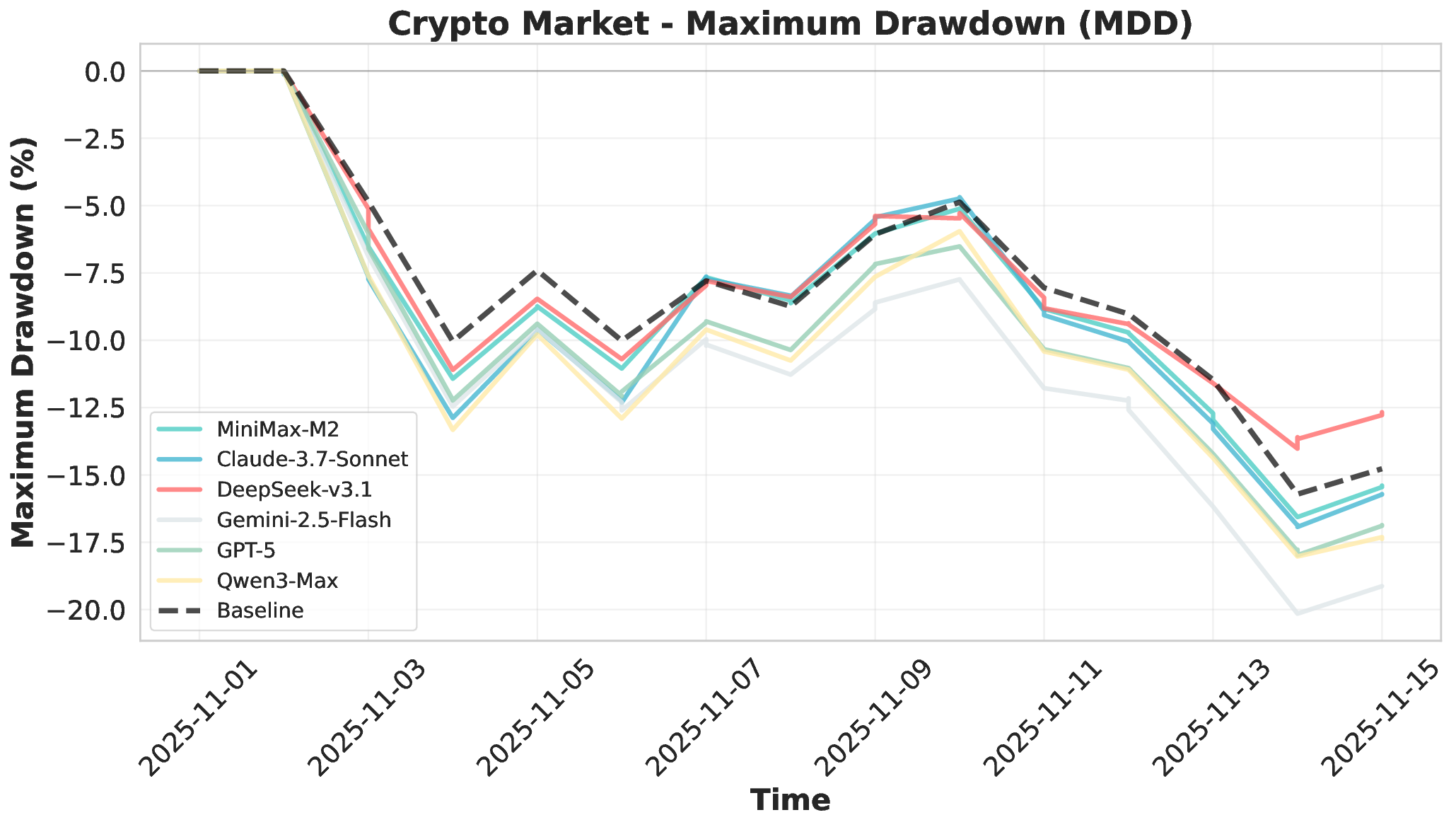
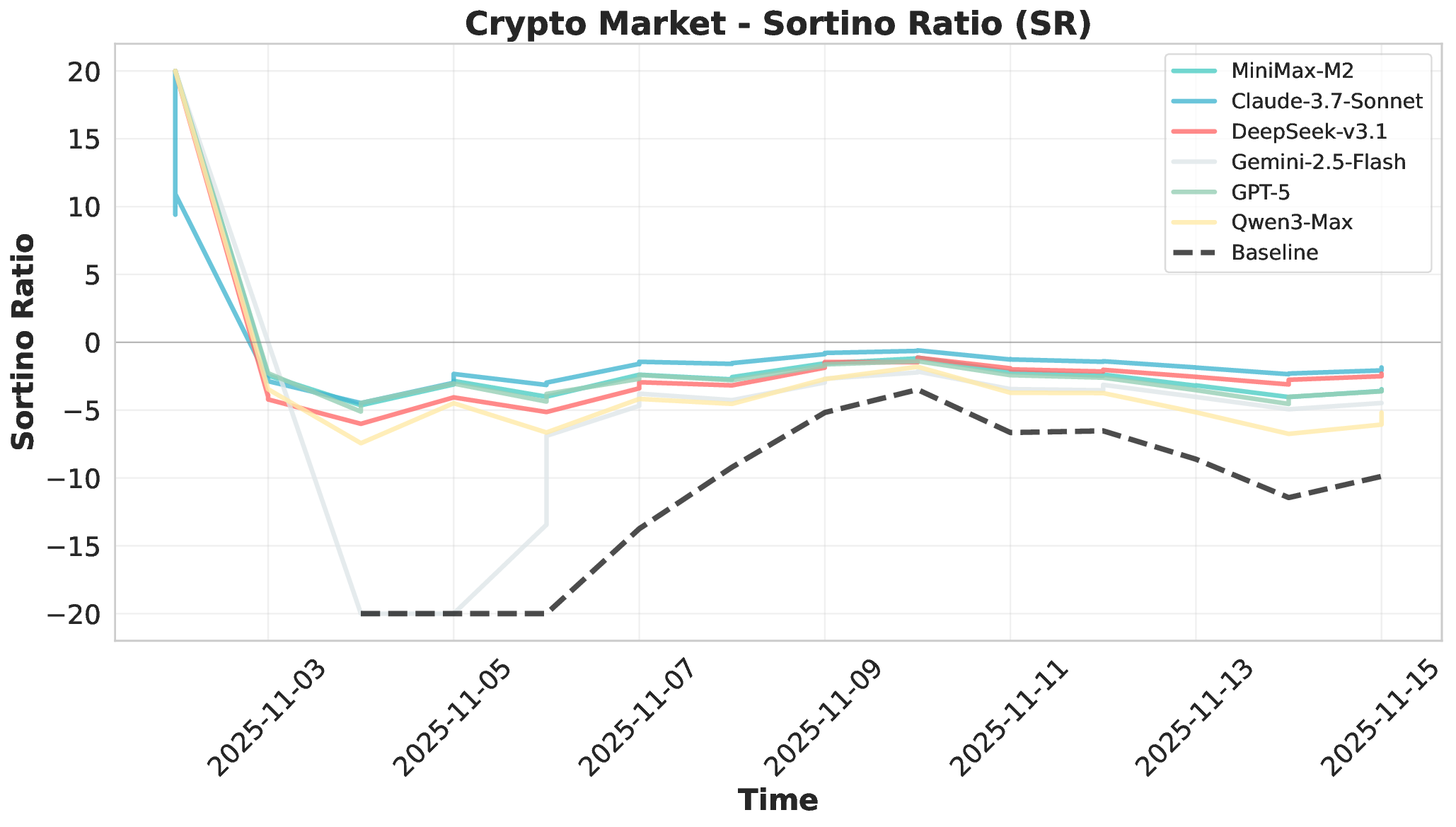
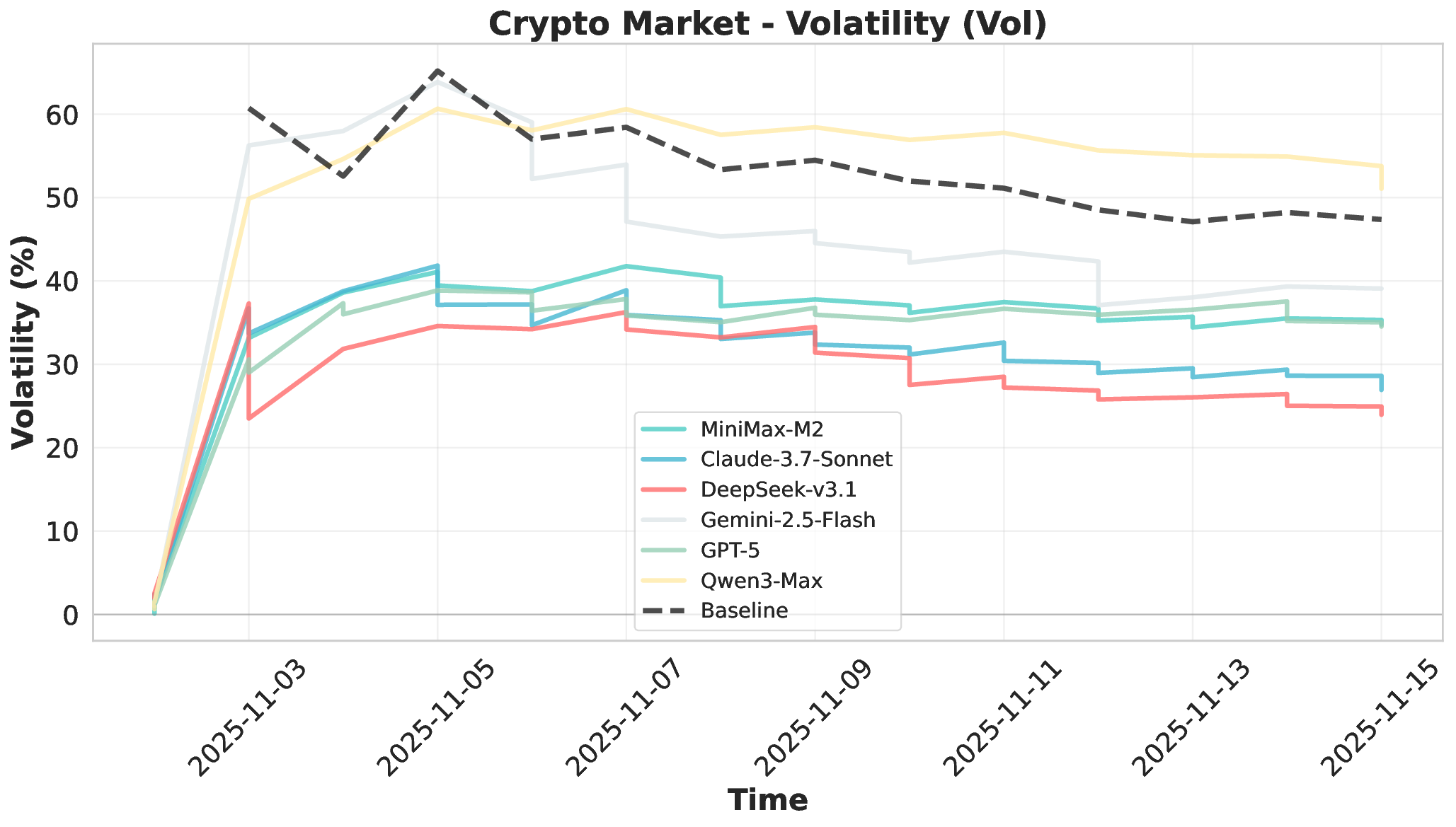
Large Language Models (LLMs) have demonstrated remarkable potential as autonomous agents, approaching human-expert performance through advanced reasoning and tool orchestration. However, decision-making in fully dynamic and live environments remains highly challenging, requiring real-time information integration and adaptive responses. While existing efforts have explored live evaluation mechanisms in structured tasks, a critical gap remains in systematic benchmarking for real-world applications, particularly in finance where stringent requirements exist for live strategic responsiveness. To address this gap, we introduce AI-Trader, the first fully-automated, live, and data-uncontaminated evaluation benchmark for LLM agents in financial decision-making. AI-Trader spans three major financial markets: U.S. stocks, A-shares, and cryptocurrencies, with multiple trading granularities to simulate live financial environments. Our benchmark implements a revolutionary fully autonomous minimal information paradigm where agents receive only essential context and must independently search, verify, and synthesize live market information without human intervention. We evaluate six mainstream LLMs across three markets and multiple trading frequencies. Our analysis reveals striking findings: general intelligence does not automatically translate to effective trading capability, with most agents exhibiting poor returns and weak risk management. We demonstrate that risk control capability determines cross-market robustness, and that AI trading strategies achieve excess returns more readily in highly liquid markets than policy-driven environments. These findings expose critical limitations in current autonomous agents and provide clear directions for future improvements. The code and evaluation data are open-sourced to foster community research: https://github.com/HKUDS/AI-Trader.
Large Language Models have catalyzed a transformative shift toward autonomous agents, endowing these systems with sophisticated capabilities in complex reasoning, dynamic tool orchestration, and strategic long-horizon planning (Gao et al., 2024;Tang et al., 2025;Zhang et al., 2025b). However, this remarkable progress has exposed a critical evaluation gap, particularly in dynamic and real-time scenarios that represent some of the most demanding real-world applications for autonomous systems. Traditional static benchmarks concentrate on question answering (Yang et al., 2018;Joshi et al., 2017;Trivedi et al., 2022), code completion (Ding et al., 2023;Chen et al., 2024;Xie et al., 2025;Zhang et al., 2025a), and single-turn instruction following (Bai et al., 2024;Jiang et al., 2024), operating within constrained, deterministic environments with limited real-world complexity.
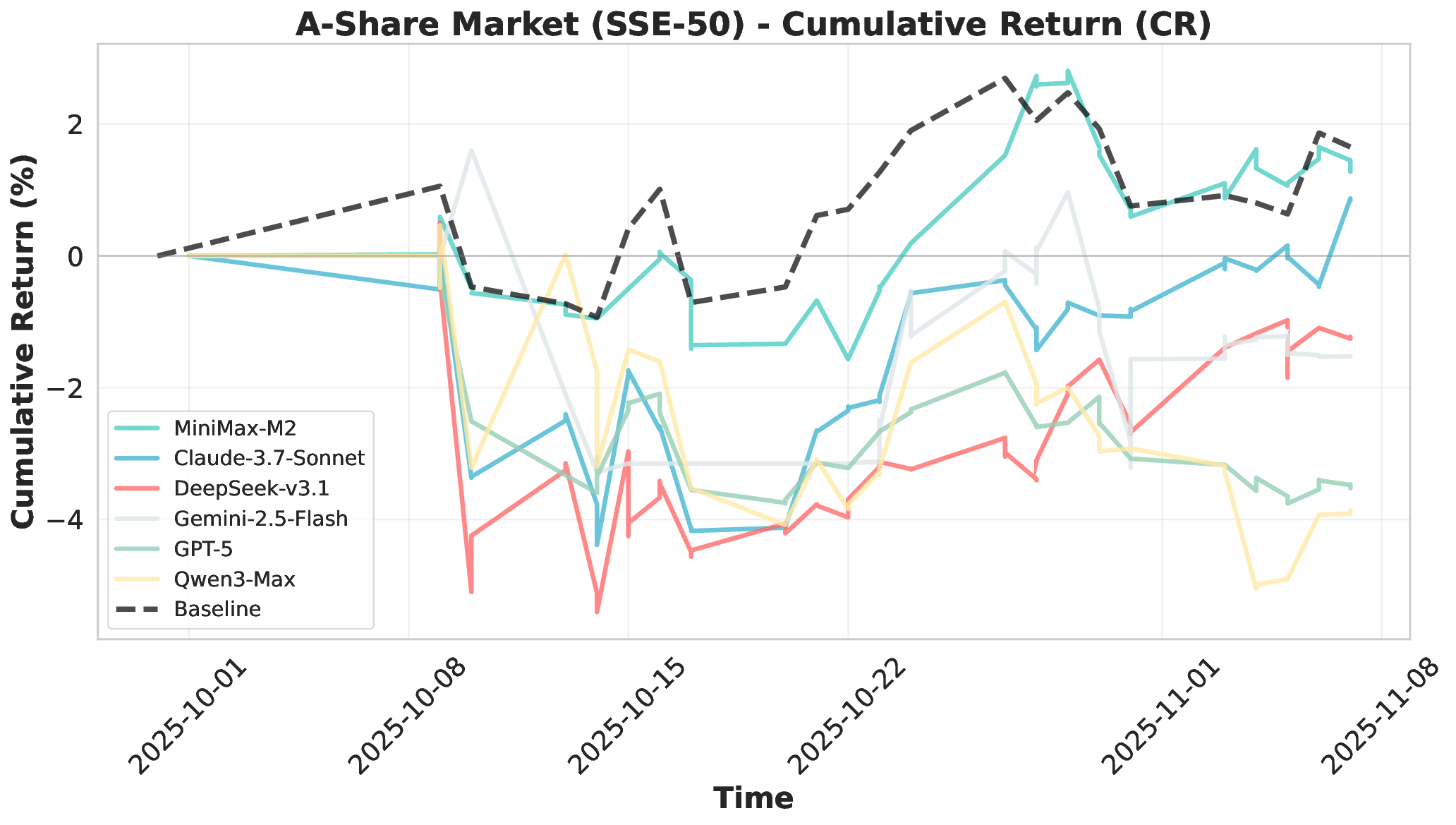
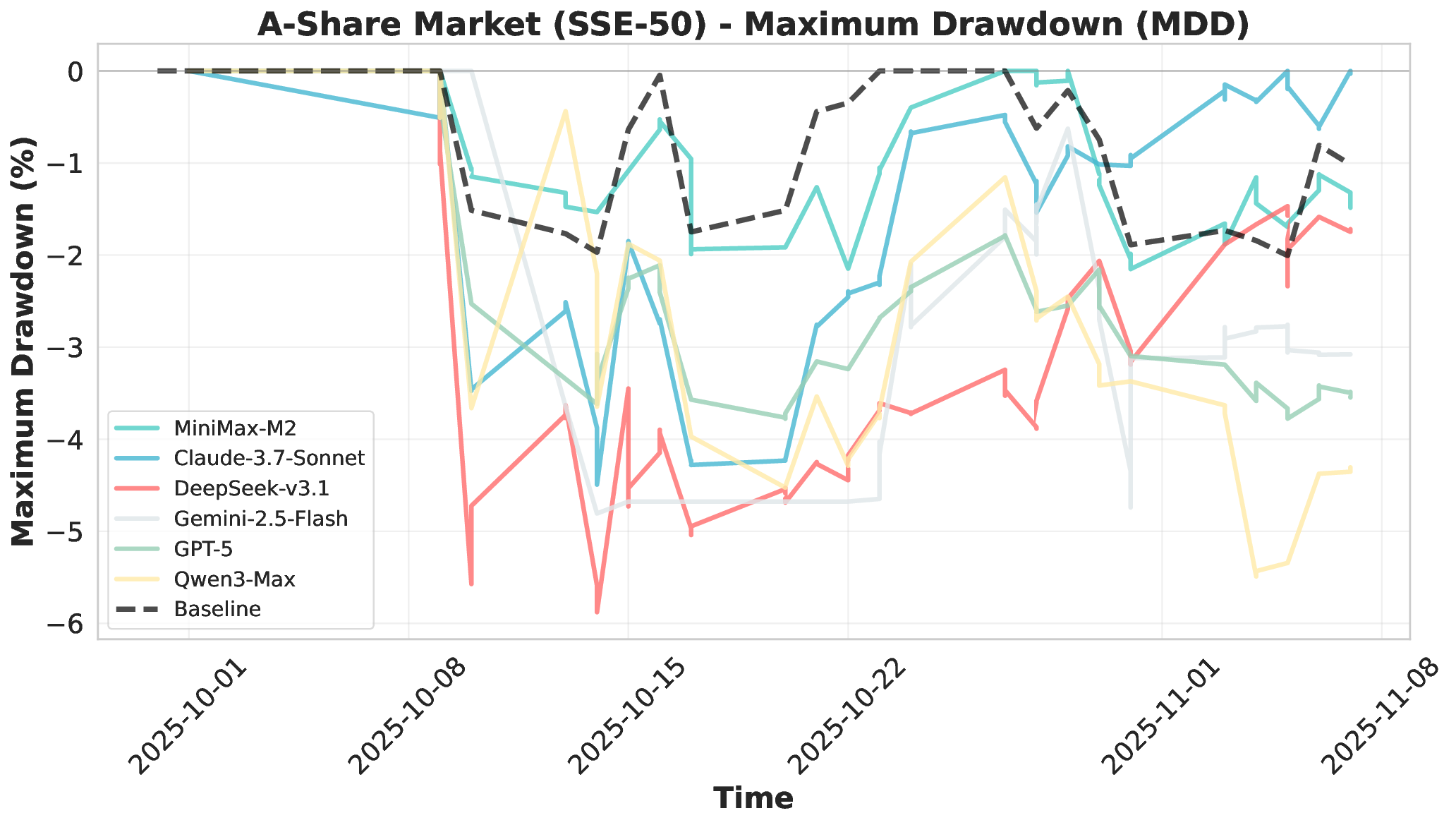
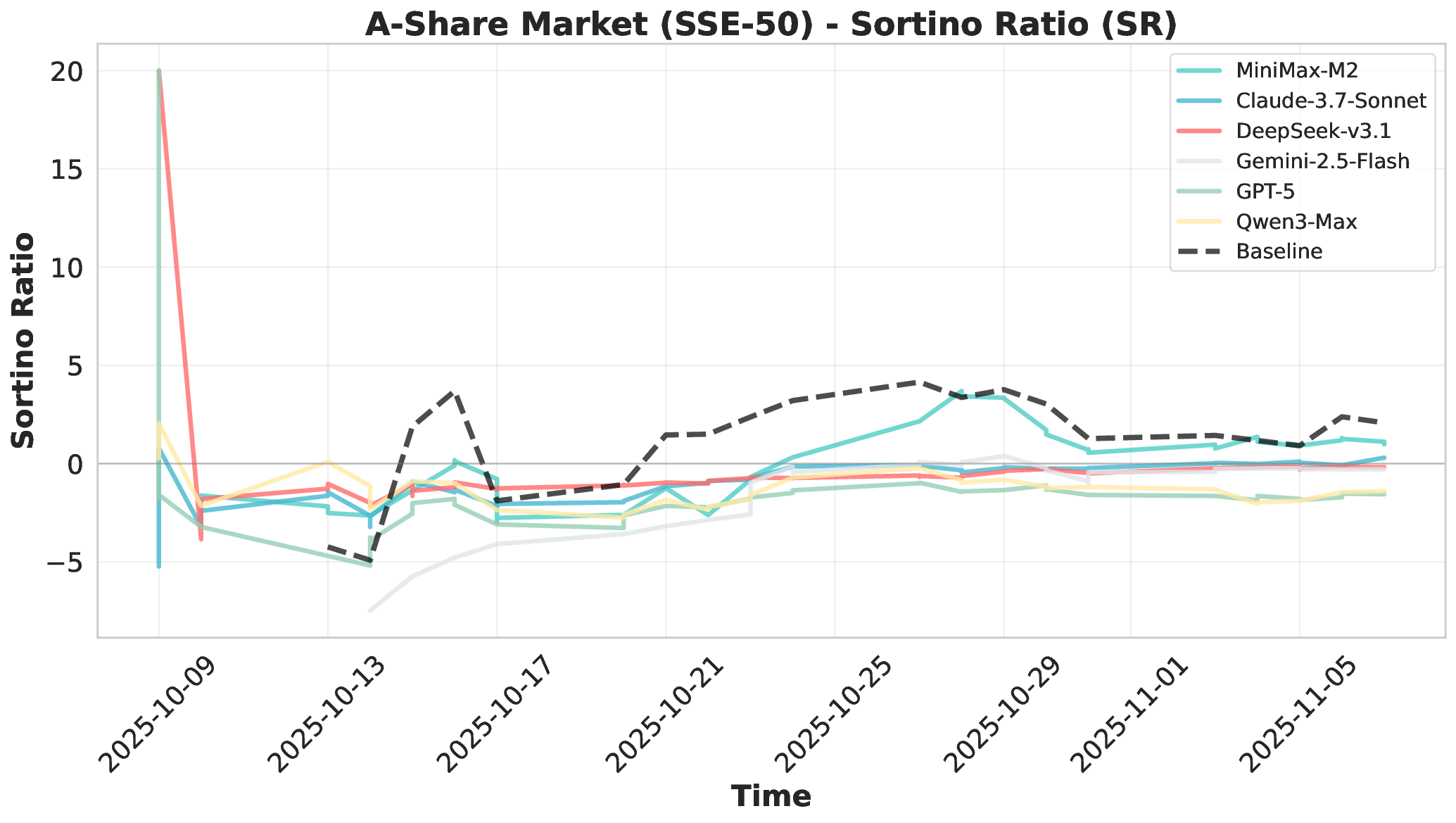
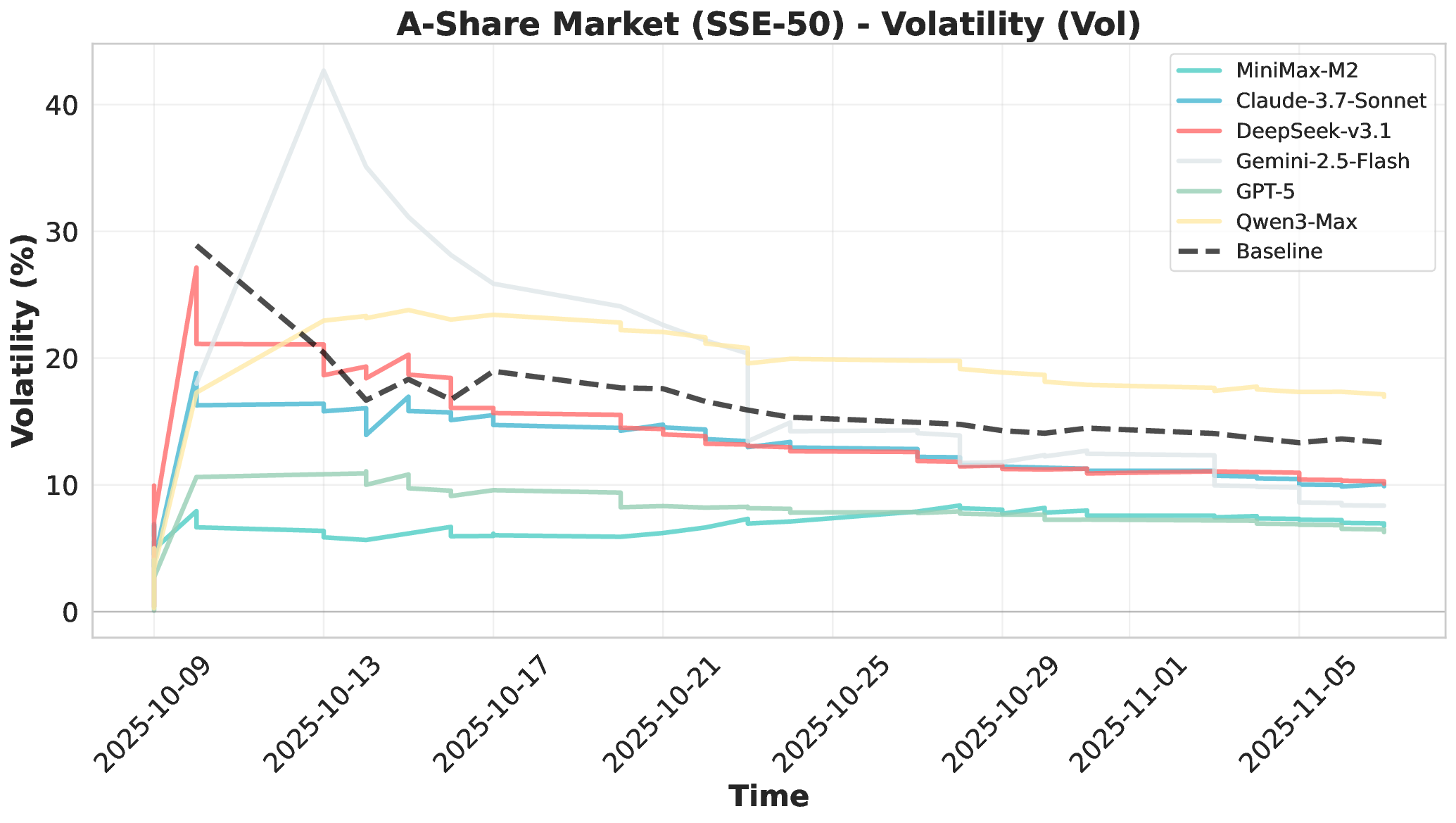
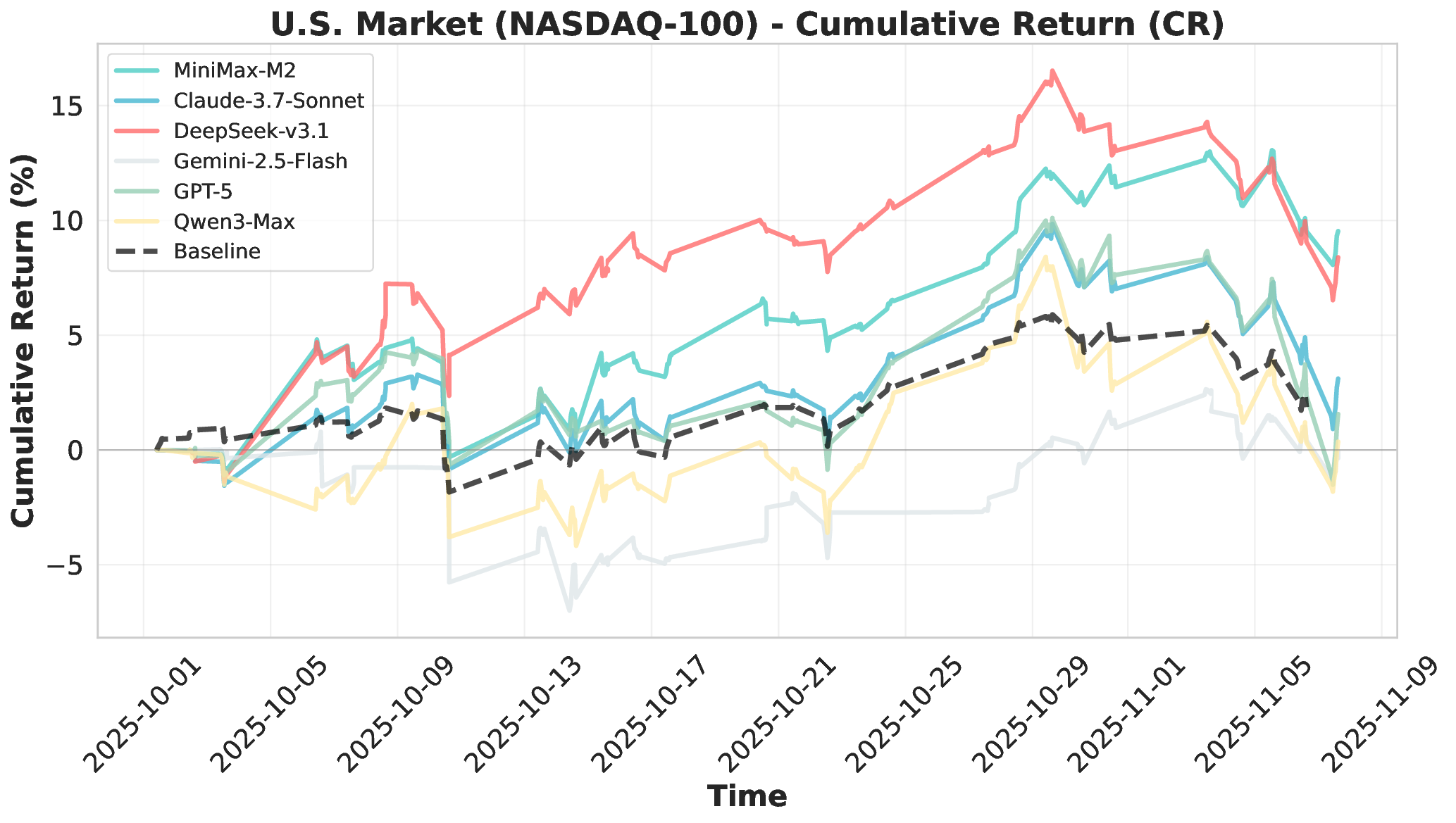
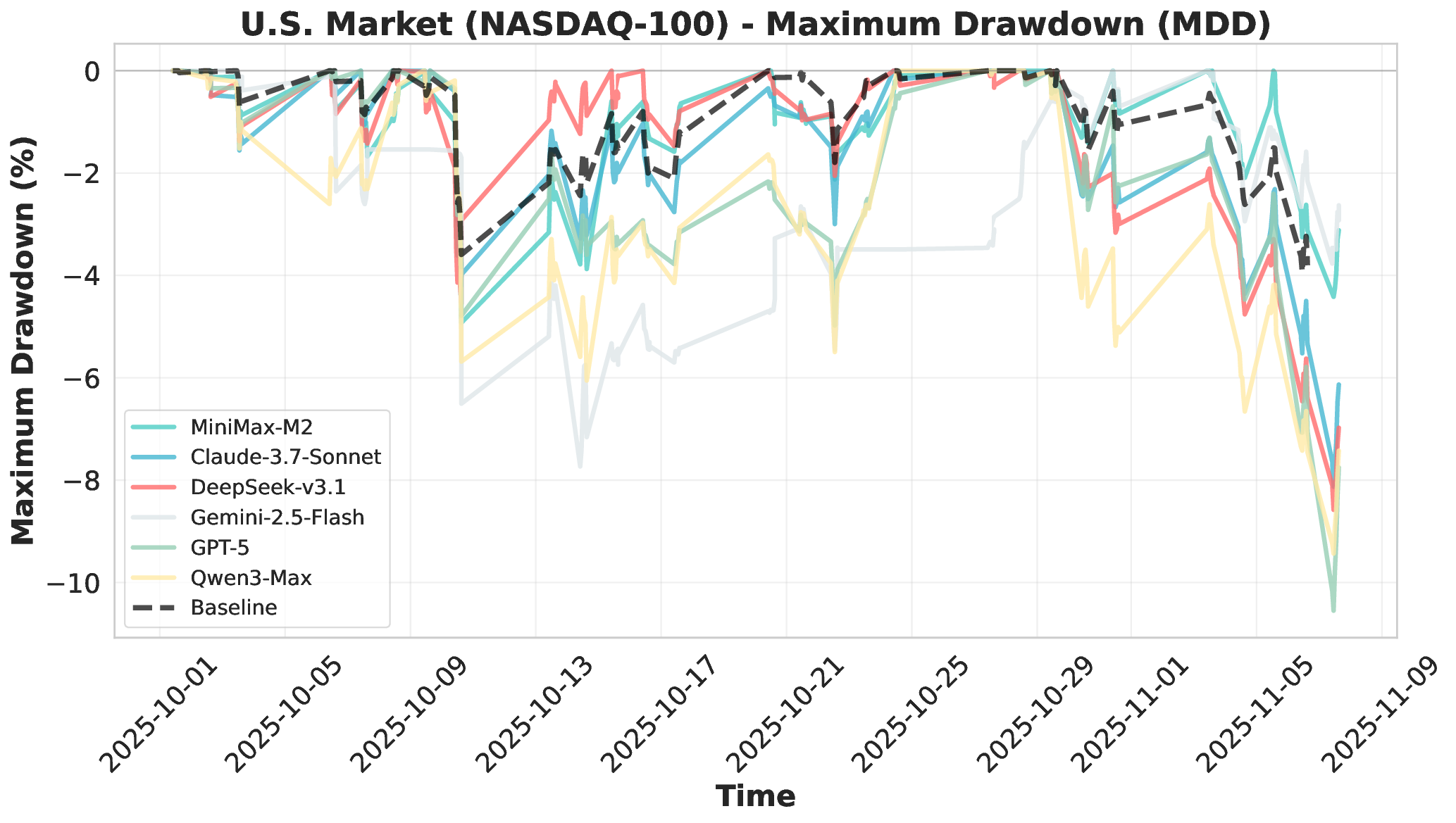
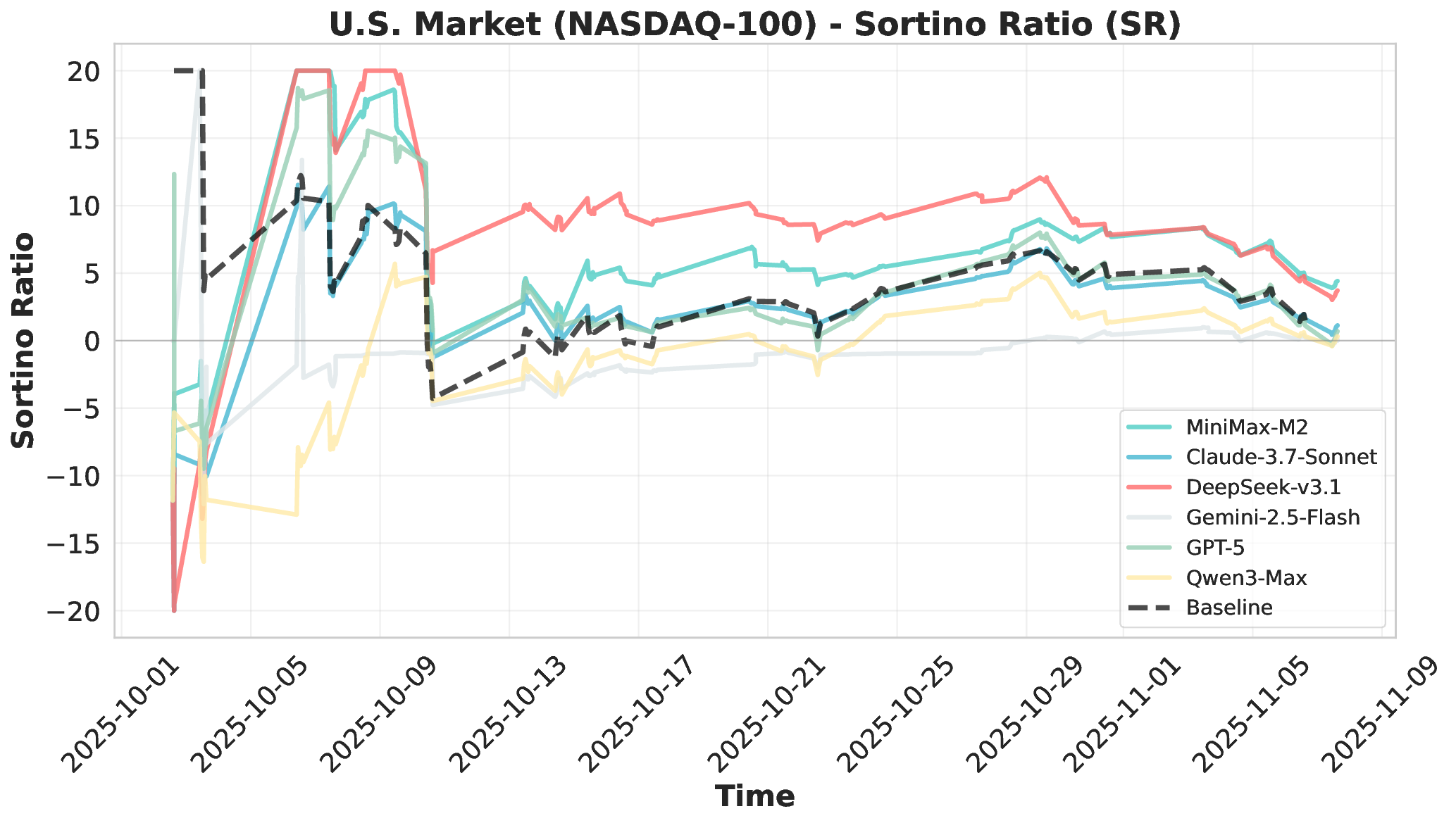
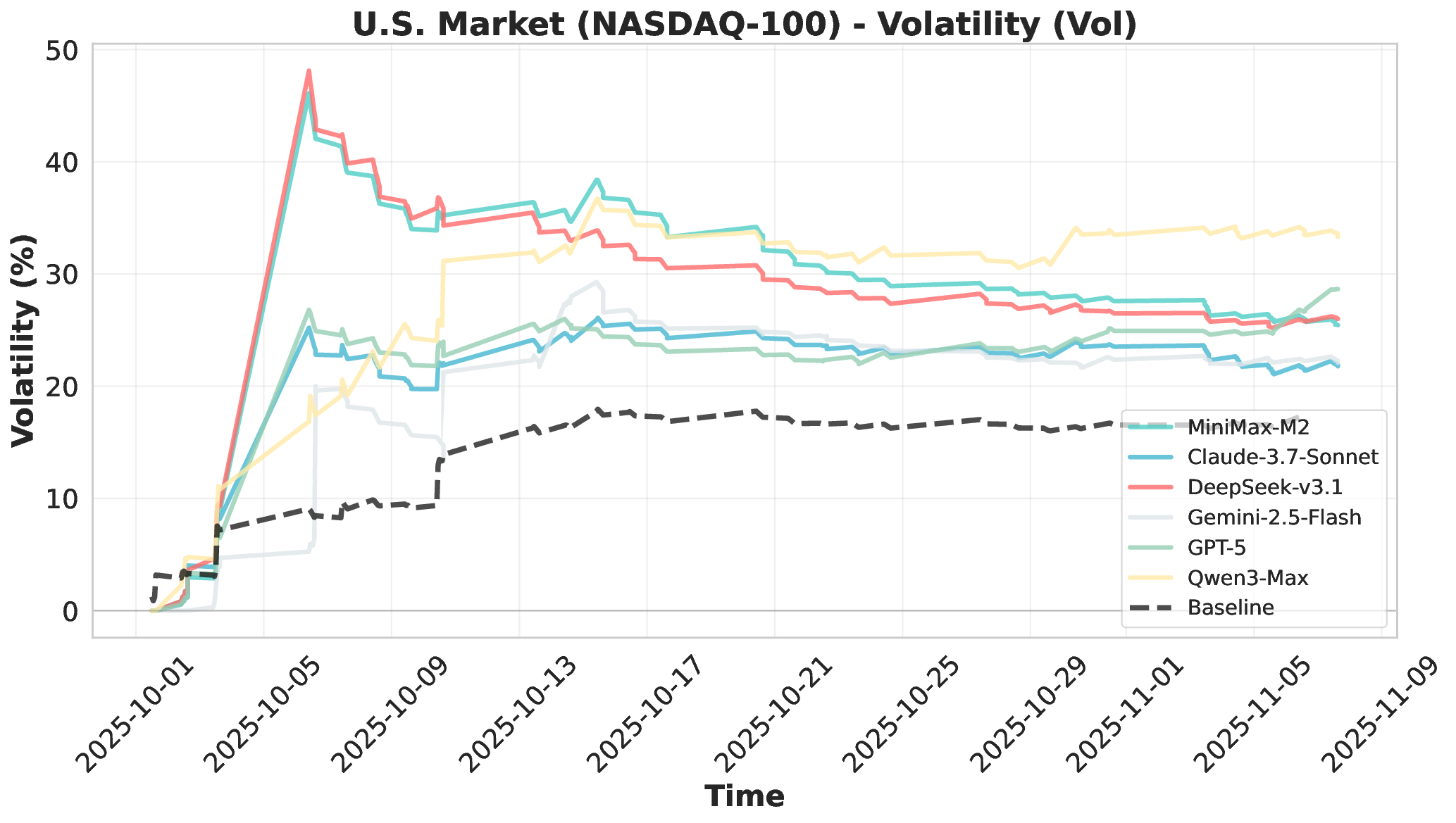
Financial markets present a stark contrast to these static evaluation environments. Unlike traditional benchmarks with fixed datasets, financial markets are inherently dynamic, continuous systems characterized by extreme volatility and unpredictable shifts. This dynamic complexity makes financial markets ideal testbeds for evaluating fundamental agent abilities including planning, information Our comprehensive evaluation across six mainstream LLMs reveals striking performance disparities. These critical limitations are invisible in static benchmarks. We demonstrate that general intelligence does not automatically translate to effective trading capability. Most agents exhibit poor returns and weak risk management in fully autonomous operations. Our analysis uncovers that AI trading strategies achieve excess returns more readily in highly liquid markets (U.S.) compared to policydriven environments (A-shares). Model generalization capabilities exhibit significant cross-market limitations when operating without human guidance. Key contributions of this work are as follows:
• First Fully Autonomous Live Multi-Market Evaluation Platform: We introduce the first financial evaluation benchmark that is completely agent-operated, real-time, and data-uncontaminated. Our platform spans U.S. equities, A-shares, and cryptocurrencies. It incorporates rigorous time consistency and information isolation mechanisms. This fundamentally breaks away from traditional static evaluation paradigms and establishes a new benchmark for autonomous agent assessment.
• End-to-End Autonomous Assessment Framework: Agents must independently search, verify, and synthesize live market information. They use only minimal context: current holdings, real-time prices, and available tools. This enables comprehensive evaluation of long-horizon tool utilization and adaptive reasoning. Decision-making capabilities are tested under genuine market constraints.
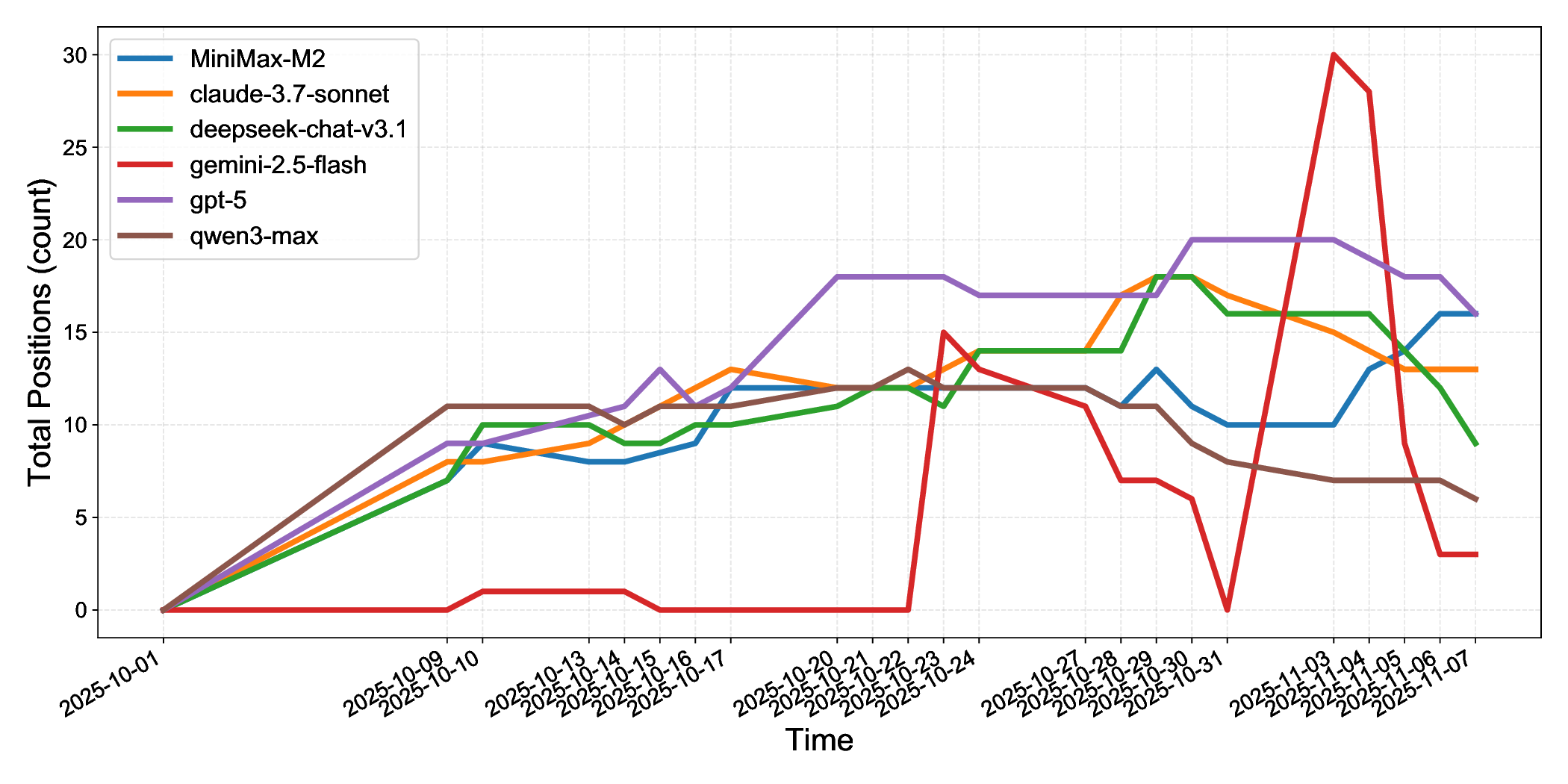
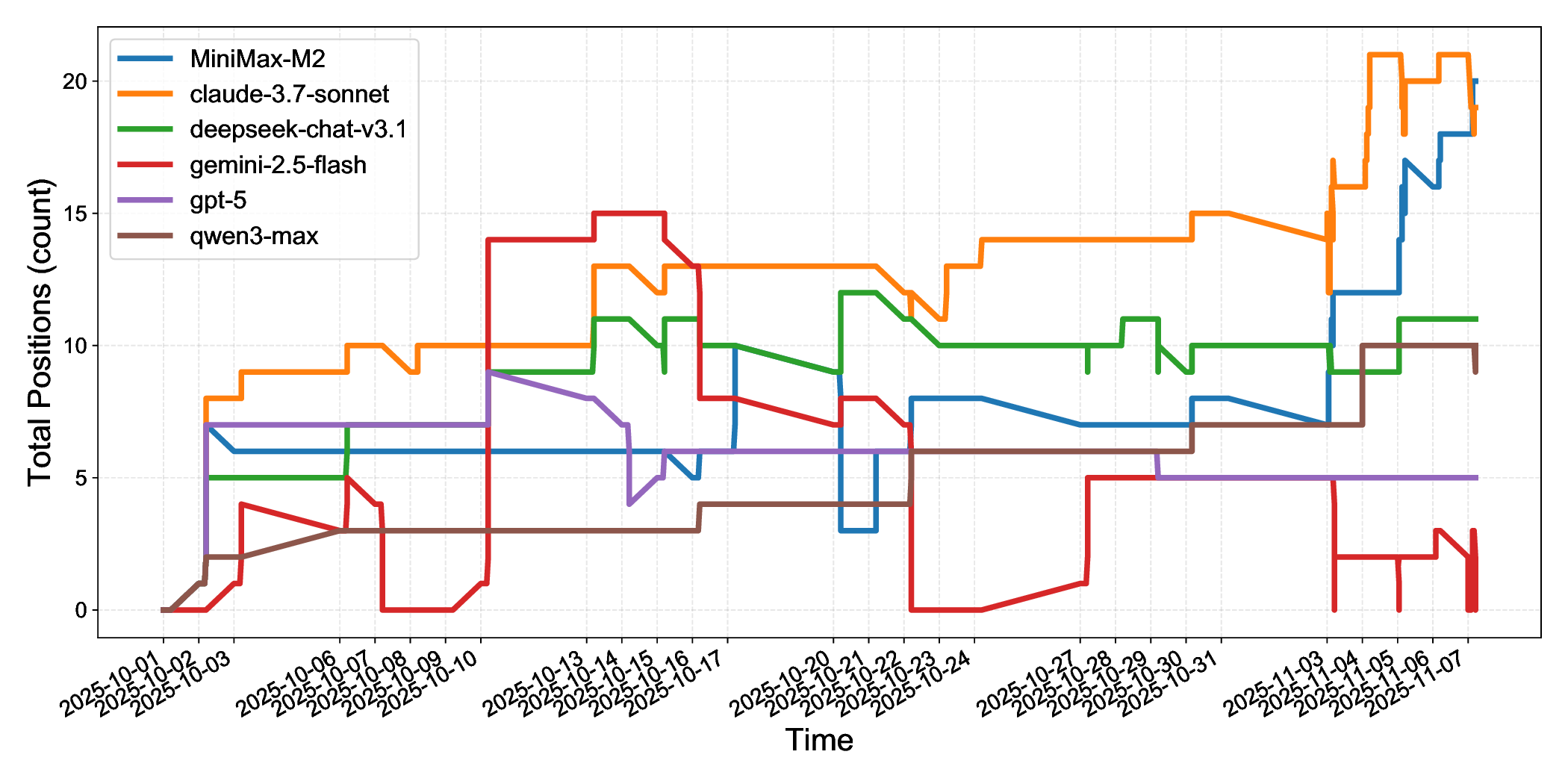
• Systematic Cross-Market Agent Capability Analysis: We evaluate six mainstream LLMs across three distinct markets and multiple trading frequencies. We systematically analyze performance in profitability, decision-making processes, and tool usage patterns. Our findings reveal critical limitations in autonomous execution, risk management, and cross-market generalization. These limitations are invisible in static benchmarks, highlighting the necessity for live evaluation.
• LLM Agents for Autonomous Decision-Making. Large language models have undergone a transformative evolution from powerful text-completion systems into autonomous agents. These systems are now capable of sophisticated reasoning, strategic planning, and dynamic interaction with external environments Anthropic (2025a;b); Yang et al. (2024); Tang et al. (2025); Xie et al. (2024);OpenAI (2023). This emergent agent capability represents the next frontier in LLM development. It directly bridges linguistic competence with tangible productivity and economic value in real-world applications (Patwardhan et al., 2025;Arora et al., 2025). The core strength of LLM agents lies in their capacity for long-horizon decision-making under uncertainty. They can maintain coherent strategies across extended time periods. Simultaneously, they adapt to evolving circumstances and complex environmental changes. AI-Trader leverages these advanced agent capabilities to enable autonomous decision-making in dynamic financial markets without human intervention.
• Tool Use and Environmental Interaction. To realize autonomous capabilities, LLM agents must interact with their environments through sophisticated tool use. This enables them to invoke external functions, APIs, and services to acquire real-time information, perform computations, and execute actions (Li, 2025;Mohammadi et al., 2025;Lu et al., 2025a). Tool use is fundamental to sustaining the perception-decision-action loop that defines autonomous agency (Yehudai et al., 2025;Raseed, 2025). Recent advances have accelerated this development significantly. Standardized protocols like the Model Context Protocol (MCP) (MCP, 2025) provide u
This content is AI-processed based on open access ArXiv data.