We study abstract visual composition, in which identity is primarily determined by the spatial configuration and relations among a small set of geometric primitives (e.g., parts, symmetry, topology). They are invariant primarily to texture and photorealistic detail. Composing such structures from fixed components under geometric constraints and vague goal specification (such as text) is non-trivial due to combinatorial placement choices, limited data, and discrete feasibility (overlap-free, allowable orientations), which create a sparse solution manifold ill-suited to purely statistical pixel-space generators. We propose a constraint-guided framework that combines explicit geometric reasoning with neural semantics. An AlphaGo-style search enforces feasibility, while a fine-tuned vision-language model scores semantic alignment as reward signals. Our algorithm uses a policy network as a heuristic in Monte-Carlo Tree Search and fine-tunes the network via search-generated plans. Inspired by the Generative Adversarial Network, we use the generated instances for adversarial reward refinement. Over time, the generation should approach the actual data more closely when the reward model cannot distinguish between generated instances and ground-truth. In the Tangram Assembly task, our approach yields higher validity and semantic fidelity than diffusion and auto-regressive baselines, especially as constraints tighten.
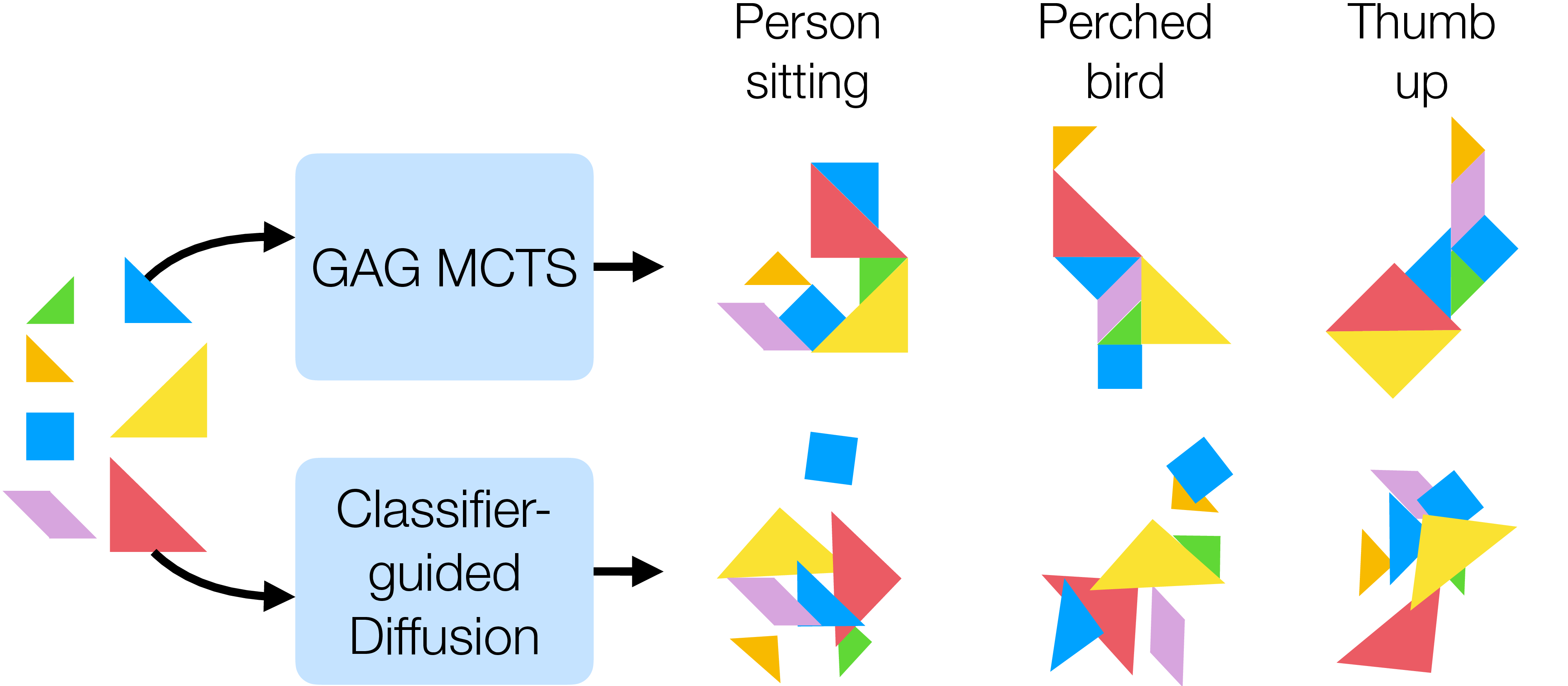
Abstract visual concepts, those defined by structural relations among primitives rather than by rich texture or appearance, underlie many forms of human reasoning, communication and design. For example, architectural blueprints, engineering schematics, iconography and signage compose meaning from simplified geometric forms across contexts. We therefore foreground visual composition: meaning emerges from how simple parts are arranged into struc-Figure 1. The Tangram assembly task. The seven pieces are placed on the board to form the target shape, described by the text prompt such as "perched bird". We show that our GAG MCTS can generate semantically aligned abstract visual concepts under hard constraints and limited data, while diffusion models perform poorly.
ture. We call a visual concept abstract when its identity is specified primarily by structural regularities over simple primitives (shape, part relations, closure, symmetry), consistent with structural accounts and Gestalt principles of perceptual organisation [3,50]. In this paper, we study composition explicitly by assembling fixed geometric pieces into target silhouettes or layouts from weak language cues (e.g., “bird,” “boat”), e.g., Tangram Assembly in Fig 1.
Composing with fixed pieces under geometric constraints differs fundamentally from naturalistic synthesis. First, feasibility is discrete and brittle: a single overlap or misalignment invalidates a composition; the feasible set is sparse and highly non-convex. Second, search is combinatorial: at each step, the system must choose which piece, where, and how to orient it while preserving future flexibility. Related packing/cutting problems are NP-hard even in simplified rectangular settings, underscoring intrinsic difficulty [16,22]. Third, semantics are underspecified: textual prompts imply global shape regularities without prescribing unique layouts. Data-driven generators trained to match pixel statistics (e.g., diffusion, latent diffusion) excel at appearance but struggle to guarantee hard constraints or discover valid layouts from limited supervision [19,42]. Object-centric auto-regressive transformer approaches ar-gue for compositional structure, but still lack exact constraint enforcement during synthesis [35].
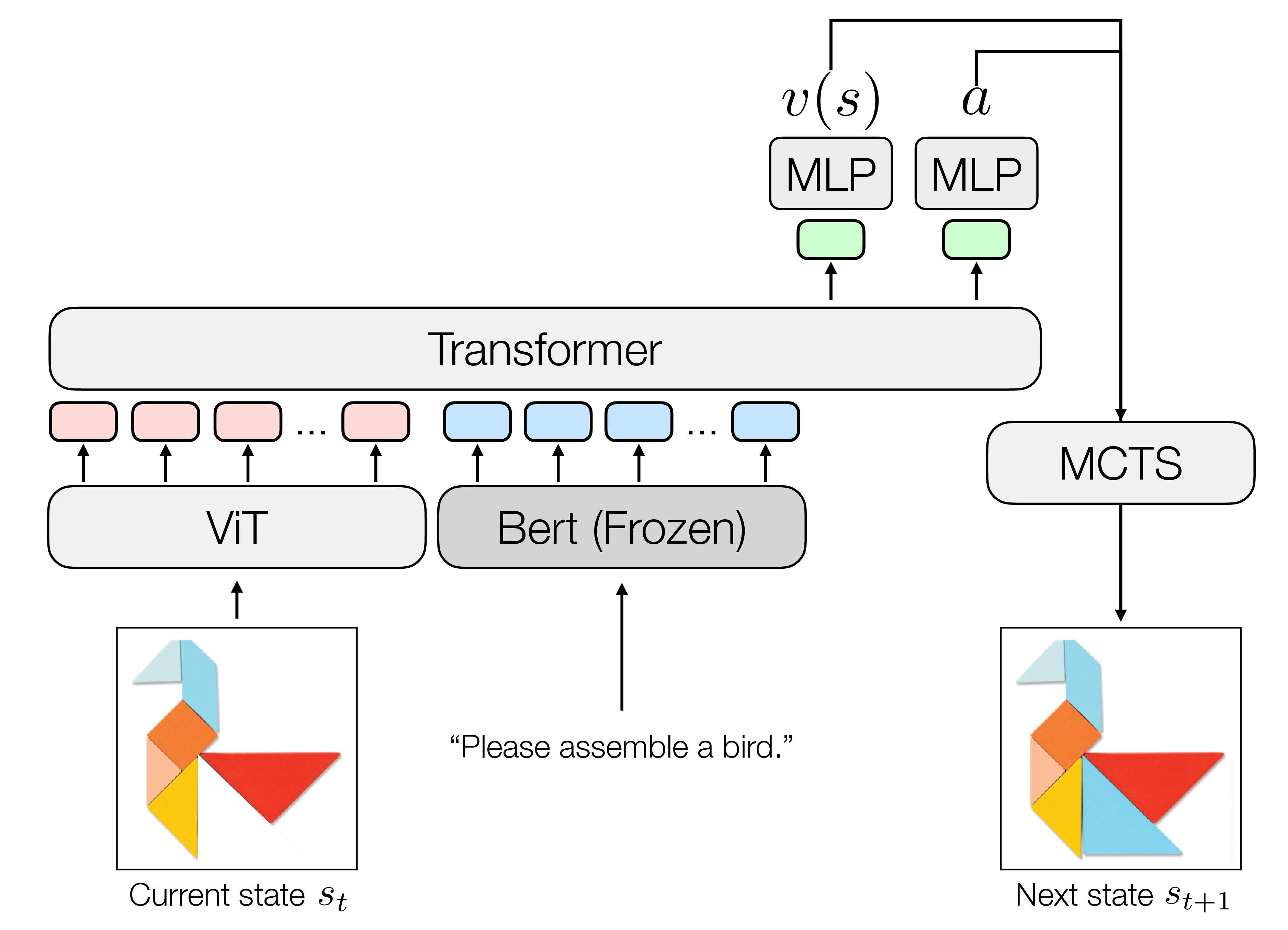
To address these challenges, we propose an AlphaGolike framework that integrates hard constraints into Monte Carlo Tree Search (MCTS) and employs a vision-language model to assess whether a generated configuration matches the textual goal. The key assumption is that validating an abstract visual composition is easier than learning to compose it directly. Prior work shows that fine-tuned visionlanguage models can reach human-level accuracy in recognising abstract tangram shapes [25], suggesting their suitability as reward models for evaluating candidate solutions.
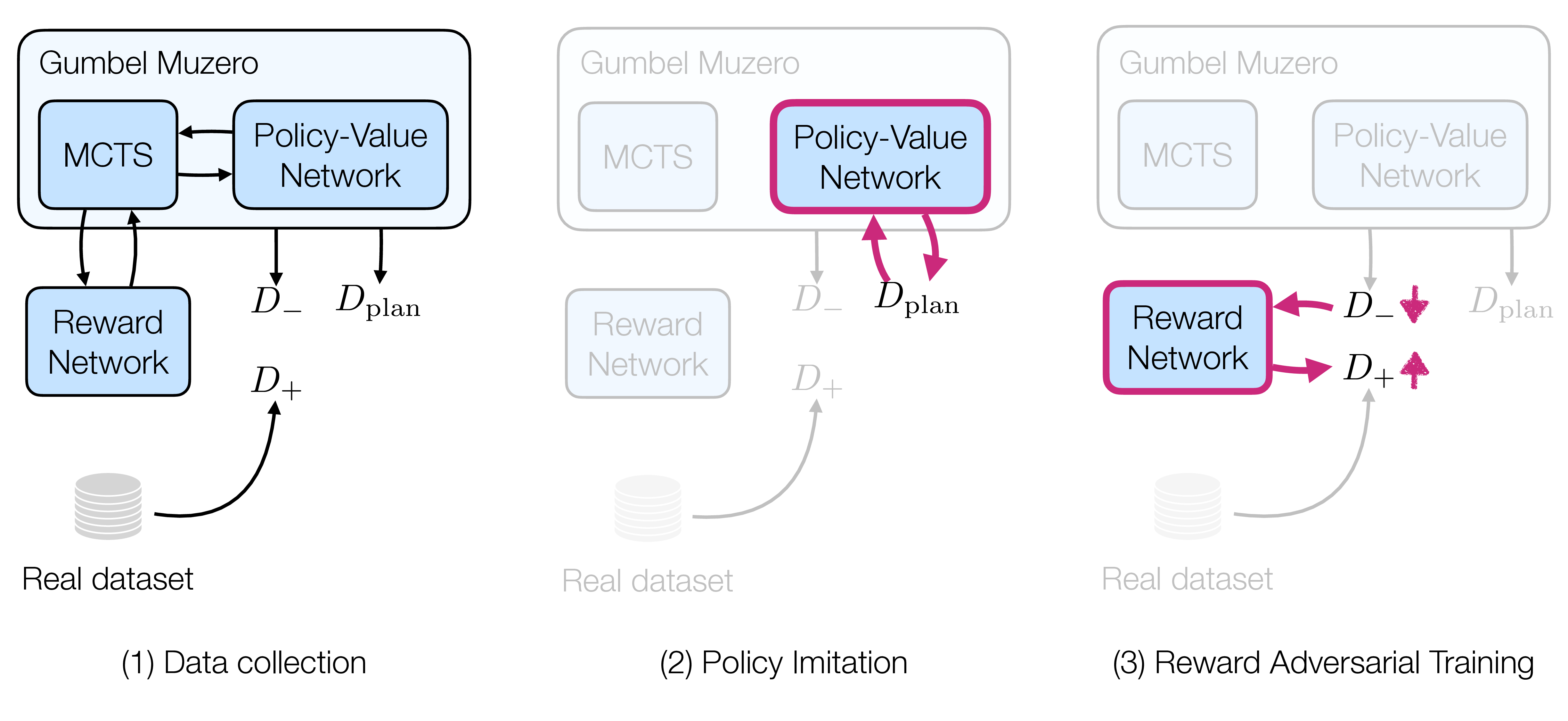
Our method adopts an AlphaGo-style algorithm [47], where hard constraints are embedded in the transition model to prune infeasible actions. A fine-tuned CLIP model [40] serves as the reward function, measuring the semantic alignment between the final assembly and the goal description. Because such scorers may be permissive or inconsistent on out-of-distribution samples, we introduce adversarial reward refinement to better distinguish valid from near-miss compositions. The policy guiding MCTS is trained using Proximal Policy Optimisation [45] (PPO) with the refined reward, and the resulting policy is further used to generate hard negative examples for continued adversarial reward refinement. This framework enhances sample efficiency through constraint-based pruning and improves semantic faithfulness by leveraging language-aligned visual features.
We evaluate on Tangram assembly: seven fixed pieces must depict a textual concept; this probes joint semantic and geometric competence. We found that methods without search are limited in generating semantically aligned abstract visual concepts. To better understand the issues, we relax the problem into a rectangle composition task, where a composition is semantically valid if all pieces lie within a bounded area of width and height specified by the text. We found that the diffusion model and PPO achieved great performance in generation with weak geometrical constraints, but performed poorly with tight geometrical constraints. Across both, the proposed search-based generator achieves higher geometric validity and semantic agreement than diffusion and autoregressive baselines, with gains increasing under tighter constraints [22].
In summary, we proposed a hybrid method combining constraint-aware search with language-aligned visual rewards and adversarial refinement, specifically for abstract visual composition under hard constraints and limited data. Our method performs substantially better in Tangram assembly and rectangle composition problems than diffusion, auto-regressive transformer, and PPO-based methods.
Abstract visual reasoning. Abstract visual concepts are intangib
This content is AI-processed based on open access ArXiv data.