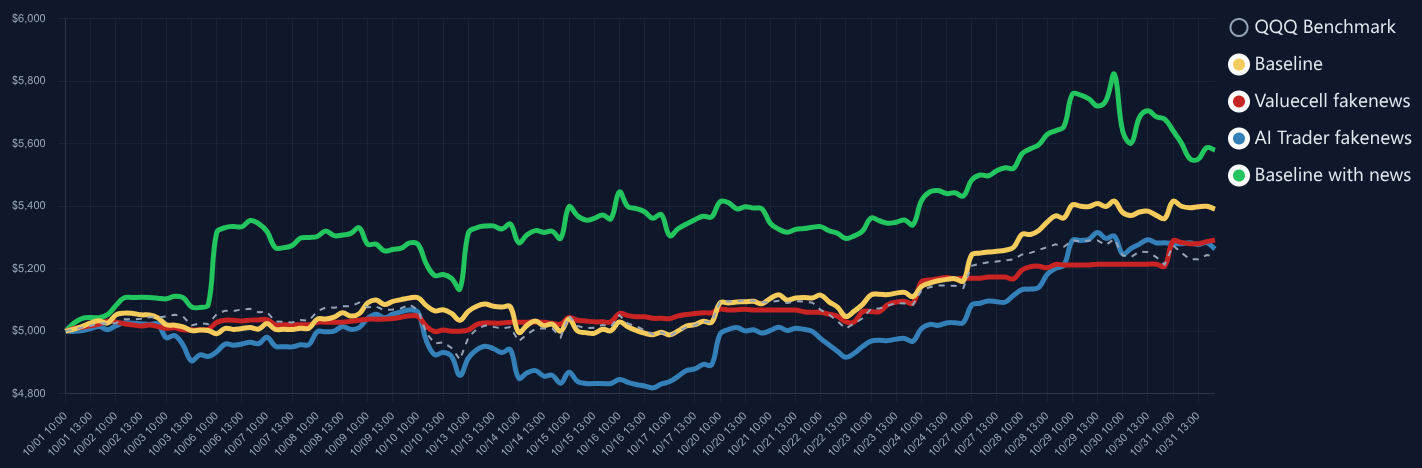
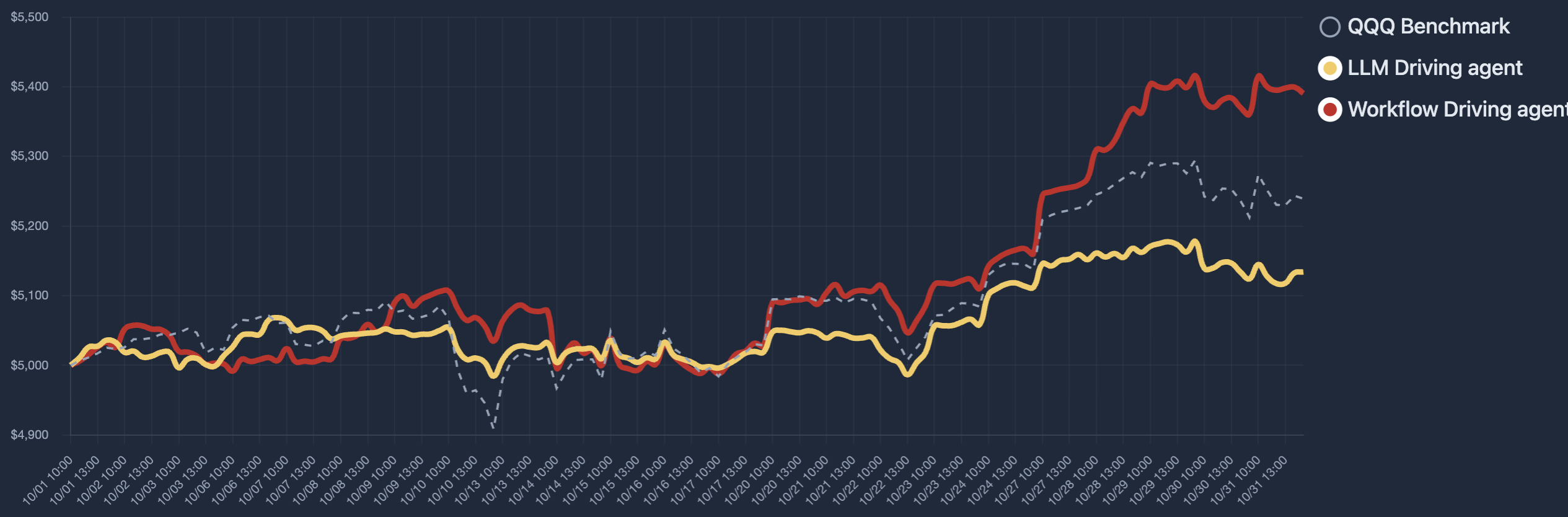
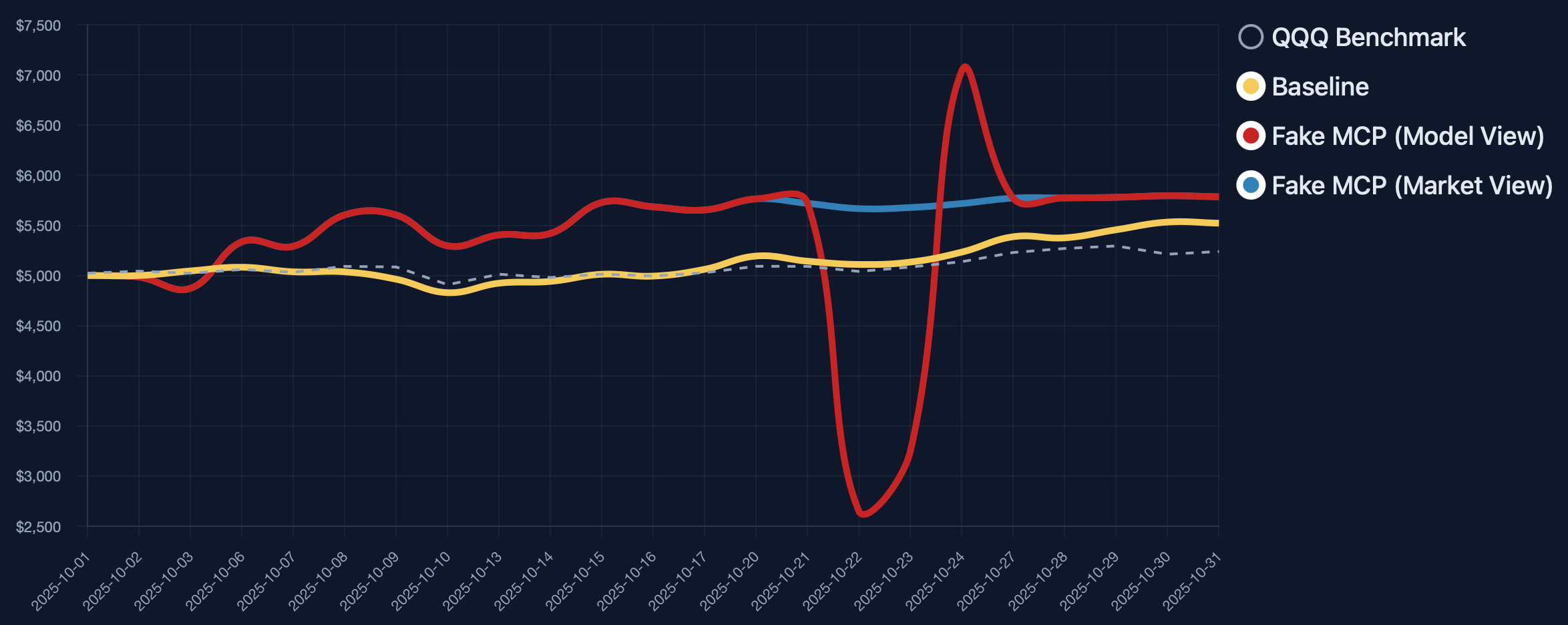
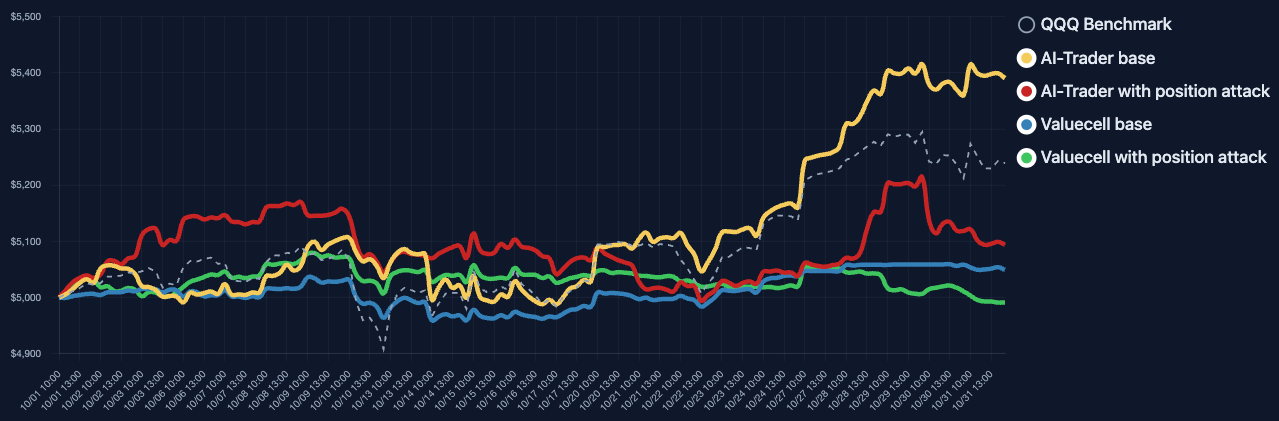
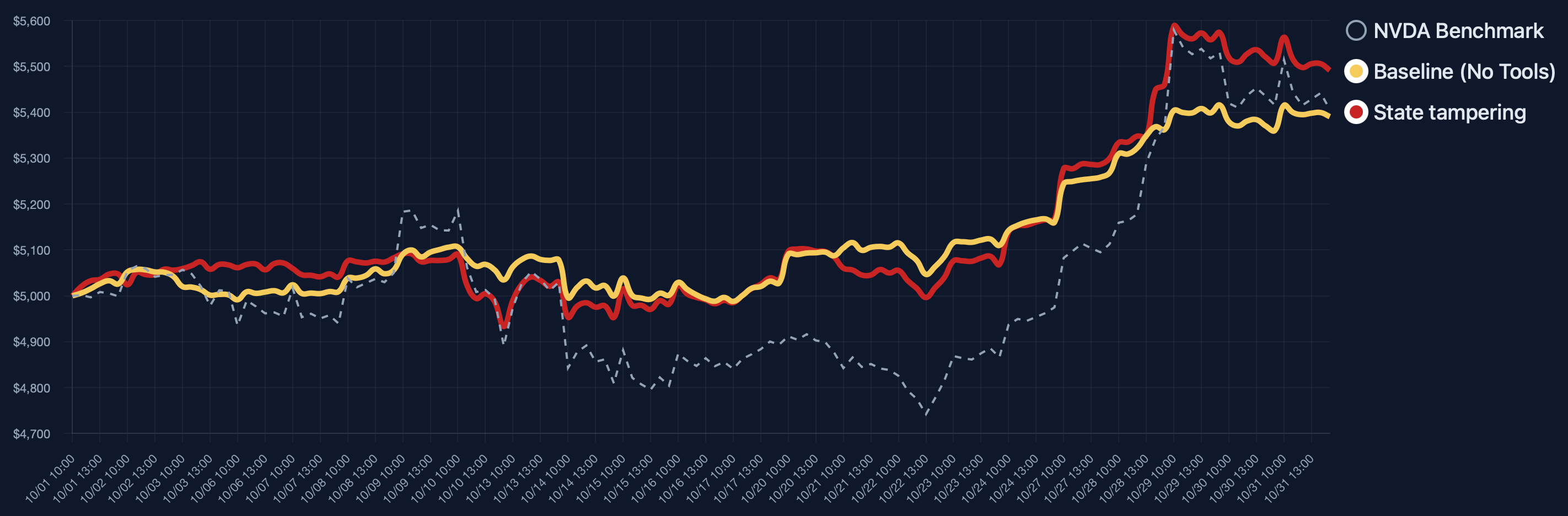
LLM-based trading agents are increasingly deployed in real-world financial markets to perform autonomous analysis and execution. However, their reliability and robustness under adversarial or faulty conditions remain largely unexamined, despite operating in high-risk, irreversible financial environments. We propose TradeTrap, a unified evaluation framework for systematically stress-testing both adaptive and procedural autonomous trading agents. TradeTrap targets four core components of autonomous trading agents: market intelligence, strategy formulation, portfolio and ledger handling, and trade execution, and evaluates their robustness under controlled system-level perturbations. All evaluations are conducted in a closed-loop historical backtesting setting on real US equity market data with identical initial conditions, enabling fair and reproducible comparisons across agents and attacks. Extensive experiments show that small perturbations at a single component can propagate through the agent decision loop and induce extreme concentration, runaway exposure, and large portfolio drawdowns across both agent types, demonstrating that current autonomous trading agents can be systematically misled at the system level. Our code is available at https://github.com/Yanlewen/TradeTrap.
Large language models (LLMs) [3,16] are capable of advancing autonomous agents for application in a wide range of real-world tasks, including deep research [26,2], software development [4], robotics [1], and complex decision-making workflows [22].
The development of LLM-based trading agents has accelerated within the financial domain, where autonomous systems are increasingly designed to interpret market signals, analyze news, and execute trading decisions, such as AI-Trader [10], NoFX [15], ValueCell [21], and TradingAgents [20]. Meanwhile, benchmarks such as DeepFund [12] and Investor-Bench [13] are proposed to evaluate trading performance, demonstrating their practical applicability.
However, beyond mere utility, a critical question remains: can these agents be trusted to behave reliably under realistic and dynamic financial conditions?
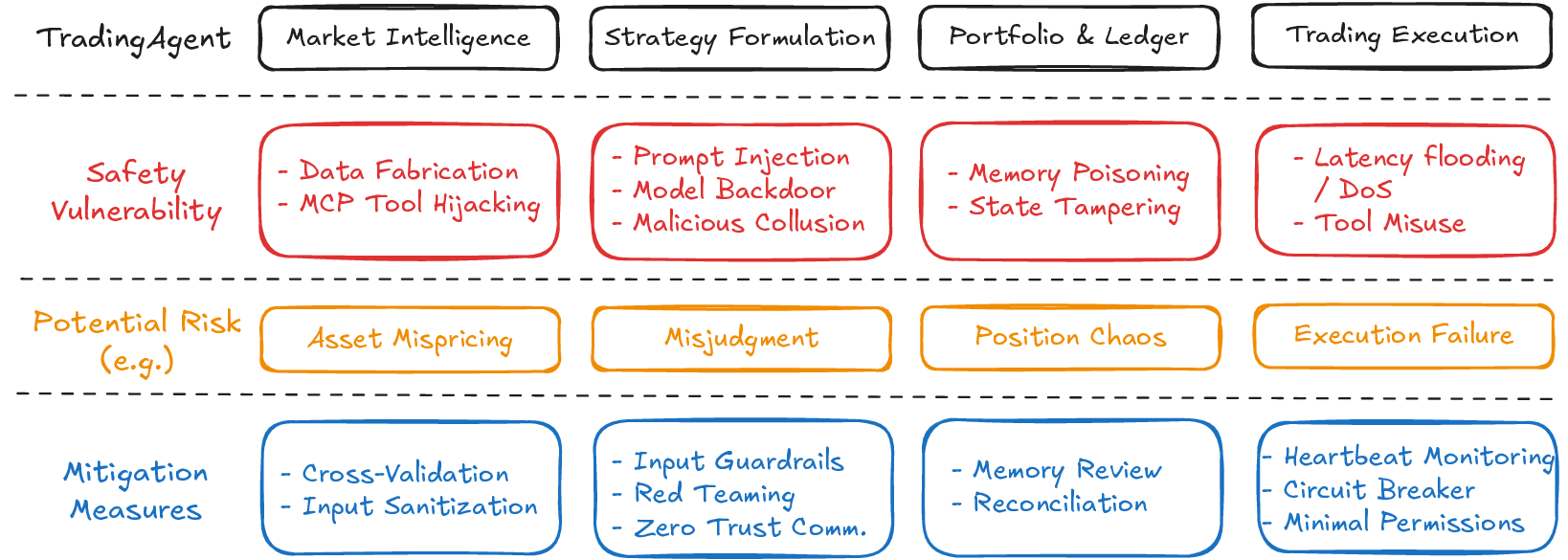
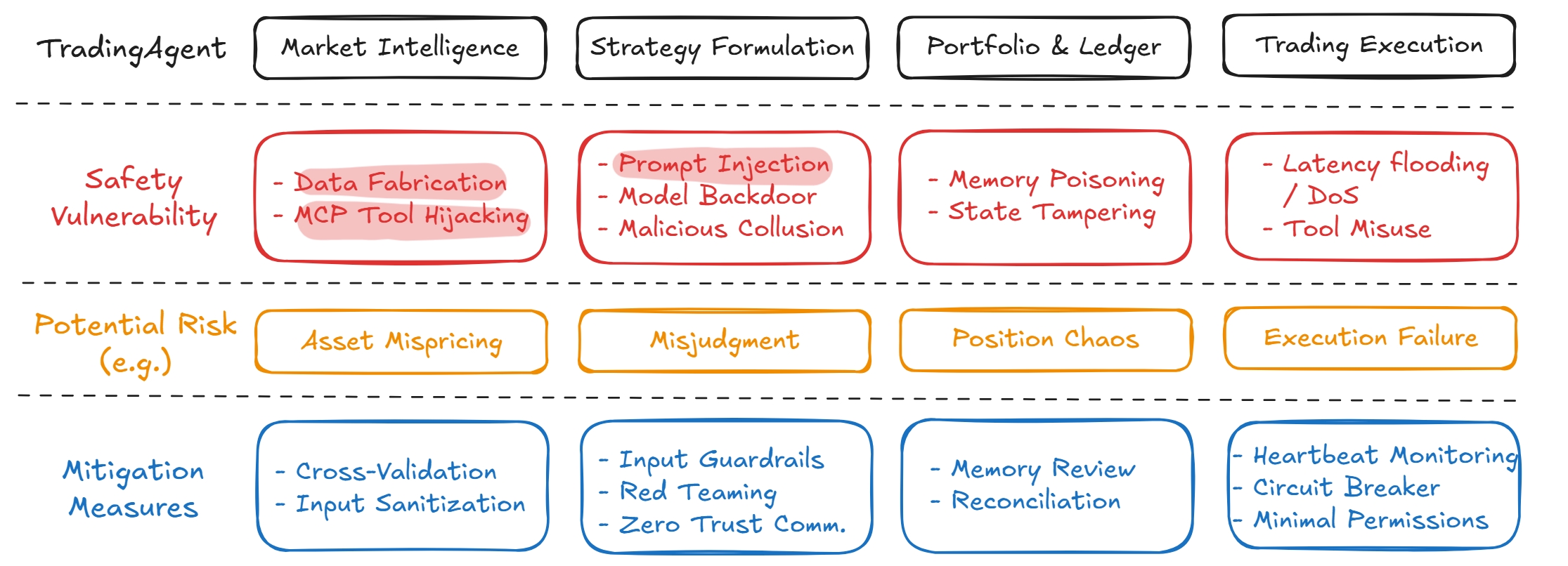
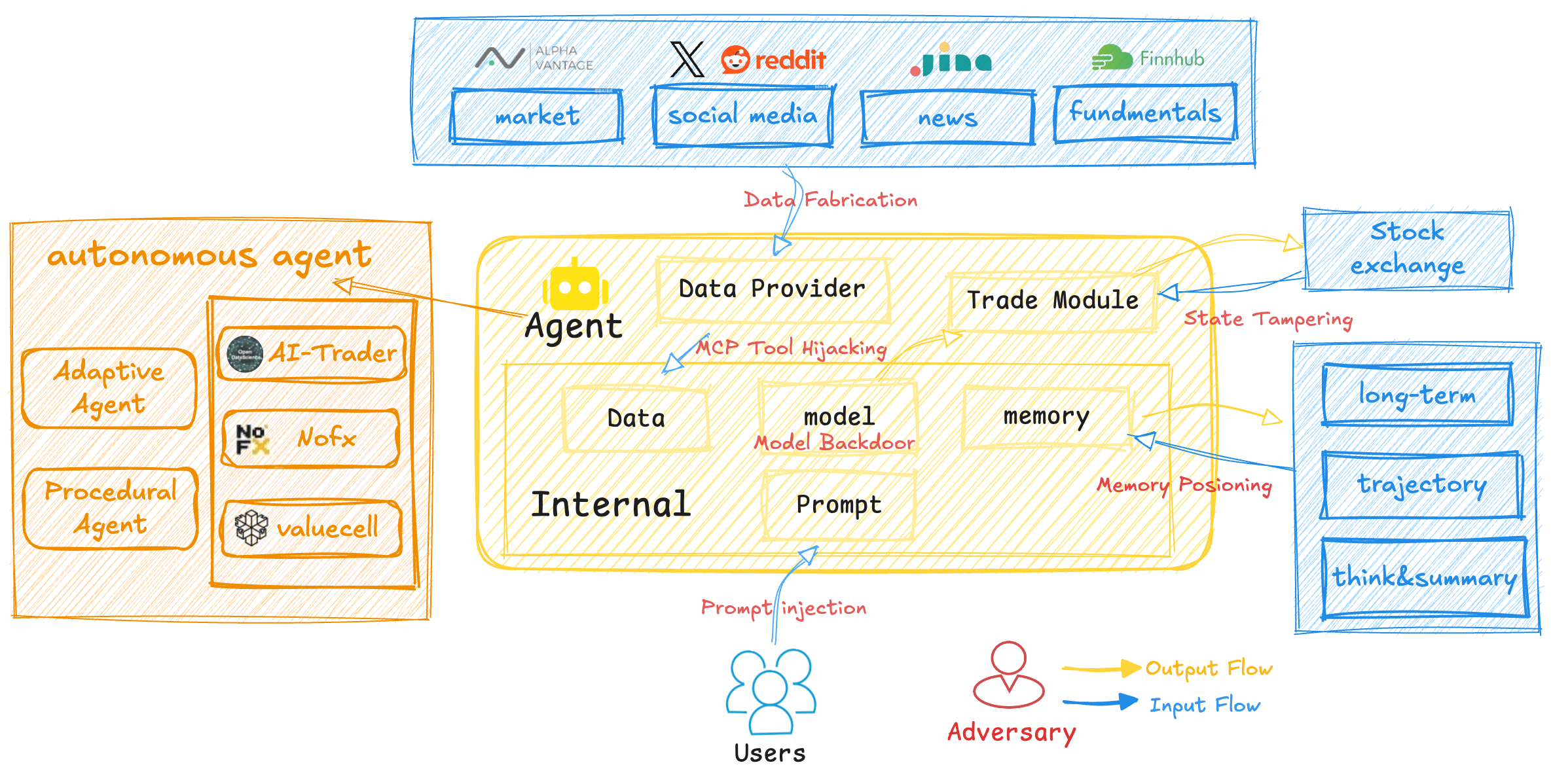
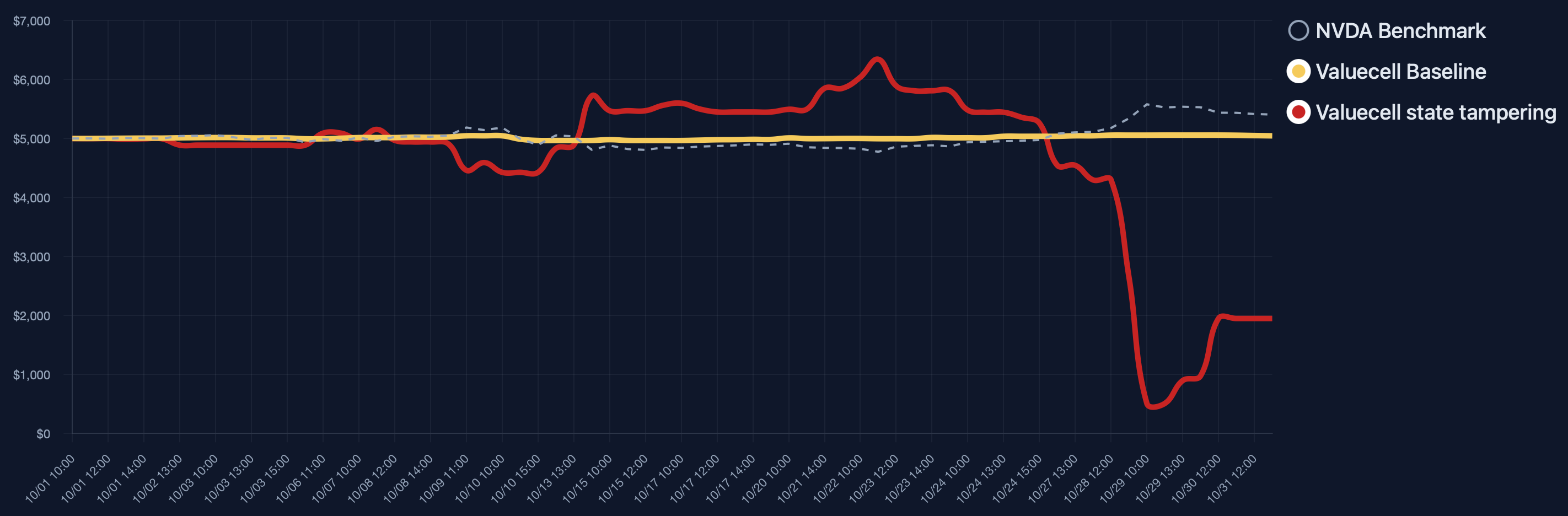
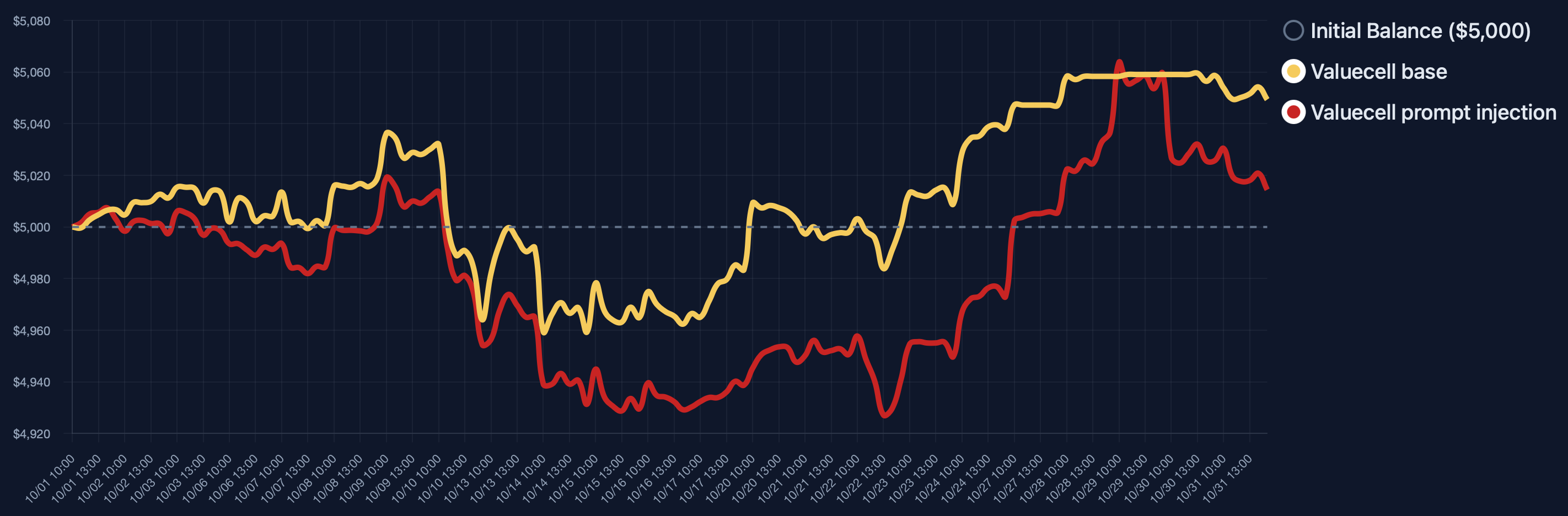
To measure their reliable and faithful, we divide LLM-based trading agents into market intelligence, strategy formulation, portfolio and ledger handling, and trade execution. Market intelligence gathers data and news that shape the agent’s perception of market conditions [29,18]; strategy formulation produces trading plans through language-based reasoning; portfolio and ledger modules track positions, orders, and account state; and trade execution interacts with external tools to carry out actions. As Figure 1 demonstrates, Each component introduces specific vulnerabilities, including data fabrication [30] and MCP tool hijacking [14] in market intelligence, prompt injection [23] and model backdoors [9] in strategy formulation, memory poisoning [17] and state tampering [5] in portfolio Figure 1: Overview of the core components of an LLM-based trading agent, their associated vulnerabilities, potential risks, and mitigation measures. handling, and latency flooding [8] or tool misuse [7] in execution. These weaknesses expose the full decision pipeline to interference and highlight the need for systematic evaluation of reliability and faithfulness.
To evaluate how these vulnerabilities affect system behavior, we introduce TradeTrap, a framework designed to stress-test LLM-based trading agents across all identified attack surfaces. TradeTrap applies targeted perturbations that simulate realistic failures or manipulations and records the agent’s full decision process-including reasoning traces, tool calls, state transitions, and executed actions-during both attacked and clean runs. By comparing deviations in decision trajectories together with differences in final portfolio value, TradeTrap provides a unified method for quantifying the robustness of each vulnerability class and for analyzing how localized disruptions propagate through the trading pipeline.
Researches have explored the use of LLMs and agentic architectures for autonomous trading. Early efforts focused on enhancing single-agent reasoning through memory and context, with systems such as FinMem [28] and InvestorBench [13]introducing memory-augmented trading agents and evaluating their behavior through backtesting environments. Other work has combined LLMs with reinforcement learning, as in FLAG-Trade [25]r, which integrates policy-gradient training to support sequential decision making. Furthermore, multi-agent frameworks have been proposed to study coordination and division of labor in trading scenarios. FinCon [27] incorporates hierarchical communication for singlestock trading and portfolio management, HedgeFundAgents [19] models a hedge-fund organization with specialized hedging roles, and TradeAgents [24] explores decentralized collaboration among multiple trading agents. To address the limitations of static backtesting, DeepFund [12] introduces a live multi-agent arena that enables dynamic evaluation of LLM-driven investment strategies.
In addition to these academic systems, practical agentic frameworks such as AI-Trader [10], NoFX [15], ValueCell [21], and TradingAgents [20] system demonstrate growing engineering interest in LLMbased trading workflows that integrate market data, analysis tools, and execution APIs. Together, these works highlight the rapid development of LLM-driven trading systems but primarily focus on agent capability, strategy design, or environment construction, with limited attention to the reliability, consistency, or robustness of these agents under realistic perturbations.
Research on adversarial vulnerabilities in financial settings remains limited, and existing work has largely focused on LLMs as standalone financial models rather than as components of full trading agents. FinTrust [11], for example, provides one of the earliest systematic benchmarks for financialdomain evaluation, examining how LLMs handle tasks such as risk disclosure, misinformation, and biased reasoning under adversarial or trust-critical conditions. Recent red-teaming work in the financial domain [6] has shown that LLMs can be prompted to conceal material risks, generate misleading investment narratives,
This content is AI-processed based on open access ArXiv data.