Legal AI systems powered by retrieval-augmented generation (RAG) face a critical accountability challenge: when an AI assistant cites case law, statutes, or contractual clauses, practitioners need verifiable guarantees that generated text faithfully represents source documents. Existing hallucination detectors rely on semantic similarity metrics that tolerate entity substitutions, a dangerous failure mode when confusing parties, dates, or legal provisions can have material consequences. We introduce HalluGraph, a graph-theoretic framework that quantifies hallucinations through structural alignment between knowledge graphs extracted from context, query, and response. Our approach produces bounded, interpretable metrics decomposed into \textit{Entity Grounding} (EG), measuring whether entities in the response appear in source documents, and \textit{Relation Preservation} (RP), verifying that asserted relationships are supported by context. On structured control documents, HalluGraph achieves near-perfect discrimination ($>$400 words, $>$20 entities), HalluGraph achieves $AUC = 0.979$, while maintaining robust performance ($AUC \approx 0.89$) on challenging generative legal task, consistently outperforming semantic similarity baselines. The framework provides the transparency and traceability required for high-stakes legal applications, enabling full audit trails from generated assertions back to source passages.
💡 Deep Analysis
📄 Full Content
HalluGraph: Auditable Hallucination Detection for Legal RAG
Systems via Knowledge Graph Alignment
Valentin No¨el
Devoteam
valentin.noel@devoteam.com
Elimane Yassine Sedou
Devoteam
elimane.yassine.seidou@devoteam.com
Charly Ken Capo-Chichi
Devoteam
charly.ken.capo-chichi@devoteam.com
Ghanem Amari
Devoteam
ghanem.amari@devoteam.com
Under review (2025)
Abstract
Legal AI systems powered by retrieval-augmented generation (RAG) face a critical accountability
challenge: when an AI assistant cites case law, statutes, or contractual clauses, practitioners need verifiable
guarantees that generated text faithfully represents source documents. Existing hallucination detectors
rely on semantic similarity metrics that tolerate entity substitutions, a dangerous failure mode when
confusing parties, dates, or legal provisions can have material consequences. We introduce HalluGraph, a
graph-theoretic framework that quantifies hallucinations through structural alignment between knowledge
graphs extracted from context, query, and response. Our approach produces bounded, interpretable metrics
decomposed into Entity Grounding (EG), measuring whether entities in the response appear in source
documents, and Relation Preservation (RP), verifying that asserted relationships are supported by context.
On structured control documents, HalluGraph achieves near-perfect discrimination (>400 words, >20
entities), HalluGraph achieves AUC = 0.979, while maintaining robust performance (AUC ≈0.89) on
challenging generative legal task, consistently outperforming semantic similarity baselines. The framework
provides the transparency and traceability required for high-stakes legal applications, enabling full audit
trails from generated assertions back to source passages. Code and dataset will be made available upon
admission.
1
Introduction
The deployment of large language models (LLMs) in legal practice introduces accountability requirements
absent in general-purpose applications. To build trustworthy AI for such high-stakes decision-making in
justice systems, systems must support professional responsibility through rigorous verification. When an AI
system summarizes a court opinion or extracts obligations from a contract, errors are not merely inconvenient:
misattributed holdings, fabricated citations, or confused parties can expose practitioners to malpractice
liability and undermine judicial processes [3].
Retrieval-augmented generation (RAG) systems partially address hallucination by grounding responses
in retrieved documents [9]. However, RAG does not guarantee faithful reproduction. A model may retrieve
the correct statute but hallucinate provisions, or cite a valid case while misrepresenting its holding. Post-hoc
1
arXiv:2512.01659v1 [cs.LG] 1 Dec 2025
Legal Document
Gc
Query
Gq
Triple Extraction
(SLM)
→(s, r, o)
Response
Ga
EG, RP, CFI
Bounded
[0, 1]
Decision
+ Audit
Trail
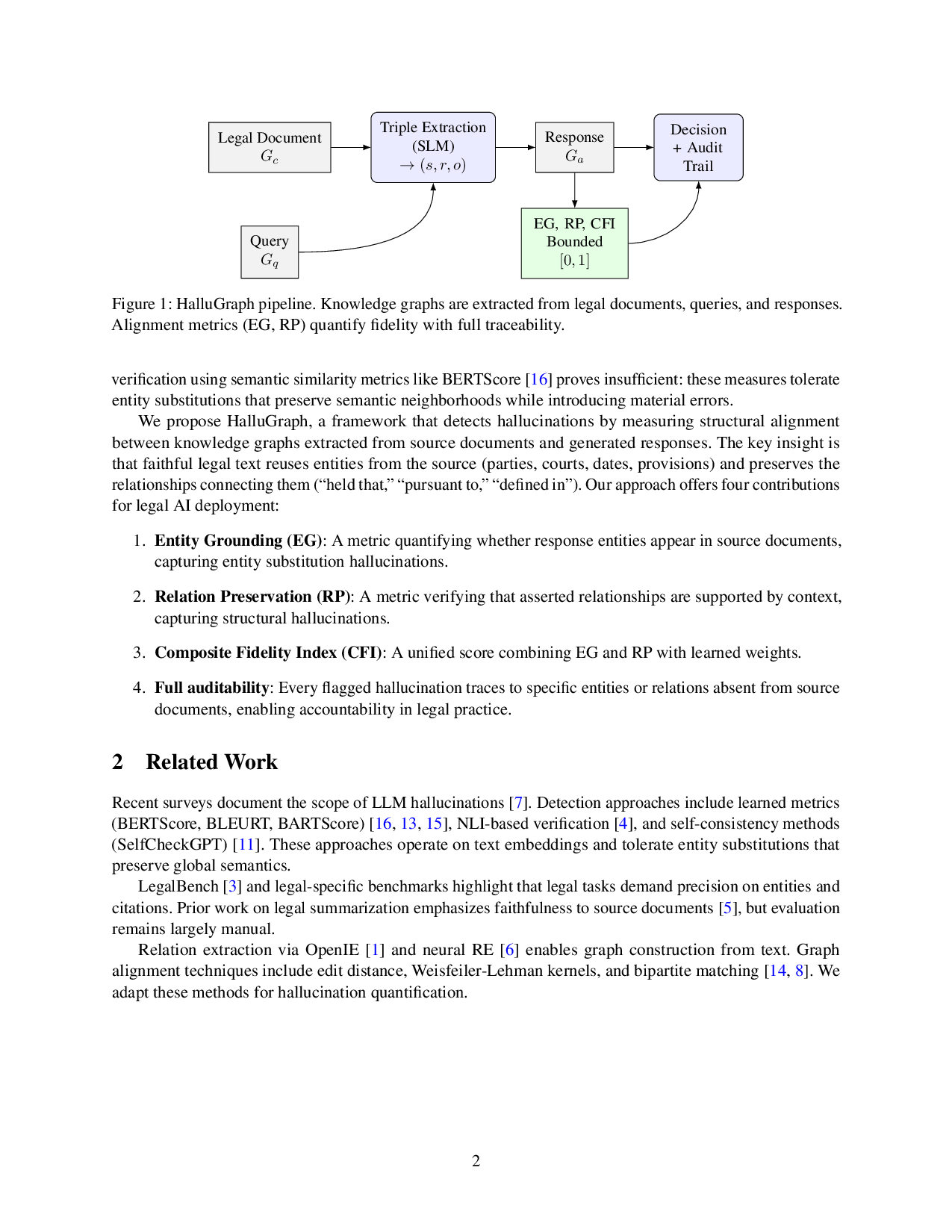
Figure 1: HalluGraph pipeline. Knowledge graphs are extracted from legal documents, queries, and responses.
Alignment metrics (EG, RP) quantify fidelity with full traceability.
verification using semantic similarity metrics like BERTScore [16] proves insufficient: these measures tolerate
entity substitutions that preserve semantic neighborhoods while introducing material errors.
We propose HalluGraph, a framework that detects hallucinations by measuring structural alignment
between knowledge graphs extracted from source documents and generated responses. The key insight is
that faithful legal text reuses entities from the source (parties, courts, dates, provisions) and preserves the
relationships connecting them (“held that,” “pursuant to,” “defined in”). Our approach offers four contributions
for legal AI deployment:
1. Entity Grounding (EG): A metric quantifying whether response entities appear in source documents,
capturing entity substitution hallucinations.
2. Relation Preservation (RP): A metric verifying that asserted relationships are supported by context,
capturing structural hallucinations.
3. Composite Fidelity Index (CFI): A unified score combining EG and RP with learned weights.
4. Full auditability: Every flagged hallucination traces to specific entities or relations absent from source
documents, enabling accountability in legal practice.
2
Related Work
Recent surveys document the scope of LLM hallucinations [7]. Detection approaches include learned metrics
(BERTScore, BLEURT, BARTScore) [16, 13, 15], NLI-based verification [4], and self-consistency methods
(SelfCheckGPT) [11]. These approaches operate on text embeddings and tolerate entity substitutions that
preserve global semantics.
LegalBench [3] and legal-specific benchmarks highlight that legal tasks demand precision on entities and
citations. Prior work on legal summarization emphasizes faithfulness to source documents [5], but evaluation
remains largely manual.
Relation extraction via OpenIE [1] and neural RE [6] enables graph construction from text. Graph
alignment techniques include edit dista