Large language model based agents are increasingly deployed in complex, tool augmented environments. While reinforcement learning provides a principled mechanism for such agents to improve through interaction, its effectiveness critically depends on the availability of structured training tasks. In many realistic settings, however, no such tasks exist a challenge we term task scarcity, which has become a key bottleneck for scaling agentic RL. Existing approaches typically assume predefined task collections, an assumption that fails in novel environments where tool semantics and affordances are initially unknown. To address this limitation, we formalize the problem of Task Generation for Agentic RL, where an agent must learn within a given environment that lacks predefined tasks. We propose CuES, a Curiosity driven and Environment grounded Synthesis framework that autonomously generates diverse, executable, and meaningful tasks directly from the environment structure and affordances, without relying on handcrafted seeds or external corpora. CuES drives exploration through intrinsic curiosity, abstracts interaction patterns into reusable task schemas, and refines them through lightweight top down guidance and memory based quality control. Across three representative environments, AppWorld, BFCL, and WebShop, CuES produces task distributions that match or surpass manually curated datasets in both diversity and executability, yielding substantial downstream policy improvements. These results demonstrate that curiosity driven, environment grounded task generation provides a scalable foundation for agents that not only learn how to act, but also learn what to learn. The code is available at https://github.com/modelscope/AgentEvolver/tree/main/research/CuES.
Large language model (LLM)-based agents are increasingly deployed in complex, tool-augmented environments such as graphical user interfaces and open-ended web platforms (Shang et al., 2025;Li et al., 2025b). Reinforcement learning (RL) provides a principled mechanism for such agents to improve their policies through interaction and feedback (Mai et al., 2025;Lin et al., 2025). However, in many realistic environments, no explicit training tasks are available. The agent can interact with the environment, but it lacks a structured set of tasks on which it can sample experience and perform RL optimization (Cheng et al., 2024;Zhang et al., 2024). As a result, this task scarcity has become a major bottleneck for scaling RL-based agent learning.
Existing approaches to agentic RL typically assume that a collection of training tasks is already provided (Gao et al., 2024;Yu et al., 2025;Chinta & Karaka, 2020). These assumptions hold in controlled benchmarks but fail in novel environments, where tool semantics and affordances are initially unknown. In such cases, constructing a sufficiently diverse and executable set of tasks by hand is both costly and brittle, and the absence of such tasks leaves the agent without a foundation for effective learning (Zhang et al., 2025;Zeng et al., 2025). Consequently, the lack of training tasks-not the lack of algorithms-often limits progress in agentic RL (Plaat et al., 2025;Singh et al., 2025;Sapkota et al., 2025).
To address this fundamental limitation (Shi et al., 2025;Team et al., 2025), we focus on the overlooked yet essential setting of training an agent within a given environment when no tasks are predefined. Specifically, we aim to answer the following question: Given an interactive environment but no predefined training tasks, how can an agent autonomously generate diverse, solvable, and useful tasks that enable effective policy learning? To this end, we first formulate and define the task generation problem for such environment-conditioned learning. We conceptualize task generation as the process of constructing a meaningful and solvable set of tasks directly from the environment’s structure and affordances, thereby bridging the gap between the environment and the agent’s learning process. This formulation establishes task generation as a first-class research problem in the development of self-improving LLM-based agents.
Building on this formulation, we propose CuES, a Curiosity-driven and Environment-grounded Synthesis framework for autonomous task generation. CuES operates without handcrafted seed goals or external corpora. It drives the agent to explore the environment under intrinsic curiosity, abstracts discovered interaction patterns into reusable task schemas, and refines them using lightweight top-down guidance and memory-based quality control. Through this process, CuES generates executable and diverse training tasks that are naturally aligned with the agent’s learning needs, thereby enabling continual and scalable improvement through RL.
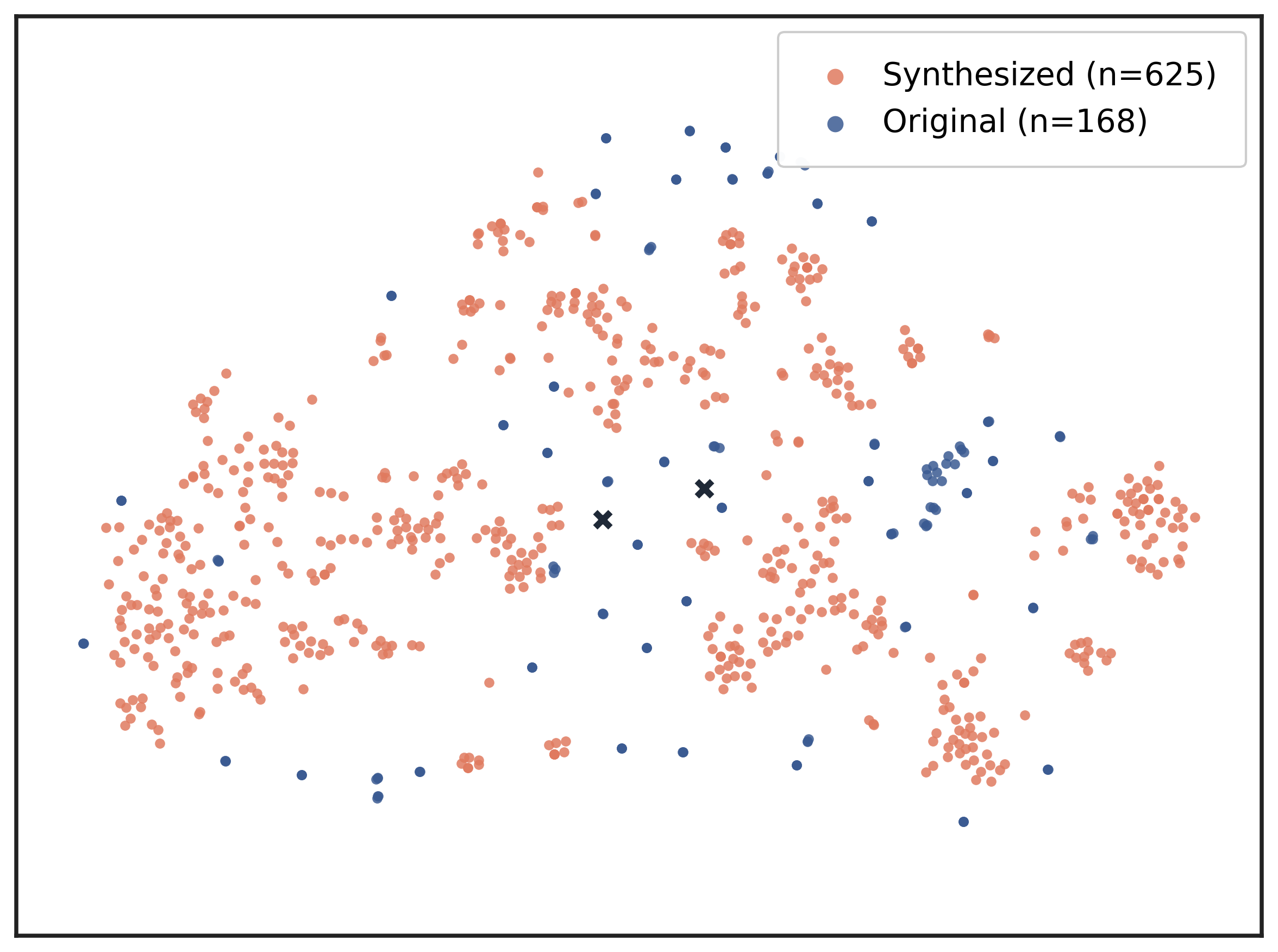
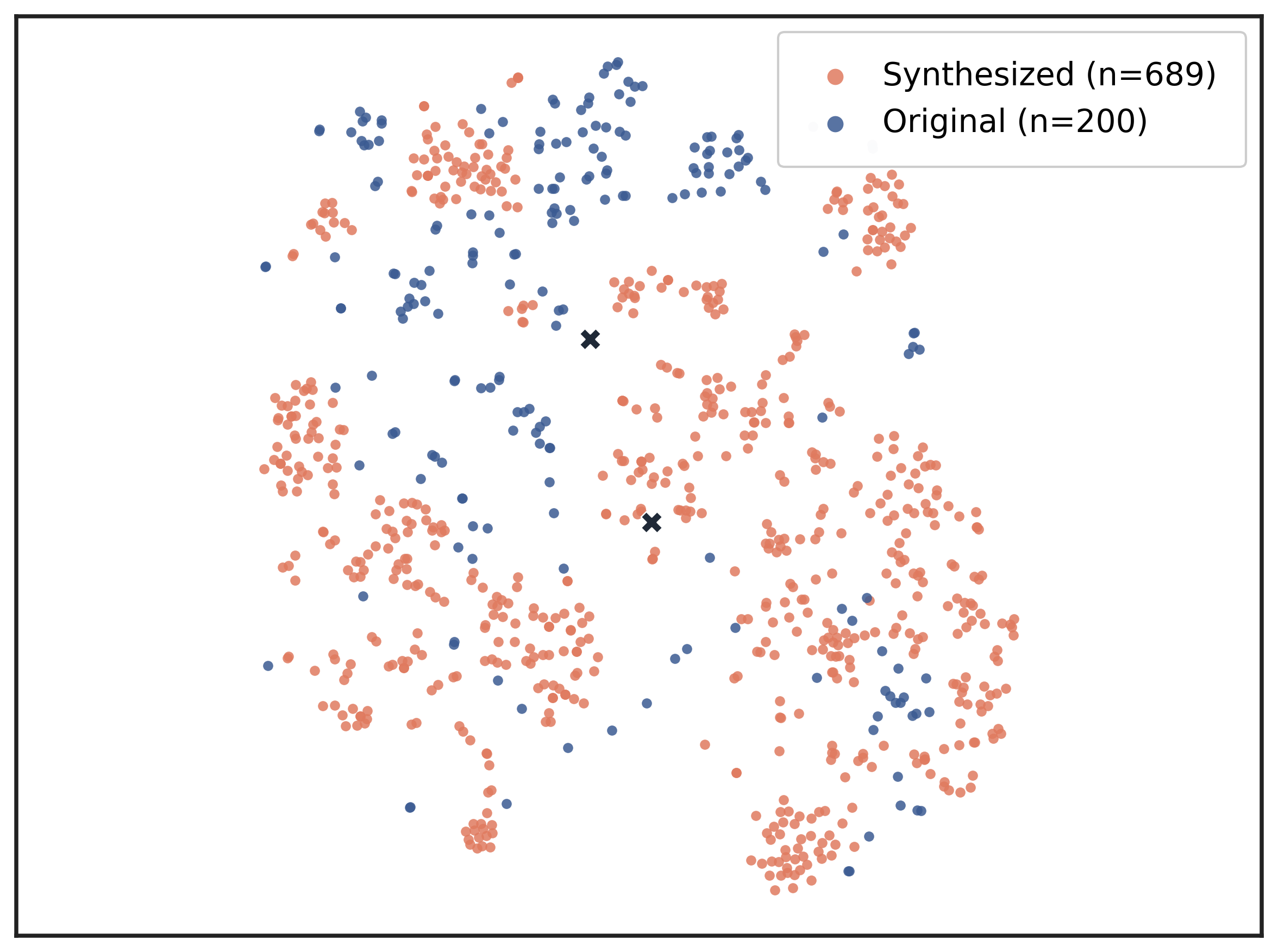
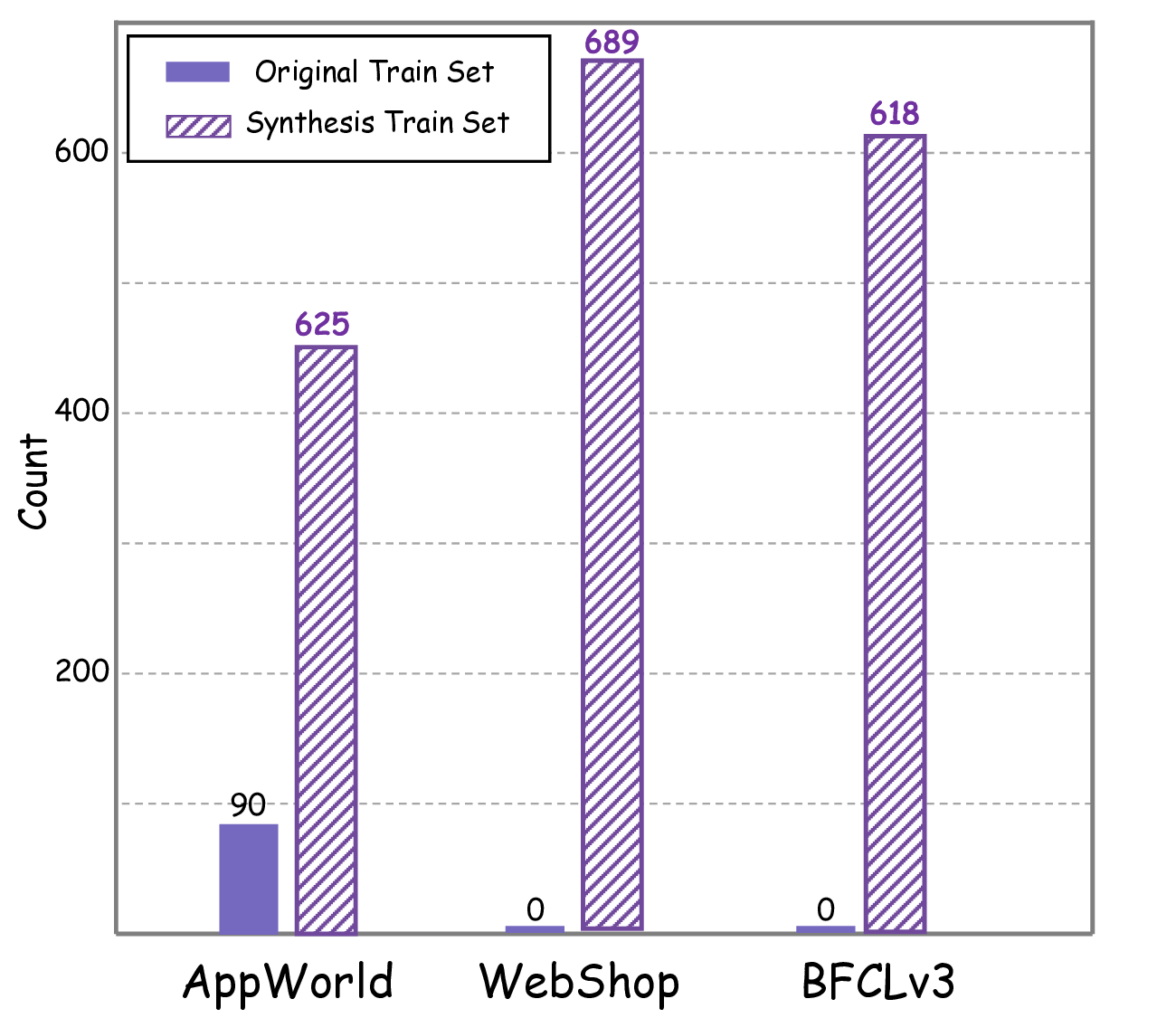
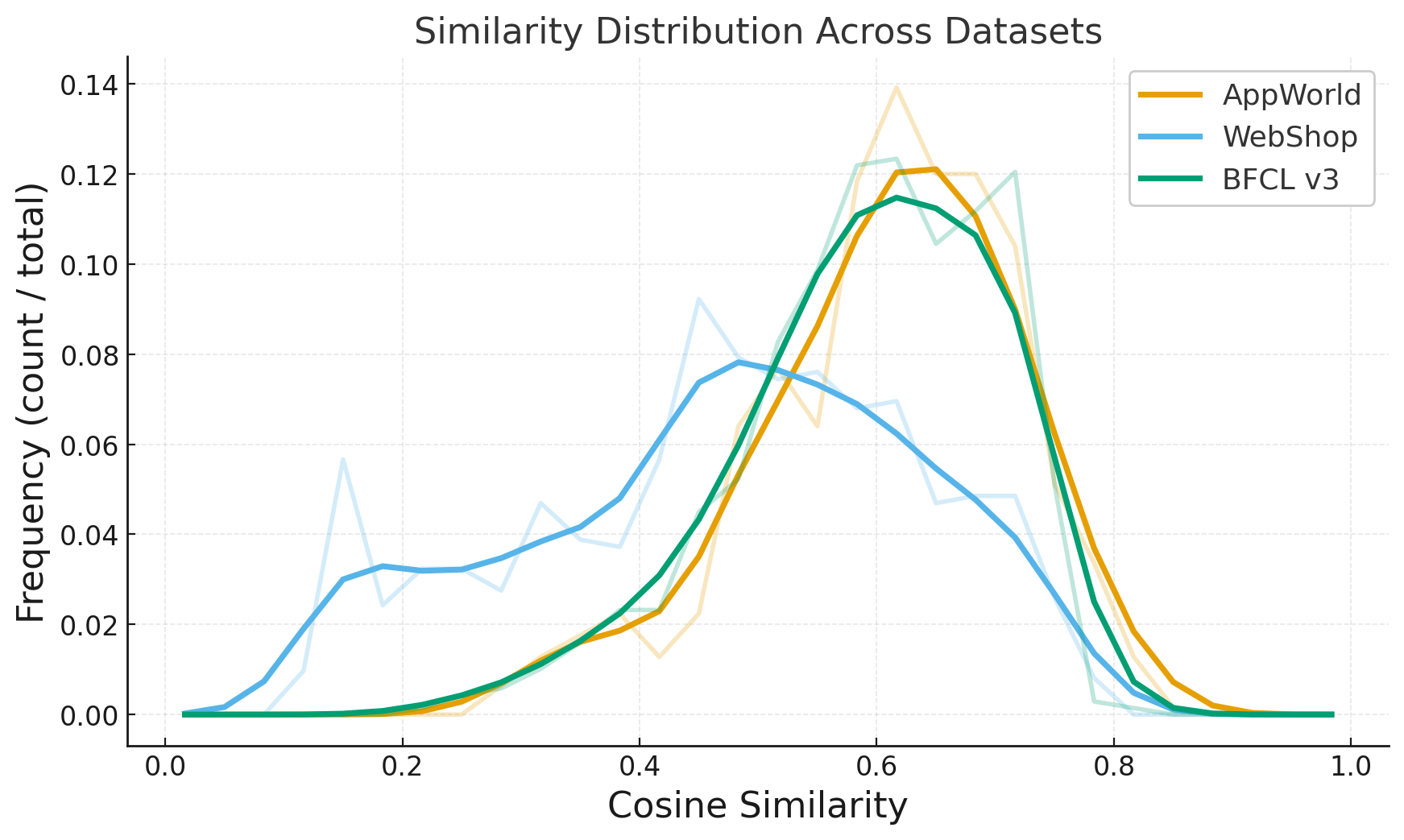
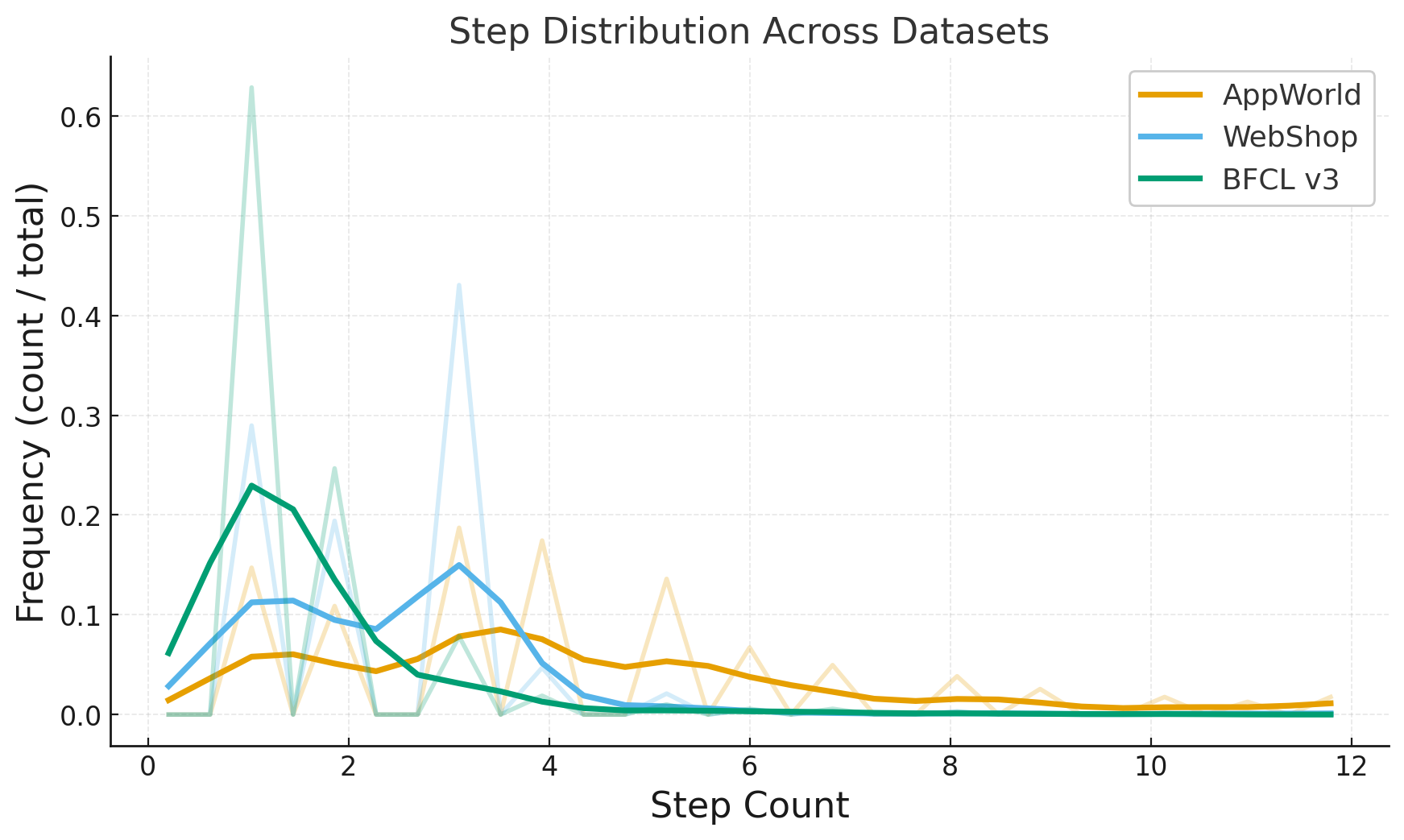
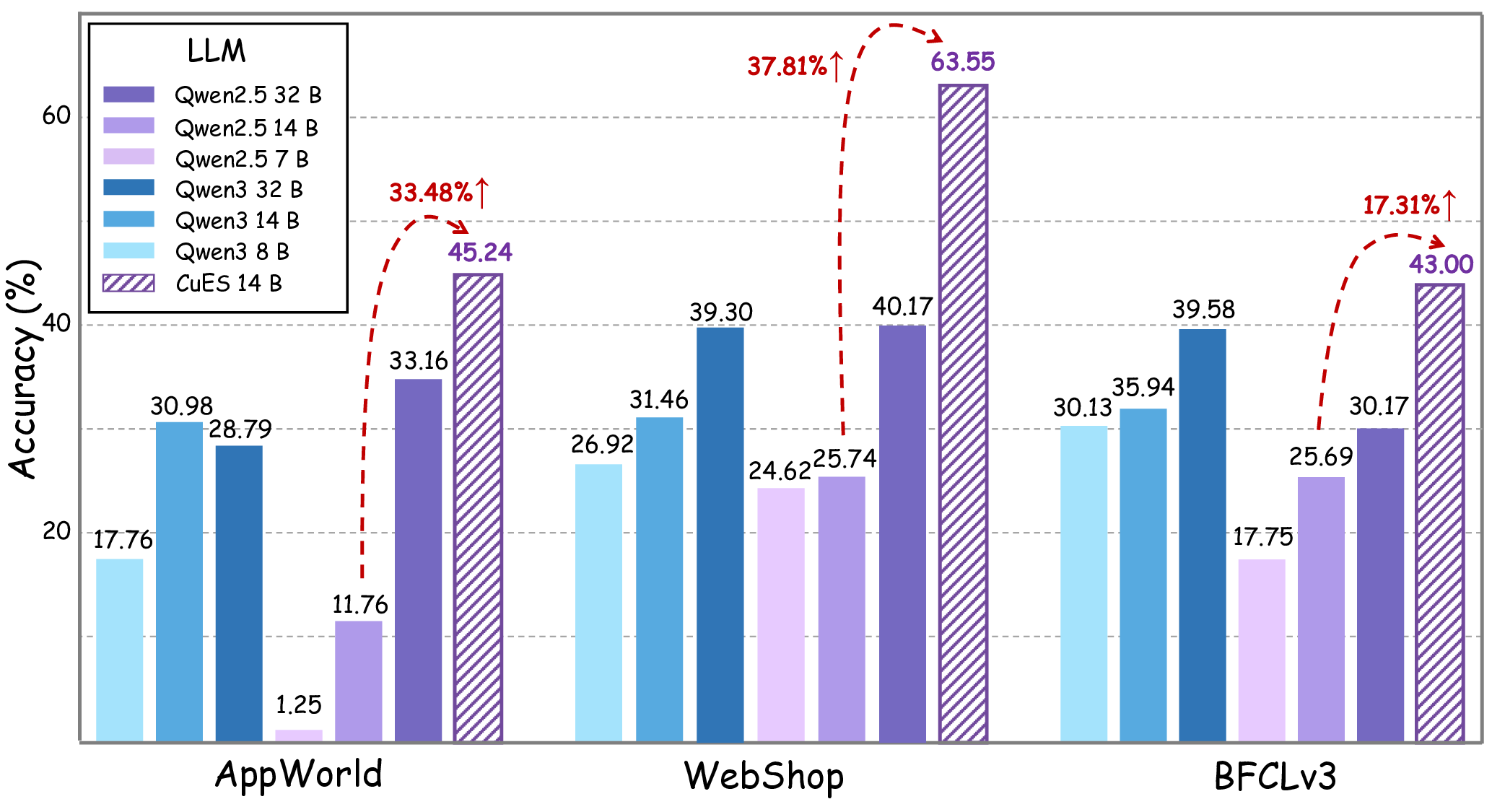
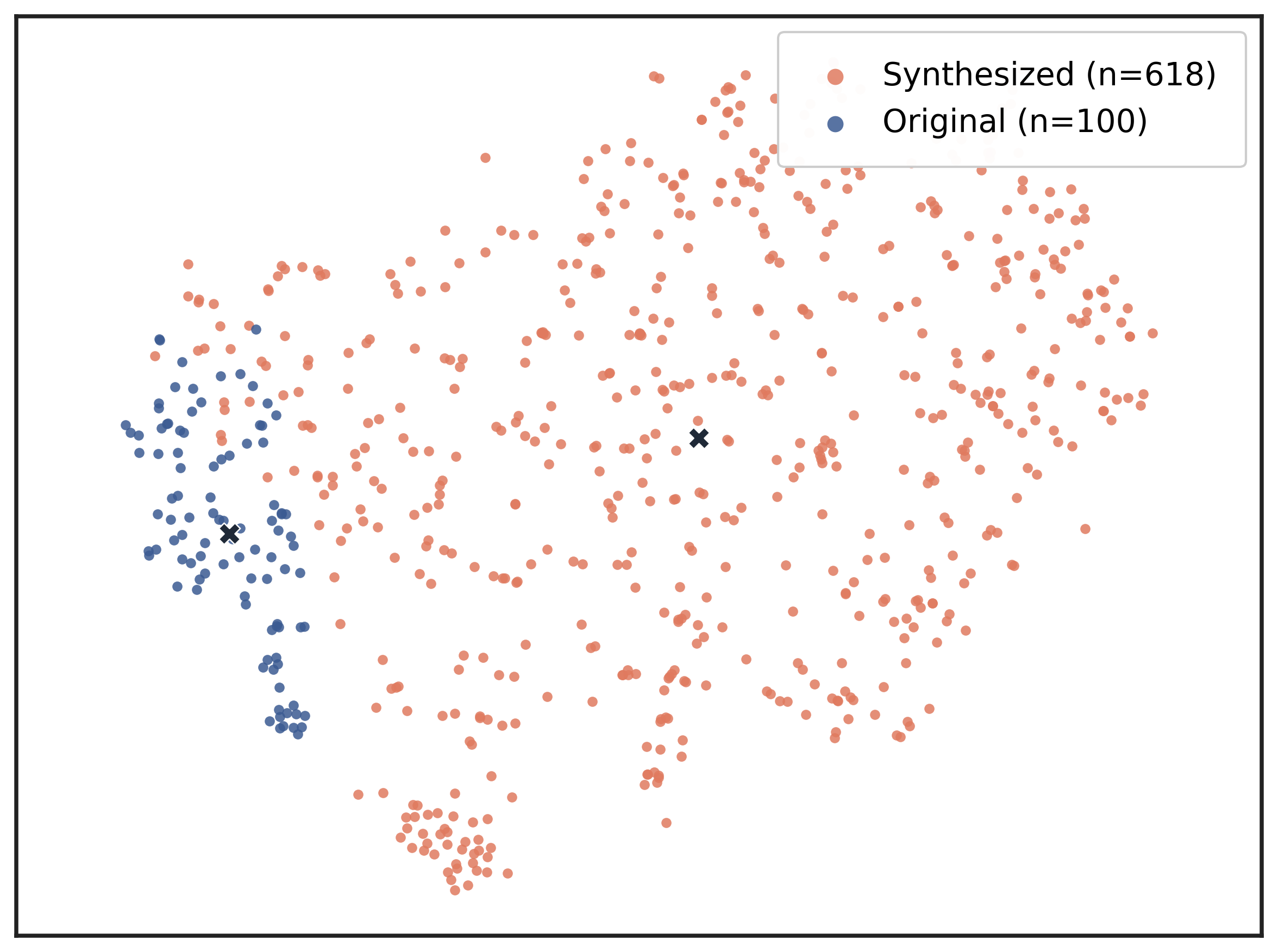
We evaluate CuES across three representative environments-AppWorld, BFCL, and WebShop-and find that the generated tasks match or surpass manually curated datasets in both diversity and executability. Moreover, when integrated into RL training, these tasks lead to substantial downstream policy improvement, demonstrating that curiosity-driven, environment-grounded task generation can effectively replace costly human task design.
Our main contributions are threefold:
• Problem Formulation. We systematically analyze and formalize the problem of Task Generation for Agentic RL, where an agent must learn within a given environment that lacks predefined tasks.
• Method. We propose CuES, a curiosity-driven and environment-grounded framework via Bottom-Up Exploration and Top-Down Guidance, which autonomously generates executable and diverse training tasks without relying on handcrafted seeds or external data.
• Empirical validation. Across multiple environments, CuES produces high-quality task distributions and strong downstream training performance, confirming the effectiveness of autonomous task generation for agentic learning.
Together, these contributions advance a systematic understanding and practical solution for learning in task-scarce environments-toward agents that not only learn how to act, but also learn what to learn.
This strategy benefits from clear goal specification and controllable semantics, but often decouples task generation from environment dynamics, producing instructions that look plausible in text yet fail during execution (Li et al., 2024;L ù et al., 2024;Lai et al., 2024). In contrast, bottom-up approaches explore the environment first and then abstract tasks from discovered trajectories, ensuring that proposed problems are feasible in situ. While this improves executability and behavioral grounding, it typically suffers from weak goal alignment, inefficient exploration, and domain-specific heuristics
This content is AI-processed based on open access ArXiv data.