Title: Rectifying LLM Thought from Lens of Optimization
ArXiv ID: 2512.01925
Date: 2025-12-01
Authors: ** - Junnan Liu (Shanghai AI Laboratory, Monash University) – 공동 1저자 - Hongwei Liu (Shanghai AI Laboratory) – 공동 1저자 - Songyang Zhang (Shanghai AI Laboratory) – 교신 저자 - Kai Chen (Shanghai AI Laboratory) – 교신 저자 **
📝 Abstract
Recent advancements in large language models (LLMs) have been driven by their emergent reasoning capabilities, particularly through long chain-of-thought (CoT) prompting, which enables thorough exploration and deliberation. Despite these advances, long-CoT LLMs often exhibit suboptimal reasoning behaviors, such as overthinking and excessively protracted reasoning chains, which can impair performance. In this paper, we analyze reasoning processes through an optimization lens, framing CoT as a gradient descent procedure where each reasoning step constitutes an update toward problem resolution. Building on this perspective, we introduce RePro (Rectifying Process-level Reward), a novel approach to refine LLM reasoning during post-training. RePro defines a surrogate objective function to assess the optimization process underlying CoT, utilizing a dual scoring mechanism to quantify its intensity and stability. These scores are aggregated into a composite process-level reward, seamlessly integrated into reinforcement learning with verifiable rewards (RLVR) pipelines to optimize LLMs. Extensive experiments across multiple reinforcement learning algorithms and diverse LLMs, evaluated on benchmarks spanning mathematics, science, and coding, demonstrate that RePro consistently enhances reasoning performance and mitigates suboptimal reasoning behaviors.
💡 Deep Analysis
📄 Full Content
2025-12-2
Rectifying LLM Thought from Lens of
Optimization
Junnan Liu1,2,*, Hongwei Liu1, Songyang Zhang1,† and Kai Chen1,†
1Shanghai AI Laboratory, 2Monash University
Recent advancements in large language models (LLMs) have been driven by their emergent reasoning ca-
pabilities, particularly through long chain-of-thought (CoT) prompting, which enables thorough exploration
and deliberation. Despite these advances, long-CoT LLMs often exhibit suboptimal reasoning behaviors, such
as overthinking and excessively protracted reasoning chains, which can impair performance. In this paper,
we analyze reasoning processes through an optimization lens, framing CoT as a gradient descent procedure
where each reasoning step constitutes an update toward problem resolution. Building on this perspective,
we introduce RePro (Rectifying Process-level Reward), a novel approach to refine LLM reasoning during
post-training. RePro defines a surrogate objective function to assess the optimization process underlying CoT,
utilizing a dual scoring mechanism to quantify its intensity and stability. These scores are aggregated into
a composite process-level reward, seamlessly integrated into reinforcement learning with verifiable rewards
(RLVR) pipelines to optimize LLMs. Extensive experiments across multiple reinforcement learning algorithms
and diverse LLMs, evaluated on benchmarks spanning mathematics, science, and coding, demonstrate that
RePro consistently enhances reasoning performance and mitigates suboptimal reasoning behaviors. Code and
data are available at https://github.com/open-compass/RePro
1. Introduction
Recent advancements in large language models (LLMs) have been propelled by their emergent reasoning
capabilities, enabling them to tackle complex tasks (Huang & Chang, 2023; Plaat et al., 2024; Ahn et al., 2024; Ke
et al., 2025; Sun et al., 2025). These capabilities are pivotal in progressing toward artificial general intelligence
(AGI) (Zhong et al., 2024). State-of-the-art LLMs, such as OpenAI’s o-series (OpenAI, 2024a,b, 2025), DeepSeek-
R1 (DeepSeek-AI et al., 2025), Kimi-K1 (Kimi-Team et al., 2025), and Gemini-2.5-Pro (Comanici et al., 2025),
leverage long chain-of-thought (CoT) prompting to enhance reasoning. This approach facilitates comprehensive
exploration and reflection, yielding robust reasoning processes (Chen et al., 2025a). Such improvements
stem largely from reinforcement learning with verifiable rewards (RLVR) (Schulman et al., 2017; Shao et al.,
2024), which enables LLMs to autonomously explore reasoning steps based on a terminal reward, fostering
self-improving models with scalable reasoning during inference (Snell et al., 2024).
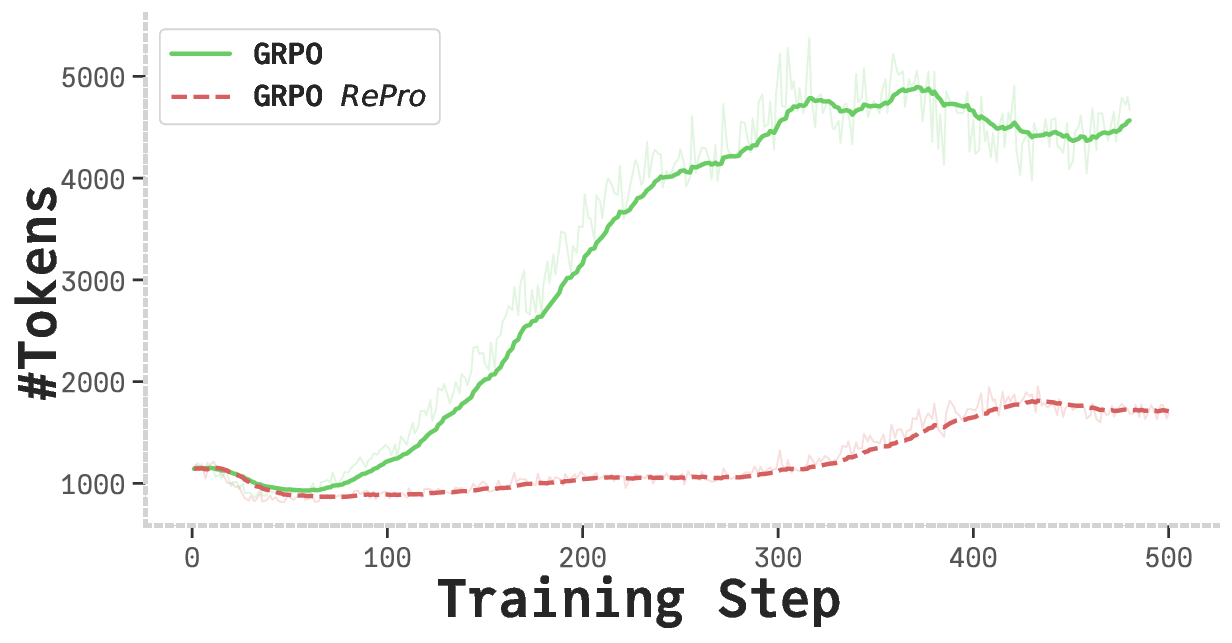
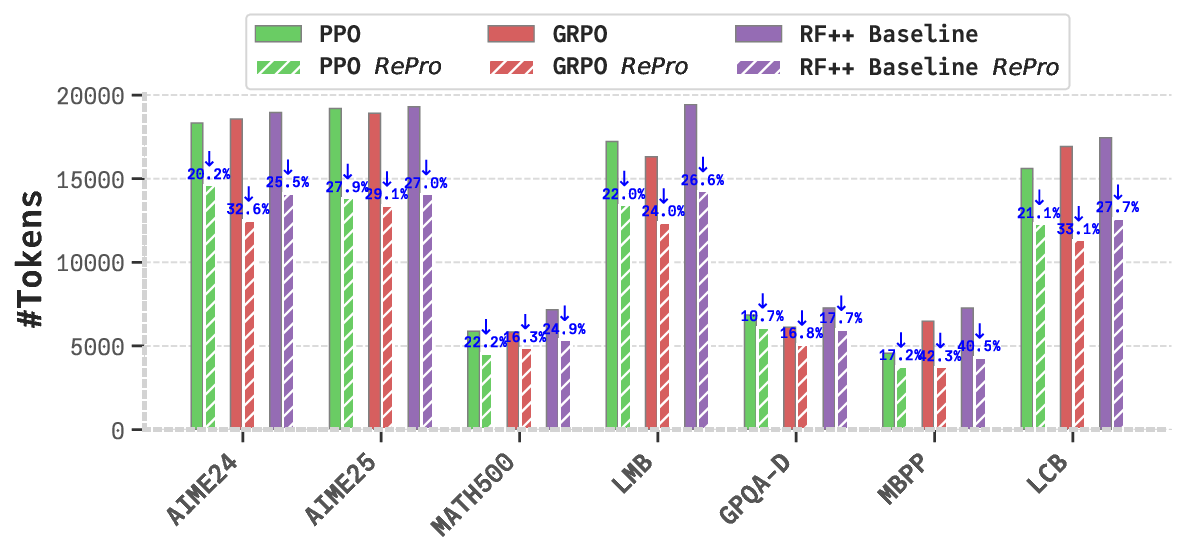
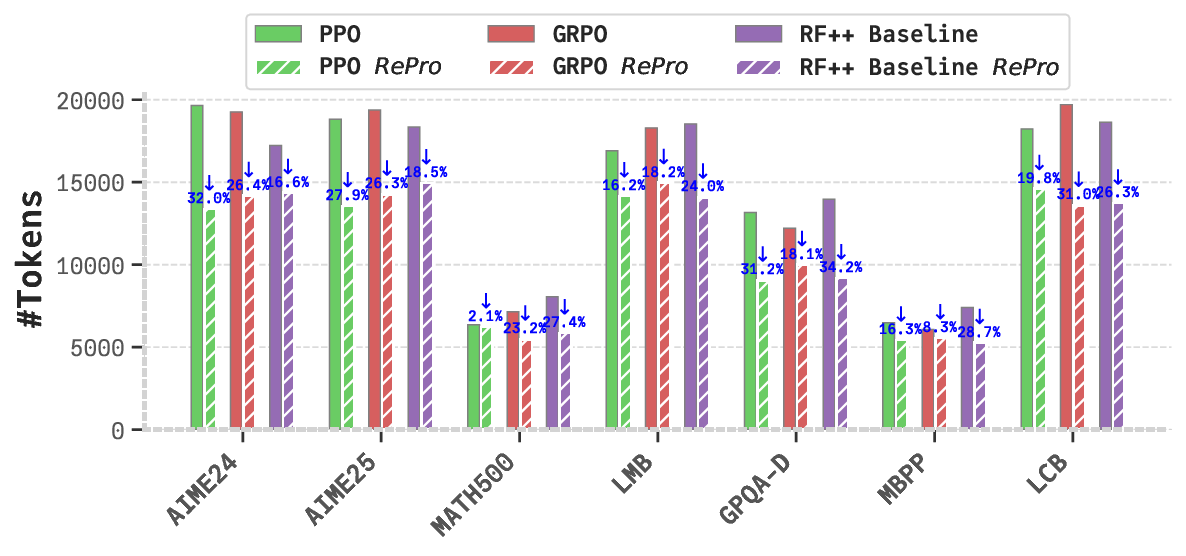
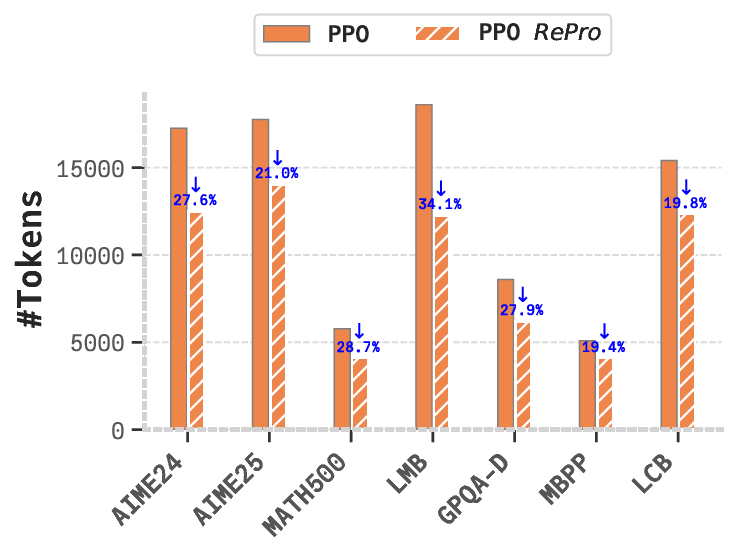
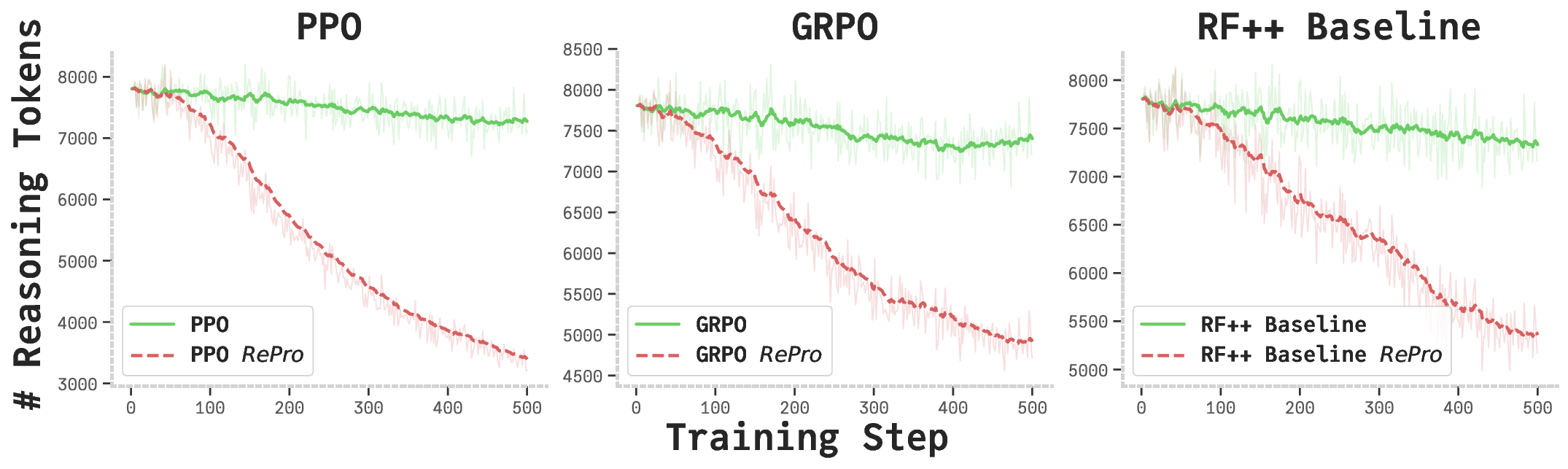
Despite these advancements, long-CoT LLMs often exhibit suboptimal reasoning behaviors (Chen et al.,
2025a). A significant issue is overthinking, where models generate excessive tokens or protracted reasoning
paths that contribute minimally to problem resolution, incurring substantial computational costs (Chen et al.,
2024; Wang et al., 2025c; Sui et al., 2025). For instance, in response to a simple query like “What is the answer
to 2 plus 3?” (Chen et al., 2024), certain long-CoT LLMs produce reasoning chains exceeding thousands of
tokens, increasing latency and resource demands, thus limiting applicability in time-sensitive domains (Sui
et al., 2025).
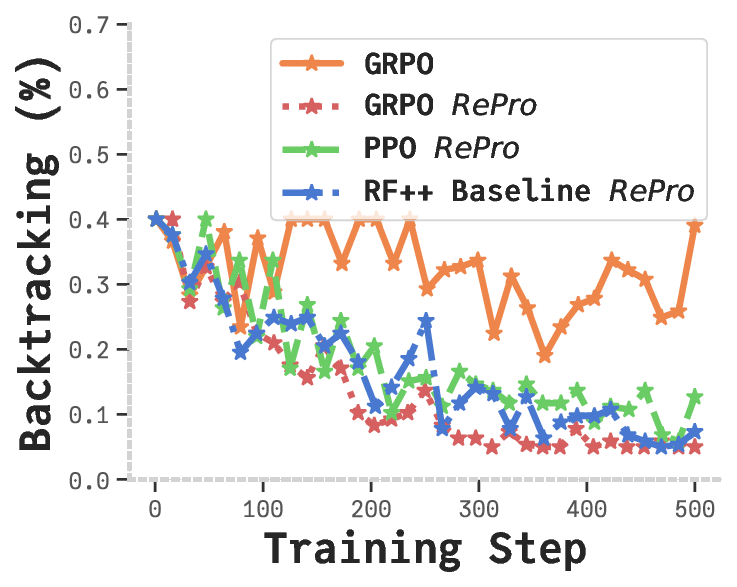
Drawing on prior work (Feng et al., 2023; Huang et al., 2025a), we analyze suboptimal reasoning through
an optimization framework, conceptualizing CoT as a task-specific variant of gradient descent, where each
reasoning step represents an optimization update (Liu et al., 2025a). In this paradigm, suboptimal reasoning
manifests as oscillations around saddle points or local optima, hindering convergence to the optimal solution.
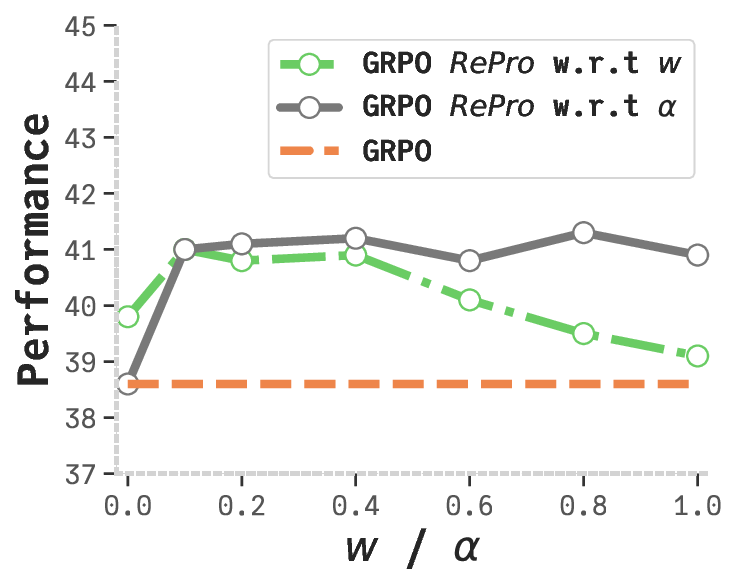
To address these challenges, we propose RePro (Rectifying Process-level Reward), a novel method to
* Work done when Junnan’s internship at Shanghai AI Laboratory. † Corresponding authors. Email to: junnan.liu@monash.edu;
zhangsongyang@pjlab.org.cn
arXiv:2512.01925v1 [cs.CL] 1 Dec 2025
Rectifying LLM Thought from Lens of Optimization
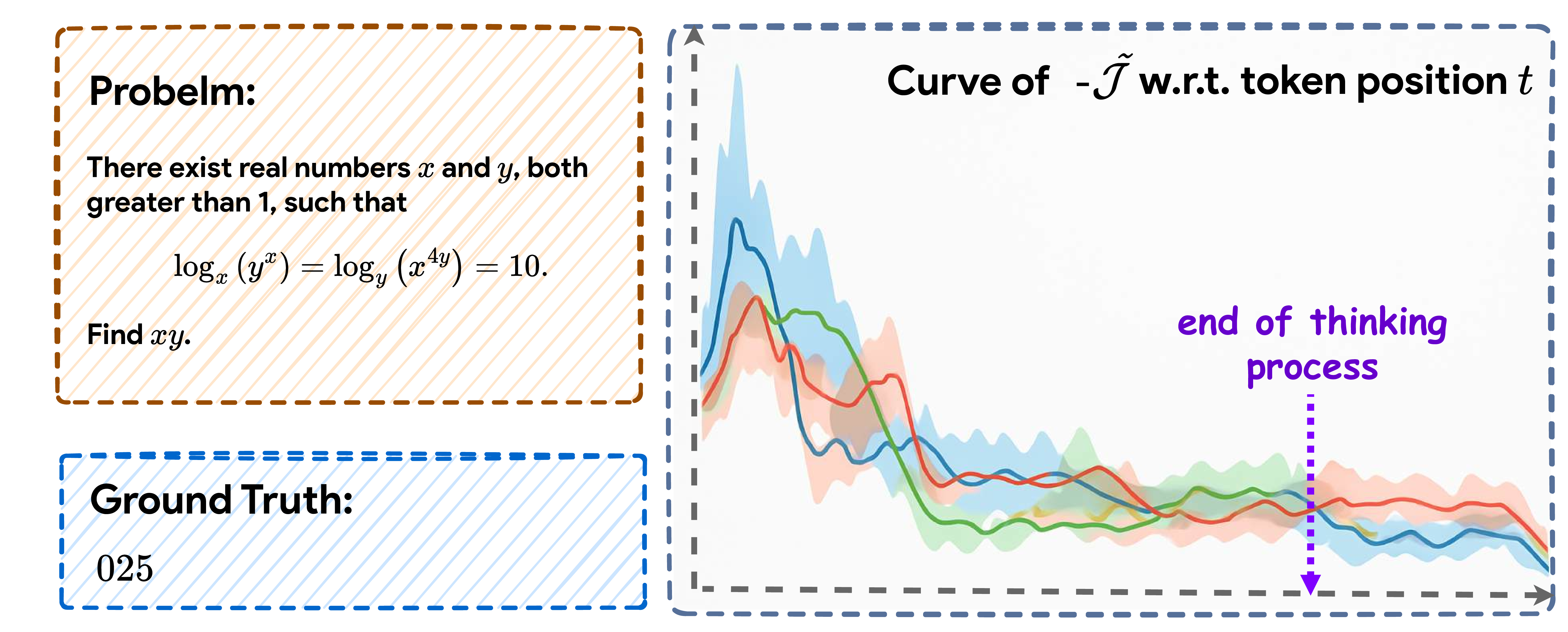
rectify LLM thought during post-training. RePro formulates a surrogate objective function, 𝒥, to monitor the
optimization process of CoT, measuring the LLM’s confidence in the ground truth via perplexity (Jelinek et al.,
1977) over the ground-truth token sequence. For a reasoning trajectory of 𝑁steps, we compute a sequence
of objective values [𝒥0, 𝒥1, . . . , 𝒥𝑁] and introduce a dual scoring system to assess optimization intensity and
stability. These scores are combined into a composite process-level reward (Lightman et al., 2024), integrated
into standard post-training pipelines (DeepSeek-AI et al., 2025; Shao et al., 2024; Hu, 2025) to enhance
reasoning. RePro is plug-and-play, compatible with prevalent reinforcement learning algorithms.
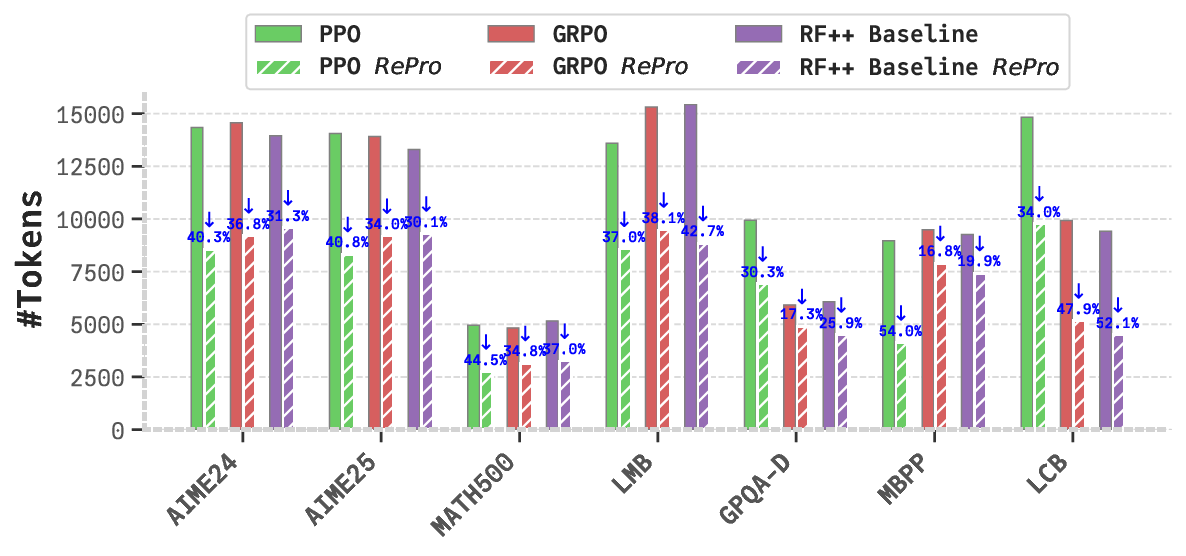
The efficacy of RePro is substantiated by comprehensive empirical evaluation. We validate RePro through
extensive experiments using rein