Title: Learned-Rule-Augmented Large Language Model Evaluators
ArXiv ID: 2512.01958
Date: 2025-12-01
Authors: Jie Meng, Jin Mao
📝 Abstract
Large language models (LLMs) are predominantly used as evaluators for natural language generation (NLG) tasks, but their application to broader evaluation scenarios remains limited. In this work, we explore the potential of LLMs as general evaluators across diverse tasks. Although LLM-based evaluators have made progress in different areas, existing methods struggle to generalize due to their reliance on costly, human-designed evaluation principles, which are often misaligned with both annotated data and LLMs' understanding.To address these challenges, we propose a rule-augmented evaluation paradigm. First, we introduce a rule distillation method that automatically extracts scoring rules from data using an LLM-assisted Monte Carlo Tree Search (MCTS), alleviating scalability issues and improving alignment with data. Second, to enable LLMs to effectively apply the learned rules, we propose two strategies: (1) Chain-of-Rule (CoR), which guides LLM to follow distilled rules, and (2) training a rule-augmented LLM evaluator (RuAE) via reinforcement learning, further bridging the gap between rules and LLMs' reasoning. Extensive experiments on diverse tasks demonstrate the effectiveness and generalizability of our approach across various evaluation scenarios.
💡 Deep Analysis
📄 Full Content
Learned-Rule-Augmented Large Language Model Evaluators
Jie Meng
Wuhan University / Wuhan
mengjie@whu.edu.cn
Jin Mao
Wuhan University / Wuhan
maojin@whu.edu.cn
Abstract
Large language models (LLMs) are predomi-
nantly used as evaluators for natural language
generation (NLG) tasks, but their application
to broader evaluation scenarios remains lim-
ited. In this work, we explore the potential
of LLMs as general evaluators across diverse
tasks. Although LLM-based evaluators have
made progress in different areas, existing meth-
ods struggle to generalize due to their reliance
on costly, human-designed evaluation princi-
ples, which are often misaligned with both
annotated data and LLMs’ understanding.To
address these challenges, we propose a rule-
augmented evaluation paradigm. First, we in-
troduce a rule distillation method that auto-
matically extracts scoring rules from data us-
ing an LLM-assisted Monte Carlo Tree Search
(MCTS), alleviating scalability issues and im-
proving alignment with data. Second, to enable
LLMs to effectively apply the learned rules,
we propose two strategies: (1) Chain-of-Rule
(CoR), which guides LLM to follow distilled
rules, and (2) training a rule-augmented LLM
evaluator (RuAE) via reinforcement learning,
further bridging the gap between rules and
LLMs’ reasoning. Extensive experiments on
diverse tasks demonstrate the effectiveness and
generalizability of our approach across various
evaluation scenarios.
1
Introduction
Recent advancements in large language models
(LLMs) have positioned them as effective and
scalable evaluators for assessing generated text
quality in Natural Language Generation (NLG)
tasks(Kocmi and Federmann, 2023; Shen et al.,
2023). This raises a natural question: can the
paradigm of LLMs as evaluators be extended
to diverse tasks? Studies have explored this po-
tential, investigating LLMs’ capabilities in grading
essays(Mizumoto and Eguchi, 2023) and assess-
ing citation significance(Zhao et al., 2025). In
essence, this means enabling LLMs to quantita-
tively evaluate text from specific perspectives, for
example, assessing quality, measuring expressed
tendencies (like empathy or aggressiveness)(Wang
et al., 2024), or evaluating textual relationships
(like relevance). These applications across multiple
domains confirm LLMs’ versatility as evaluators.
Nevertheless, research has revealed challenges
in LLM’s application as trustworthy general evalu-
ators. Primarily, most existing approaches develop
task-specific Chain-of-Thought (CoT) prompts
(i.e., evaluation principles)(Mizrahi et al., 2024;
Törnberg, 2024), which are difficult to generalize
across diverse tasks. Moreover, these evaluation
methods often fail to align with human judgment,
manifesting in two key misalignments: 1) mis-1:
misalignments between evaluation principles and
human-labeled data, and 2) mis-2: misalignments
between LLMs’ understanding and application of
these principles. These issues hinder progress to-
ward developing a general text evaluator.
To investigate the root of these misalignments,
we conducted an exploratory study on ASAP (see
Section 4.1) by prompting Qwen-7b to propose
evaluation principles and score essays accordingly.
We analyzed 600 responses, extracted principles
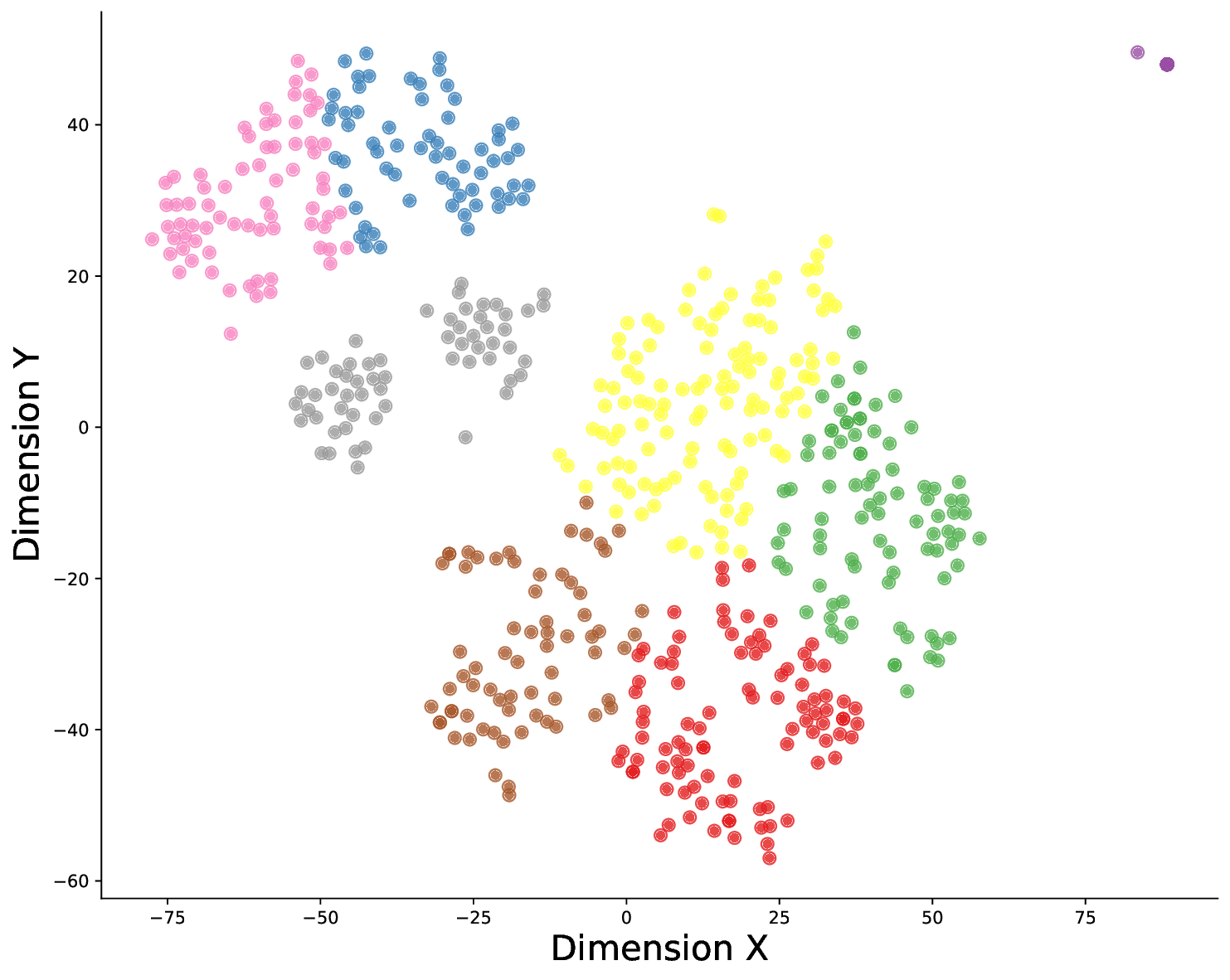
and performed dimensionality reduction. As shown
in Fig. 1, we observed highly dispersed principles
with no unified standards. Even within the same
evaluation dimension, consistent scoring remained
challenging. This contrasts with human evaluation
patterns, suggesting that the misalignment primar-
ily stems from differing evaluation standards.
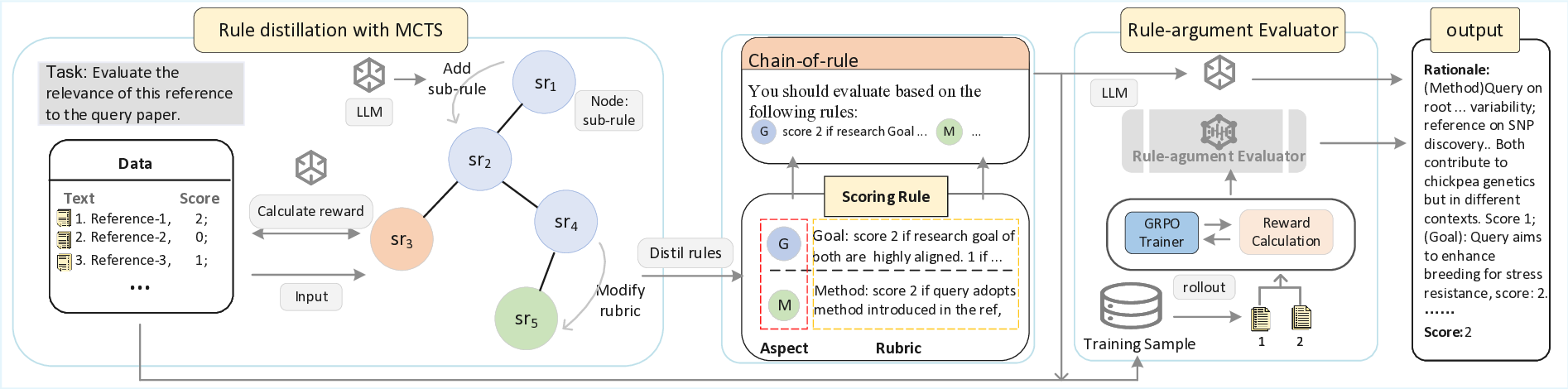
Inspired by this insight, we propose a rule-
argumented text evaluation paradigm. These rules
represent principles that specify evaluation aspects
and detailed criteria for assigning scores. While
rules can be manually summarized, this is costly
and lacks generalizability. Instead, we focus on
learning scoring rules from data. To achieve this,
we introduce an LLM-assisted Monte Carlo Tree
1
arXiv:2512.01958v1 [cs.AI] 1 Dec 2025
Search (MCTS)(Browne et al., 2012) approach
to distill rules from annotated data, efficiently
generating structured and interpretable rules while
avoiding compositional search complexity. This
approach aligns better with LLMs’ understanding
and human-labeled data, potentially addressing the
misalignment mis-1.
75
50
25
0
25
50
75
Dimension X
60
40
20
0
20
40
Dimension Y
Figure 1: Clustering visualization of evaluation princi-
ples generated by Qwen-7b.
When attempting to enable LLMs to apply
these rules, we encounter another misalignment
challenge mis-2: how can LLMs effectively fol-
low rules during evaluation? Even well-crafted
rules cannot prevent deviations in LLMs’ execu-
tion(Calderon et al., 2025), whether in providing
rationales or assigning scores. To address this, we
explore two strategies to enhance LLMs’ reason-
ing with learned rules: 1) Chain-of-Rule (CoR):
injecting distilled rules into prompts, a simple and
scalable method. However,