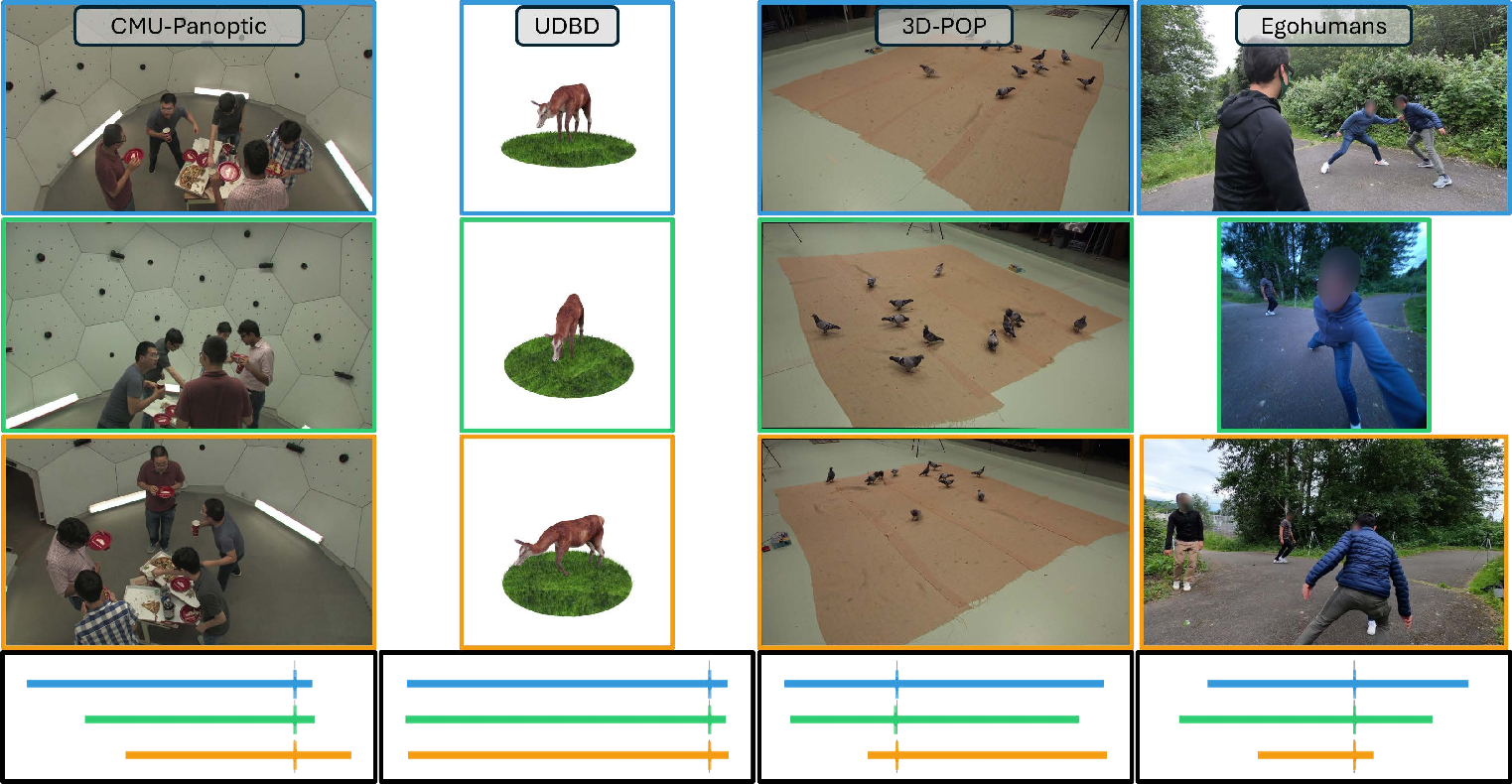
Today, people can easily record memorable moments, ranging from concerts, sports events, lectures, family gatherings, and birthday parties with multiple consumer cameras. However, synchronizing these cross-camera streams remains challenging. Existing methods assume controlled settings, specific targets, manual correction, or costly hardware. We present VisualSync, an optimization framework based on multi-view dynamics that aligns unposed, unsynchronized videos at millisecond accuracy. Our key insight is that any moving 3D point, when co-visible in two cameras, obeys epipolar constraints once properly synchronized. To exploit this, VisualSync leverages off-the-shelf 3D reconstruction, feature matching, and dense tracking to extract tracklets, relative poses, and cross-view correspondences. It then jointly minimizes the epipolar error to estimate each camera's time offset. Experiments on four diverse, challenging datasets show that VisualSync outperforms baseline methods, achieving an median synchronization error below 50 ms.
Recording dynamic scenes from multiple viewpoints has become increasingly common in everyday life. From concerts and sports events to lectures and birthday parties, people often capture the same moment using different handheld devices. These multi-view recordings present a rich opportunity to reconstruct scenes in 4D, enable bullet-time effects, or enhance the capabilities of existing vision models. However, these videos are typically captured independently, without synchronization or known camera poses, making it difficult to align and fuse them coherently.
Existing synchronization methods rely on controlled environments, manual annotations, specific patterns (e.g. human pose), audio signals (e.g. flashes or claps), or expensive hardware setups such as time-coded devices, none of which are available in casually captured videos. In this work, we design a versatile and robust algorithm for synchronizing videos without requiring specialized capture or making assumptions about the scene content. Our key insight is that, at the correct synchronization, the scene is static and thus the epipolar relationship (i.e. x ′T F x = 0 for correspondent points x and x ′ in two views) must hold true for all correspondences, whether on static or dynamic objects [19]. See Fig. 2 for an illustration.
While the insight follows directly from first principles and has been used in past attempts on this problem [3,34,60,41,31,55,16], building a practical and robust system that works on videos in the wild is challenging. We need a reliable estimate for the fundamental matrix between camera pairs, dynamic objects are a priori unknown and are generally small and blurry, and not all views may have an overlap. Our key contribution is to leverage recent advances in computer vision, specifically dense tracking, cross-view correspondences, and robust structure-from-motion, to build a robust and versatile system that can reliably synchronize challenging videos. Specifically, we formulate a joint energy function that measures the violations to the epipolar constraints between correspondences between videos and adopt a three-stage optimization procedure. In Stage 0, we use VGGT [57] to estimate fundamental matrices between each video pair, use MAST3R [30] to establish correspondences across videos, and use CoTracker3 [23,24] to establish dense tracks within each video. This gives us access to quantities (correspondences and fundamental matrices) necessary to evaluate the joint energy. Optimizing this joint energy directly is challenging. Therefore, in Stage 1, we decompose this energy into pairwise energy terms and estimate the best temporal alignment between each video pair via a brute force search. In Stage 2, we synchronize the temporal offsets across all video pairs to assign a globally consistent temporal offset to each video. We validate our approach on diverse datasets and show strong performance across different scenes, motions, and camera setups, and achieve high-precision synchronization even under severe viewpoints. Specifically, we outperform SyncNerf [26], a recent method for this task by radiance field optimization, and adaptations of two recent methods Uni4D [62] and MAST3R [30]. These results demonstrate the robustness and generality of our approach and open the door to scalable, unconstrained multi-view 4D scene understanding.
Tracking and Correspondence. Establishing reliable correspondences across time and views is fundamental for synchronizing multi-view videos [15,4,6,12,47,5,51]. Recent models like CoTracker [23,24,18,13,14] track points densely over time, offering strong temporal coherence. However, they do not model spatial correspondences across different viewpoints. On the other hand, MASt3R [30,58] focuses on spatial matching and stereo reconstruction, providing dense crossview correspondences, but it does not handle temporal dynamics, especially in moving scenes. Our method bridges this gap by constructing spatio-temporal cross-view correspondences, integrating both temporal tracking and spatial matching to enable accurate synchronization in dynamic, multi-view video settings. Multi-View Structure-from-Motion. Structure-from-Motion (SfM) techniques [2,58,48,52,38,39,50,61], such as COLMAP [48], have significantly advanced 3D reconstruction pipelines by producing accurate camera poses from multi-view images and videos. More recent models [7,53] like HLOC [47,46] and VGGT [57,56] build on this progress using learning-based features and transformers to handle large-scale matching and pose estimation. While these methods achieve strong performance in estimating camera geometry, they fall short in synchronizing dynamic scenes, as they rely predominantly on static visual cues. In contrast, our approach explicitly decomposes the scene into static and dynamic components, leveraging static cues for pose estimation and dynamic cues from moving objects to perform robust temporal synchronization across views.
Video Synchr
This content is AI-processed based on open access ArXiv data.