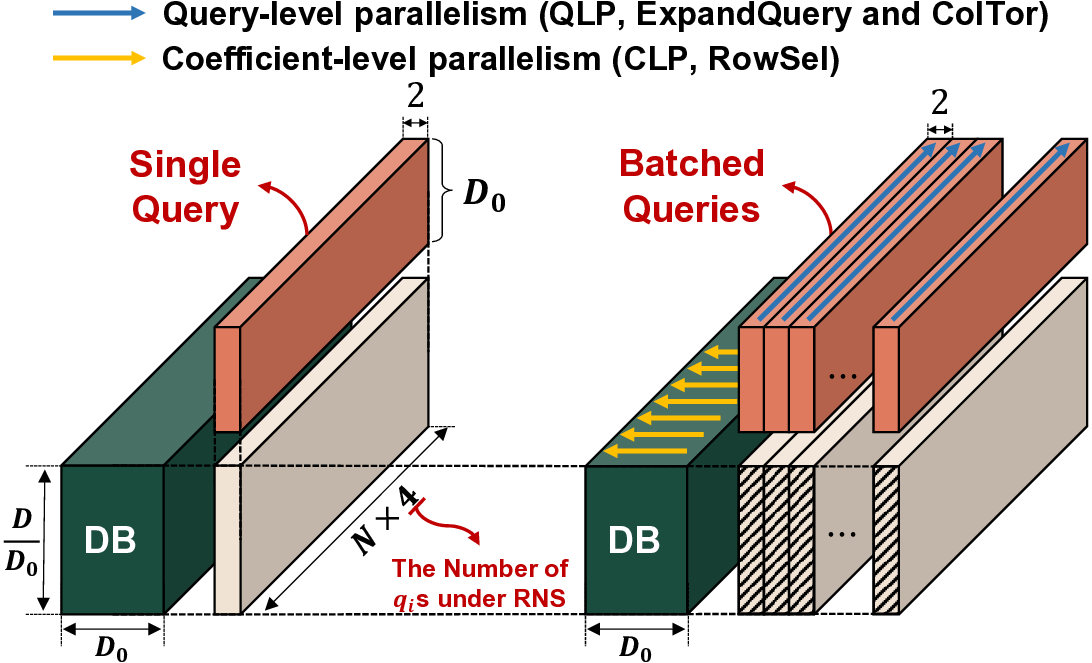
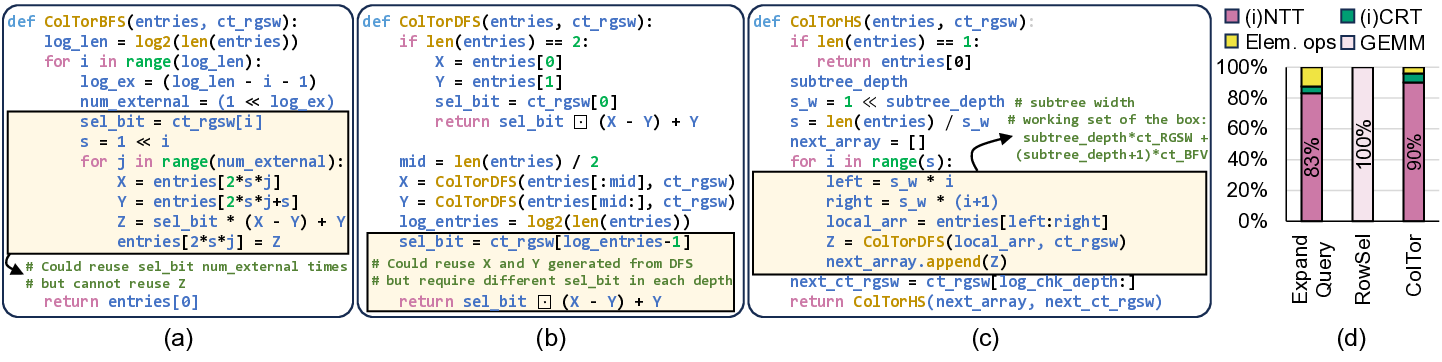
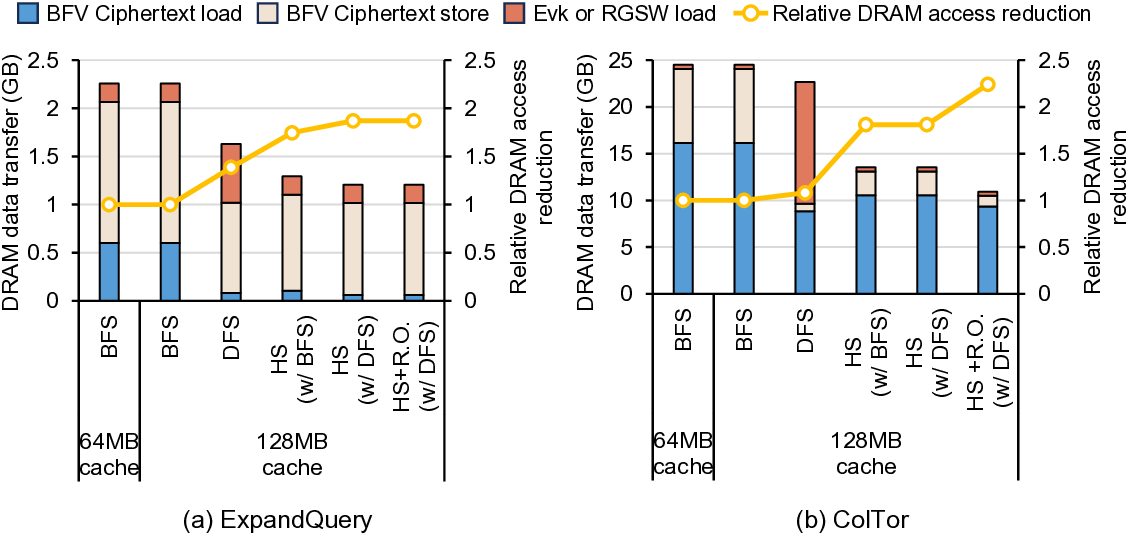
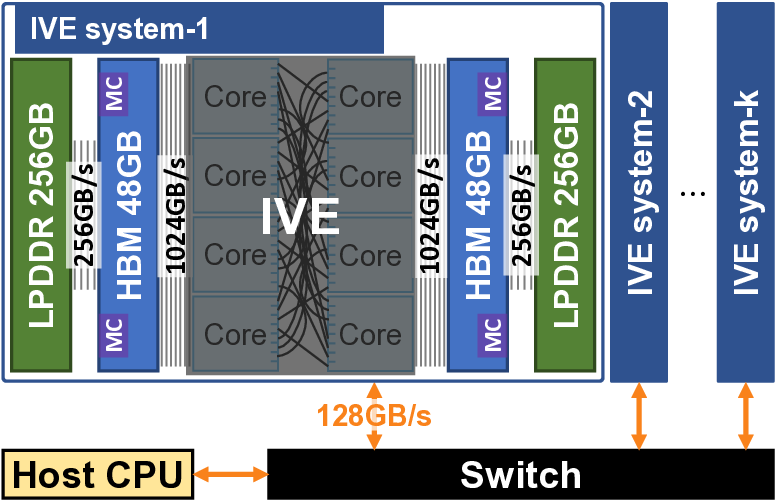
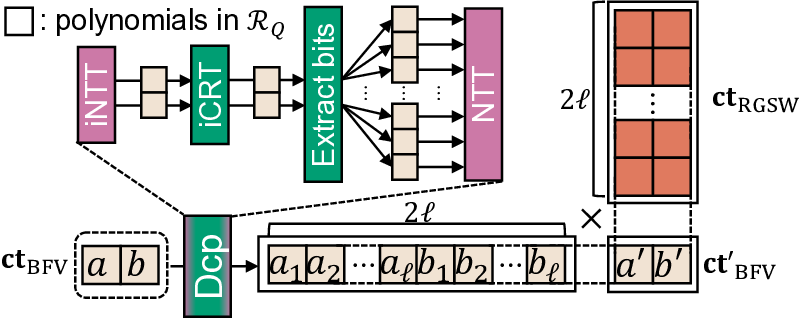
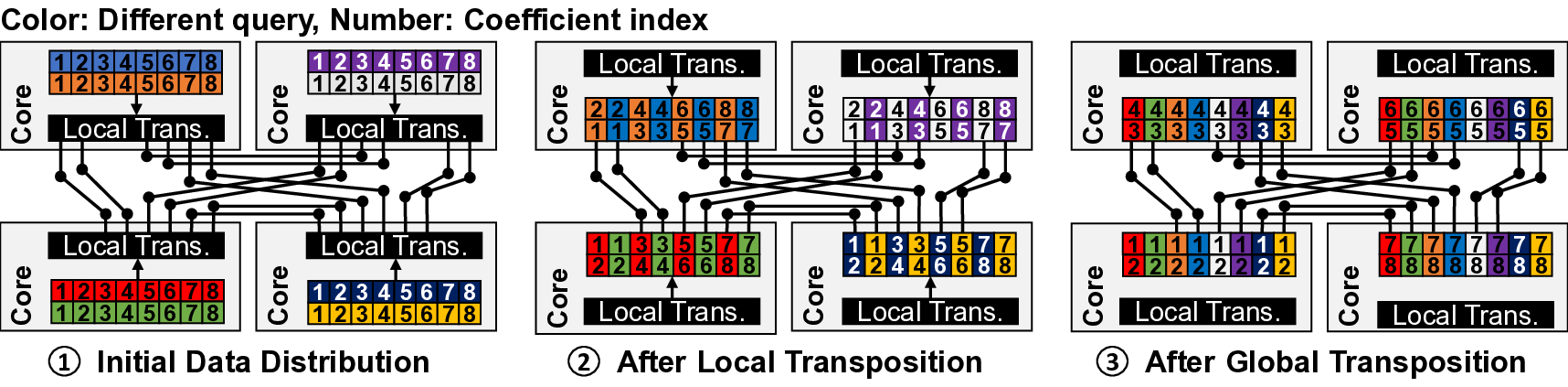
IVE: An Accelerator for Single-Server Private Information Retrieval Using Versatile Processing Elements
Reading time: 5 minute
...
📝 Original Info
Title: IVE: An Accelerator for Single-Server Private Information Retrieval Using Versatile Processing Elements
ArXiv ID: 2512.01574
Date: 2025-12-01
Authors: Sangpyo Kim, Hyesung Ji, Jongmin Kim, Wonseok Choi, Jaiyoung Park, Jung Ho Ahn
📝 Abstract
Private information retrieval (PIR) is an essential cryptographic protocol for privacy-preserving applications, enabling a client to retrieve a record from a server's database without revealing which record was requested. Single-server PIR based on homomorphic encryption has particularly gained immense attention for its ease of deployment and reduced trust assumptions. However, single-server PIR remains impractical due to its high computational and memory bandwidth demands. Specifically, reading the entirety of large databases from storage, such as SSDs, severely limits its performance. To address this, we propose IVE, an accelerator for single-server PIR with a systematic extension that enables practical retrieval from large databases using DRAM. Recent advances in DRAM capacity allow PIR for large databases to be served entirely from DRAM, removing its dependence on storage bandwidth. Although the memory bandwidth bottleneck still remains, multi-client batching effectively amortizes database access costs across concurrent requests to improve throughput. However, client-specific data remains a bottleneck, whose bandwidth requirements ultimately limits performance. IVE overcomes this by employing a large on-chip scratchpad with an operation scheduling algorithm that maximizes data reuse, further boosting throughput. Additionally, we introduce sysNTTU, a versatile functional unit that enhances area efficiency without sacrificing performance. We also propose a heterogeneous memory system architecture, which enables a linear scaling of database sizes without a throughput degradation. Consequently, IVE achieves up to 1,275x higher throughput compared to prior PIR hardware solutions.
💡 Deep Analysis
📄 Full Content
IVE: An Accelerator for Single-Server Private Information
Retrieval Using Versatile Processing Elements
Sangpyo Kim†, Hyesung Ji‡, Jongmin Kim‡, Wonseok Choi‡, Jaiyoung Park‡, and Jung Ho Ahn‡
†CryptoLab Inc., ‡Seoul National University
spkim@cryptolab.co.kr, {kevin5188, jongmin.kim, wonseok.choi, jeff1273, gajh}@snu.ac.kr
Abstract—Private information retrieval (PIR) is an essential
cryptographic protocol for privacy-preserving applications, en-
abling a client to retrieve a record from a server’s database
without revealing which record was requested. Single-server
PIR based on homomorphic encryption has particularly gained
immense attention for its ease of deployment and reduced trust
assumptions. However, single-server PIR remains impractical
due to its high computational and memory bandwidth demands.
Specifically, reading the entirety of large databases from storage,
such as SSDs, severely limits its performance. To address this,
we propose IVE, an accelerator for single-server PIR with a
systematic extension that enables practical retrieval from large
databases using DRAM. Recent advances in DRAM capacity
allow PIR for large databases to be served entirely from DRAM,
removing its dependence on storage bandwidth. Although the
memory bandwidth bottleneck still remains, multi-client batching
effectively amortizes database access costs across concurrent
requests to improve throughput. However, client-specific data
remains a bottleneck, whose bandwidth requirements ultimately
limits performance. IVE overcomes this by employing a large
on-chip scratchpad with an operation scheduling algorithm that
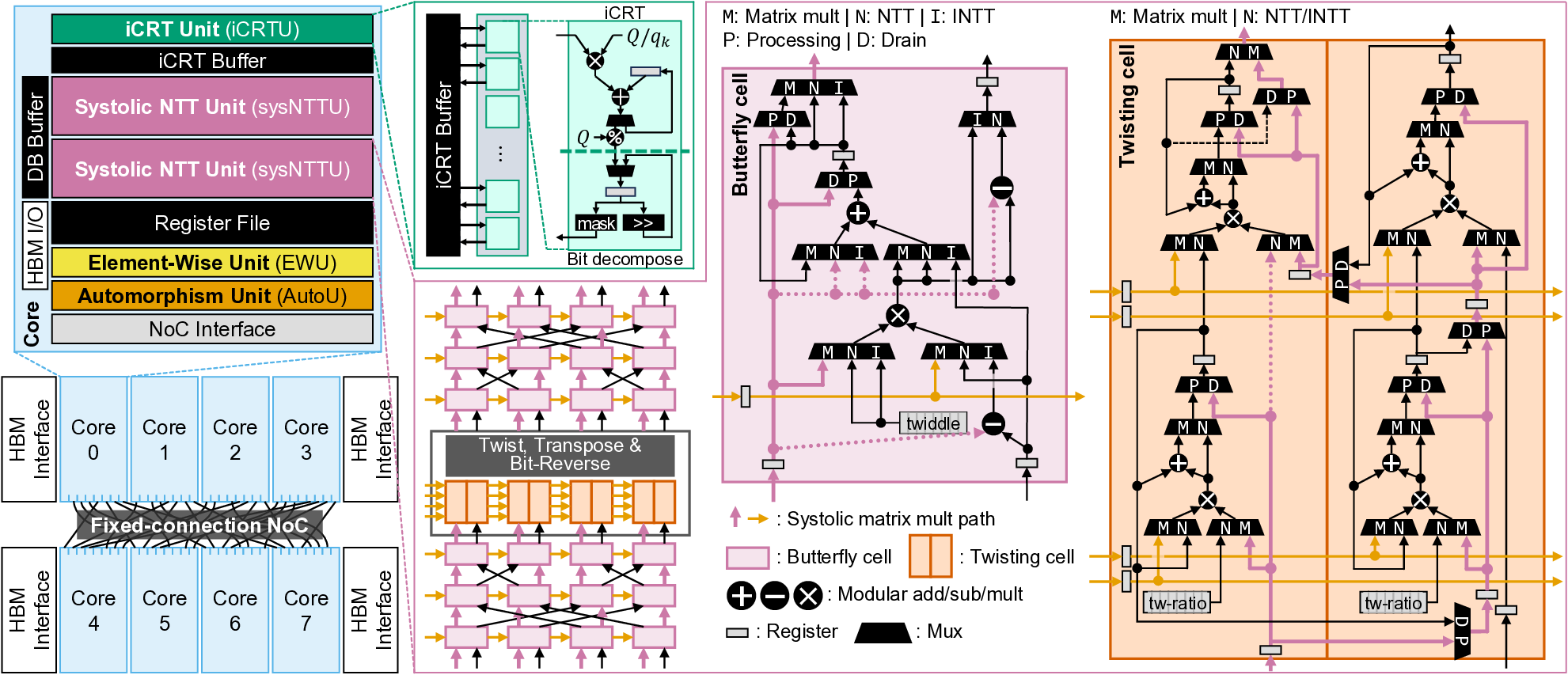
maximizes data reuse, further boosting throughput. Additionally,
we introduce sysNTTU, a versatile functional unit that enhances
area efficiency without sacrificing performance. We also propose
a heterogeneous memory system architecture, which enables a
linear scaling of database sizes without a throughput degradation.
Consequently, IVE achieves up to 1,275× higher throughput
compared to prior PIR hardware solutions.
I. INTRODUCTION
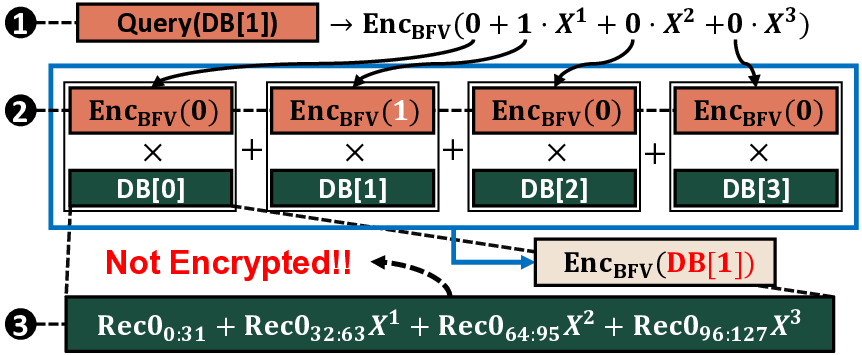
Private information retrieval (PIR) allows users to query a
remote database (DB) without revealing their query, offering
a cryptographic basis for privacy-preserving access to public
data. Amid the rapid expansion of cloud computing and
growing emphasis on data governance, PIR is emerging as
a critical building block for privacy-preserving applications,
such as web search, location-based services, contact tracing,
and AI inference [2], [5], [43], [45], [47], [63], [64], [69],
[75], [98].
Among various PIR protocols, those based on homomorphic
encryption (HE) stand out due to their general applicability
and low communication costs [2]–[4], [15], [49], [71], [76].
HE [12], [24], [26] is an encryption scheme that enables
direct computation on encrypted data, allowing a server to
process PIR queries without decryption. Unlike other PIR pro-
tocols [27], [29], [33], [41] requiring additional assumptions,
complex infrastructures with multiple servers, or both, HE-
based PIR relies on strong cryptographic guarantees to ensure
privacy with only a single server. Its strong security has led
to its gradual adoption in practical applications [6], [48], [68],
as exemplified by Apple’s use in private visual search.
This simplicity, however, comes at the cost of heavy server-
side computation. The high computational complexity of HE
operations incurs long retrieval latencies, limiting its practical
use. For example, state-of-the-art PIR protocols [32], [49],
[65], [67], [71], [72] take 1.1–18.6 seconds for retrieving a 1B–
32KB record from an 8GB DB on a CPU-based system [67].
Numerous acceleration studies have been conducted for
HE, leveraging CPUs/GPUs [9], [39], [53], [55]–[57], [61]
or custom FPGAs/ASICs [1], [58], [59], [62], [88], [89].
They focus on number-theoretic transforms (NTTs), with an
emphasis on bootstrapping [23], [25], [46], which dominate
the runtime in typical HE workloads.
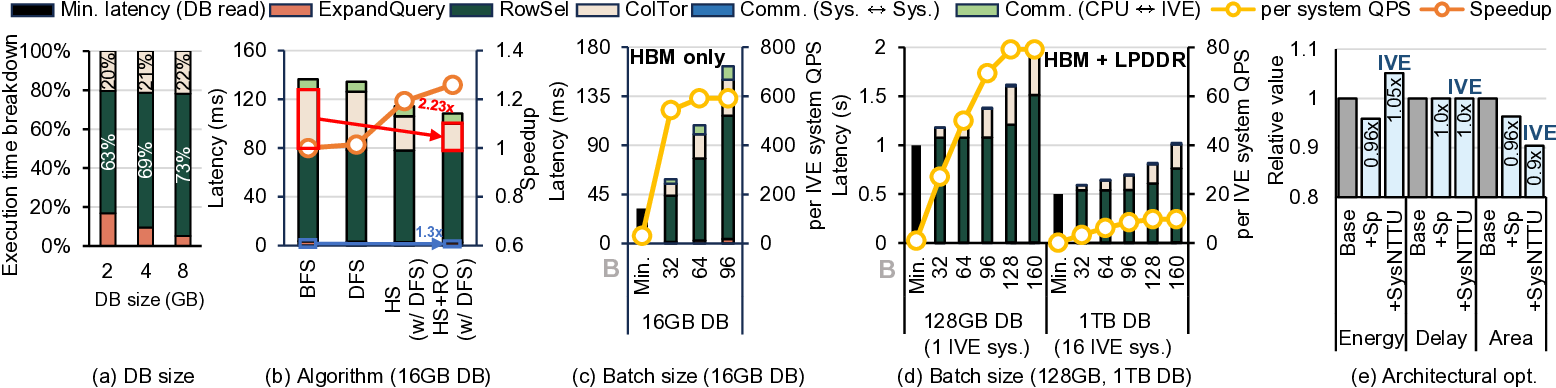
However, PIR’s memory-intensive nature hinders its ac-
celeration: as concealing the target record requires scanning
the entire DB, for large DBs exceeding DRAM capacity, the
low bandwidth of secondary storage devices (e.g., SSDs)
significantly degrades performance. This limitation motivated
INSPIRE [66] to adopt in-storage ASICs to accelerate HE-
based PIR. Unfortunately, even with such efforts, PIR remains
impractical, requiring 36 seconds to retrieve a 288B entry from
a 288GB DB for anonymous communication [2].
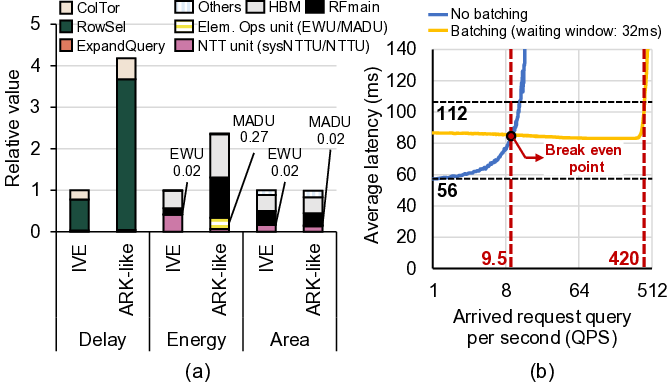
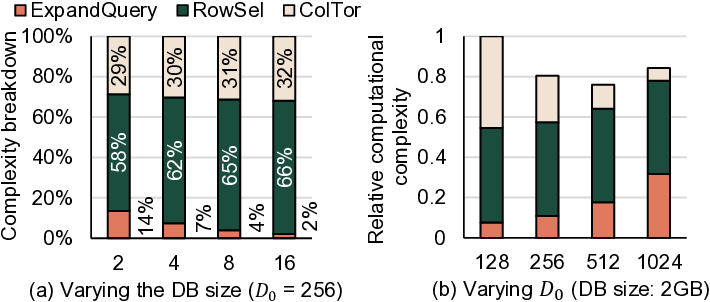
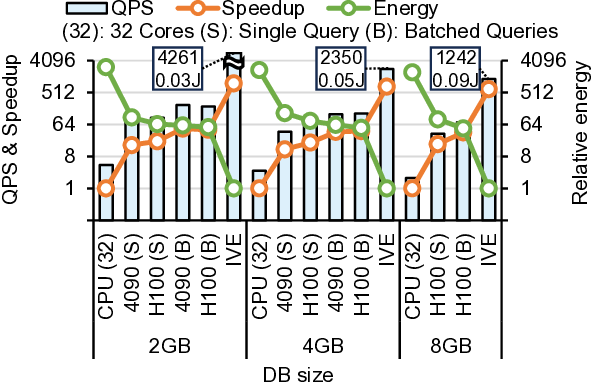
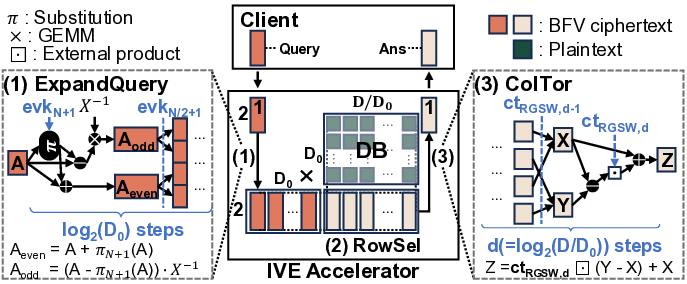
To overcome this limitation, we propose IVE, an accelerator
for single-server HE-based PIR with a systematic extension to
support large DBs efficiently. Technology scaling now allows
modern hardware systems to support terabyte-scale DRAM
configurations, which open up new opportunities to accelerate
the retrieval process by providing DB data with notably higher
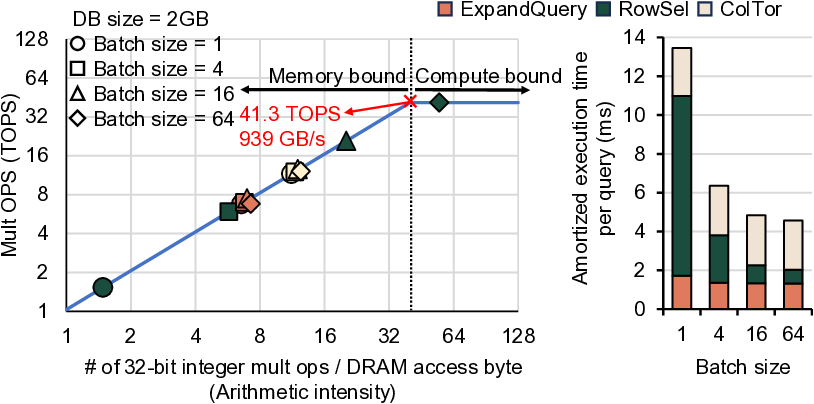
DRAM bandwidth. Our in-depth analysis shows that, although
the memory bandwidth bottleneck for scanning DB persists
even with DRAM, batching mult