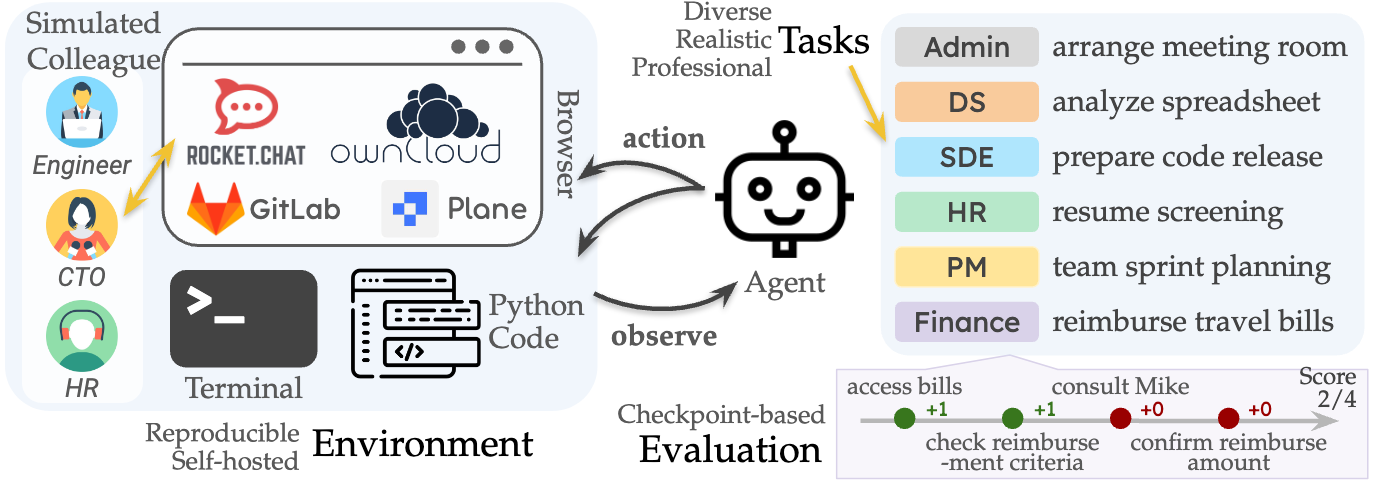
Benchmarking LLM Agents for Wealth-Management Workflows
Reading time: 7 minute
...
📝 Original Info
Title: Benchmarking LLM Agents for Wealth-Management Workflows
ArXiv ID: 2512.02230
Date: 2025-12-01
Authors: Rory Milsom
📝 Abstract
Modern work relies on an assortment of digital collaboration tools, yet routine processes continue to suffer from human error and delay. To address this gap, this dissertation extends TheAgentCompany with a finance-focused environment and investigates whether a general purpose LLM agent can complete representative wealth-management tasks both accurately and economically. This study introduces synthetic domain data, enriches colleague simulations, and prototypes an automatic task-generation pipeline. The study aims to create and assess an evaluation set that can meaningfully measure an agent's fitness for assistant-level wealth management work. We construct a benchmark of 12 task-pairs for wealth management assistants spanning retrieval, analysis, and synthesis/communication, with explicit acceptance criteria and deterministic graders. We seeded a set of new finance-specific data and introduced a high vs. low-autonomy variant of every task. The paper concluded that agents are limited less by mathematical reasoning and more so by end-to-end workflow reliability, and meaningfully affected by autonomy level, and that incorrect evaluation of models have hindered benchmarking.
💡 Deep Analysis
📄 Full Content
Benchmarking LLM Agents in
Wealth-Management Workflows
Rory Milsom
T
H
E
U
N
I
V
E
R
S
I
T
Y
O
F
E
D
I
N
B
U
R
G
H
Master of Science
School of Informatics
University of Edinburgh
2025
arXiv:2512.02230v1 [cs.AI] 1 Dec 2025
Abstract
Modern work relies on an assortment of digital collaboration tools, yet routine
processes continue to suffer from human error and delay. To address this gap, this disser-
tation extends TheAgentCompany with a finance-focused environment and investigates
whether a general-purpose LLM agent can complete representative wealth-management
tasks both accurately and economically. This study introduces synthetic domain data,
enriches colleague simulations, and prototypes an automatic task-generation pipeline.
The study aims to create and assess an evaluation set that can meaningfully measure an
agent’s fitness for assistant-level wealth management work. We construct a benchmark
of 12 task-pairs for wealth management assistants spanning retrieval, analysis, and
synthesis/communication, with explicit acceptance criteria and deterministic graders.
We seeded a set of new finance-specific data and introduced a high- vs. low-autonomy
variant of every task. The paper concluded that agents are limited less by mathematical
reasoning and more so by end-to-end workflow reliability, and meaningfully affected by
autonomy level, and that incorrect evaluation of models have hindered benchmarking.
i
Research Ethics Approval
This project was planned in accordance with the Informatics Research Ethics policy.
It did not involve any aspects that required approval from the Informatics Research
Ethics committee.
Declaration
I declare that this thesis was composed by myself, that the work contained herein is my
own except where explicitly stated otherwise in the text, and that this work has not been
submitted for any other degree or professional qualification except as specified.
(Rory Milsom)
ii
Acknowledgements
I thank Dr Alexandra Birch-Mayne and Barry Haddow for their great guidance, and
the maintainers of TheAgentCompany, OpenHands, OwnCloud, Rocket.Chat, Plane,
and EspoCRM for making this work possible. I am especially grateful to my family,
particularly my Mum and Dad for their constant encouragement and support. Finally,
I am incredibly grateful for my beautiful girlfriend for putting up with me for this
stressful year, as well as her unwavering belief in me, even when I didn’t believe in
myself.
iii
Table of Contents
1
Introduction
1
1.1
Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
1
1.2
Research Objective . . . . . . . . . . . . . . . . . . . . . . . . . . .
2
1.3
Contributions & Outcomes . . . . . . . . . . . . . . . . . . . . . . .
3
1.4
Structure of the Document
. . . . . . . . . . . . . . . . . . . . . . .
3
2
Background and Related Work
4
2.1
Agents and Autonomy
. . . . . . . . . . . . . . . . . . . . . . . . .
4
2.2
Workplace Agent Benchmarks . . . . . . . . . . . . . . . . . . . . .
5
2.3
Financial Domain Agent Evaluation . . . . . . . . . . . . . . . . . .
7
2.4
Cost–Accuracy Trade-offs in Agent Evaluation
. . . . . . . . . . . .
8
3
Methodology & System Design
9
3.1
Methodology Overview . . . . . . . . . . . . . . . . . . . . . . . . .
9
3.2
Environment for Development . . . . . . . . . . . . . . . . . . . . .
11
3.2.1
Tools and roles . . . . . . . . . . . . . . . . . . . . . . . . .
11
3.2.2
Relation to TAC architecture . . . . . . . . . . . . . . . . . .
12
3.3
The choice of EspoCRM . . . . . . . . . . . . . . . . . . . . . . . .
12
3.4
EspoCRM Deployment: Platform, Configuration, and Integration . . .
13
3.5
Task Suite Design . . . . . . . . . . . . . . . . . . . . . . . . . . . .
14
3.5.1
Preparatory work: Interviews and Research . . . . . . . . . .
14
3.5.2
Task Creation Method and Task Descriptions . . . . . . . . .
15
3.5.3
Checkpoint Design and Description . . . . . . . . . . . . . .
18
3.5.4
Checkpoint Design . . . . . . . . . . . . . . . . . . . . . . .
19
3.5.5
The Creation of Automatic Evaluators . . . . . . . . . . . . .
20
3.6
Process of Modifying Task Autonomy . . . . . . . . . . . . . . . . .
22
3.7
Data Generation . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
24
iv
3.8
NPCs and Services Creation
. . . . . . . . . . . . . . . . . . . . . .
25
3.9
Performing Evaluation with OpenHands . . . . . . . . . . . . . . . .
27
4
Results & Evaluation
28
4.1
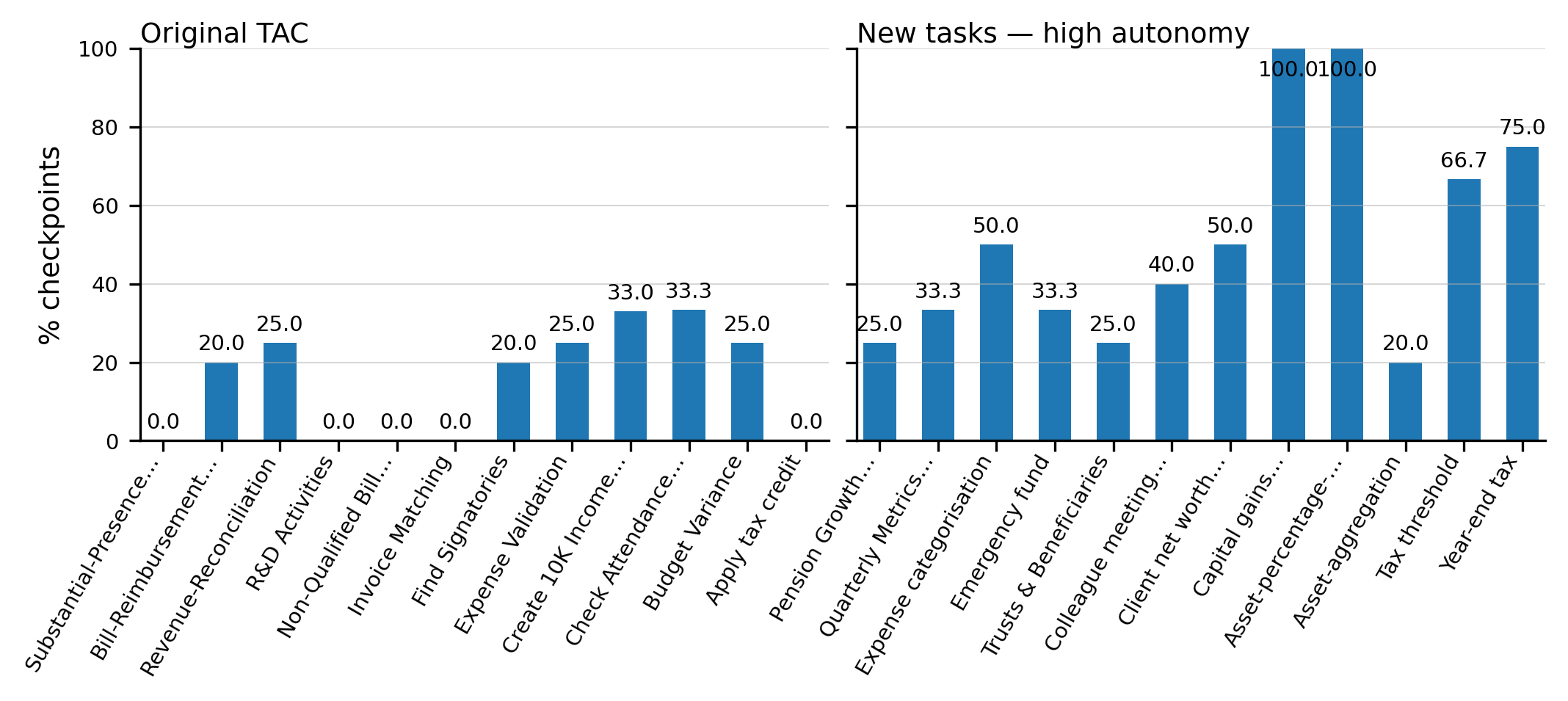
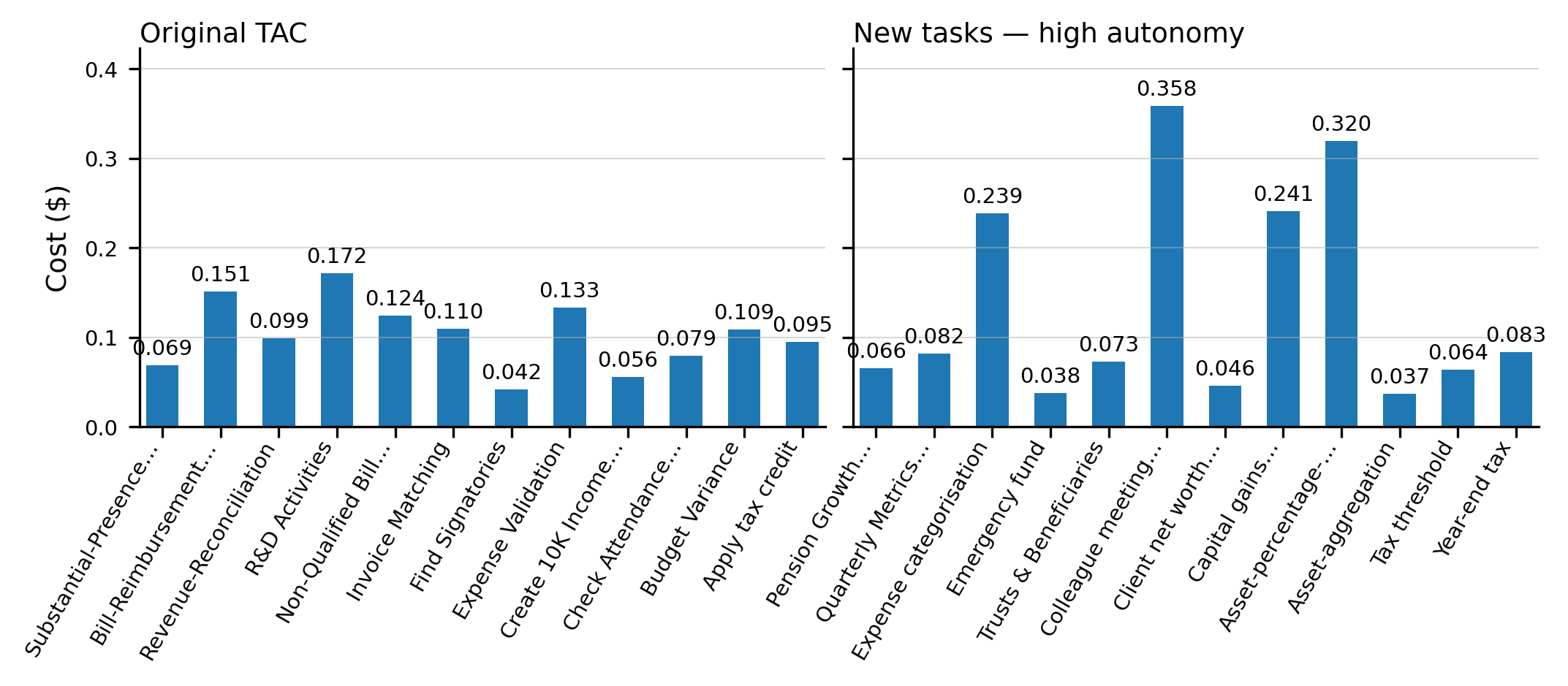
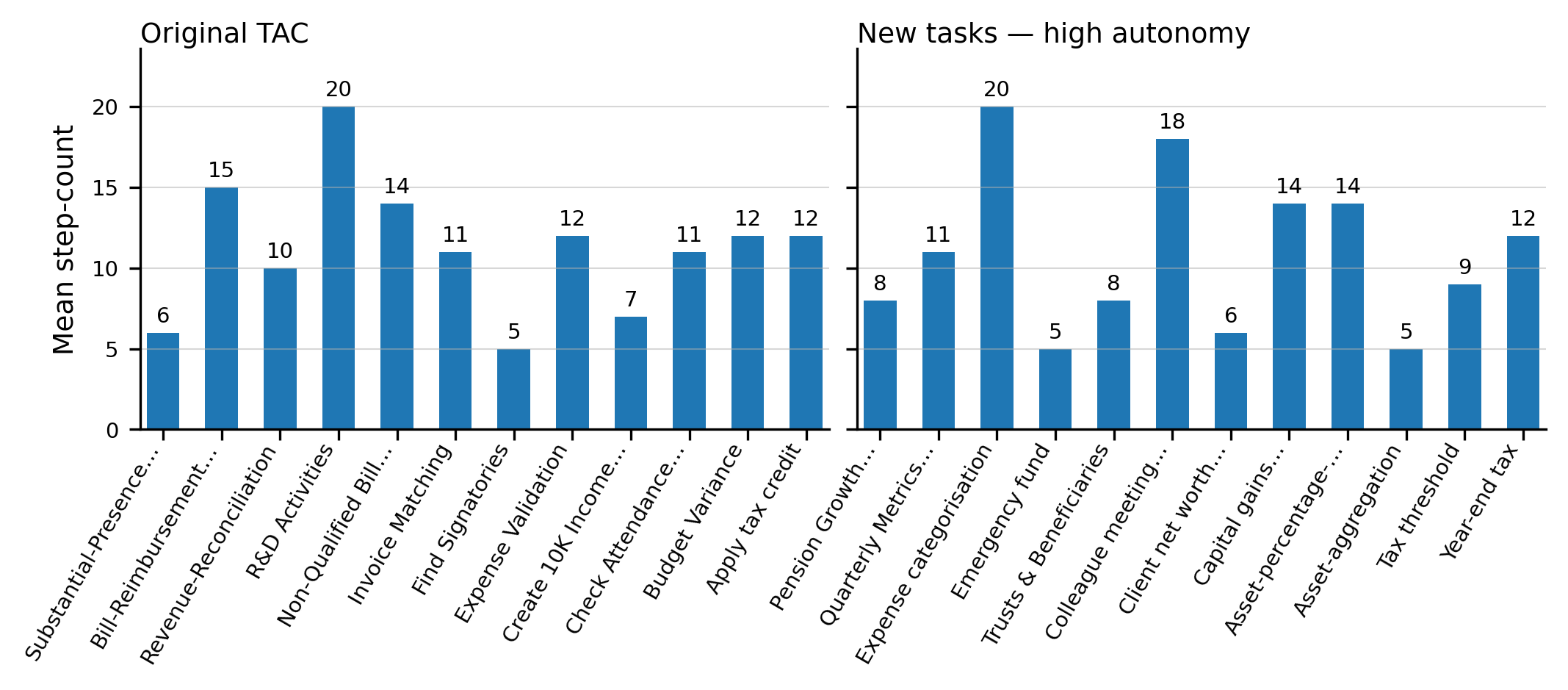
Experiment 1 – New Finance Tasks vs. Original TAC . . . . . . . . .
28
4.1.1
Quantitative Analysis . . . . . . . . . . . . . . . . . . . . . .
30
4.1.2
Qualitative Analysis
. . . . . . . . . . . . . . . . . . . . . .
32
4.2
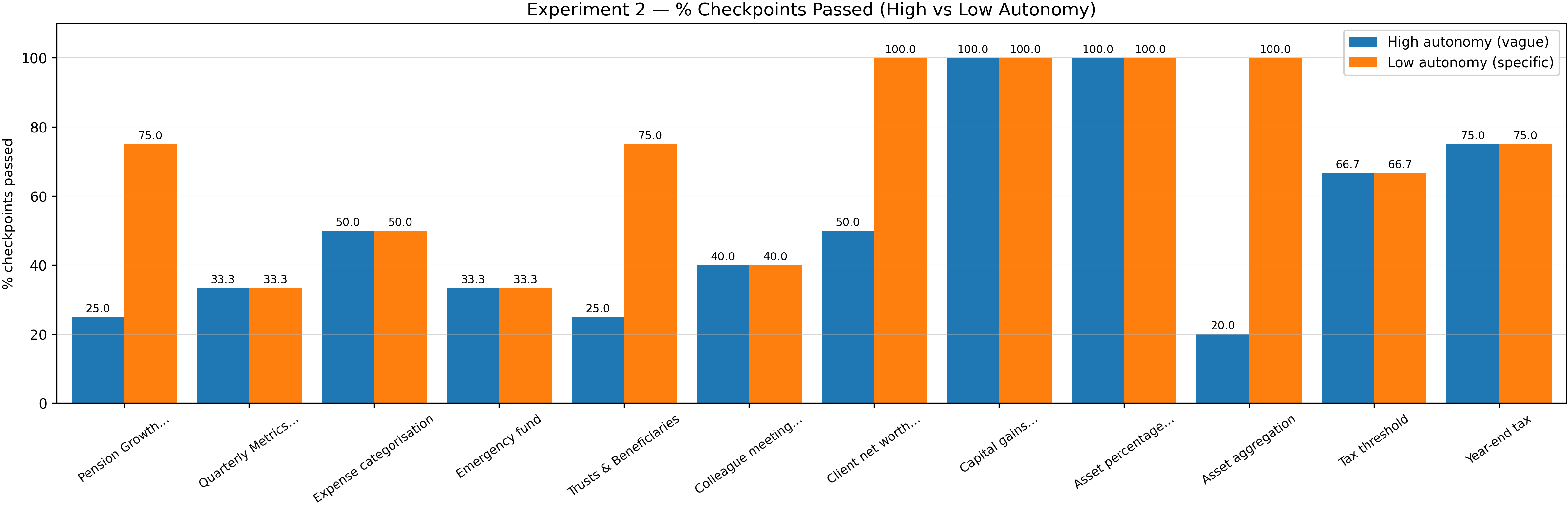
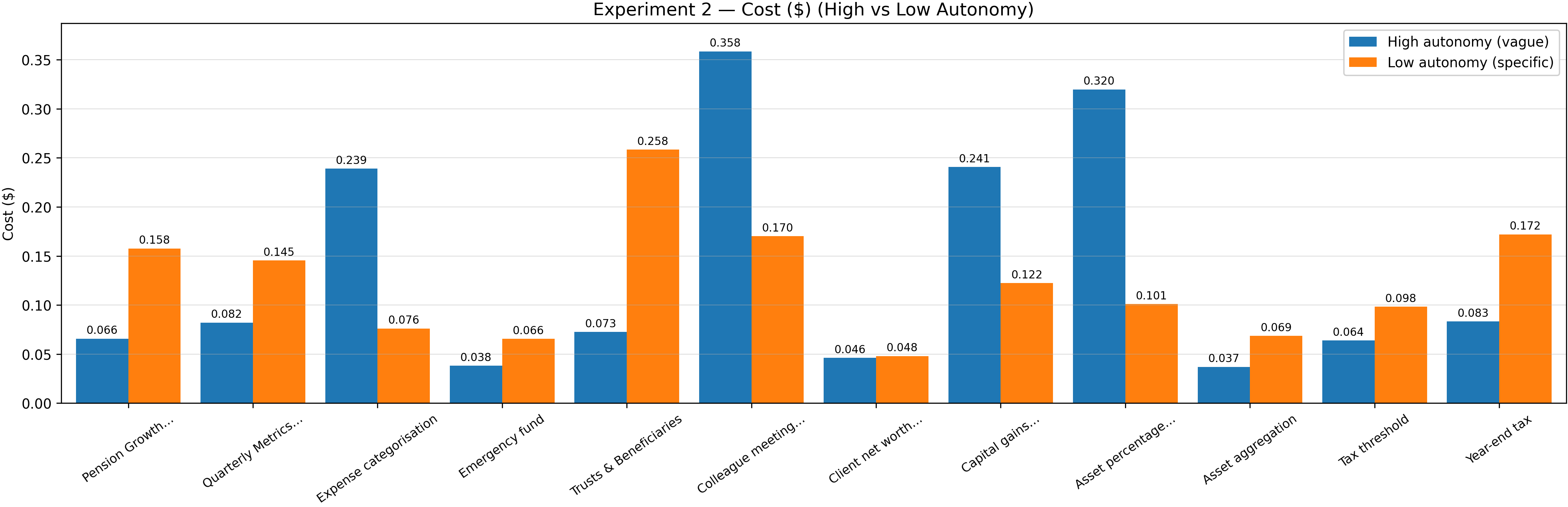
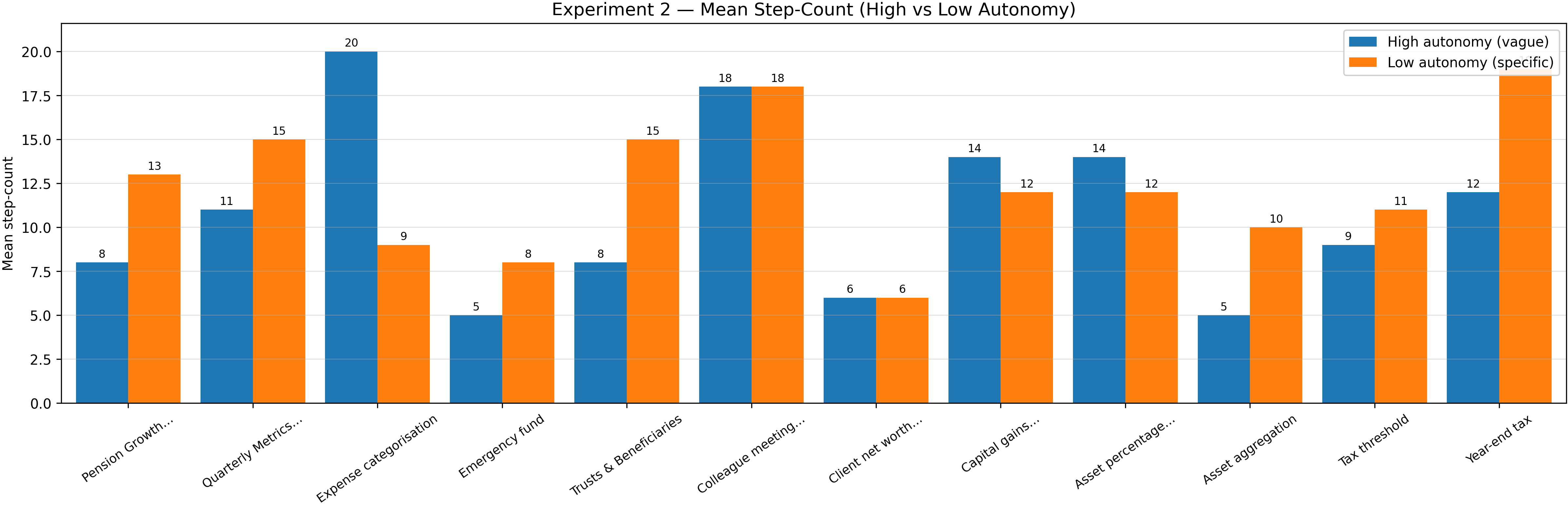
Experiment 2 – Task Autonomy Comparison . . . . . . . . . . . . . .
34
4.2.1
Quantitative Analysis . . . . . . . . . . . . . . . . . . . . . .
35
4.2.2
Qualitative Analysis
. . . . . . . . . . . . . . . . . . . . . .
37
5
Conclusion & Future Work
39
5.1
Concluding Remarks . . . . . . . . . . . . . . . . . . . . . . . . . .
39
5.2
Possible Future Research Directions . . .