Understanding how the brain responds to external stimuli and decoding this process has been a significant challenge in neuroscience. While previous studies typically concentrated on brain-to-image and brain-to-language reconstruction, our work strives to reconstruct gestures associated with speech stimuli perceived by brain. Unfortunately, the lack of paired \{brain, speech, gesture\} data hinders the deployment of deep learning models for this purpose. In this paper, we introduce a novel approach, \textbf{fMRI2GES}, that allows training of fMRI-to-gesture reconstruction networks on unpaired data using \textbf{Dual Brain Decoding Alignment}. This method relies on two key components: (i) observed texts that elicit brain responses, and (ii) textual descriptions associated with the gestures. Then, instead of training models in a completely supervised manner to find a mapping relationship among the three modalities, we harness an fMRI-to-text model, a text-to-gesture model with paired data and an fMRI-to-gesture model with unpaired data, establishing dual fMRI-to-gesture reconstruction patterns. Afterward, we explicitly align two outputs and train our model in a self-supervision way. We show that our proposed method can reconstruct expressive gestures directly from fMRI recordings. We also investigate fMRI signals from different ROIs in the cortex and how they affect generation results. Overall, we provide new insights into decoding co-speech gestures, thereby advancing our understanding of neuroscience and cognitive science.
linguistic decoding [6], [7], [8]. This area of study has garnered considerable attention in neuroscience research due to the distinctiveness of human language as an ability that is not shared by other animals. An early attempt [9] built a correspondence between brain activation and words by predicting the functional magnetic resonance imaging (fMRI) recordings associated with concrete nouns. Prior to this advancement, our understanding was limited to the discovery that distinct patterns of fMRI activities are associated with images belonging to specific semantic categories [10], [11], [12]. After more than a decade of development, the research has progressed towards more complex linguistic decoding tasks, including word decoding [7], sentence decoding [6] and speech decoding [13], [8]. However, one type of decoding that has received little attention so far is co-speech gesture. To this point, there have been no attempts made to predict continuous gestures from cortical activities.
Co-speech gestures commonly occur alongside speech, and these two elements are integral parts of human communication and understanding [14]. With conscious or unconscious gestures, speakers can better elaborate on the meanings behind the speech content [15], [16], [17], [18]. Decoding gestures from brain signals is critical to brain-computer interfaces (BCIs), which can help people who are incapacitated or speechimpaired to better communicate with others. It also provides guidance for robots and virtual entities on how to mimic human behavior. Despite its potential, this area has remained unexplored thus far. This is probably attributed to the lack of paired data encompassing brain activation recordings and gestures. Obtaining such data is highly challenging mainly due to the following reasons: 1) Some data collection devices, such as fMRI scanners, typically require subjects to remain as still as possible and avoid any noticeable head or body movements, which contradicts the natural movement in gesture collection. 2) The data collection process is time and laborconsuming. For instance, the NSD dataset [19], which is widely used for image reconstruction based on fMRI signals, required approximately one year of collection. 3) There is a limited number of volunteers, and only a small fraction of them are willing to participate in invasive recording procedures. Additionally, noise in the recorded signals and other factors further complicate the task.
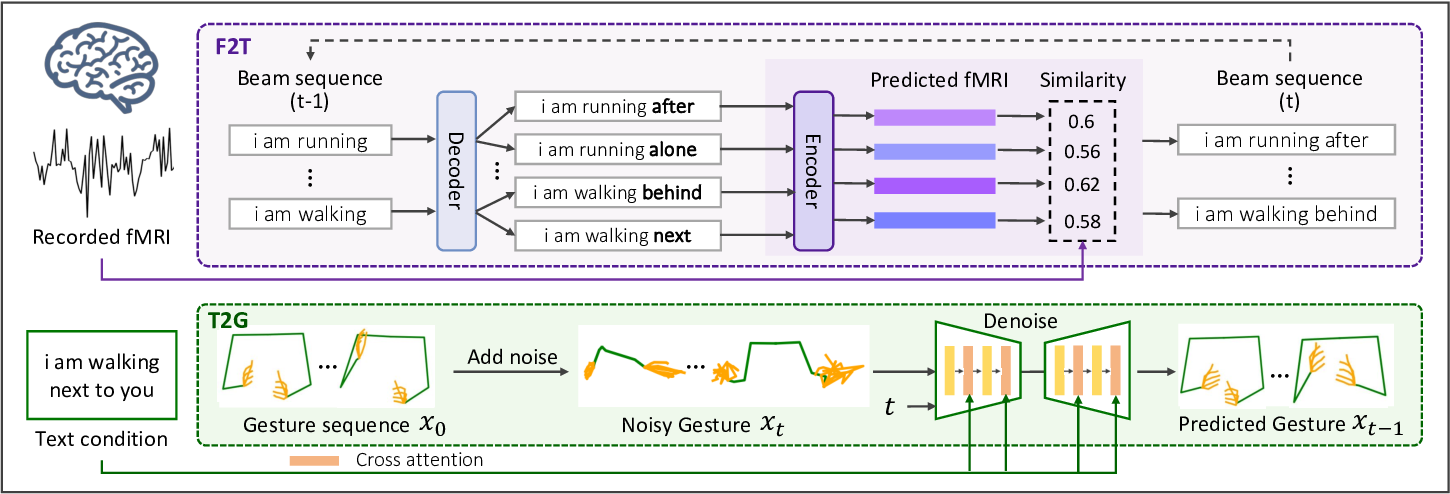
In this paper, we propose to investigate the brain-to-gesture problem and introduce spoken text as an additional modality to compensate for the data deficiency, as depicted in Fig. 1. The rationale for leveraging text modality stems from its intrinsic relationship with speech, while speech provides dynamic and real-time linguistic expressions through acoustic signals, text serves as its static written representation preserving identical semantic content. This speech-text duality establishes a natural bridge for connecting brain activities with gestures. On one hand, gestures accompanying speech are inherently synchronized with the semantic flow of spoken language. On the other hand, the availability of paired brain, text and text, gesture data allows for the exploration of the relationship between brain activities and gestures through a hybrid approach that combines both supervised and unsupervised learning. Note that our study specially focuses on conversational gestures, namely co-speech gestures, while excluding sign languages (e.g. ASL [20]) and other types of gestures. Besides, we choose to utilize fMRI data as the representation of the brain modality due to its non-invasive nature, which allows for a wider range of applicability and presents potential future applications [7].
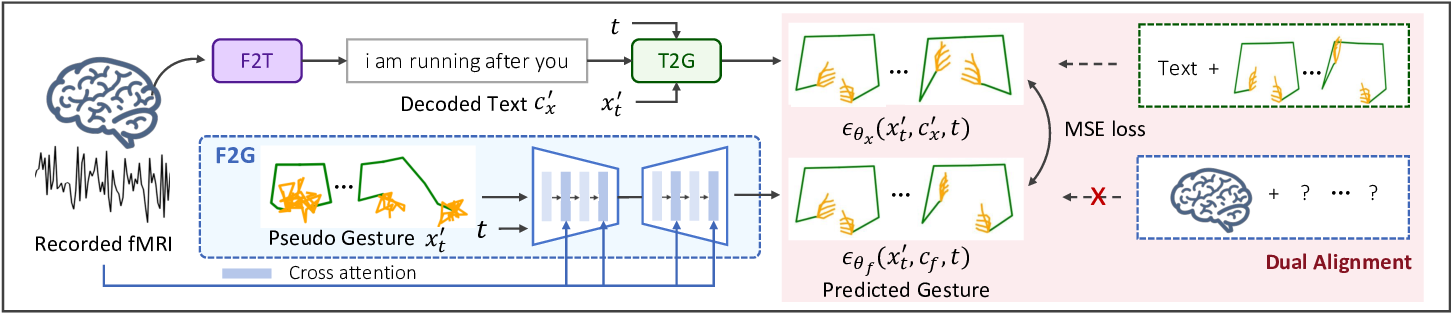
Based on the analysis mentioned above, we propose a novel approach, fMRI-to-Gesture Reconstruction with Diffusion Models (fMRI2GES), which aims to directly decode gestures from brain recordings. Rather than training a model with supervised brain-gesture data, we leverage existing paired {fMRI, text} and {text, gesture} data to train an fMRI-togesture (F2G) model using unpaired brain-gesture data and dual brain decoding alignment. Our training process comprises two phases. In the initial phase, we construct an fMRI-totext (F2T) model and a text-to-gesture (T2G) model using supervised learning methods, leveraging corresponding paired data. With these models as a guide, we transition to training the F2G model in an unsupervised manner in the second phase. Given the absence of gesture data for specific fMRI recordings, we develop a novel dual alignment strategy for training. Specifically, we input an fMRI signal into the F2T model to predict a text sequence, which is then passed into the T2G model to generate gestures as pseudo labels. Concurrently, the F2G model also utilizes the fMRI signal as input and produces several gestures. The F2G model is optimized based on the alignment of these gestures and the pse
This content is AI-processed based on open access ArXiv data.