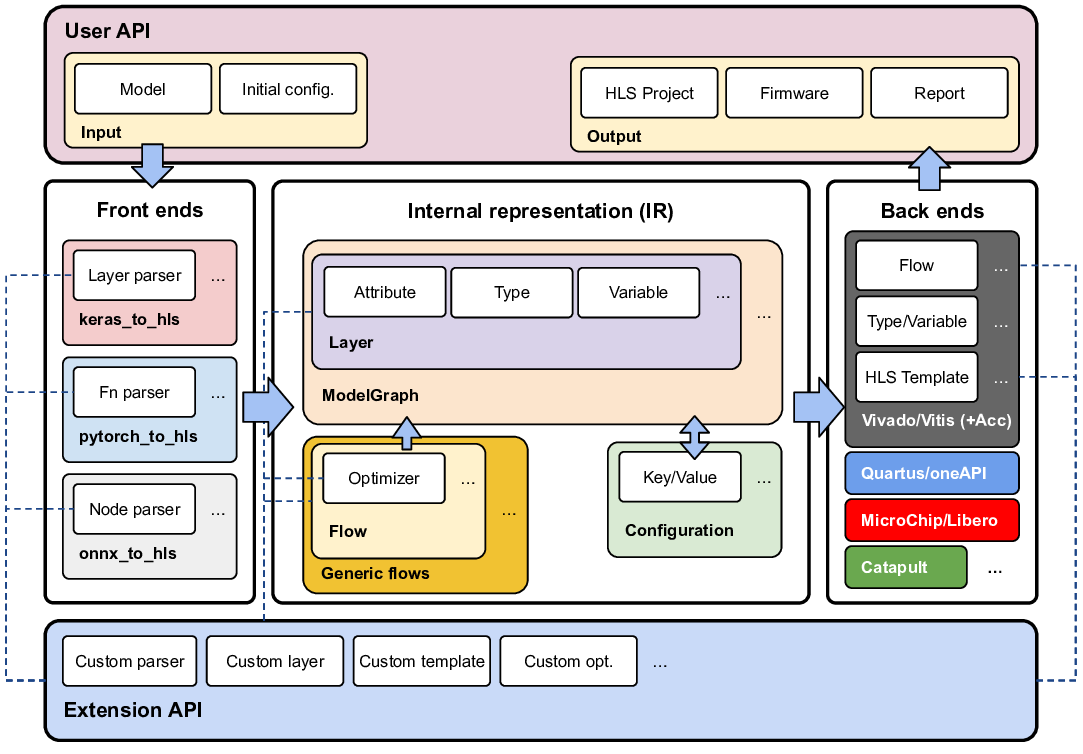
We present hls4ml, a free and open-source platform that translates machine learning (ML) models from modern deep learning frameworks into high-level synthesis (HLS) code that can be integrated into full designs for field-programmable gate arrays (FPGAs) or application-specific integrated circuits (ASICs). With its flexible and modular design, hls4ml supports a large number of deep learning frameworks and can target HLS compilers from several vendors, including Vitis HLS, Intel oneAPI and Catapult HLS. Together with a wider eco-system for software-hardware co-design, hls4ml has enabled the acceleration of ML inference in a wide range of commercial and scientific applications where low latency, resource usage, and power consumption are critical. In this paper, we describe the structure and functionality of the hls4ml platform. The overarching design considerations for the generated HLS code are discussed, together with selected performance results.
lines of Python code. Owing to hls4ml's modularity and standardized interfaces, it is straightforward to integrate it with any platform for FPGA deployment, with out-of-the-box support for commercial [5,66] or academic [97] shells.
As a platform, hls4ml can be used in two ways: first, as a deployment platform for various applications, including HEP experiments [28,29], quantum computing [14,38], network firewalls [61], self-driving cars [48], heart signal monitoring [80], and space exploration [108]. Second, hls4ml can be used as a starting point for research in efficient deep learning and hardware-model co-design [20, 92-94, 98, 118, 119, 134]. Originally presented in [41] for HEP applications at CERN, hls4ml has since grown into a widely used, open-source project for deep learning acceleration and research on custom hardware (see Section 10 for more details on hls4ml use cases and applications). The project is actively maintained with contributions from both academia and industry, is well documented and tested, and frequent supporting tutorials, workshops, and seminars are held to foster the user community.
FPGAs have emerged as suitable platforms for low-latency, low-power neural network inference, due to their low-level hardware control and high configurability. While development for ASICs is also supported in hls4ml, FPGAs are the primary target device and the focus of this paper. In the following, we present a brief overview of common design techniques for model inference on FPGAs. More in-depth overviews are given elsewhere [18,63,83].
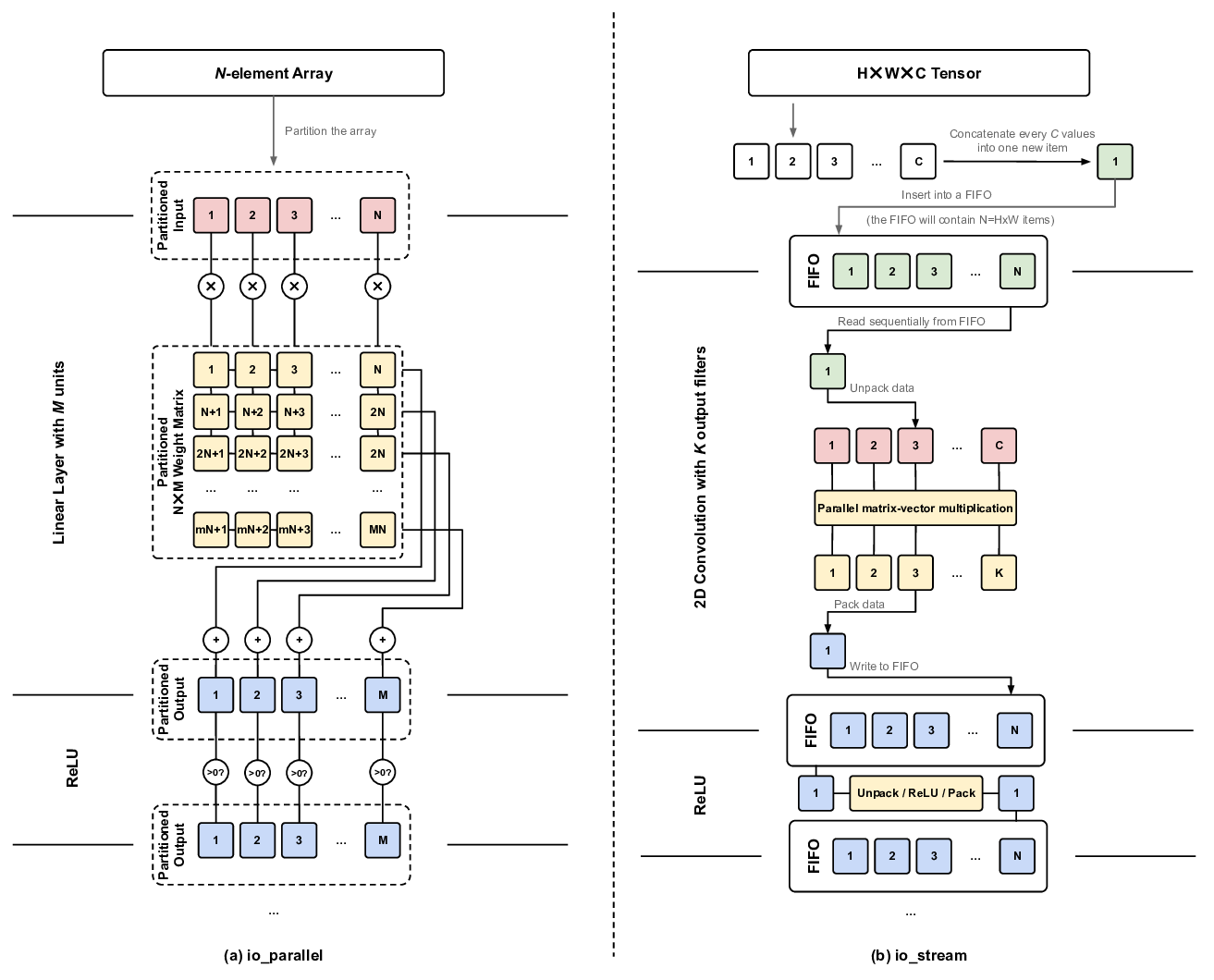
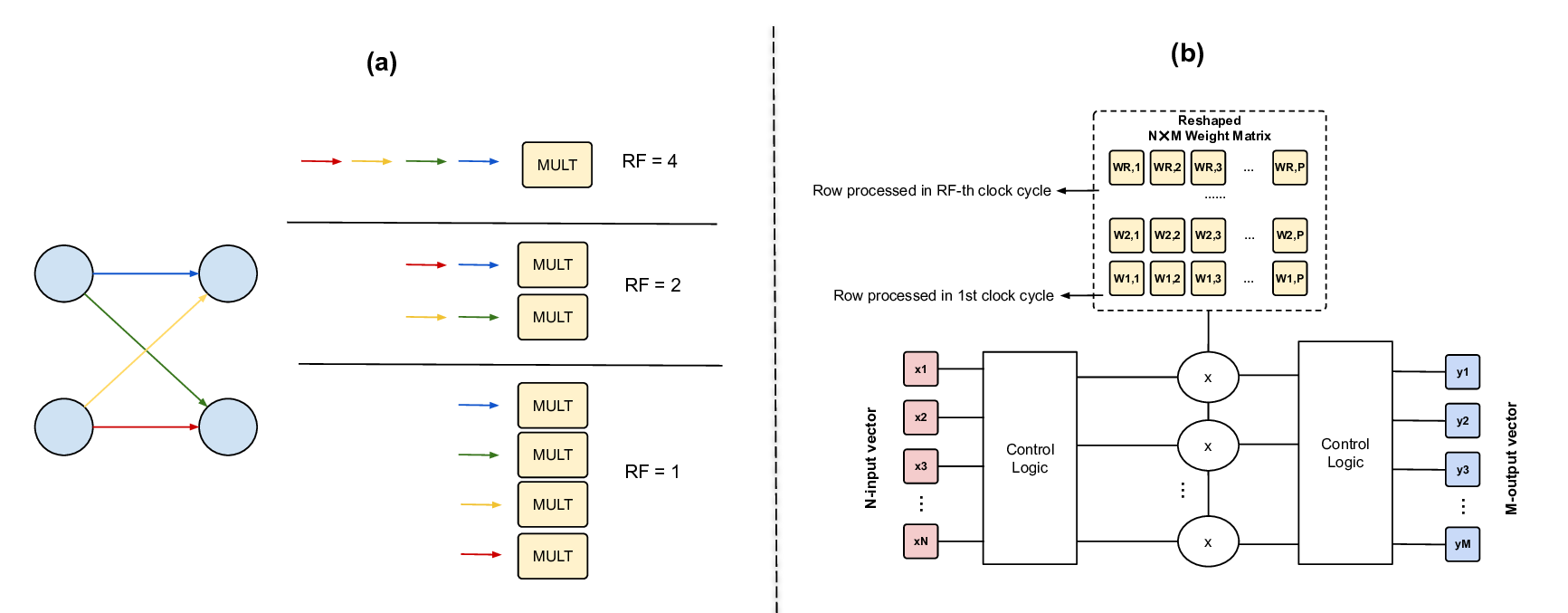
To achieve high throughput and low latency inference, there are many established design techniques. Parallelization splits the calculations between multiple processing units (PUs), for example by partitioning the input data between different instances of the layer implementations (data parallelization) or distributing the computation for the neurons of a layer between PUs (model parallelization). Pipelining partitions the calculation in depth so that, for example, subsequent layers are assigned to different PUs, allowing continuous data flow through the design. This allows the design to accept new inputs before the overall inference is completed, resulting in a low initiation interval (II). Most frameworks [15,41,110,124] use both techniques to achieve maximum performance.
Many frameworks [41,56,122] store weights and intermediate results in on-chip memory to avoid the overhead of accessing off-chip memory. These implementations can achieve very low latency and high throughput for models that fit within the limited on-chip logic resources. For larger models, such as transformers, previous studies [55,69,123] have proposed using high-bandwidth memory (HBM) on recent FPGAs.
For computations, many FPGAs include hardened digital signal processors (DSPs) optimized for multiply-accumulate (MAC) operations with wide bit-widths in deep learning models. Compared to the higher abstraction in CPU and GPU programming, arithmetic operations with these blocks reduce instruction overhead and enable more granular control over data flow. Look-up tables (LUTs) and, sometimes, fast carry chains allow implementing MAC operations without the need for dedicated multiplier blocks like DSPs, either by shift-and-add operations, such as the Booth multiplication algorithm [16], or by table look-ups for small bit-width multiplications. Recent works [10,120] propose training neural networks that can be mapped directly to FPGA LUTs, often achieving high operating frequencies and low resource usage with minimal accuracy loss.
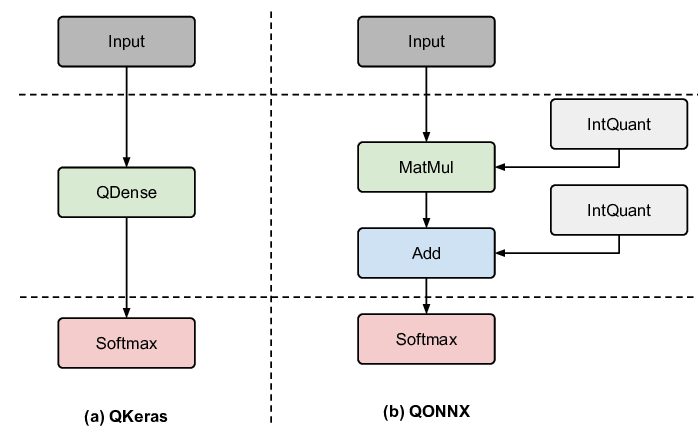
Compared to the commonly used floating-point precisions on CPUs and GPUs, FPGA designs typically represent variables in fixed-precision with lower bit-width. Quantizing a model trained with full precision to lower bit-widths with no or little retraining is known as post-training quantization (PTQ). Higher degrees of quantization can be achieved while maintaining accuracy by training the model directly with the intended bit-width, a technique known as quantization-aware training (QAT). Quantization is a method particularly suited for FPGA acceleration, as the arbitraryprecision operation can be efficiently mapped to low-level logic elements in hardware. Examples of quantization Manuscript submitted to ACM for FPGAs include heterogeneously quantized models [20,31], as well as binary and ternary models [85,120,131].
Additionally, models can also be compressed by pruning parameters, setting some weights or activations to zero. The level of pruning is selected to balance model size with an acceptable inference accuracy loss [22,93]. On FPGAs, pruning can be structured to be compatible with the low-level hardware implementation [98].
Traditionally, register-transfer level (RTL) design in languages such as VHDL, (System)Verilog, or Chisel have been used to program FPGAs. While allowing for more granular control, producing designs in this way is usually more challenging and com
This content is AI-processed based on open access ArXiv data.