This work presents a systematic characterization of Large Language Model (LLM) inference to address fragmented understanding. Through comprehensive experiments, we establish a four-dimensional analytical framework: (1) Two-Phase Heterogeneity Observation; (2) Microarchitectural Root Cause Analysis; (3) System Scaling Principles; and (4) Emerging Paradigm Boundaries. Our investigation progresses systematically from observation to foresight: identifying performance phenomena, revealing hardware causes, validating system behavior, and exploring new paradigms. This study not only consolidates a reliable empirical foundation for existing research but also provides new discoveries and practical optimization guidance for LLM inference.
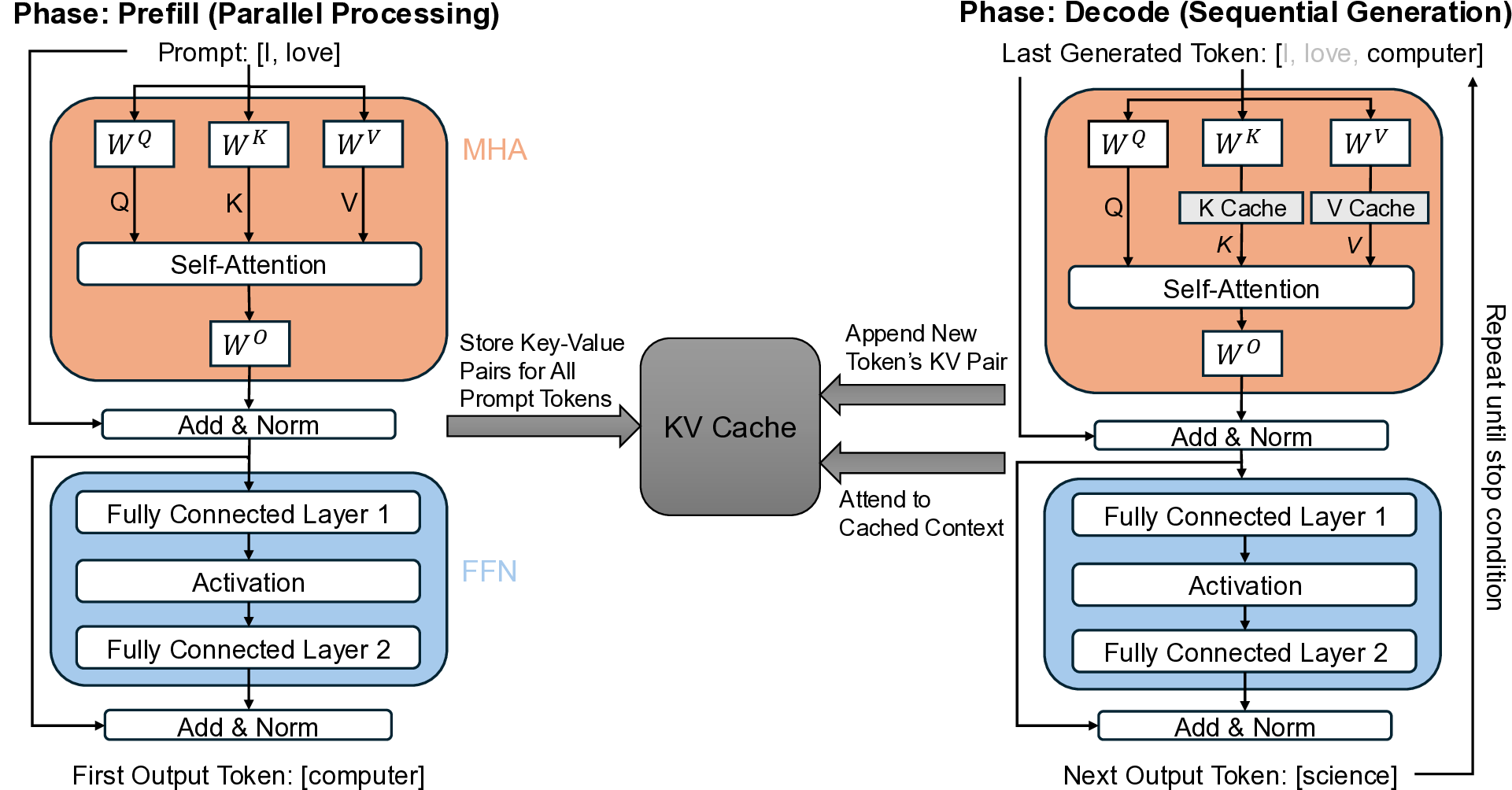
The inference of Large Language Models (LLMs) has emerged as a critical workload spanning from data centers to edge devices [6,16,36,50,55,58,60]. As LLM deployment expands across diverse applications-from real-time conversational systems [24,34,49] to complex retrieval-augmented generation [10,14,22,30] pipelines-optimizing inference efficiency has become increasingly vital [29,31,32,38,41,56,59,63]. Unlike conventional deep learning workloads, LLM inference exhibits a distinctive two-phase execution pattern: the parallelizable Prefill phase and the sequential Decode phase [25,62]. This inherent computational heterogeneity generates conflicting hardware demands that dictate system performance across latency, throughput, and energy efficiency metrics.
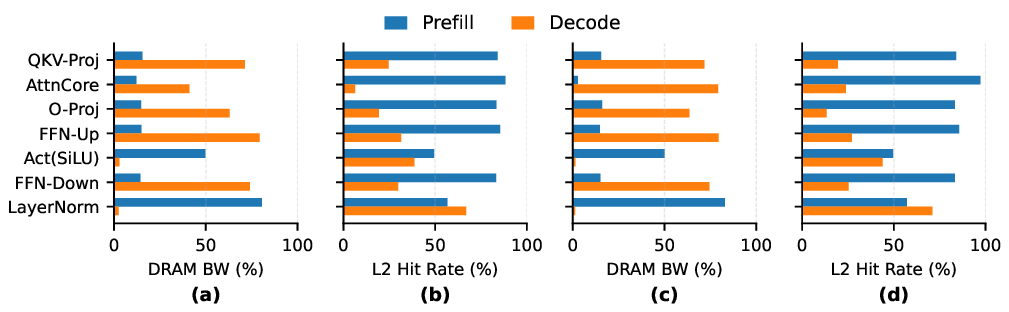
Although the compute-bound nature of Prefill and memory-bound characteristics of Decode have gained broad recognition, current research predominantly treats this dichotomy as a static assumption rather than examining it through dynamic quantitative analysis. The growing complexity of model architectures-particularly the shift toward Mixture-of-Experts (MoE) [4,11,43] paradigms-coupled with expanding deployment scenarios encompassing edge computing and sophisticated Retrieval-Augmented Generation (RAG) workflows, has further complicated the interplay between hardware constraints and software characteristics. This landscape creates a pressing need for a systematic characterization that can not only validate established understandings with rigorous microarchitectural evidence but also reveal fundamental relationships between execution patterns, memory hierarchy behavior, and energy consumption profiles.
Existing characterization studies exhibit significant fragmentation across research domains. Device-and energy-focused analyses profile platform-specific latency and power patterns [3,12,26,35,40], while quantization research examines precision-performance trade-offs [44]. Kernel-and compiler-level investigations dissect attention/GEMM operations and optimization strategies [5,7,51,57], and system-oriented studies explore serving, scheduling policies, and cache management [20, the Key and Value tensors of all preceding tokens, computing attention scores against the full history before appending the current step’s KV pairs to the cache.
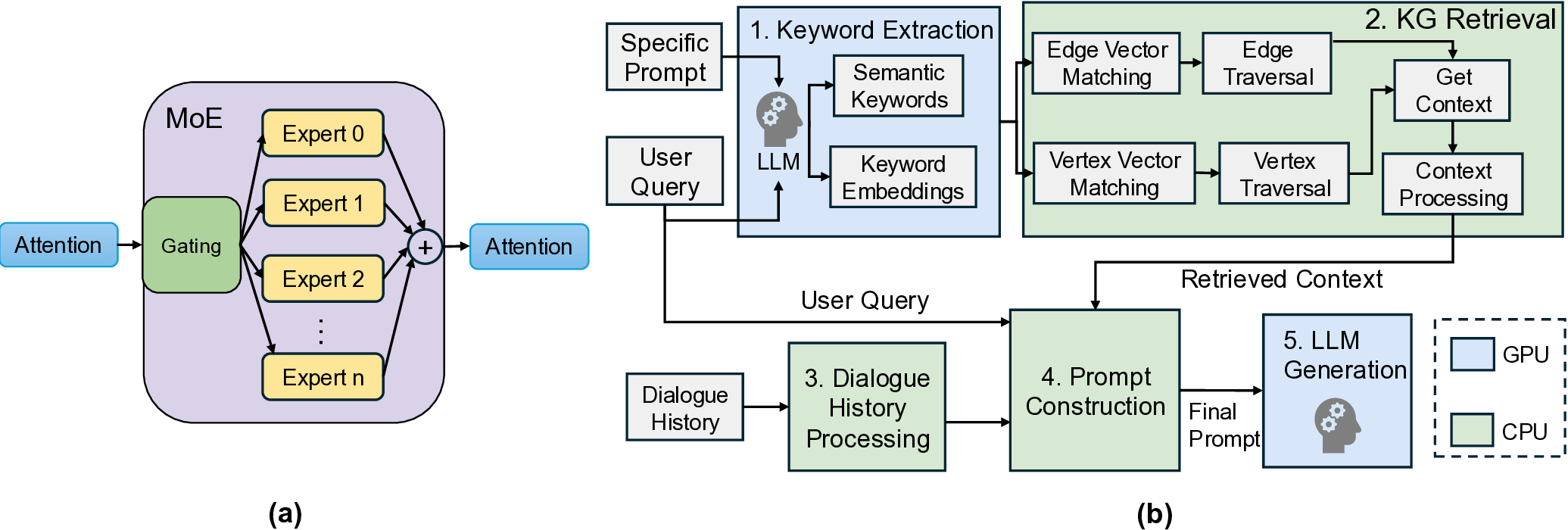
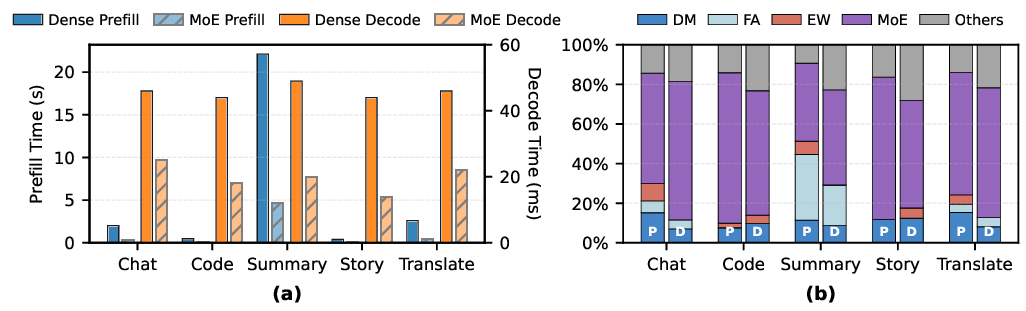
While dense Transformer architectures have dominated early LLM development, two emerging paradigms are fundamentally reshaping the computational characteristics of LLM inference. Mixture-of-Experts. MoE represents a fundamental architectural shift from dense computation to sparse activation. By replacing dense feed-forward networks with specialized expert layers, MoE architectures achieve unprecedented decoupling of model capacity from computational cost. As illustrated in Fig. 2(a), a routing network dynamically selects only the top-𝑘 experts per token, enabling massive parameter counts while activating minimal computational paths. This sparse activation dramatically reduces FLOPs per token but introduces distinct system challenges: significant routing overhead emerges during sequential Decode, while expert partitioning creates fragmented memory access patterns, establishing new phase-dependent optimization frontiers.
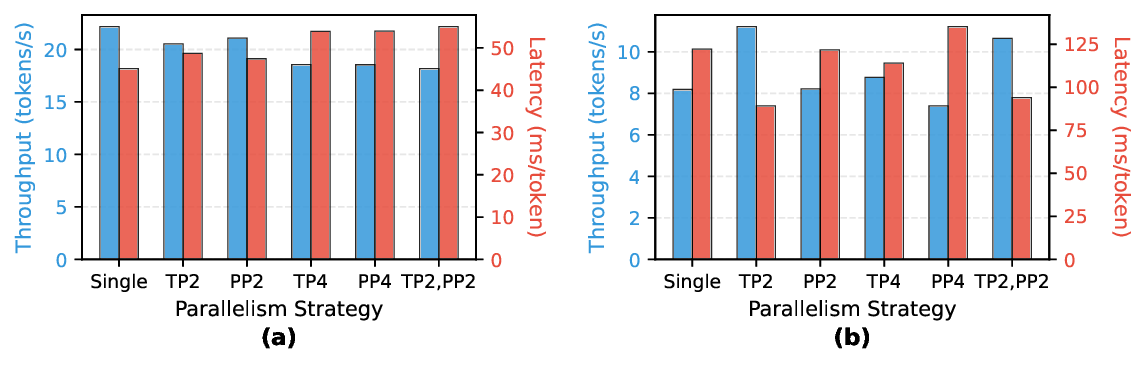
Retrieval-Augmented Generation. RAG transforms LLM inference by integrating explicit knowledge retrieval components. These systems create a heterogeneous CPU-GPU pipeline where external knowledge retrieval precedes LLM execution, fundamentally redistributing system bottlenecks. As shown in Fig. 2(b), performance constraints shift from GPU computational throughput to CPU-side retrieval latency and memory bandwidth saturation. Furthermore, the integration of retrieved knowledge substantially expands effective context length during the Prefill phase, introducing additional computational complexity and memory demands that reshape the entire inference profile.
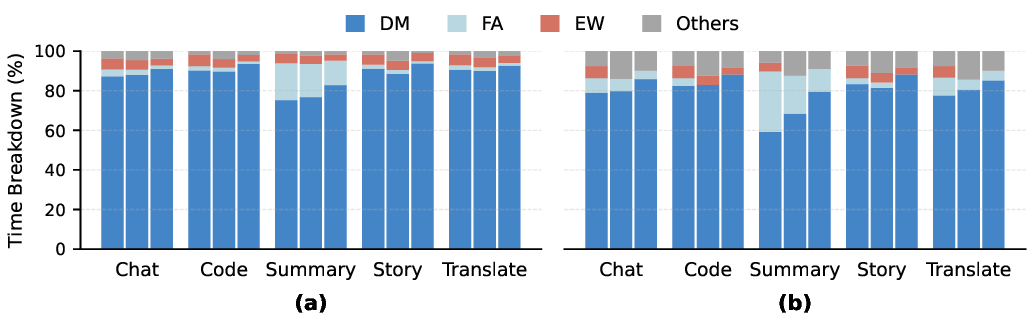
The RAG workflow comprises five distinct stages. Keyword Extraction: LLM processes the input query to extract semantic keywords and generate embeddings. Knowledge Graph (KG) Retrieval: Hybrid vector and graph-based searches retrieve relevant contextual information. Dialogue History Processing: Management and preparation of previous conversation turns. Prompt Construction: Integration of retrieved context, dialogue history, and current query into the final prompt. LLM Generation: Standard inference execution on the augmented prompt.
The KG Retrieval stage further decomposes into six functional sub-stages. Edge/Vertex Vector Matching: Compute vector similarities to identify relevant graph entities. Edge/Vertex Traversal: Navigate graph structure to expand retrieval scope. Get Context: Acquire textual content associated with retrieved entities. Context Processing: Preprocess and prepare retrieved text for integration. The matching sub-stages handle similarity computation, while the traversal and processing substages manage graph navigation and text preparation, r
This content is AI-processed based on open access ArXiv data.