LLMs and Agents have achieved impressive progress in code generation, mathematical reasoning, and scientific discovery. However, existing benchmarks primarily measure correctness, overlooking the diversity of methods behind solutions. True innovation depends not only on producing correct answers but also on the originality of the approach. We present InnoGym, the first benchmark and framework designed to systematically evaluate the innovation potential of AI agents. InnoGym introduces two complementary metrics: performance gain, which measures improvement over the best-known solutions, and novelty, which captures methodological differences from prior approaches. The benchmark includes 18 carefully curated tasks from real-world engineering and scientific domains, each standardized through resource filtering, evaluator validation, and solution collection. In addition, we provide iGym, a unified execution environment for reproducible and long-horizon evaluations. Extensive experiments show that while some agents produce novel approaches, their lack of robustness limits performance gains. These results highlight a key gap between creativity and effectiveness, underscoring the need for benchmarks that evaluate both.
In recent years, LLMs (Jaech et al., 2024;DeepSeek-AI et al., 2025a) and Agents (Wang et al., 2024;Guo et al., 2024) have made rapid progress in areas such as code generation (Jain et al., 2025;Chen et al., 2021), mathematical reasoning (Hendrycks et al., 2021;Cobbe et al., 2021), and scientific discovery (Majumder et al., 2025;Jing et al., 2025). However, most existing benchmarks focus solely on whether an answer is correct. Under this paradigm, any output that passes test cases or matches the reference answer is deemed successful. Yet intelligence and innovation lie not only in the results, but also in the methods: two agents may arrive at the same correct answer while following entirely different approaches. Such methodological differences are often overlooked in current evaluation frameworks.
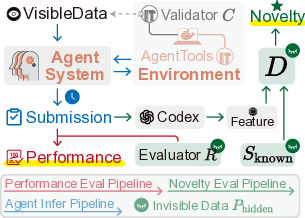
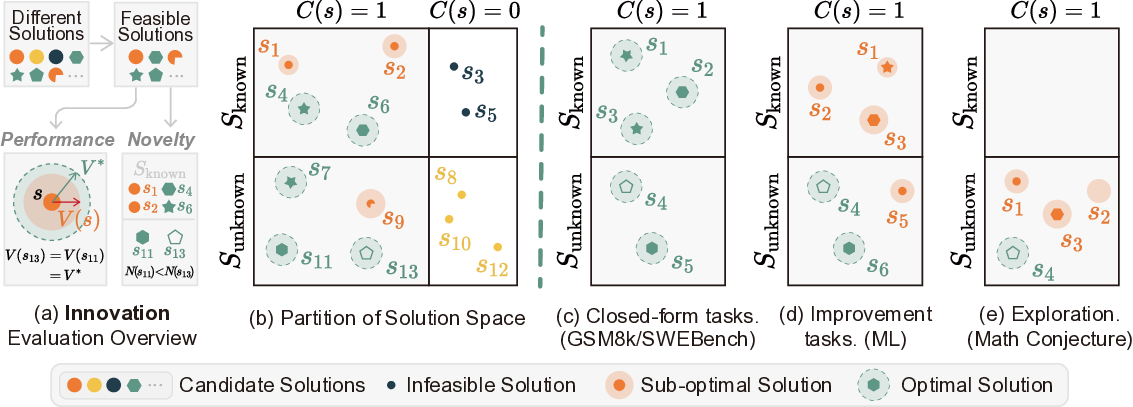
To address this gap, we propose a framework for evaluating innovation that formalizes each task as a quadruple (P, S, V, D). Here, P denotes the problem instance, S the solution space, V the performance measure, and D the measure of dissimilarity between solutions. On top of this formulation, we introduce two key metrics: Performance gain G and Novelty N . Performance gain G quantifies the improvement of a solution relative to the best-known baseline, while Novelty N captures the methodological difference between a new solution and prior ones. Together, these metrics enable us to assess both performance breakthroughs and methodological innovation.
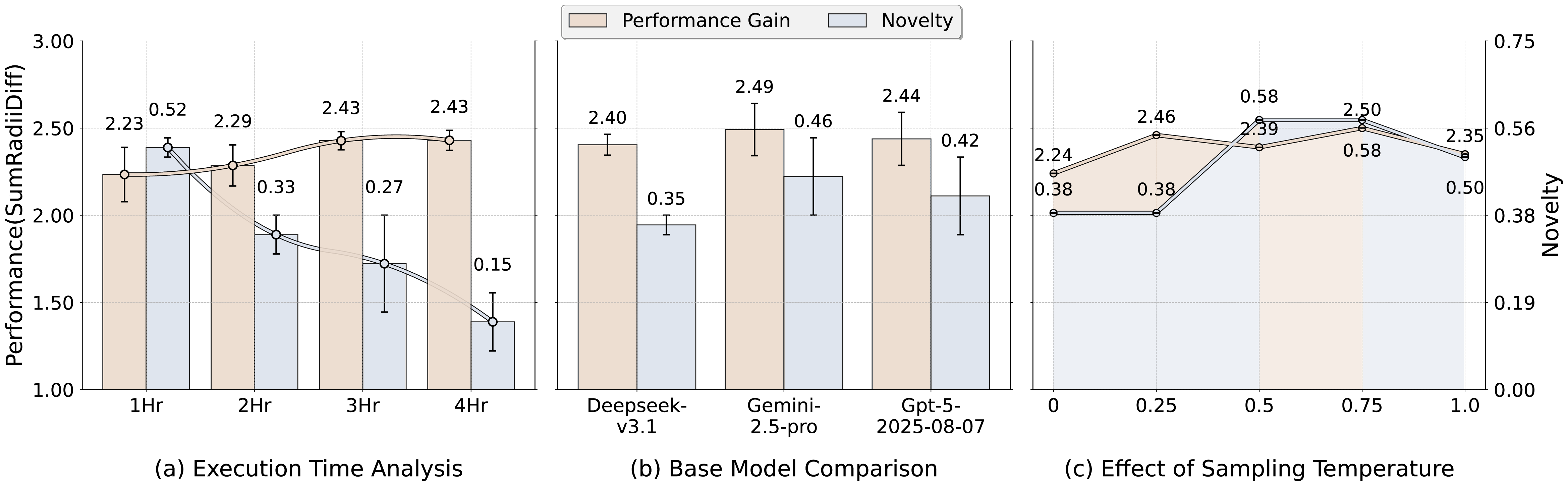
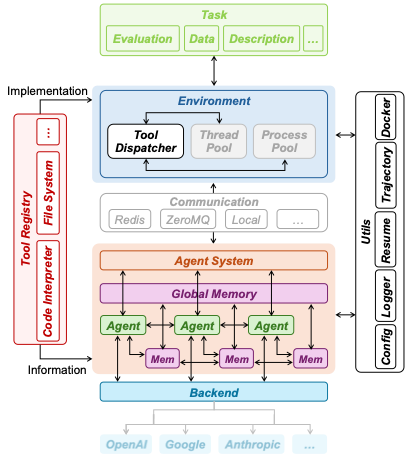
Our contributions can be summarized as follows: 1) We propose a principled framework for defining and measuring innovation in AI agents, combining performance gain and novelty as two complementary evaluation dimensions. 2) We introduce InnoGym, the first benchmark specifically targeting innovation potential, consisting of 18 standardized Improvable Tasks curated from real-world engineering and scientific domains. 3) We provide iGym, a unified agent execution environment that supports reproducible, long-horizon evaluations across diverse systems. 4) We conduct systematic experiments on state-of-the-art agents, uncovering key limitations in robustness and highlighting the gap between novelty and effective performance.
In summary, InnoGym establishes both a principled framework and a standardized benchmark for measuring innovation in AI agents, offering a reproducible and cross-domain platform to support future research on systematically evaluating AI’s creative and innovative capabilities. Most existing benchmarks judge agents by answer correctness, overlooking the solution that yields the answer. Existing benchmarks for intelligent agents primarily focus on the correctness of the final answer, neglecting the underlying solution used to obtain it. Yet intelligence and innovation lie not only in what is achieved, but in how. Two agents may output the same answer for a problem while one employs a fundamentally novel solution. This section introduces a framework for quantifying innovation in terms of its performance and novelty.
We define a task as a quadruple T = (P, S, V, D), where:
• Problem instance P contains the task description, constraints, objectives, and evaluation artifacts (e.g., ground-truth answer or test cases). Agents observe P visible ⊂ P . P hidden = P \ P visible is for evaluation only.
• Solution space S is the set of executable solutions s ∈ S that can be submitted to solve P (e.g., code, a proof/derivation, an algorithmic strategy).
• Performance V : S → R quantifies the quality of a solution. We define it as V (s) = C(s) • R(s), where C(s) ∈ {0, 1} checks feasibility or legality (format, execution, constraint satisfaction) and R(s) measures the degree to which a feasible solution satisfies the problem’s objective (e.g., accuracy, pass rate).
• Distance D : S × S → R ≥0 measures dissimilarity between two solutions. A larger value implies greater dissimilarity in the underlying solution. Conceptually, D can be any task-appropriate dissimilarity function (e.g., an embedding-based distance). In our implementation, we instantiate D as an Agent-as-judge score that compares two solutions. See Appendix E for details.
We denote prior-known (human or literature) solutions by S known ⊆ S and the unknown region by S unknown = S \ S known . For brevity, we omit the task subscript on (P, S, V, D). Then we can define the optimal solution set S * that achieves the maximal performance score V * :
However, the optimum S * is often unknown, intractable, or may not exist for many challenging tasks. Our framework therefore grounds its evaluation in the empirical and dynamic set S known , encompassing the best known solutions ranging from fixed theoretical optima to the evolving SOTA.
What constitutes innovation? The management theorist Peter Drucker famously defined innovation as “change that creates a new dimension of performance.” Inspired by this insight, we formalize innovation within our task framework. We define a candidate solution s as innovative if, subje
This content is AI-processed based on open access ArXiv data.