Story2MIDI: Emotionally Aligned Music Generation from Text
Reading time: 5 minute
...
📝 Original Info
Title: Story2MIDI: Emotionally Aligned Music Generation from Text
ArXiv ID: 2512.02192
Date: 2025-12-01
Authors: Mohammad Shokri, Alexandra C. Salem, Gabriel Levine, Johanna Devaney, Sarah Ita Levitan
📝 Abstract
In this paper, we introduce Story2MIDI, a sequence-to-sequence Transformer-based model for generating emotion-aligned music from a given piece of text. To develop this model, we construct the Story2MIDI dataset by merging existing datasets for sentiment analysis from text and emotion classification in music. The resulting dataset contains pairs of text blurbs and music pieces that evoke the same emotions in the reader or listener. Despite the small scale of our dataset and limited computational resources, our results indicate that our model effectively learns emotion-relevant features in music and incorporates them into its generation process, producing samples with diverse emotional responses. We evaluate the generated outputs using objective musical metrics and a human listening study, confirming the model's ability to capture intended emotional cues.
💡 Deep Analysis
📄 Full Content
Story2MIDI: Emotionally Aligned Music
Generation from Text
Mohammad Shokri
The Graduate Center, CUNY
New York, US
mshokri@gradcenter.cuny.edu
Alexandra C. Salem
The Graduate Center, CUNY
New York, US
asalem1@gradcenter.cuny.edu
Gabriel Levine
The Graduate Center, CUNY
New York, US
glevine@gradcenter.cuny.edu
Johanna Devaney
Brooklyn College, CUNY
New York, US
johanna.devaney@brooklyn.cuny.edu
Sarah Ita Levitan
Hunter College, CUNY
New York, US
slevitan@hunter.cuny.edu
Abstract—In this paper, we introduce Story2MIDI, a sequence-
to-sequence Transformer-based model for generating emotion-
aligned music from a given piece of text. To develop this model,
we construct the Story2MIDI dataset by merging existing datasets
for sentiment analysis from text and emotion classification in mu-
sic. The resulting dataset contains pairs of text blurbs and music
pieces that evoke the same emotions in the reader or listener.
Despite the small scale of our dataset and limited computational
resources, our results indicate that our model effectively learns
emotion-relevant features in music and incorporates them into
its generation process, producing samples with diverse emotional
responses. We evaluate the generated outputs using objective
musical metrics and a human listening study, confirming the
model’s ability to capture intended emotional cues.
I. INTRODUCTION
We live in a world with an ever-growing demand for
entertainment and multimedia content. The rise of social
media and platforms for music, audio-books, and podcasts has
gained tremendous momentum. At the heart of many of these
forms of entertainment lies a narrative, a story that drives
the experience, whether in a film, a game, a podcast, or a
documentary. Narratives are powerful tools for evoking emo-
tion. As audiences engage with a story, they often experience
a dynamic emotional journey shaped by the characters [1],
[2], plot developments [3], and underlying themes [4]. This
emotional progression within a story, is integral to the impact
that stories have on readers and viewers. The emotional affect
of a story is integral to the impact that it has on readers and
viewers. Just like stories, music also has a remarkable impact
on listeners’ emotional states [5] and is widely recognized
as a means of expressing emotions [6], [7]. Because of
this emotional power, creative producers often accompany
narratives with background music, which has been shown to
significantly influence the audience’s emotional engagement
and enhance the immersive quality of the content [8], [9]. With
the rapid progress of AI in various modalities, new models are
introduced on a daily basis, capable of generating content in
different modalities.
The goal of our research is to develop a model capable
of generating music that aligns with a given story, thereby
enhancing its emotional impact. Narratives are complex, often
guiding readers or viewers through evolving emotional arcs.
Ideally, an effective model should be able to mirror this emo-
tional trajectory and reinforce the story’s intended affective
experience through music. However, this problem remains un-
derexplored, in part due to the lack of large-scale datasets that
pair narrative text with emotionally aligned music. As a first
step towards our goal, this study focuses on generating music
that captures the holistic emotional tone of a piece of text. In
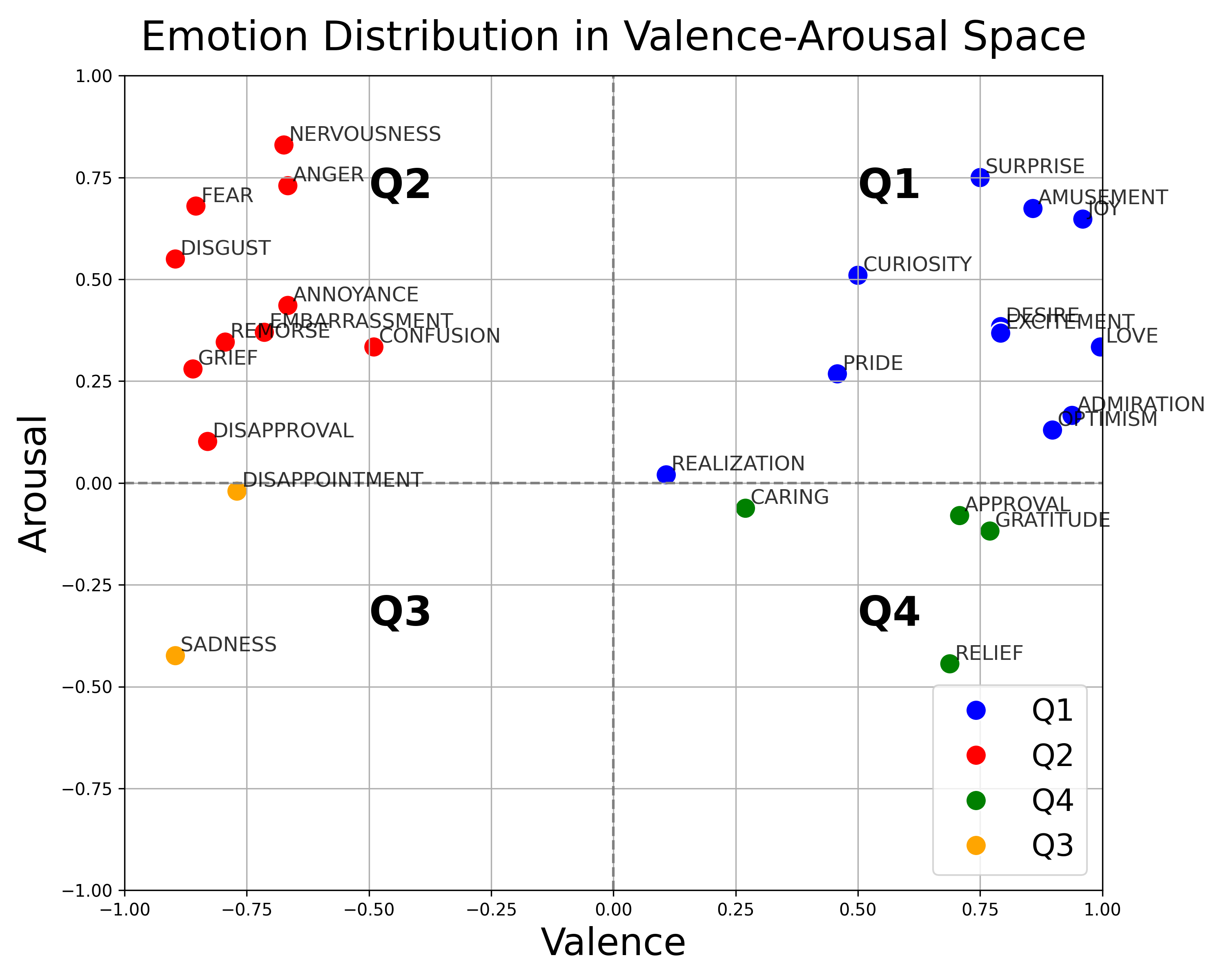
this study, we collect text blurbs from an existing sentiment
analysis dataset annotated by humans. Using these sentences,
we build a dataset of emotionally aligned story–music pairs.
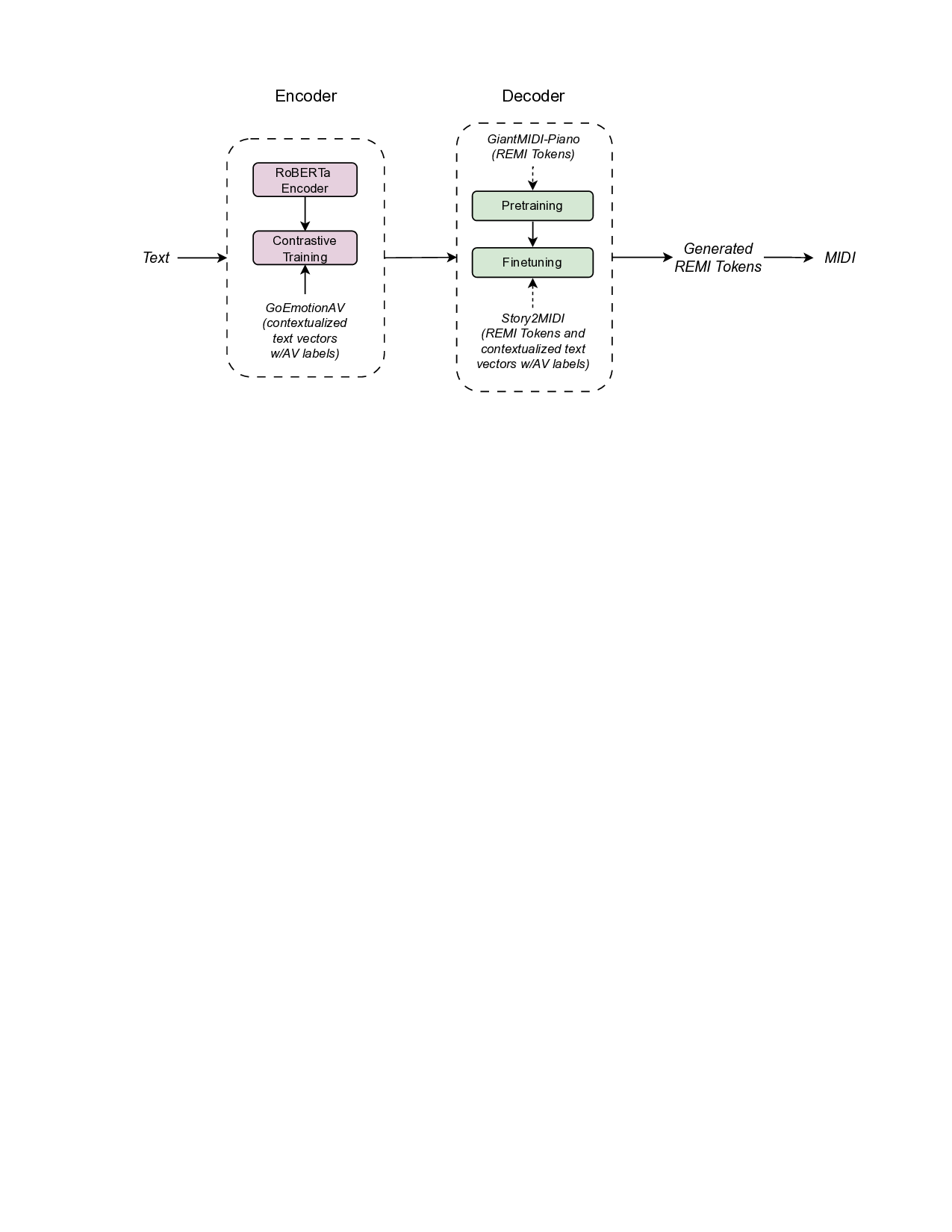
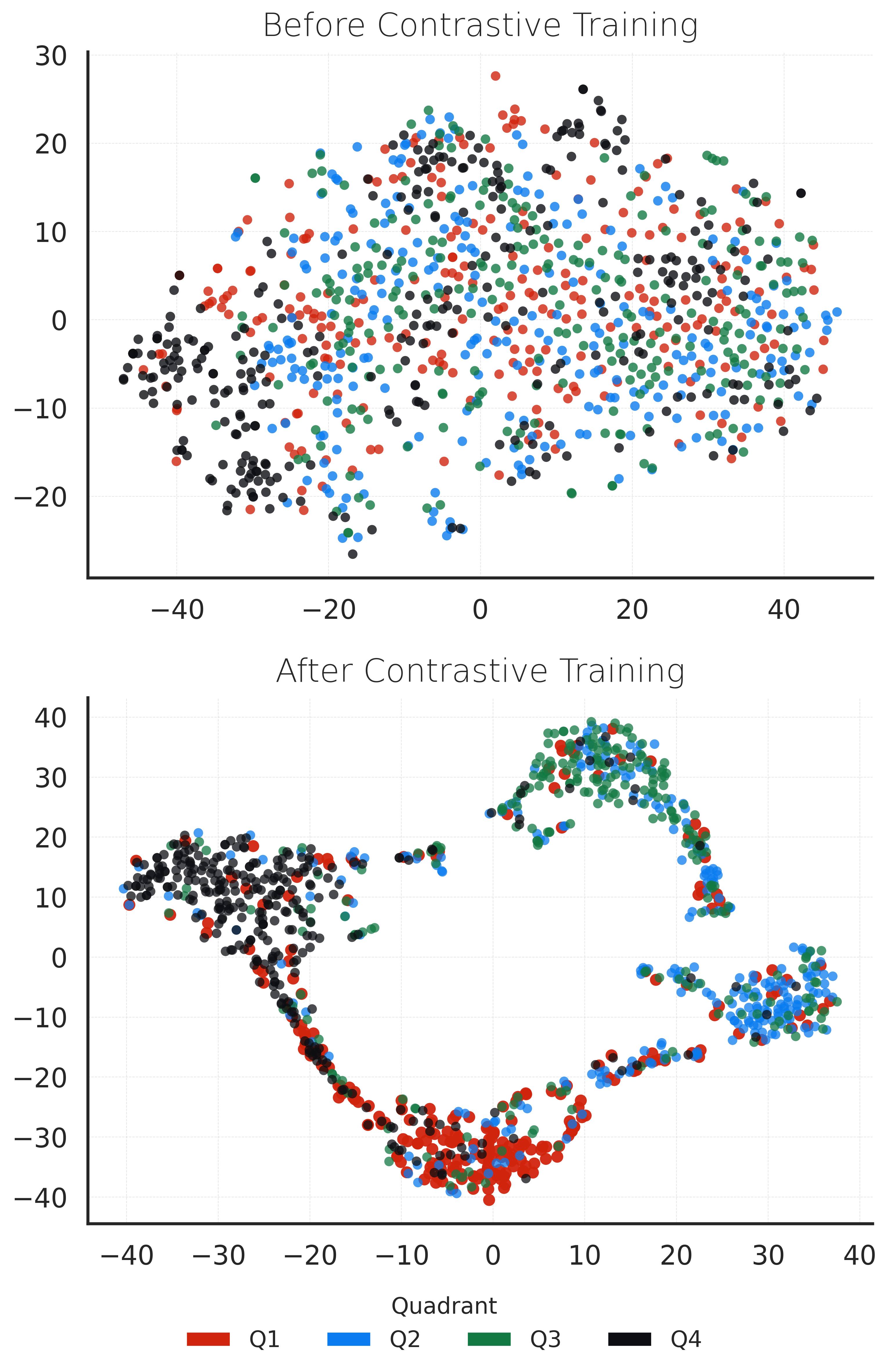
We then propose a Transformer-based encoder–decoder model
[10] that generates music intended to evoke the same emotion
as the input text. To ensure the model learns the structure
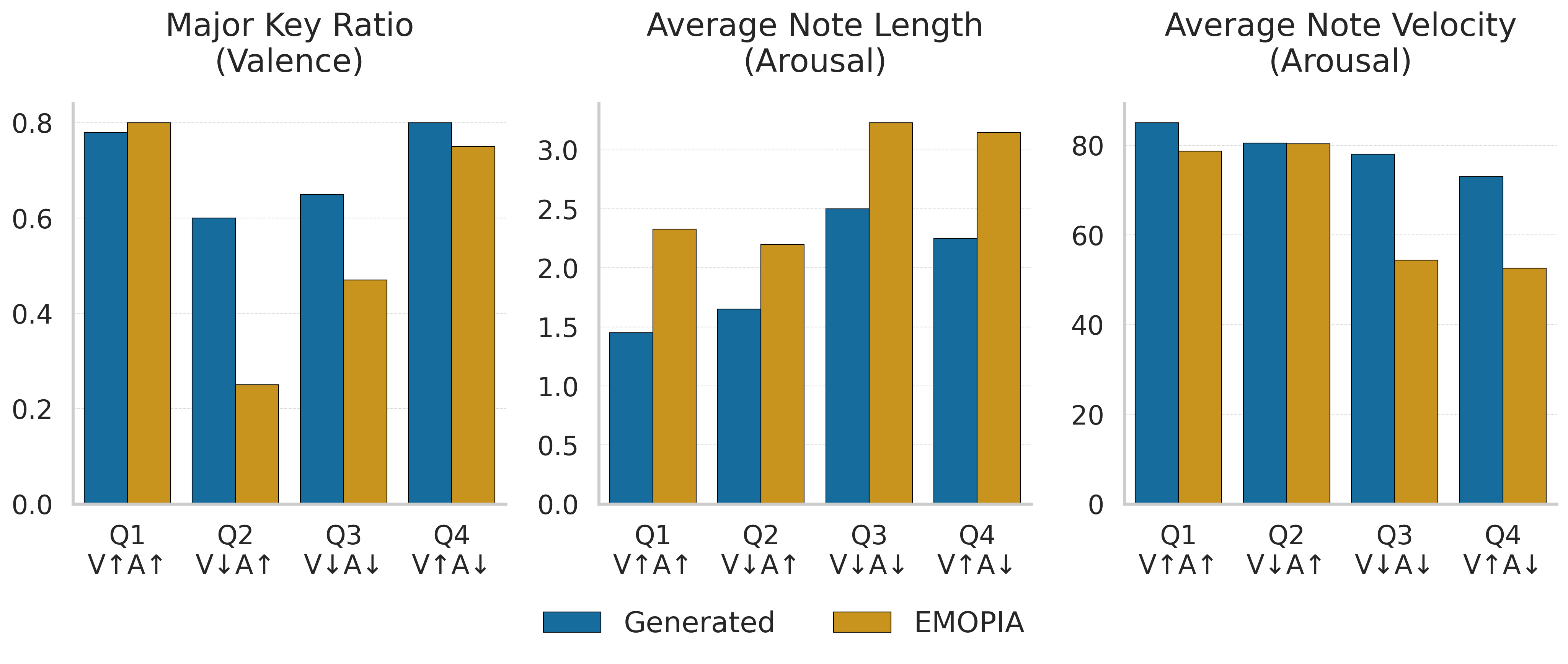
of symbolic music, we pre-train the decoder on a large-scale
symbolic music dataset before fine-tuning it on our emotion-
aligned data.
II. RELATED WORK
Affective Music Generation (AMG) refers to computational
methods for composing music that reflects or evokes emotions,
with applications in healthcare [11]–[13], co-creativity, and
entertainment [14], [15]. Prior work categorizes AMG ap-
proaches into rule-based, data-driven, optimization-based, and
hybrid systems [16]. Rule-based methods rely on predefined
mappings between musical features and emotional states [17],
[18], whereas data-driven approaches learn such mappings
from data using deep learning models. Recent transformer-
based architectures [10] have greatly improved the ability to
model long-term temporal structure and musical coherence,
outperforming earlier Markov chain and LSTM-based meth-
ods. Building on these advances, several transformer-based
systems have been developed for symbolic music genera-
tion [19]–[21], demonstrating the capacity of self-attention to
capture long-range harmonic and rhythmic patterns. Among
arXiv:2512.02192v1 [cs.SD] 1 Dec 2025
symbolic systems, MINUET [22] generates sentence-level,
mood-conditioned music from text using a Markov chai