Title: Delta Sum Learning: an approach for fast and global convergence in Gossip Learning
ArXiv ID: 2512.01549
Date: 2025-12-01
Authors: Tom Goethals, Merlijn Sebrechts, Stijn De Schrijver, Filip De Turck, Bruno Volckaert
📝 Abstract
Federated Learning is a popular approach for distributed learning due to its security and computational benefits. With the advent of powerful devices in the network edge, Gossip Learning further decentralizes Federated Learning by removing centralized integration and relying fully on peer to peer updates. However, the averaging methods generally used in both Federated and Gossip Learning are not ideal for model accuracy and global convergence. Additionally, there are few options to deploy Learning workloads in the edge as part of a larger application using a declarative approach such as Kubernetes manifests. This paper proposes Delta Sum Learning as a method to improve the basic aggregation operation in Gossip Learning, and implements it in a decentralized orchestration framework based on Open Application Model, which allows for dynamic node discovery and intent-driven deployment of multi-workload applications. Evaluation results show that Delta Sum performance is on par with alternative integration methods for 10 node topologies, but results in a 58% lower global accuracy drop when scaling to 50 nodes. Overall, it shows strong global convergence and a logarithmic loss of accuracy with increasing topology size compared to a linear loss for alternatives under limited connectivity.
💡 Deep Analysis
📄 Full Content
Delta Sum Learning: an approach for fast and
global convergence in Gossip Learning
Tom Goethals, Merlijn Sebrechts, Stijn De Schrijver, Filip De Turck and Bruno Volckaert
Ghent University - imec, IDLab
Gent, Belgium
ORCID: 0000-0002-1332-2290, 0000-0002-4093-7338, N/A, 0000-0003-4824-1199, 0000-0003-0575-5894
Abstract—Federated Learning is a popular approach for dis-
tributed learning due to its security and computational benefits.
With the advent of powerful devices in the network edge,
Gossip Learning further decentralizes Federated Learning by
removing centralized integration and relying fully on peer to
peer updates. However, the averaging methods generally used in
both Federated and Gossip Learning are not ideal for model
accuracy and global convergence. Additionally, there are few
options to deploy Learning workloads in the edge as part
of a larger application using a declarative approach such as
Kubernetes manifests. This paper proposes Delta Sum Learning
as a method to improve the basic aggregation operation in Gossip
Learning, and implements it in a decentralized orchestration
framework based on Open Application Model, which allows for
dynamic node discovery and intent-driven deployment of multi-
workload applications. Evaluation results show that Delta Sum
performance is on par with alternative integration methods for
10 node topologies, but results in a 58% lower global accuracy
drop when scaling to 50 nodes. Overall, it shows strong global
convergence and a logarithmic loss of accuracy with increasing
topology size compared to a linear loss for alternatives under
limited connectivity.
Index Terms—gossip learning, artificial intelligence, ai, edge
learning, federated learning
I. INTRODUCTION
Federated Learning (FL) has since long improved the
training of Artificial Intelligence (AI) models by enabling
distributed training on huge datasets while integrating the
results at a central location, resulting in reduced training times
and practical use of larger datasets. This is achieved through
any number of integration methods, most popularly averaging
methods (e.g. Federated Averaging or FedAvg). With the rise
of edge computing, there is a push to further decentralize AI
training through Gossip Learning (GL), which eliminates the
centralized aggregation and relies on each node to spread its
updates to the rest of the cluster by proxy, thus gossip. GL may
be useful for various reasons; data may be processed at the
source to reduce privacy concerns, spare computational capac-
ity from dedicated hardware may be leveraged, etc. However,
GL has certain inefficiencies compared to FL, for example,
updates must be sent to several nodes instead of a single
centralized location. Furthermore, because the distribution of
training data and received updates is likely asymmetrical,
Research funded by Flanders Research Foundation Junior Postdoctoral
Researcher grant number 1245725N, and the NATWORK Horizon Europe
project.
models are likely to diverge during training. As a result, GL
requires the integration of the full model whereas some FL
approaches only send changed parameters to reduce network
traffic. To counteract this, GL nodes should send updates to
as few others as possible, which in turn leads to slower or
possibly no global convergence, especially if not all nodes in
a gossip cluster are mutually known. Furthermore, standard
averaging approaches may result in statistical anomalies (e.g.
vanishing variance), which lead to slower training conver-
gence, as well as lower accuracy. As such, there is a need for
integration methods that provide strong global convergence,
through minimal and local communication with other nodes.
In terms of framework support, ML workloads are strongly
supported in cloud environments. For example, KubeFlow
enables MLOps in Kubernetes clusters, automating workload
deployment and management using Kubernetes manifests on
up to hundreds of nodes. However, edge learning lacks the
same support; solutions such as Azure IoT Edge and OpenEI
generally only enable edge intelligence, and in limited cases
edge learning, whereas most recent studies focus on edge
learning specifically through FL, or are aimed at specialized
use cases that only leverage learning workloads. As such, there
is a clear need for a framework that enables GL in the edge as
a part of larger applications, while allowing Kubernetes-like
modeling of workloads.
This paper examines the fundamental integration operation
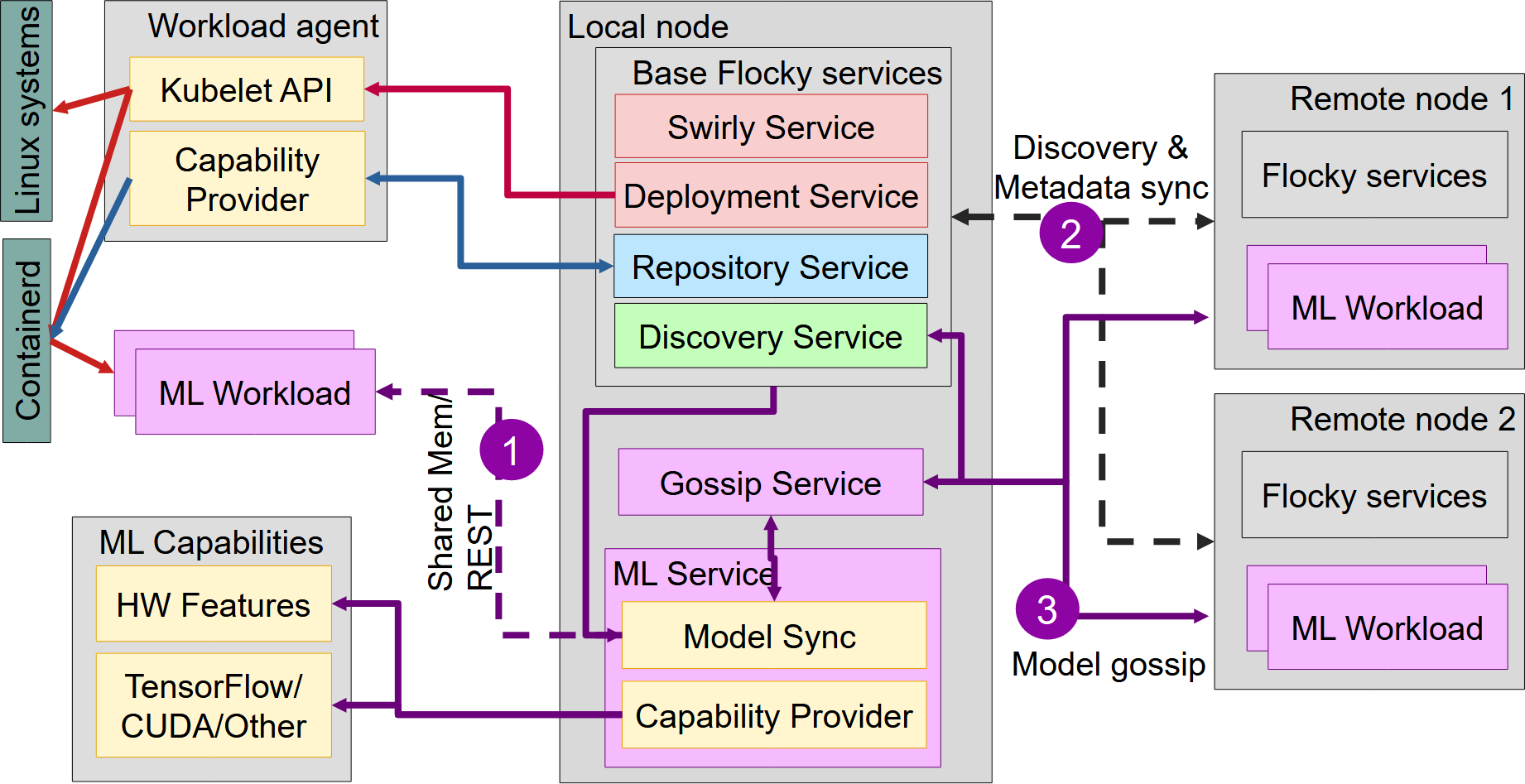
used by FL and GL, proposing Delta Sum Learning to improve
global convergence. Additionally, this method is integrated
into a decentralized intent-based framework for edge workload
deployment, including Gossip and ML services to support GL.
Concretely, the contributions of this paper are:
• Improving Gossip Learning through Delta Sum Learning
to provide better and faster global convergence with
minimal local communication.
• Integrating the improvements into a prototype framework
for online edge learning and di