Audio-based depression detection models have demonstrated promising performance but often suffer from gender bias due to imbalanced training data. Epidemiological statistics show a higher prevalence of depression in females, leading models to learn spurious correlations between gender and depression. Consequently, models tend to over-diagnose female patients while underperforming on male patients, raising significant fairness concerns. To address this, we propose a novel Counterfactual Debiasing Framework grounded in causal inference. We construct a causal graph to model the decision-making process and identify gender bias as the direct causal effect of gender on the prediction. During inference, we employ counterfactual inference to estimate and subtract this direct effect, ensuring the model relies primarily on authentic acoustic pathological features. Extensive experiments on the DAIC-WOZ dataset using two advanced acoustic backbones demonstrate that our framework not only significantly reduces gender bias but also improves overall detection performance compared to existing debiasing strategies.
Depression is a serious mental disorder that impairs cognitive and behavioral functions and increases suicide risk [1]. The World Health Organization [2] reported a global prevalence of about 4% in 2021, causing an estimated annual productivity loss of one trillion dollars. Therefore, early depression diagnosis is critically important. Traditional diagnostic methods mainly rely on subjective scales such as the Patient Health Questionnaire-8 (PHQ-8) [3] and the Beck Depression Inventory (BDI) [4], as well as structured interviews by clinicians [5]. However, due to limited medical expertise and healthcare resources [1], many patients struggle to receive timely diagnosis.
In recent years, automated depression detection based on artificial intelligence has gained increasing attention. Among various modalities, audio-based methods show great potential due to easy data acquisition, low cost, and non-invasiveness. Models like wav2vec 2.0 [6] have been successfully applied to learn effective speech representations, forming a strong foundation for high-performance depression detection.
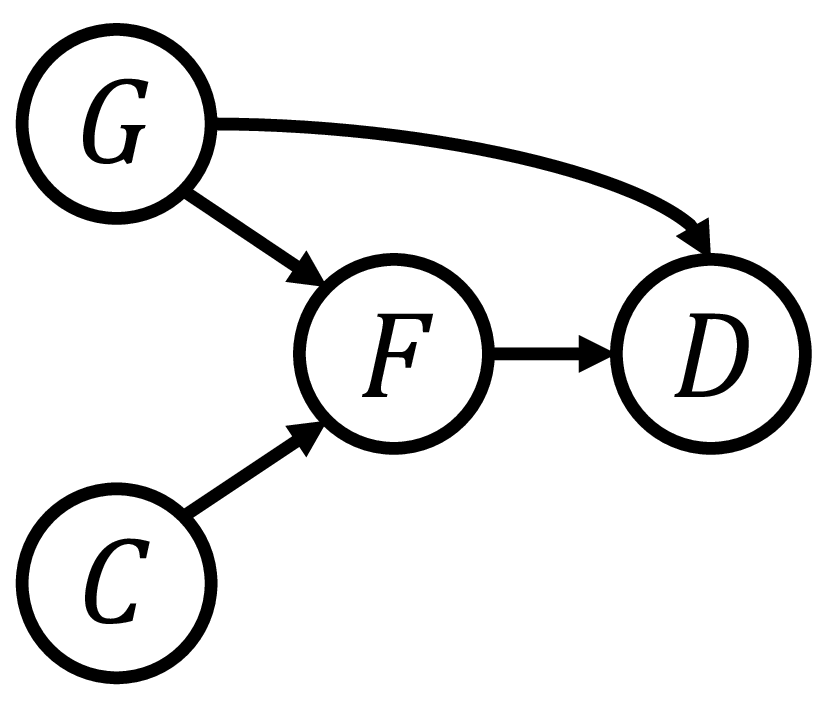
However, deep learning model performance heavily depends on training data quality and distribution. A crucial but often overlooked issue is that these models can unintentionally learn and amplify inherent data biases. In depression research, epidemiological data show female depression prevalence is about twice that of males [7], causing a gender imbalance in datasets, where female samples, especially those diagnosed with depression, significantly exceeding the number of male samples. This bias may lead models to rely more on gender information rather than true pathological voice features in depression detection. Consequently, the model tends to overdiagnose female patients [8] while exhibiting lower recognition accuracy for male patients [9], which raises significant fairness and ethical concerns. Given the serious consequences, it is crucial to adopt effective mitigation methods.
Regarding the issue of gender bias, researchers have proposed several mitigation strategies, most of which are preprocessing (data-level) approaches. For example, Bailey and Plumbley [10] enforced a balanced number of samples across different classes in the training set by sub-sampling the majority group. In addition, Cheong et al. [11] proposed a featurelevel data augmentation technique to synthesize new virtual samples. However, these methods only adjust superficial data distribution and fail to break the spurious causal link between gender and depression within the model’s decision process. Therefore, more systematic approachs are needed to eliminate such bias.
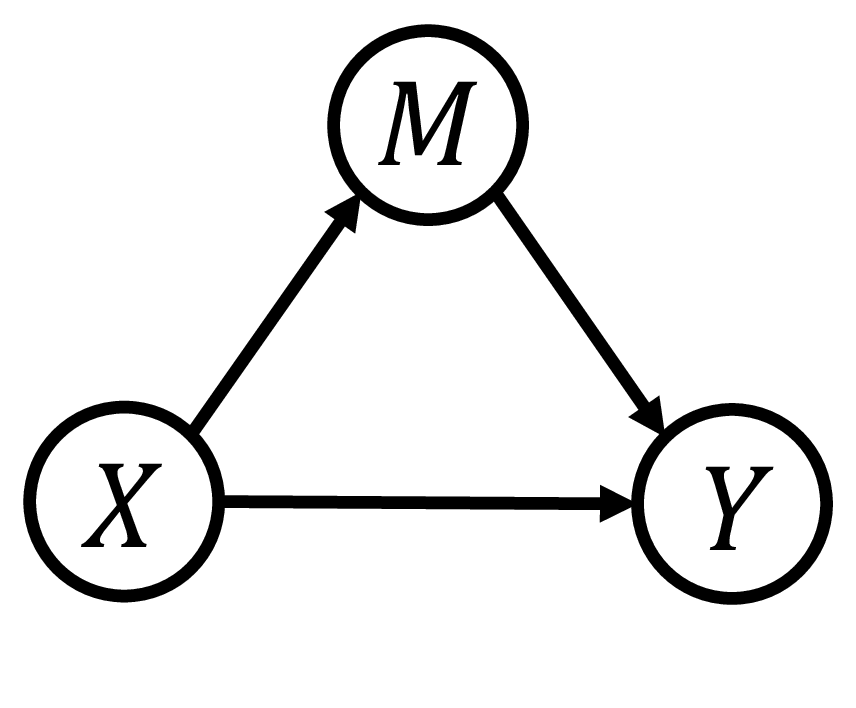
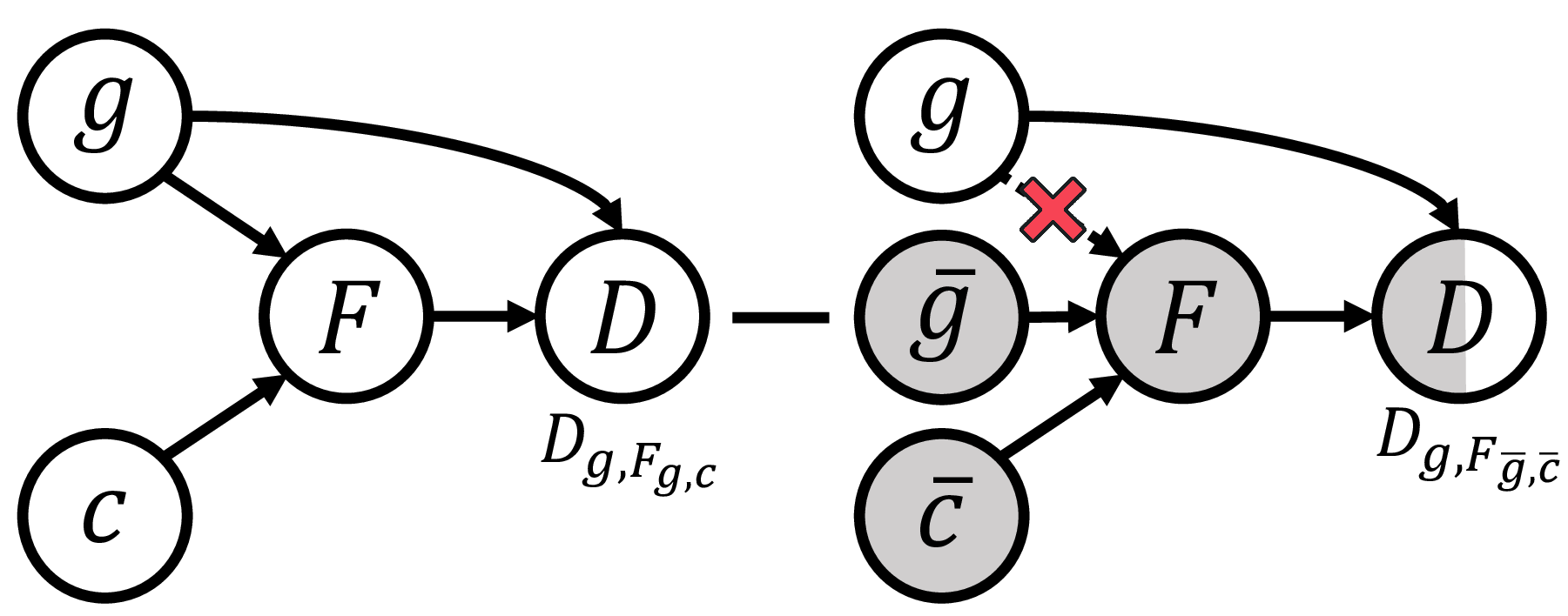
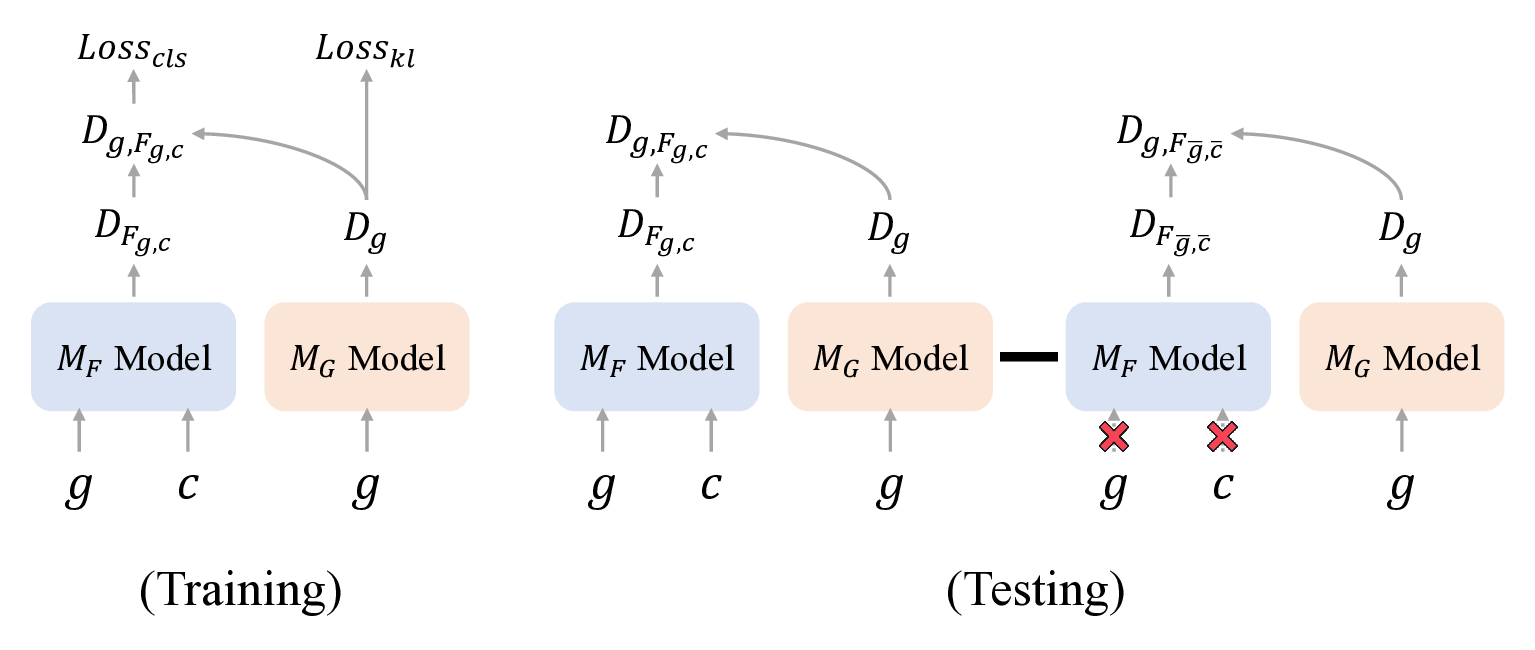
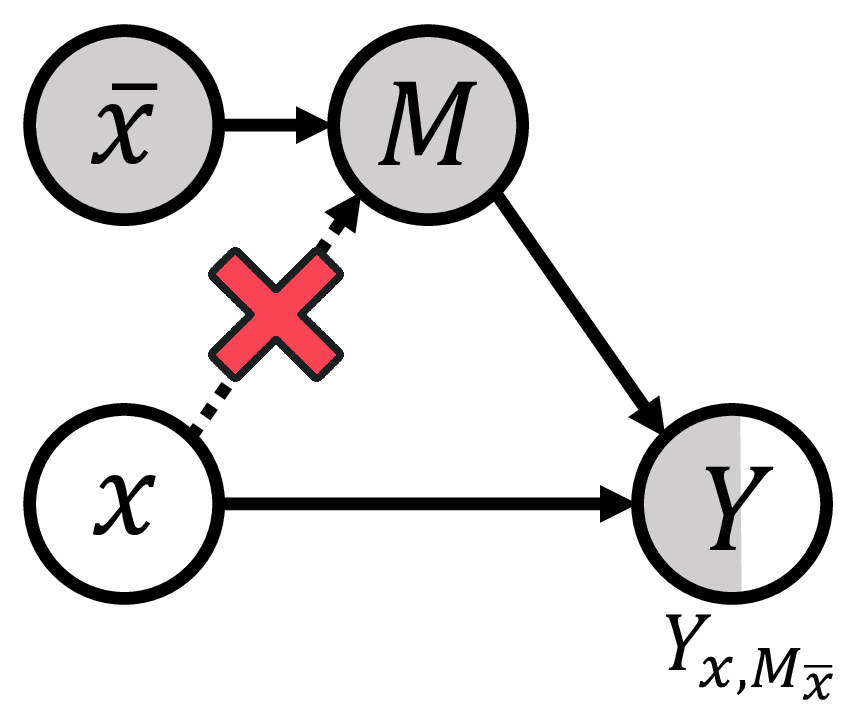
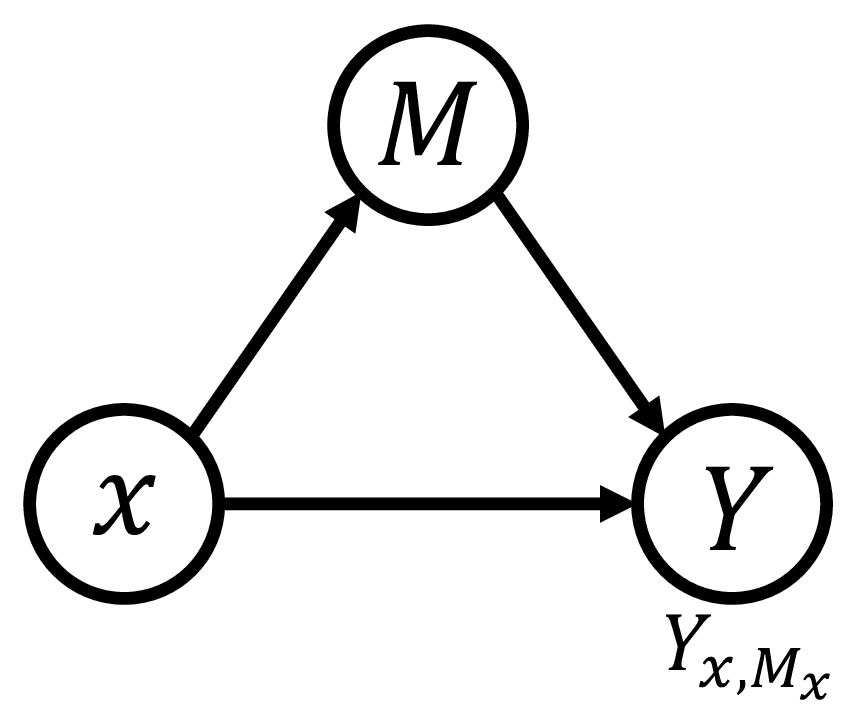
Inspired by causal inference theory [12] and counterfactual inference theory [13], and drawing on their successful application in eliminating language bias in the Visual Question Answering (VQA) domain [14], we propose a novel Counterfactual Debiasing Framework. We formally define gender bias as the direct causal effect of gender information on depression status. During model training, we introduce counterfactual interventions aimed at quantifying this bias effect and removing it from the model’s overall judgment during final inference. This results in a more equitable diagnosis that relies more heavily on authentic acoustic pathological features. Overall, the main contributions of this paper are as follows:
- Analyze and quantify the gender bias present in automatic depression detection. 2) Propose a novel end-to-end counterfactual debiasing framework that cuts off the spurious causal link between gender and depression. 3) Conduct experiments on two advanced acoustic baseline models, with results demonstrating that the proposed framework not only enhances overall performance, but also improves model fairness.
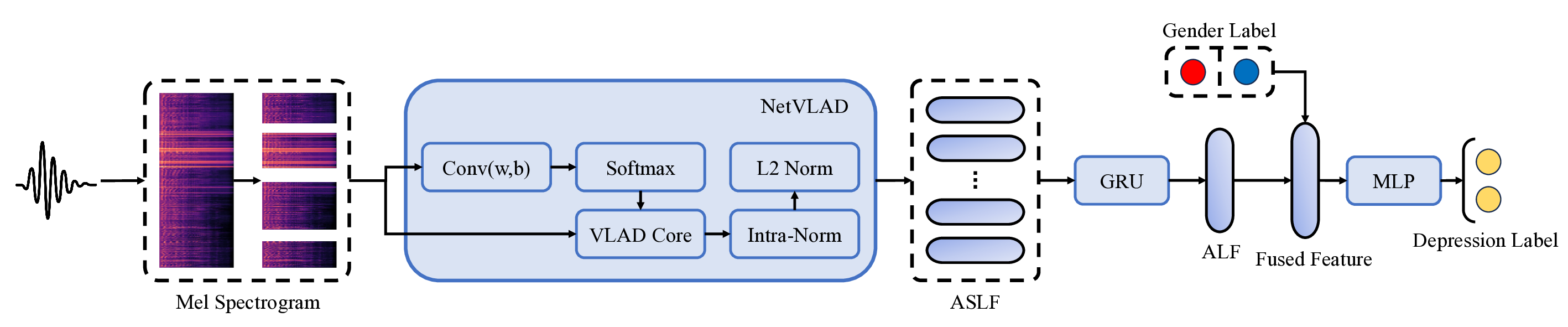
Early audio-based depression detection primarily relied on handcrafted acoustic features and traditional machine learning classifiers [15], such as landmark words with Support Vector Machine (SVM) [16], and eGeMAPS features with logistic regression [17]. With the rise of deep learning, AI chatbots have been employed to collect audio signals [18], and end-toend deep speech features often outperform traditional acoustic features [19]. Niu et al. [20] proposed the Spatio-Temporal Attention (STA) network, which captures both spatial and temporal features of speech signals, and highlights key frames through an attention mechanism. To address the issue of variable-length speech segments in clinical interviews, Shen et al. [21] introduced a framework based on the NetVLAD aggregation module, which encodes acoustic feature sequences of arbitrary length into fixed-dimensional vector representations. Building on the works of [20] and [21], we construct two advanced acoustic backbone models to comprehensively evaluate the proposed debiasing framework.
Existing debiasing methods for depression detection fall into three types: pre-processing, in-processing, and post-processing [22]. Pre-processing
This content is AI-processed based on open access ArXiv data.