Agentic Policy Optimization via Instruction-Policy Co-Evolution
Reading time: 5 minute
...
📝 Original Info
Title: Agentic Policy Optimization via Instruction-Policy Co-Evolution
ArXiv ID: 2512.01945
Date: 2025-12-01
Authors: Han Zhou, Xingchen Wan, Ivan Vulić, Anna Korhonen
📝 Abstract
Reinforcement Learning with Verifiable Rewards (RLVR) has advanced the reasoning capability of large language models (LLMs), enabling autonomous agents that can conduct effective multi-turn and tool-integrated reasoning. While instructions serve as the primary protocol for defining agents, RLVR typically relies on static and manually designed instructions. However, those instructions may be suboptimal for the base model, and the optimal instruction may change as the agent's policy improves and explores the interaction with the environment. To bridge the gap, we introduce INSPO, a novel Instruction-Policy co-evolution framework that integrates instruction optimization as a dynamic component of the reinforcement learning (RL) loop. INSPO maintains a dynamic population of instruction candidates that are sampled with questions, where reward signals in RL loops are automatically attributed to each instruction, and low performers are periodically pruned. New instructions are generated and verified through an on-policy reflection mechanism, where an LLM-based optimizer analyzes past experience from a replay buffer and evolves more effective strategies given the current policy. We conduct extensive experiments on multi-turn retrieval and reasoning tasks, demonstrating that INSPO substantially outperforms strong baselines relying on static instructions. INSPO discovers innovative instructions that guide the agent toward more strategic reasoning paths, achieving substantial performance gains with only a marginal increase in computational overhead.
💡 Deep Analysis
📄 Full Content
Agentic Policy Optimization via Instruction-Policy Co-Evolution
Han Zhou 1 Xingchen Wan 2 * Ivan Vuli´c 1 Anna Korhonen 1
Abstract
Reinforcement Learning with Verifiable Rewards
(RLVR) has advanced the reasoning capability
of large language models (LLMs), enabling au-
tonomous agents that can conduct effective multi-
turn and tool-integrated reasoning. While instruc-
tions serve as the primary protocol for defining
agents, RLVR typically relies on static and man-
ually designed instructions. However, those in-
structions may be suboptimal for the base model,
and the optimal instruction may change as the
agent’s policy improves and explores the interac-
tion with the environment. To bridge the gap, we
introduce INSPO, a novel Instruction-policy Co-
Evolution framework that integrates instruction
optimization as a dynamic component of the rein-
forcement learning (RL) loop. INSPO maintains
a dynamic population of instruction candidates
that are sampled with questions, where reward
signals in RL loops are automatically attributed
to each instruction, and low performers are peri-
odically pruned. New instructions are generated
and verified through an on-policy reflection mech-
anism, where an LLM-based optimizer analyzes
past experience from a replay buffer and evolves
more effective strategies given the current policy.
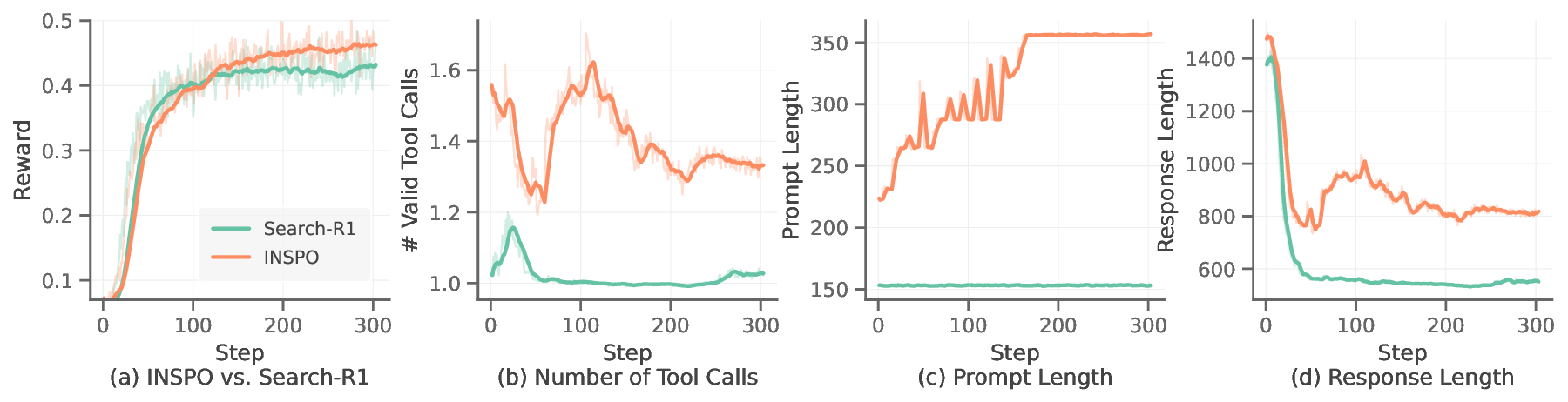
We conduct extensive experiments on multi-turn
retrieval and reasoning tasks, demonstrating that
INSPO substantially outperforms strong baselines
relying on static instructions. INSPO discovers in-
novative instructions that guide the agent toward
more strategic reasoning paths, achieving substan-
tial performance gains with only a marginal in-
crease in computational overhead.
1. Introduction
The advent of large language models (LLMs) (Brown et al.,
2020; Chung et al., 2024) has given rise to autonomous
1Language Technology Lab, University of Cambridge.
2Machine Learning Research Group, University of Oxford. ∗Now
at Google. Correspondence to: Han Zhou .
Preprint. February 3, 2026.
agents that are capable of reasoning, interpreting user in-
tents, and tackling complex tasks via interacting with the
environment (Yao et al., 2023). When paired with care-
fully engineered instructions, LLM-based agents have ex-
celled in a wide range of applications, such as code genera-
tion (Jimenez et al., 2023), retrieval-augmented generation
(Trivedi et al., 2023), and interactive decision-making (Su
et al., 2025). Recently, the reinforcement learning (RL)
(Sutton et al., 1999) paradigm has further advanced the rea-
soning capabilities of LLM agents, enabling them to learn
policies from verifiable rewards (Shao et al., 2024) (RLVR)
and achieve multi-turn and tool-integrated reasoning (Jin
et al., 2025; Xue et al., 2025).
In the core of these agentic capabilities, instructions serve
as the protocol for programming these agents, characteriz-
ing their roles, and defining any available tools/interfaces
for interaction. The performance of LLM-based agents has
been shown to be highly dependent on the instruction (Zhou
et al., 2025), and subtle changes can exert substantial dif-
ferences in generated trajectories, preventing robust and
generalizable agent applications. The compounding effect
of instructions is further amplified when LLMs are post-
trained via RL, where changes in instructions can result in
different initial spaces for policy learning, thereby largely af-
fecting the converged performance after training (Liu et al.,
2025a). Consequently, instruction design becomes crucial
for agent training and typically requires costly human efforts
for iterative refinements via trial-and-error.
The traditional paradigm of RLVR treats instruction as a
static and pre-defined input. However, the optimal instruc-
tion for the base model is not always known a priori and may
even change as the model’s policy improves and explores
the interaction with the environment (Soylu et al., 2024).
Recent findings also underscore the importance of instruc-
tion for RL, where injecting reward specification (Zhang
et al., 2025) or in-context hints (Liu et al., 2025b) into the
instruction better aligns the model with the learning objec-
tive and generates richer reward signals. While automated
prompt optimization (APO) (Zhou et al., 2023; Yang et al.,
2024) approaches exist for obtaining a better instruction
before commencing the RL phase, generalizing them to the
online setting of RL and incorporating adaptive knowledge
during policy updates is rather non-trivial.
1
arXiv:2512.01945v2 [cs.LG] 31 Jan 2026
Agentic Policy Optimization via Instruction-Policy Co-Evolution
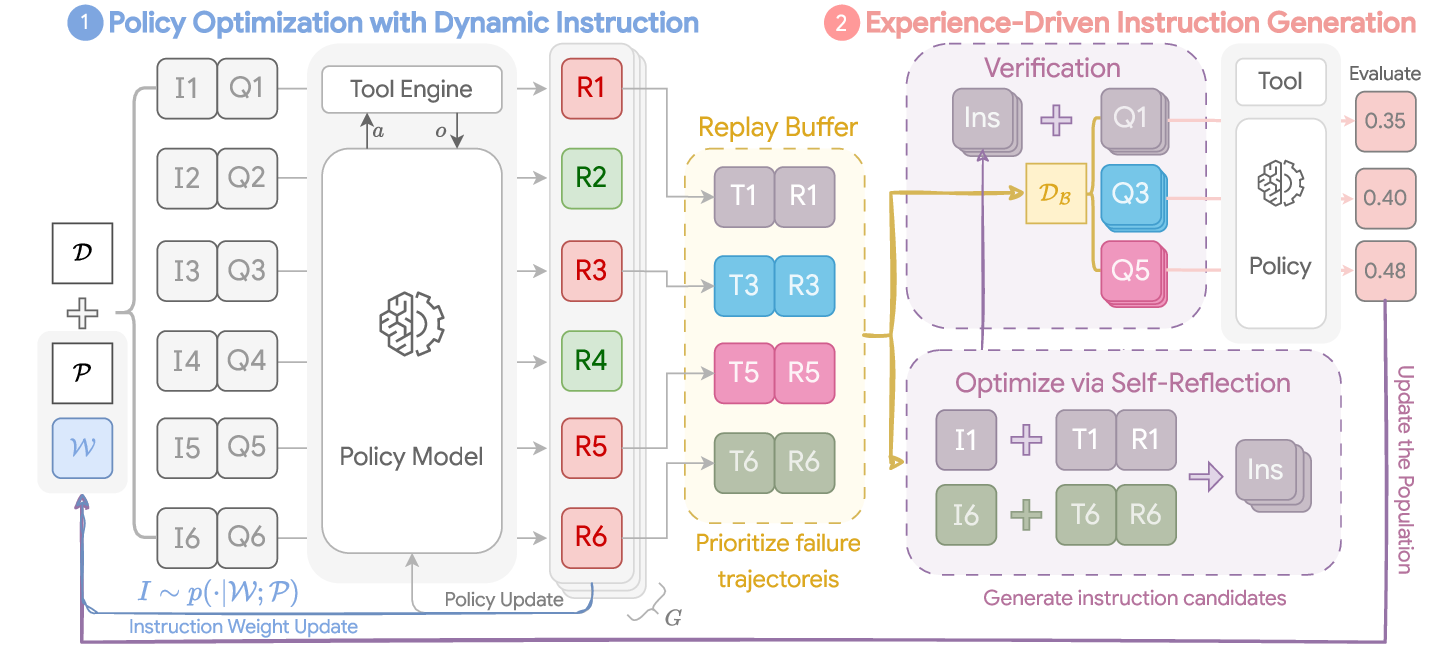
To bridge this gap, we propose to automate instruction learn-
ing not as a static term, but as an integral and dynamic
component of the RL learning loop, allowing the instruction
and policy to co-evolve in an online setup. We introduce
INSPO, INStruction-POlicy co-evolution, for agentic policy
optimization, a novel framework that delivers two major
inn