As web platforms evolve towards greater personalization and emotional complexity, conversational agents must transcend superficial empathy to demonstrate identity-aware emotional reasoning. However, existing systems face two limitations: (1) reliance on situation-centric datasets lacking persistent user identity, which hampers the capture of personalized affective nuances; and (2) dependence on opaque, coarse reward signals that hinder development of verifiable empathetic reasoning. To address these gaps, we introduce KardiaBench, a large-scale user-grounded benchmark comprising 178,080 QA pairs across 22,080 multi-turn conversations anchored to 671 real-world profiles. The dataset is constructed via a model-in-the-loop pipeline with iterative rubric-guided refinement to ensure psychological plausibility and persona consistency. This progressive empathy pipeline that integrates user comprehension, contextual reasoning, and emotion perception into conversations, followed by iterative critique and rubric-based refinement to ensure psychological plausibility, emotional fidelity, and persona consistency. Building on this, we propose Kardia-R1, a framework that trains models for interpretable, stepwise empathetic cognition. Kardia-R1 leverages Rubric-as-Judge Empathetic Reinforcement Learning (Rubric-ERL), a GRPO-based method that uses explainable, human-aligned rubric rewards to tightly couple user understanding, emotional inference, and supportive response generation. Extensive experiments across four LLM backbones demonstrate that Kardia-R1 consistently outperforms othet methods in emotion accuracy, empathy, relevance, persona consistency, and safety. Our dataset and model will be released at https://github.com/JhCircle/Kardia-R1.
As web-based conversational AI Zhang et al. (2020); Yang et al. (2024a) becomes increasingly integrated into daily life, online platforms have evolved into "emotional commons" where individuals share vulnerabilities and complex affective states Miller & Wallis (2011). Supporting such interactions requires models that provide user-grounded emotional support shaped by personal background and situational needs. This depends on systems able to perceive emotion, reason about context, and account for individual differences. Empathy, central to theories of trust and perspective taking Batson et al. (1991), is therefore essential for meaningful human-AI interaction. Although recent work adapts to emotional cues Gao et al. (2021;2023) or models affective states Majumder et al. (2020); Bi et al. (2023); Yuan et al. (2025), current systems still struggle to incorporate users' identities and nuanced emotional histories.
Existing empathetic dialogue models can be broadly categorized into two categories: small-scale models that integrate explicit empathy mechanisms, and LLM-based models that leverage reasoning capabilities Dubey et al. (2024); Team et al. (2024b). Small-scale models enhance contextual understanding through emotion-conditioned decoding Lin et al. (2019); Majumder et al. (2020), multi-resolution knowledge Li et al. (2020;2022), or multi-grained signals including emotional cause Bi et al. (2023); Hamad et al. (2024) and emotion-intent reflection Yuan et al. (2025), enabling emotionally responsive replies. However, their reliance on heuristic signals and limited external knowledge often yields fluent but shallow responses that misalign with nuanced user affect. In contrast, LLM-based models exploit instruction tuning Chen et al. (2023) and chain-of-thought reasoning Chen et al. (2023); Hu et al. (2024); Cai et al. (2024) to simulate higher-order empathetic cognition via multi-step inference.
Building on datasets like EmpatheticDialogues Rashkin et al. (2019), recent work further leverages LLMs to synthesize auxiliary supervision, such as emotional causes He et al. (2025), user intent Xie & Pu (2021);
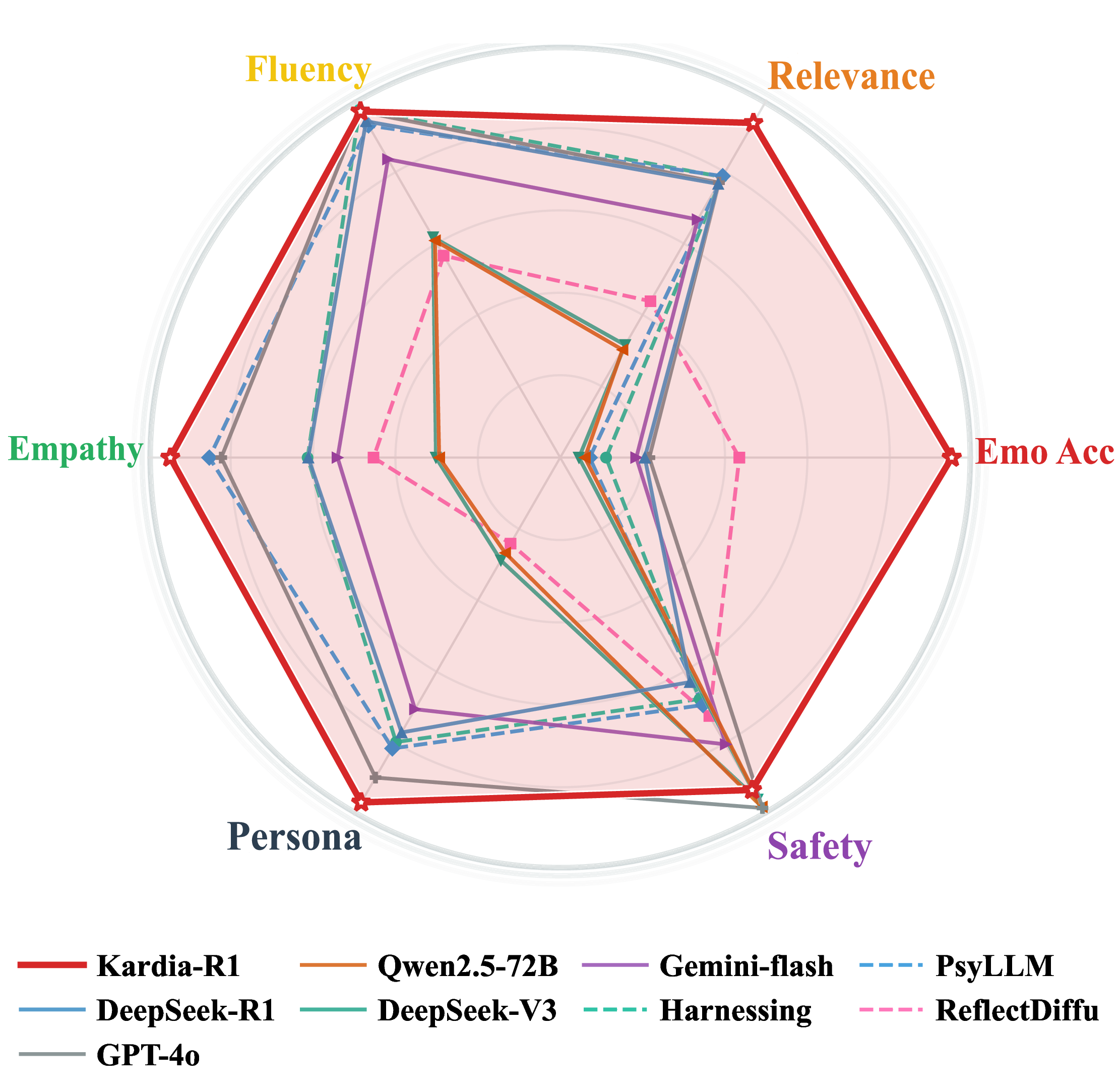
.DUGLD5 ‘HHS6HHN5 *37R 4ZHQ% ‘HHS6HHN9 *HPLQLIODVK +DUQHVVLQJ 3V//0 5HIOHFW’LIIX Figure 1: Kardia-R1 versus strong general-purpose LLMs and specialized empathetic systems across six core dimensions of empathetic dialogue (emotion recognition accuracy, relevance, fluency, safety, persona consistency, and empathy). Yuan et al. (2025) and personality traits Wu et al. (2025) for finetuning Bi et al. (2023); Chen et al. (2025) or reinforcement learning Li et al. (2024); Dai et al. (2025). However, these methods or benchmarks remain detached from users’ concrete backgrounds and emotional states, overlooking perspective-taking principles Batson et al. (1991) that stress grounding empathy in an individual’s specific context and experiences. In summary, current LLM-based empathetic dialogue models face two major challenges: (1) lack of user-grounded training data, as most benchmarks, including EmpatheticDialogues, represent general emotional situations rather than user-oriented interactions, limiting models’ ability to generate responses aligned with individual user’s nuanced emotional states; (2) challenges in training with verifiable reward signals, since supervised fine-tuning and reinforcement learning with reward models are difficult to validate in empathetic dialogue, as existing evaluation metrics cannot reliably assess whether responses genuinely reflect users’ affective states and contextual subtleties.
To address these limitations, we first construct KardiaBench, a user-grounded multi-turn empathetic dialogue benchmark derived from 671 real online profiles and EmpatheticDialogues Rashkin et al. (2019). In our pipeline, one LLM simulates a user generating queries based on a specific profile and situation, while another acts as an empathetic expert performing perspective-taking. Crucially, each turn is iteratively refined via user critique and model-in-the-loop updates under rubric evaluation, and finally verified through manual checks. Building on this benchmark, we develop Kardia-R1. This model is trained via supervised fine-tuning (SFT) for cold-start alignment, followed by GRPO-based reinforcement learning Guo et al. (2025) guided by Rubric-as-Judge Empathetic RL (Rubric-ERL). This framework enables the model to actively learn user comprehension and empathetic generation, using turn-level critique to optimize its policy for coherence and alignment with user background, personality, and emotional state.
Our main contributions are summarized as follows:
• We propose KardiaBench, a user-grounded multi-turn empathetic dialogue benchmark that augments EmpatheticDialogues with 671 real online user profiles, leveraging a fine-grained LLM data synthesis pipeline to generate high-quality multi-turn empathetic dialogues.
• We develop Kardia-R1, a progressive framework that models empathy as a perspective-taking
This content is AI-processed based on open access ArXiv data.