Generative modeling has recently shown remarkable promise for visuomotor policy learning, enabling flexible and expressive control across diverse embodied AI tasks. However, existing generative policies often struggle with data inefficiency, requiring large-scale demonstrations, and sampling inefficiency, incurring slow action generation during inference. We introduce EfficientFlow, a unified framework for efficient embodied AI with flow-based policy learning. To enhance data efficiency, we bring equivariance into flow matching. We theoretically prove that when using an isotropic Gaussian prior and an equivariant velocity prediction network, the resulting action distribution remains equivariant, leading to improved generalization and substantially reduced data demands. To accelerate sampling, we propose a novel acceleration regularization strategy. As direct computation of acceleration is intractable for marginal flow trajectories, we derive a novel surrogate loss that enables stable and scalable training using only conditional trajectories. Across a wide range of robotic manipulation benchmarks, the proposed algorithm achieves competitive or superior performance under limited data while offering dramatically faster inference. These results highlight EfficientFlow as a powerful and efficient paradigm for high-performance embodied AI.
Learning robotic policies from data using generative models has emerged as a powerful and flexible paradigm in embodied AI, particularly with the recent success of diffusion-based approaches (Chi et al., 2023;Ze et al., 2024). These models have demonstrated strong performance in visuomotor control by learning complex action distributions conditioned on high-dimensional observations. However, two key limitations remain: low data efficiency, requiring large amounts of training data, and low sampling efficiency, incurring high computational cost at inference due to the iterative sampling process.
Recent works have sought to address the data efficiency issue by incorporating equivariance into diffusion models for policy learning (Wang et al., 2024). By leveraging the inherent symmetries of the environment (e.g., 2D rotation), these methods introduce strong inductive biases that enable policies to generalize across symmetric configurations. Nevertheless, as they are still built upon diffusion models, which typically require hundreds of iterative denoising steps to generate a single action (Sohl-Dickstein et al., 2015;Ho et al., 2020), they remain impractical for real-time robotic control. To overcome this limitation, we turn to Flow Matching (Lipman et al., 2023), a recent class of generative models that learns a continuous trajectory from a simple prior distribution to the data distribution using an ordinary differential equation (ODE) defined by a velocity field. Compared to diffusion models, flow-based approaches offer better numerical stability and faster inference, making them highly appealing for efficient embodied AI.
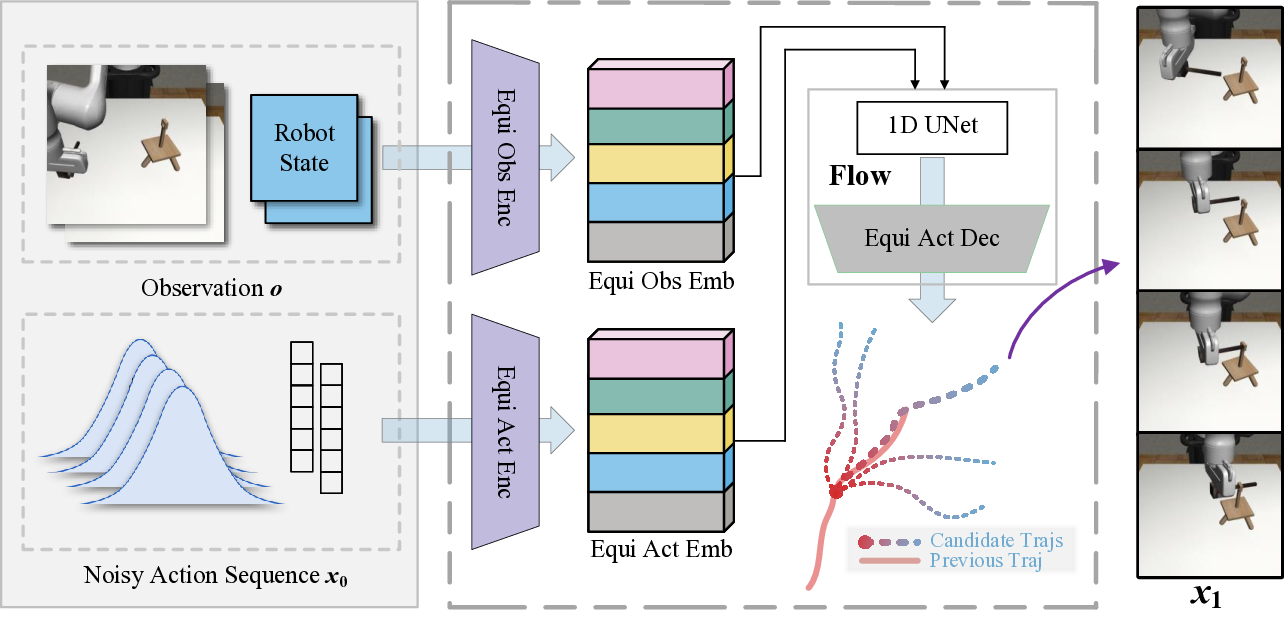
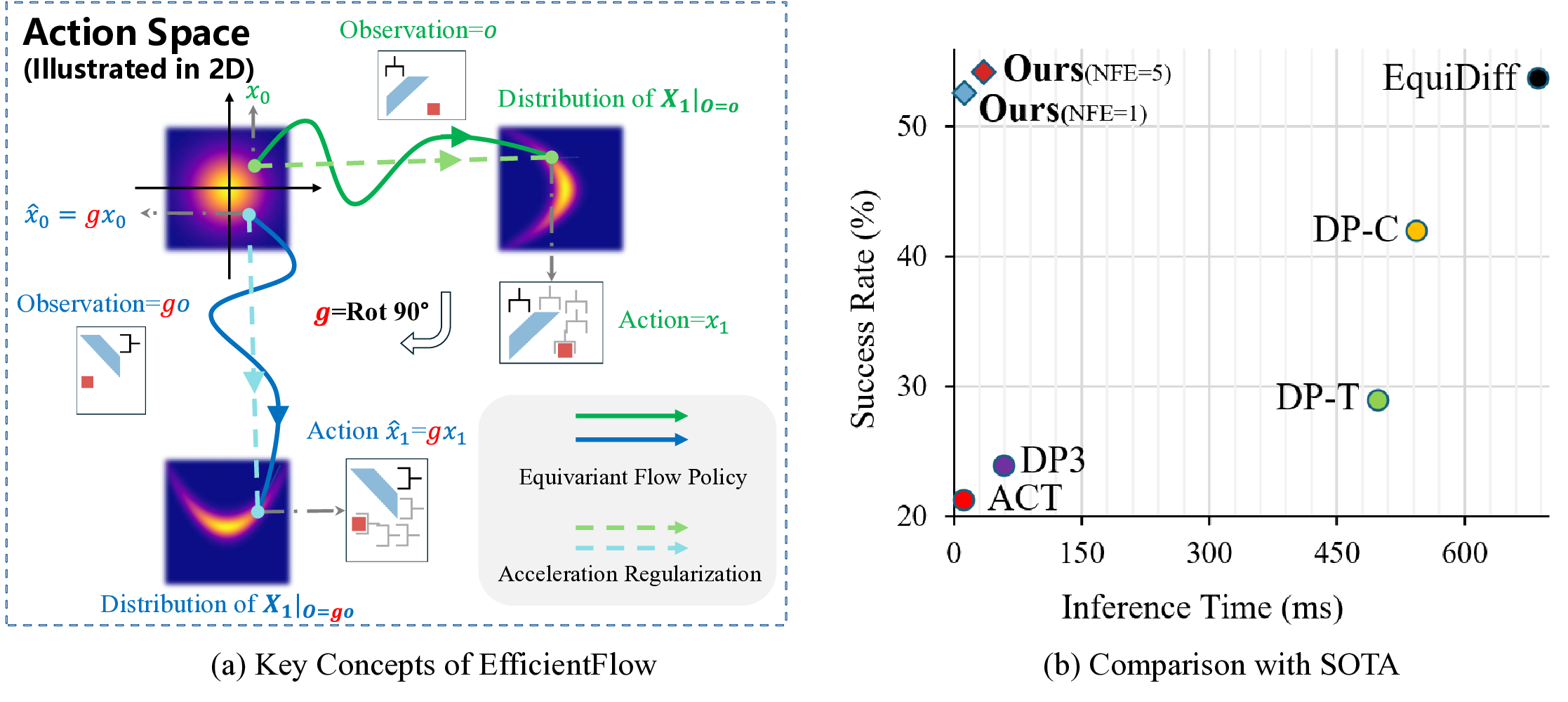
We present EfficientFlow, a new policy learning framework that unifies equivariant learning and flow-based generative modeling. We first investigate how to incorporate equivariance into flow-based policy models and theoretically show that, under an isotropic Gaussian prior and an equivariant velocity field network, the conditional action distribution induced by flow matching remains equivariant with respect to input observation transformations (see Figure 1(a)). This property allows policies to generalize across symmetric configurations of the environment without additional supervision or data augmentation.
To further improve the action sampling efficiency, we introduce a regularization technique that penalizes the acceleration of the generation flow trajectory, i.e., the second-order temporal derivative, which encourages a smoother and more stable action sampling process.
However, computing acceleration requires consecutive points along the marginal flow trajectories, which are unavailable in the standard flow matching framework. To address this challenge, we propose a novel surrogate objective called Flow Acceleration Upper Bound (FABO). FABO provides a practical and effective approximation of the acceleration penalty using only conditional flow trajectories available during training, enabling much faster flow policies with lower computational costs.
The proposed EfficientFlow combines the best of both worlds: it achieves fast inference speed thanks to the flow-based architecture and smoothed sampling trajectory, and maintains high performance by leveraging equivariance. As illustrated in Figure 1(b), EfficientFlow compares favorably against existing methods in both inference speed and task success rates.
Our primary contributions are as follows:
• We formulate a flow-based policy learning framework, EfficientFlow, that achieves equivariance to geometric transformations, allowing the model to generalize across symmetric states and significantly improve data efficiency. We provide a theoretical analysis showing that equivariance is preserved in the flow framework when using an isotropic prior and an equivariant velocity field conditioned on visual observations.
• To promote sampling speed, we propose a second-order regularization objective that penalizes flow acceleration. Since direct acceleration computation requires access to neighboring marginal samples that are unavailable, we introduce a novel surrogate loss called FABO, enabling effective training.
• We provide comprehensive evaluations of EfficientFlow on 12 robotic manipulation tasks in the MimicGen (Mandlekar et al., 2023) benchmark, showing that EfficientFlow achieves favorable success rates with high inference speeds (19.9 to 56.1 times faster than EquiDiff (Wang et al., 2024)).
2 Related Work
Applying equivariance to robot manipulation is a highly promising research direction, and multiple studies have demonstrated that it can significantly enhance the data efficiency of robot policy learning (Wang et al., 2022b;Jia et al., 2023;Wang et al., 2022c;Simeonov et al., 2023;Pan et al., 2023;Huang et al., 2023;Liu et al., 2023a;Kim et al., 2023;Nguyen et al., 2023;Yang et al., 2024a). Early work used SE(3) open-loop or SE(2) closed-loop for control, validated the effectiveness of equivariant models in on-robot learning (Zh
This content is AI-processed based on open access ArXiv data.