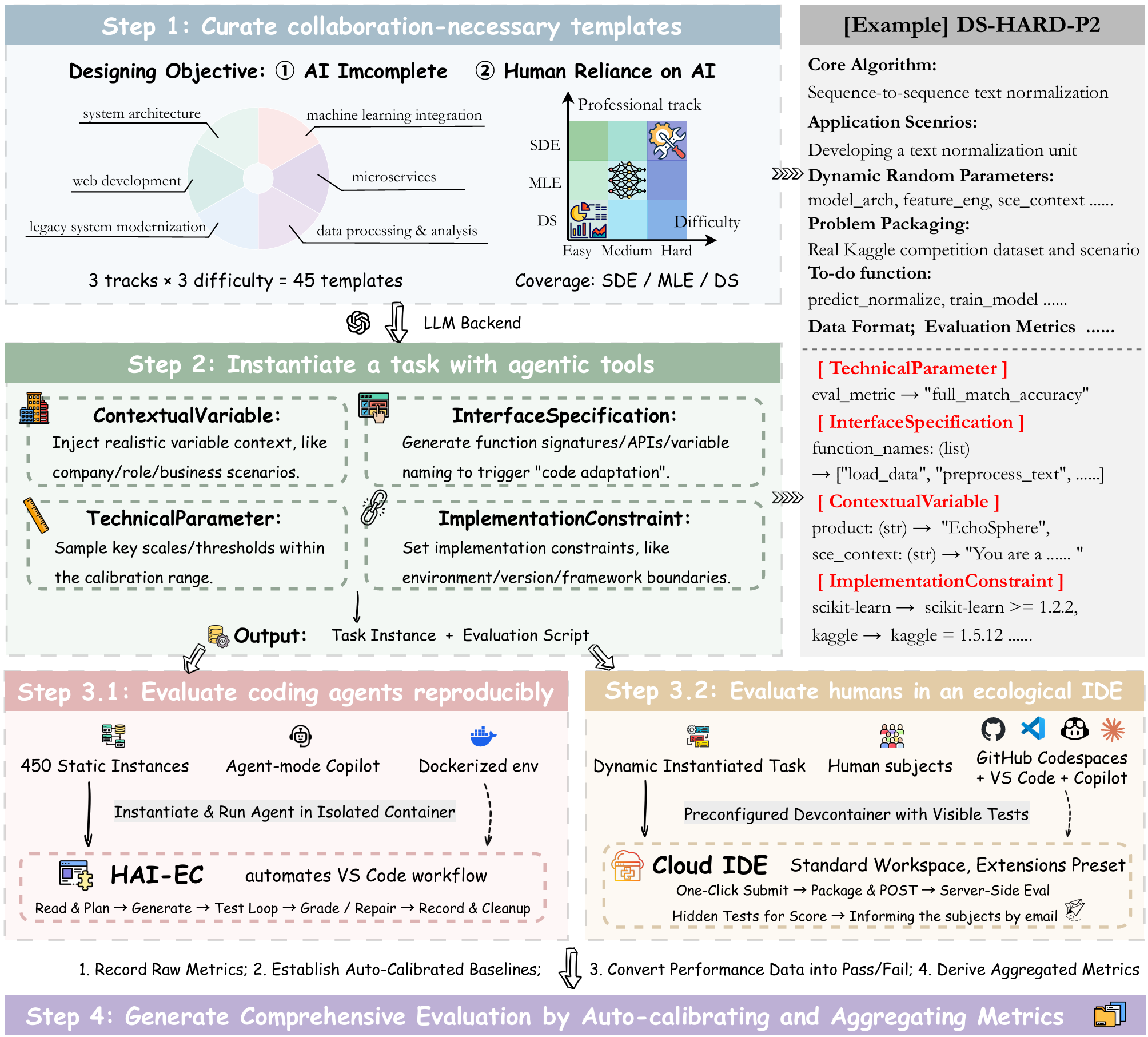
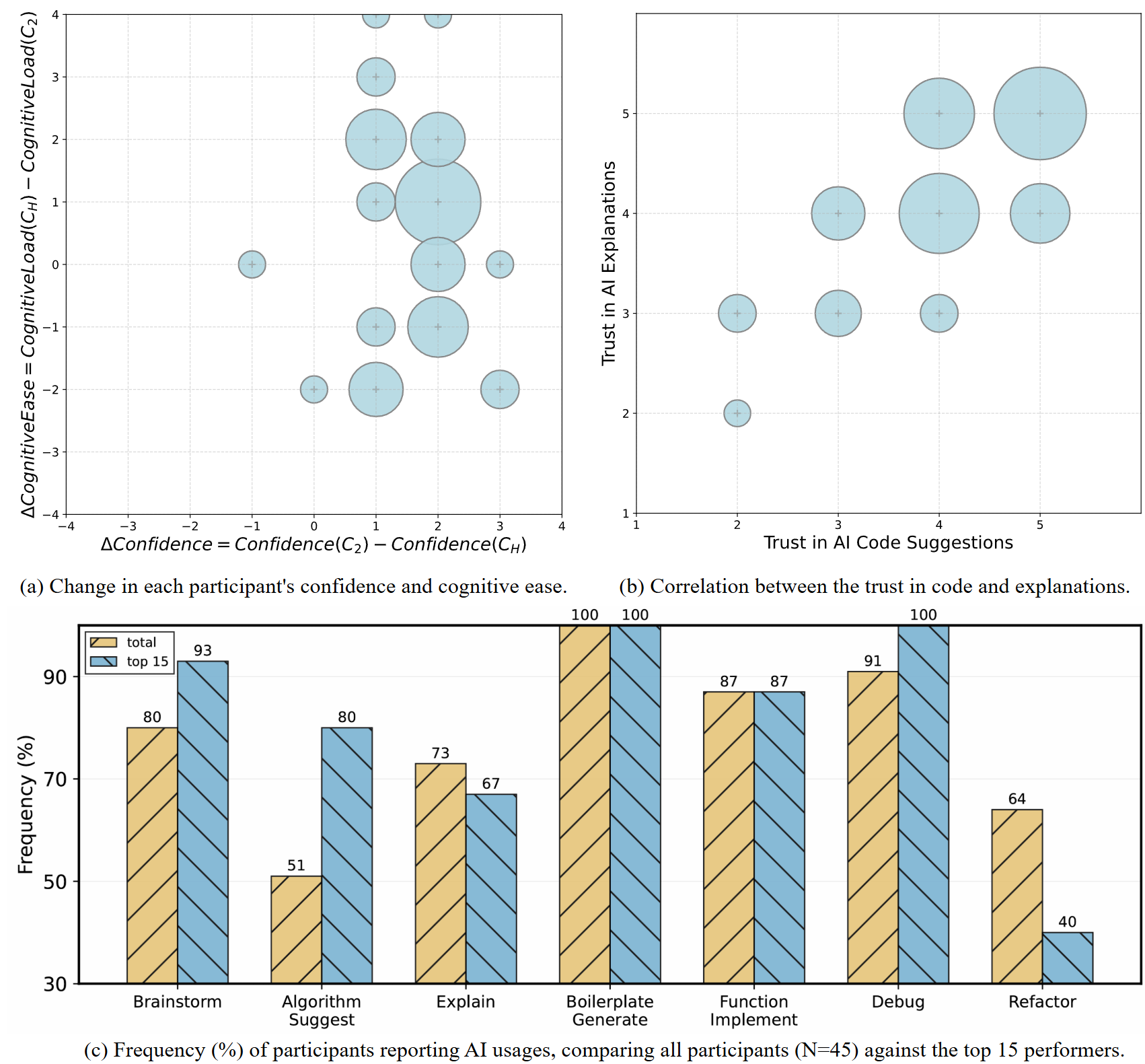
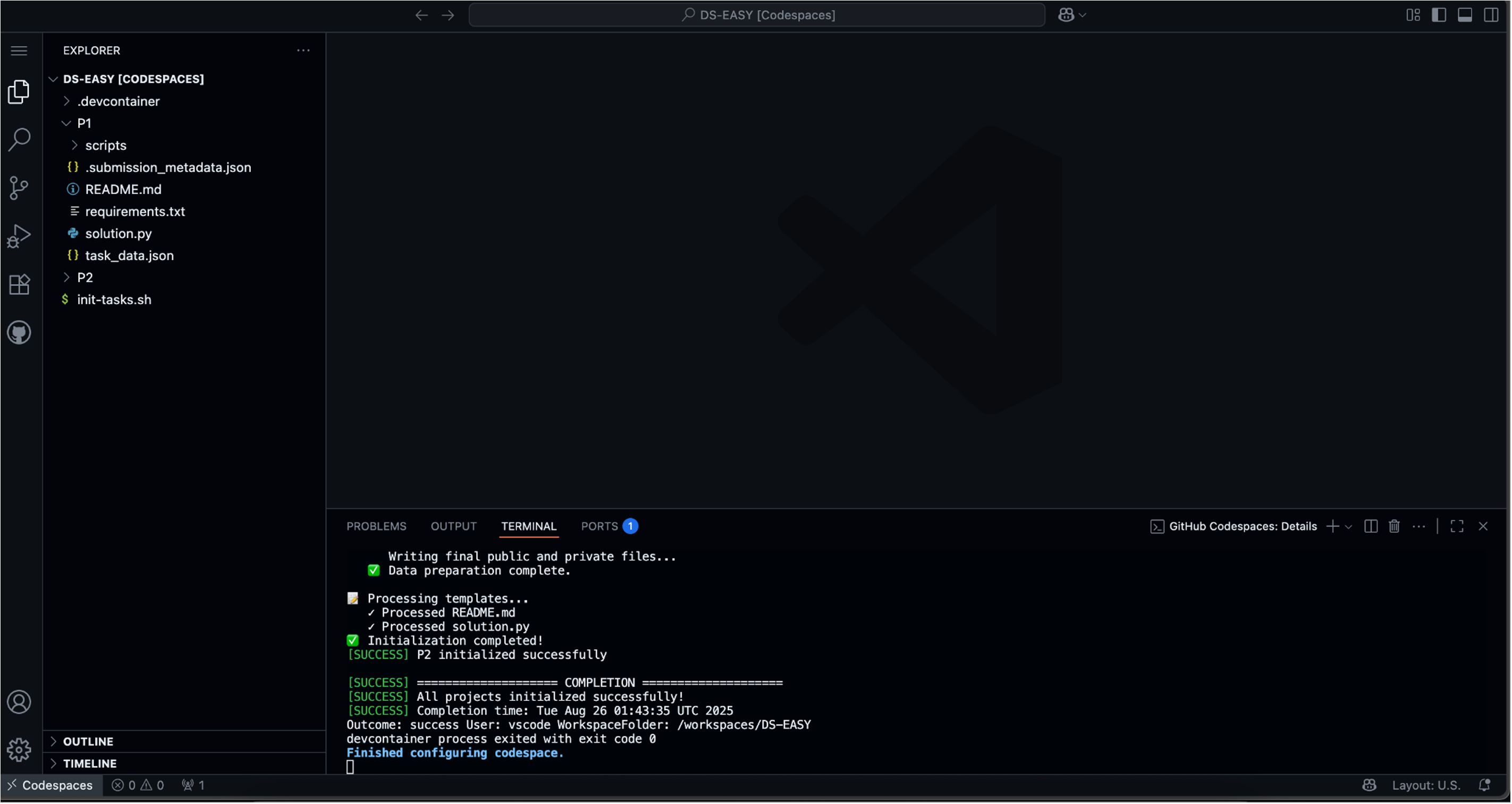
LLM-powered coding agents are reshaping the development paradigm. However, existing evaluation systems, neither traditional tests for humans nor benchmarks for LLMs, fail to capture this shift. They remain focused on well-defined algorithmic problems, which excludes problems where success depends on human-AI collaboration. Such collaborative problems not only require human reasoning to interpret complex contexts and guide solution strategies, but also demand AI efficiency for implementation. To bridge this gap, we introduce HAI-Eval, a unified benchmark designed to measure the synergy of human-AI partnership in coding. HAI-Eval's core innovation is its "Collaboration-Necessary" problem templates, which are intractable for both standalone LLMs and unaided humans, but solvable through effective collaboration. Specifically, HAI-Eval uses 45 templates to dynamically create tasks. It also provides a standardized IDE for human participants and a reproducible toolkit with 450 task instances for LLMs, ensuring an ecologically valid evaluation. We conduct a within-subject study with 45 participants and benchmark their performance against 5 state-of-the-art LLMs under 4 different levels of human intervention. Results show that standalone LLMs and unaided participants achieve poor pass rates (0.67% and 18.89%), human-AI collaboration significantly improves performance to 31.11%. Our analysis reveals an emerging co-reasoning partnership. This finding challenges the traditional human-tool hierarchy by showing that strategic breakthroughs can originate from either humans or AI. HAI-Eval establishes not only a challenging benchmark for next-generation coding agents but also a grounded, scalable framework for assessing core developer competencies in the AI era. Our benchmark and interactive demo will be openly accessible.
💡 Deep Analysis
📄 Full Content
Preprint. Work in progress.
HAI-EVAL: MEASURING HUMAN-AI SYNERGY
IN COLLABORATIVE CODING
Hanjun Luo1∗, Chiming Ni3∗, Jiaheng Wen4∗, Zhimu Huang1,
Yiran Wang6, Bingduo Liao7, Sylvia Chung5, Yingbin Jin8,
Xinfeng Li2†, Wenyuan Xu5, XiaoFeng Wang2, Hanan Salam1
1New York University Abu Dhabi, 2Nanyang Technological University
3University of Illinois Urbana-Champaign, 4Harvard University
5Zhejiang University, 6University of Electronic Science and Technology of China
7Beijing University of Technology, 8The Hong Kong Polytechnic University
ABSTRACT
LLM-powered coding agents are reshaping the development paradigm. However,
existing evaluation systems, neither traditional tests for humans nor benchmarks
for LLMs, fail to capture this shift. They remain focused on well-defined algo-
rithmic problems, which excludes problems where success depends on human-AI
collaboration. Such collaborative problems not only require human reasoning to
interpret complex contexts and guide solution strategies, but also demand AI effi-
ciency for implementation. To bridge this gap, we introduce HAI-Eval, a unified
benchmark designed to measure the synergy of human-AI partnership in coding.
HAI-Eval’s core innovation is its “Collaboration-Necessary” problem templates,
which are intractable for both standalone LLMs and unaided humans, but solv-
able through effective collaboration. Specifically, HAI-Eval uses 45 templates to
dynamically create tasks. It also provides a standardized IDE for human partic-
ipants and a reproducible toolkit with 450 task instances for LLMs, ensuring an
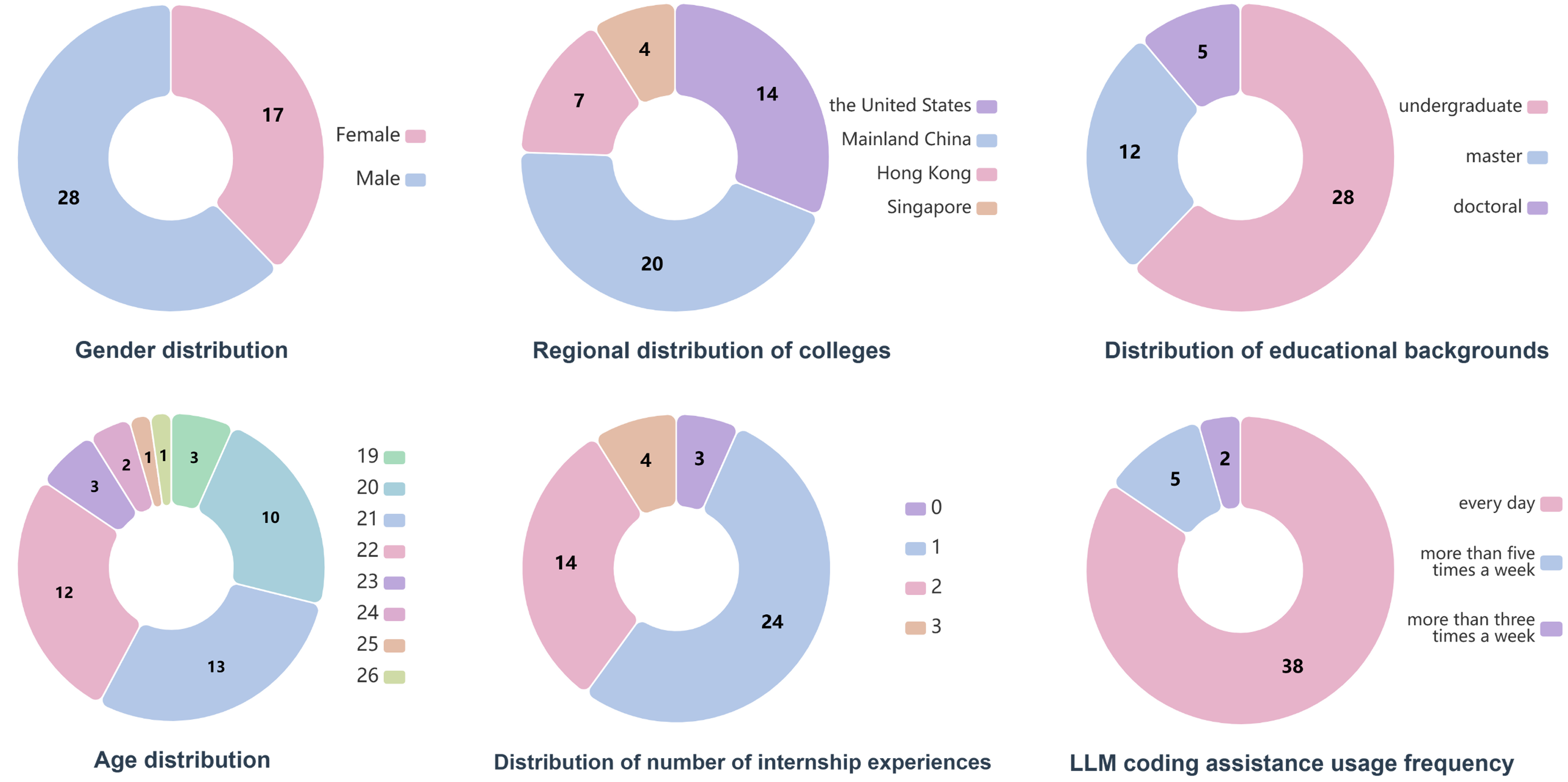
ecologically valid evaluation. We conduct a within-subject study with 45 partic-
ipants and benchmark their performance against 5 state-of-the-art LLMs under 4
different levels of human intervention. Results show that standalone LLMs and
unaided participants achieve poor pass rates (0.67% and 18.89%), human–AI col-
laboration significantly improves performance to 31.11%. Our analysis reveals an
emerging co-reasoning partnership. This finding challenges the traditional human-
tool hierarchy by showing that strategic breakthroughs can originate from either
humans or AI. HAI-Eval establishes not only a challenging benchmark for next-
generation coding agents but also a grounded, scalable framework for assessing
core developer competencies in the AI era. Our benchmark and interactive demo
will be openly accessible.
1
INTRODUCTION
Coding agents powered by Large Language Models (LLMs) are fundamentally reshaping the soft-
ware development paradigm (Soni et al., 2023; Coutinho et al., 2024; Martinovi´c & Rozi´c, 2025).
Tools such as Claude Code (Anthropic, 2024), Cursor (Anysphere, 2024), and GitHub Copi-
lot (GitHub, 2024) are now widely used in practice (Perumal, 2025). As a result, the role of a
developer is shifting from that of a code producer to a leader within a human-AI collaborative sys-
tem. Developers are now responsible for strategic planning, directing AI contributions, and ensuring
final code quality (Alenezi & Akour, 2025; Eshraghian et al., 2025). Simultaneously, coding agents
are evolving to automate increasingly higher-level tasks. This trend continuously extends the frontier
of human-AI collaboration (Hou et al., 2024; Nghiem et al., 2024; Pezz`e et al., 2025).
Nonetheless, this revolution in development practice exposes a fundamental gap in evaluation. Most
current assessments, for both humans and AI, share a common flaw: they assume the existence
∗Equal contribution (hl6266@nyu.edu).
†Corresponding author (lxfmakeit@gmail.com).
1
arXiv:2512.04111v1 [cs.SE] 30 Nov 2025
Preprint. Work in progress.
of a perfectly defined problem. Human-focused platforms like LeetCode (LeetCode, 2015) and
Codeforces (Codeforces, 2010), emphasize well-structured algorithmic problems, which incentivize
developers to master skills that are increasingly automated (opentools, 2025; April Bohnert, 2023).
Similarly, recent AI benchmarks that aim for realism (Jimenez et al., 2024; Yu et al., 2024; Li
et al., 2024b) often focus on environmental details (e.g., using real-world repositories), but they
still frame tasks as cleanly defined problems. These benchmarks overlook the complex stage of
problem formulation and thus fail to evaluate higher-order reasoning skills. Such skills, including
problem formulation, requirement engineering, and strategic decomposition, are essential for navi-
gating ambiguity before a problem is fully defined (Hemmat et al., 2025; Mozannar et al., 2024a).
Some advanced evaluation methods, such as LLM-as-a-Judge (Zheng et al., 2023; Li et al., 2024a)
and Agent-as-a-Judge (Zhuge et al., 2024), are emerging to evaluate performance on higher-order
definitions. However, this progress in evaluators has not been matched by an evolution in datasets;
these powerful methods are still applied to benchmarks with only perfectly defined problems (Wang
et al., 2025; Crupi et al., 2025), limiting the comprehensive evaluation of above crucial skills.
This situati