Logical specifications have been shown to help reinforcement learning algorithms in achieving complex tasks. However, when a task is under-specified, agents might fail to learn useful policies. In this work, we explore the possibility of improving coarse-grained logical specifications via an exploration-guided strategy. We propose \textsc{AutoSpec}, a framework that searches for a logical specification refinement whose satisfaction implies satisfaction of the original specification, but which provides additional guidance therefore making it easier for reinforcement learning algorithms to learn useful policies. \textsc{AutoSpec} is applicable to reinforcement learning tasks specified via the SpectRL specification logic. We exploit the compositional nature of specifications written in SpectRL, and design four refinement procedures that modify the abstract graph of the specification by either refining its existing edge specifications or by introducing new edge specifications. We prove that all four procedures maintain specification soundness, i.e. any trajectory satisfying the refined specification also satisfies the original. We then show how \textsc{AutoSpec} can be integrated with existing reinforcement learning algorithms for learning policies from logical specifications. Our experiments demonstrate that \textsc{AutoSpec} yields promising improvements in terms of the complexity of control tasks that can be solved, when refined logical specifications produced by \textsc{AutoSpec} are utilized.
Reinforcement Learning (RL) algorithms have made tremendous strides in recent years Sutton & Barto (2018); Silver et al. (2016); Mnih et al. (2015); Levine et al. (2016). However, most algorithms assume access to a scalar reward function that must be carefully engineered to make environments amenable to RL-a practice known as reward engineering Ibrahim et al. (2024). This creates challenges in applying RL to new environments where useful reward functions are hard to construct. Furthermore, scalar Markovian rewards cannot provide sufficient feedback for certain tasks Abel et al. (2021); Bowling et al. (2023), leading to growing interest in non-Markovian reward functions Li et al. (2017a); Jothimurugan et al. (2021); Alur et al. (2023).
To make non-Markovian rewards tractable, it is standard to represent them via logical specification formulas that capture the intended task. These approaches, known as specification-guided reinforcement learning Aksaray et al. (2016); Li et al. (2017b); Icarte et al. (2018); Jothimurugan et al. (2019;2021), derive reward functions from logical specifications. However, this creates two challenges: (i) providing specifications granular enough to guide RL algorithms, and (ii) defining accurate labeling functions mapping environment states to specification predicates. Users often create coarse specifications or labeling functions that, while logically correct, provide insufficient guidance for learning.
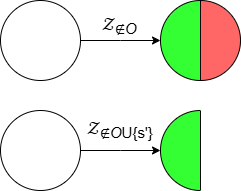
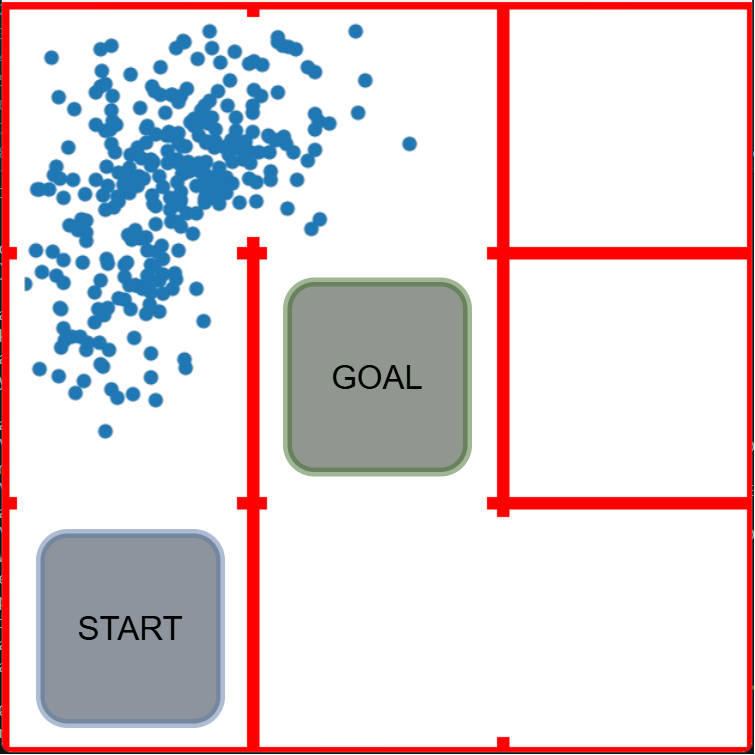
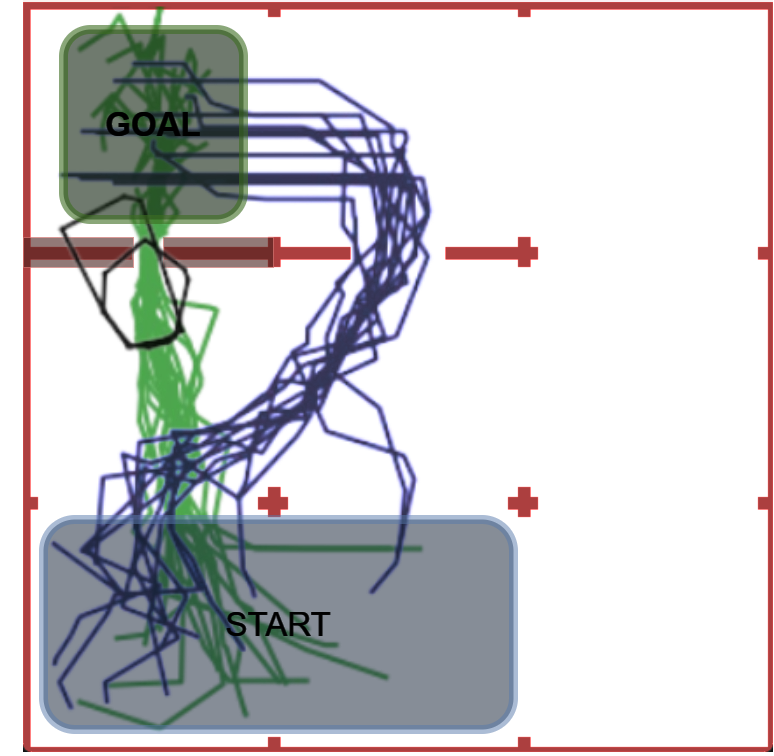
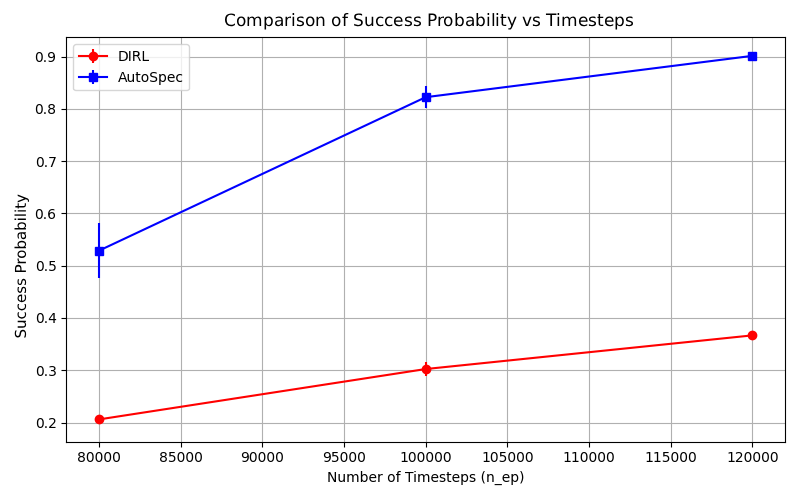
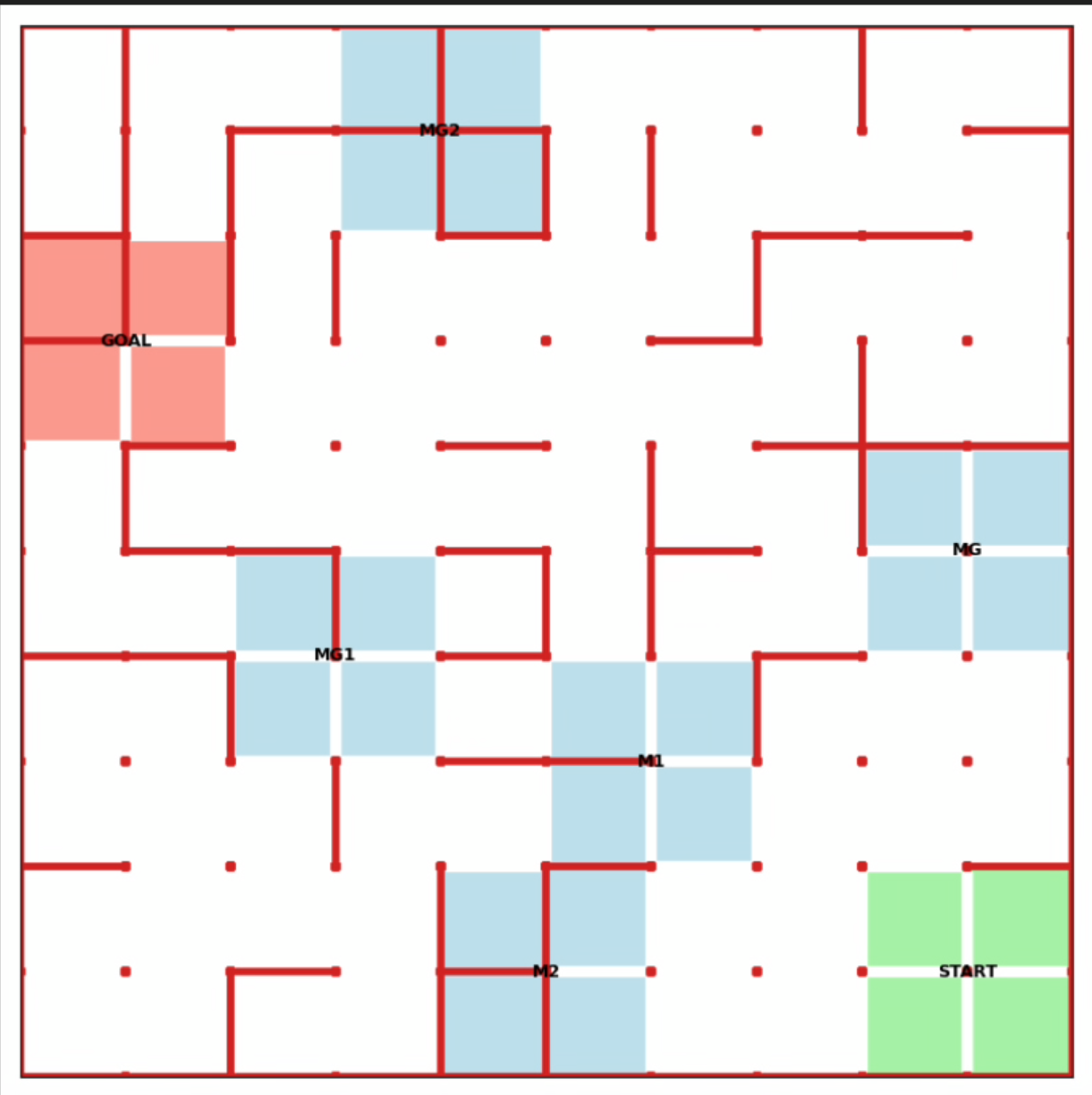
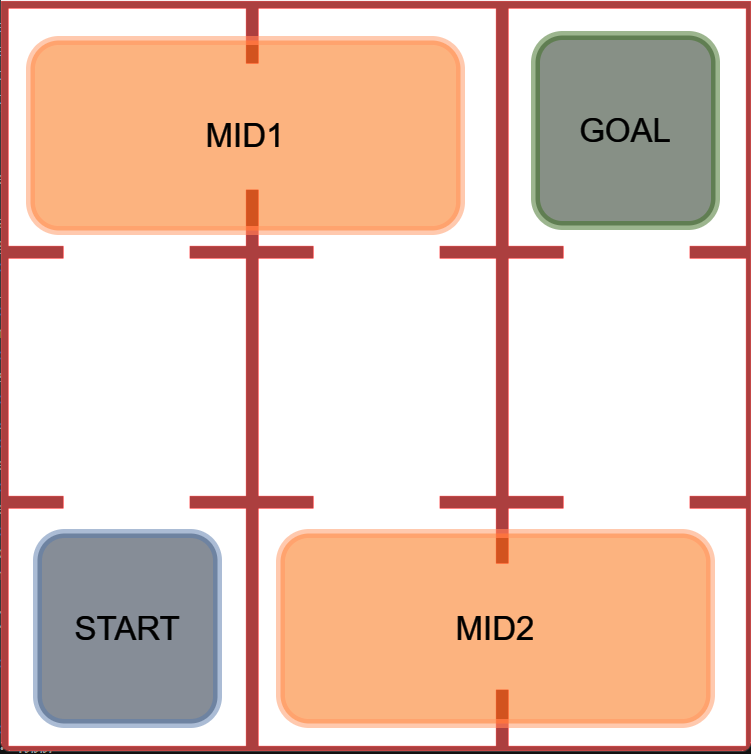
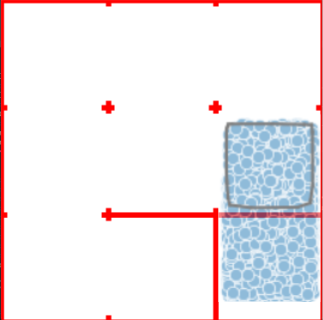
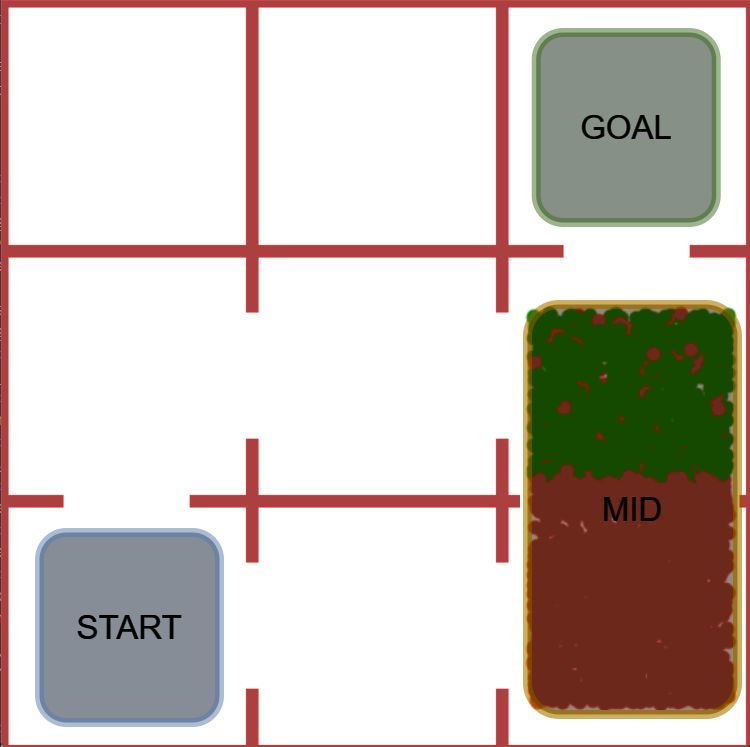
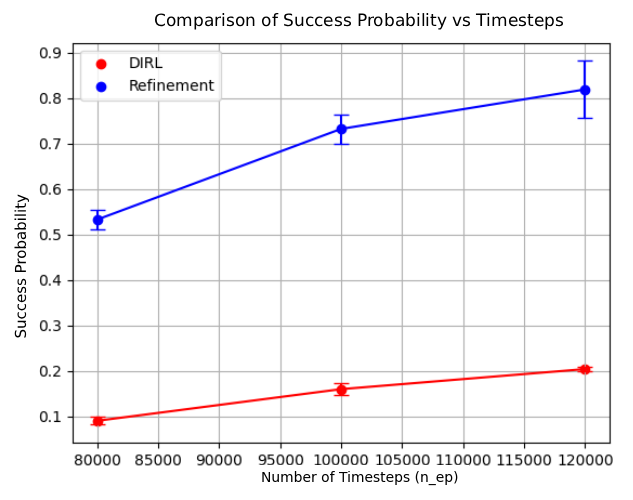
Figure 1: Example of refinement by AUTOSPEC in a 9-rooms environment. The original MID-node region includes a trap state from which recovery is impossible. The refined specification excludes this trap, enabling the agent to learn a policy with higher satisfaction probability.
We present AUTOSPEC, a framework for automatically refining coarse specifications without user intervention. We say that a logical specification is coarse (or under-specified) if its predicate labelings or logical structure are too coarse to allow specification-guided RL algorithms to translate logical specifications into reward functions that allow for effective learning of RL policies. AUTOSPEC starts with an initial logical specification, translates it to a reward function, and attempts to learn a policy. If the learned policy’s performance is unsatisfactory, AUTOSPEC identifies which specification components cause learning failures and automatically refines both the specification formula and labeling function. The refined specification’s satisfaction implies the original’s satisfaction while providing additional structure for learning. This process repeats until a satisfactory policy is learned.
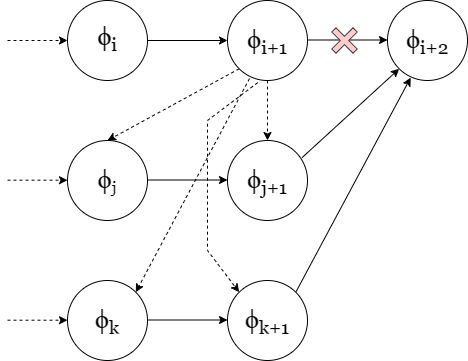
AUTOSPEC works with SpectRL specifications; boolean and sequential combinations of reach-avoid tasks Jothimurugan et al. (2019). Any SpectRL specification decomposes into an abstract graph where edges specify reach-avoid tasks Jothimurugan et al. (2021). AUTOSPEC identifies problematic edges and applies targeted refinements: either modifying the labeling function for regions (Figure 1) or restructuring the graph to add alternative paths. These problematic edges are identified by employing an exploration-guided strategy that utilizes empirical trajectory data to identify edges in the abstract graph whose reach-avoid tasks (i.e. initial, target or unsafe regions) make it hard to learn a good RL policy. For instance, in Figure 1, the initial MID region of the MID-GOAL edge in the abstract graph is under-specified, as it overlaps with a trap state. The trap state is not immediately obvious as there is a path from MID to GOAL. By analyzing explored traces, AUTOSPEC identifies problematic start states in MID and refines the region to exclude the trap (as shown in Figure 1), thereby refining the logical reach-avoid specification associated to the MID-GOAL edge.
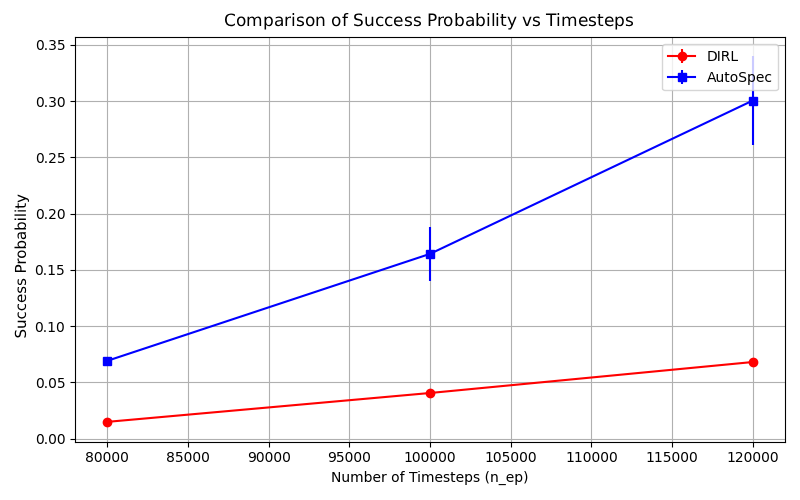
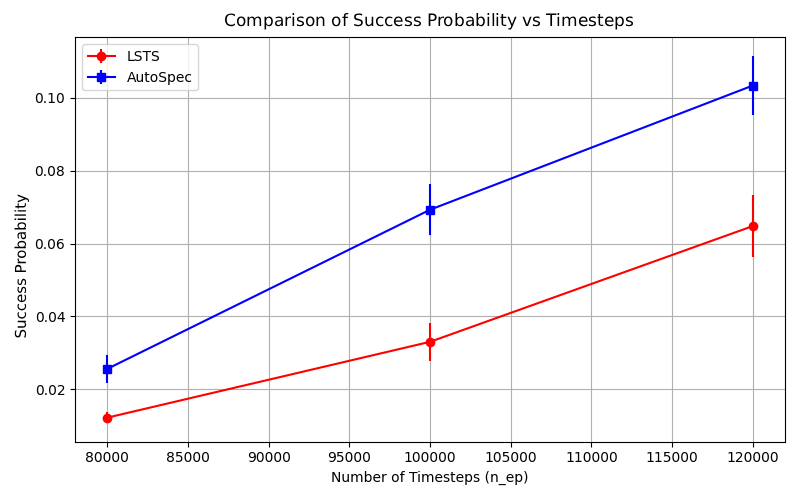
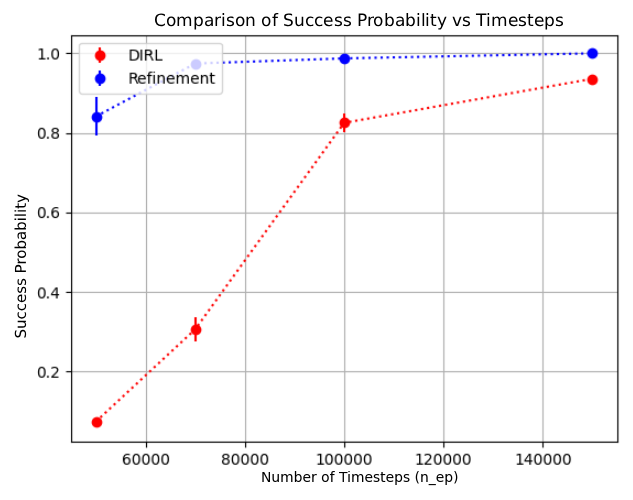
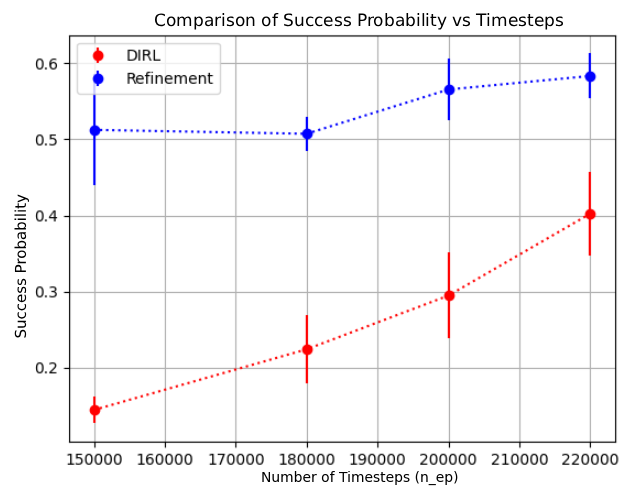
We prove that all refinements maintain soundness, where satisfaction of the refined specification implies satisfaction of the original. AUTOSPEC integrates with existing SpectRL-compatible algorithms as demonstrated with DIRL Jothimurugan et al. (2021) and LSTS Shukla et al. (2024).
Our contributions:
A framework for automated refinement of logical RL specifications with four refinement procedures, all with formal soundness guarantees (Section 3).
Integration with existing specification-guided RL algorithms, enabling them to solve tasks with coarse specifications (Section 3).
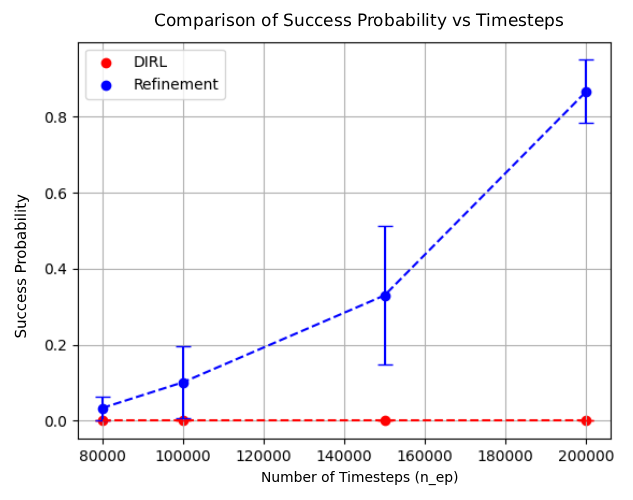
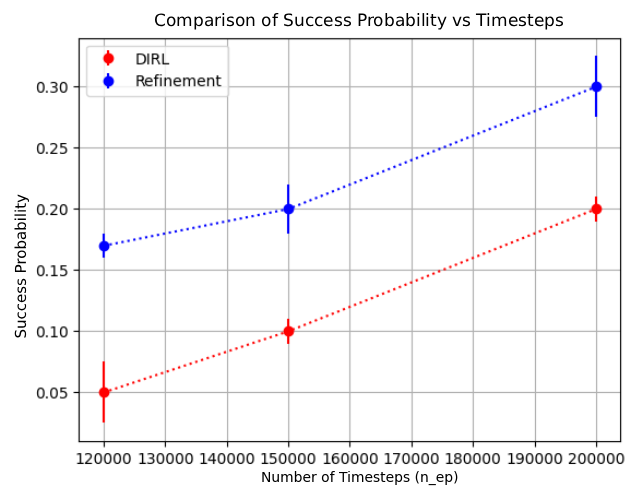
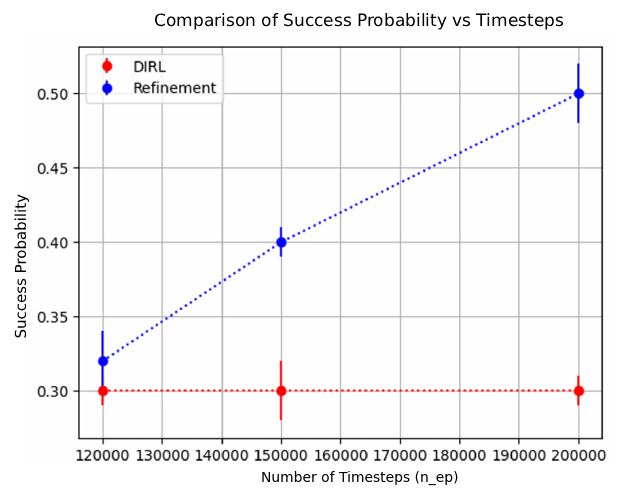
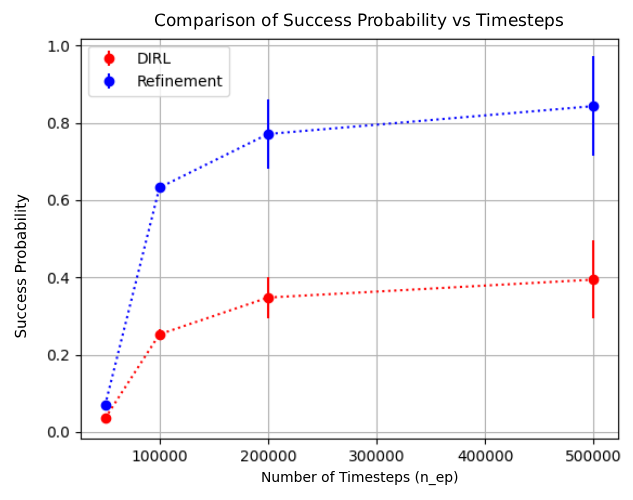
Empirical demonstration that AUTOSPEC enables learning from specifications that existing methods cannot handle (Section 4). 2019) consider tasks that can be specified using deterministic finite automata (DFA) and solve them by reward machines, which decompose these tasks and translate them into a reward function. The reward function can then be used to train existing RL algorithms. Li et al. (2017b) considers a variant of LTL called TLTL for specifying tasks and propose a method for translating these specifications into continuous reward functions. Hasanbeig et al. (2022;201
This content is AI-processed based on open access ArXiv data.