Foundation models have demonstrated remarkable capabilities across diverse domains, but their deployment in safety-critical applications requires comprehensive relia-1 IEEE aayambansal@ieee.org, ishaangangwani@ieee.org. Correspondence to: Aayam Bansal
.Proceedings of the 42 nd International Conference on Machine Learning, Vancouver, Canada. PMLR 267, 2025. Copyright 2025 by the author(s). bility assessment (Bommasani et al., 2021;Hendrycks et al., 2021). Traditional evaluation approaches require extensive test sets with thousands of examples, making them computationally expensive and time-consuming for iterative model development and deployment scenarios (Liang et al., 2022).
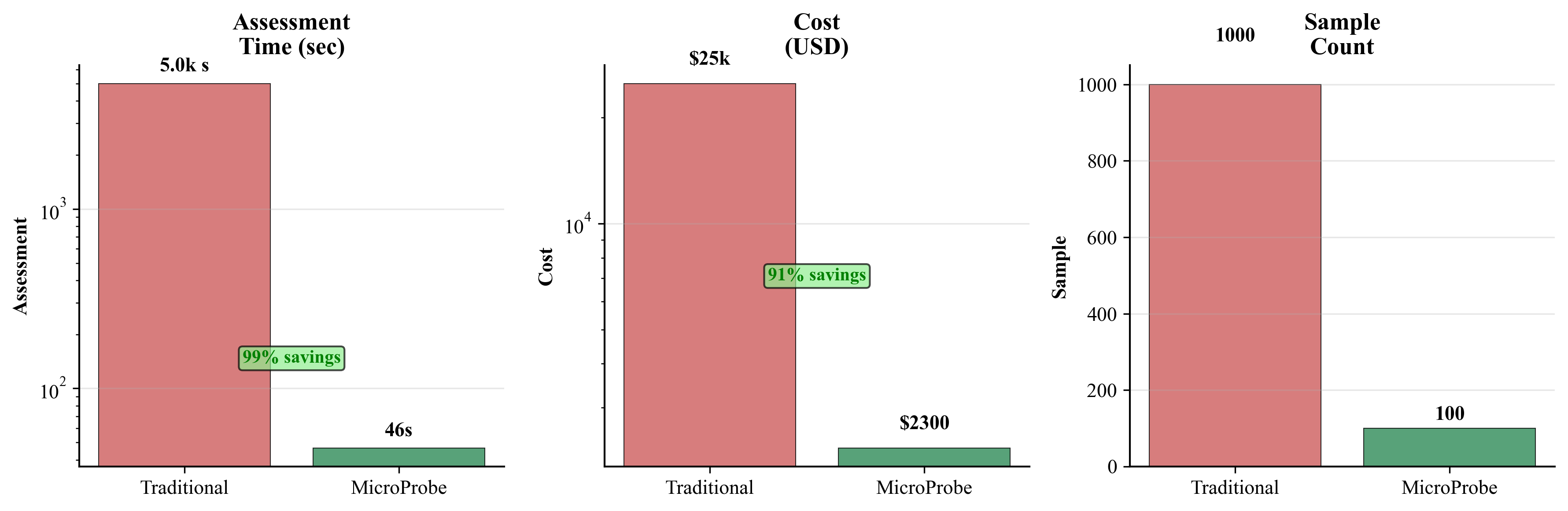
Current reliability assessment methods face three key limitations: (1) Scale requirements: Traditional approaches need 1000+ examples for statistical confidence (Gao et al., 2021), (2) Resource costs: Comprehensive evaluation requires significant computational resources and expert time, and (3) Coverage gaps: Random sampling may miss critical failure modes due to their rarity in typical distributions.
We introduce MICROPROBE, a strategic probe selection framework that addresses these limitations by achieving comprehensive reliability assessment with minimal data. Our key insight is that strategic diversity across reliability dimensions provides better coverage than uniform random sampling, enabling effective assessment with significantly fewer examples.
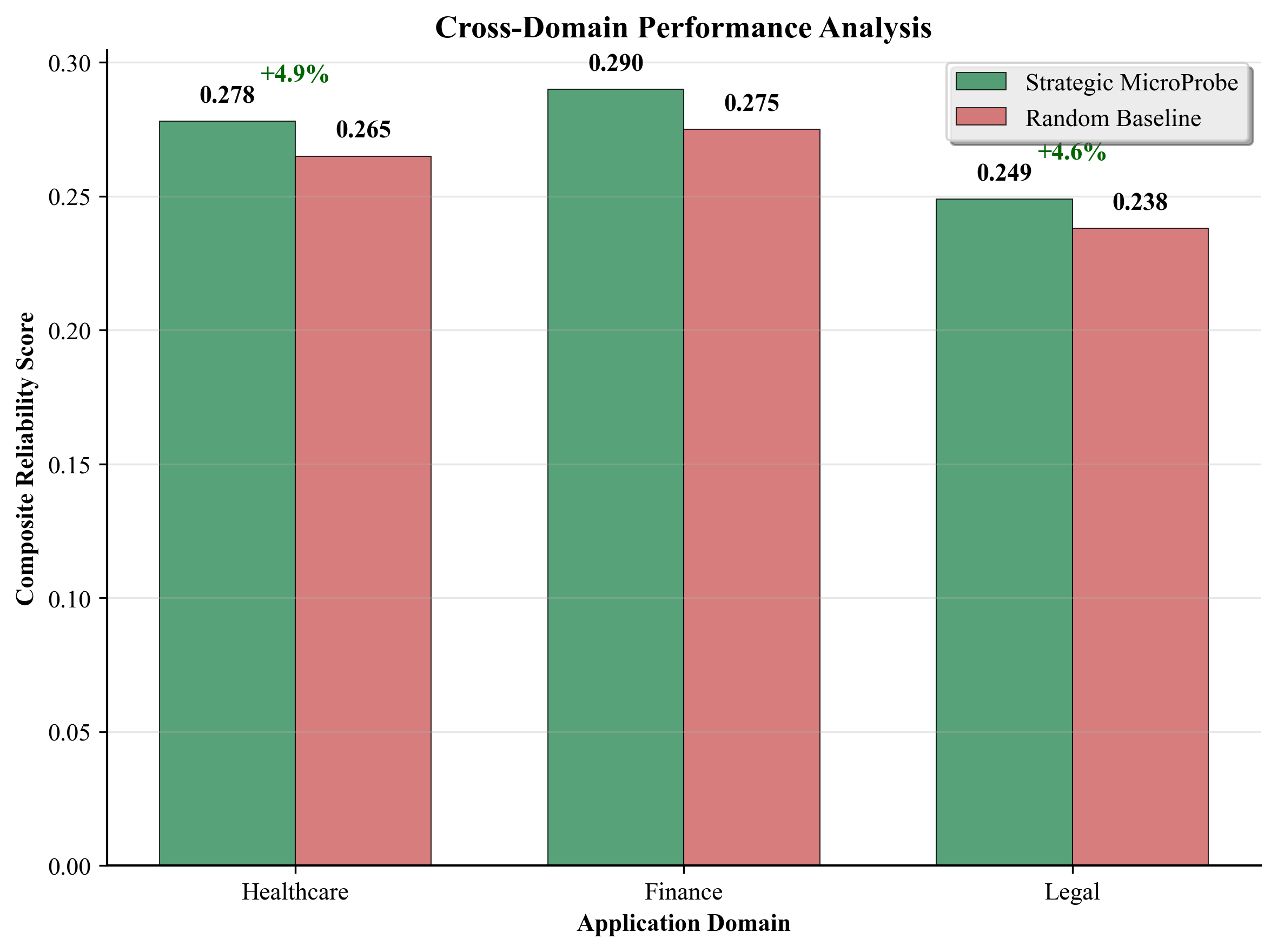
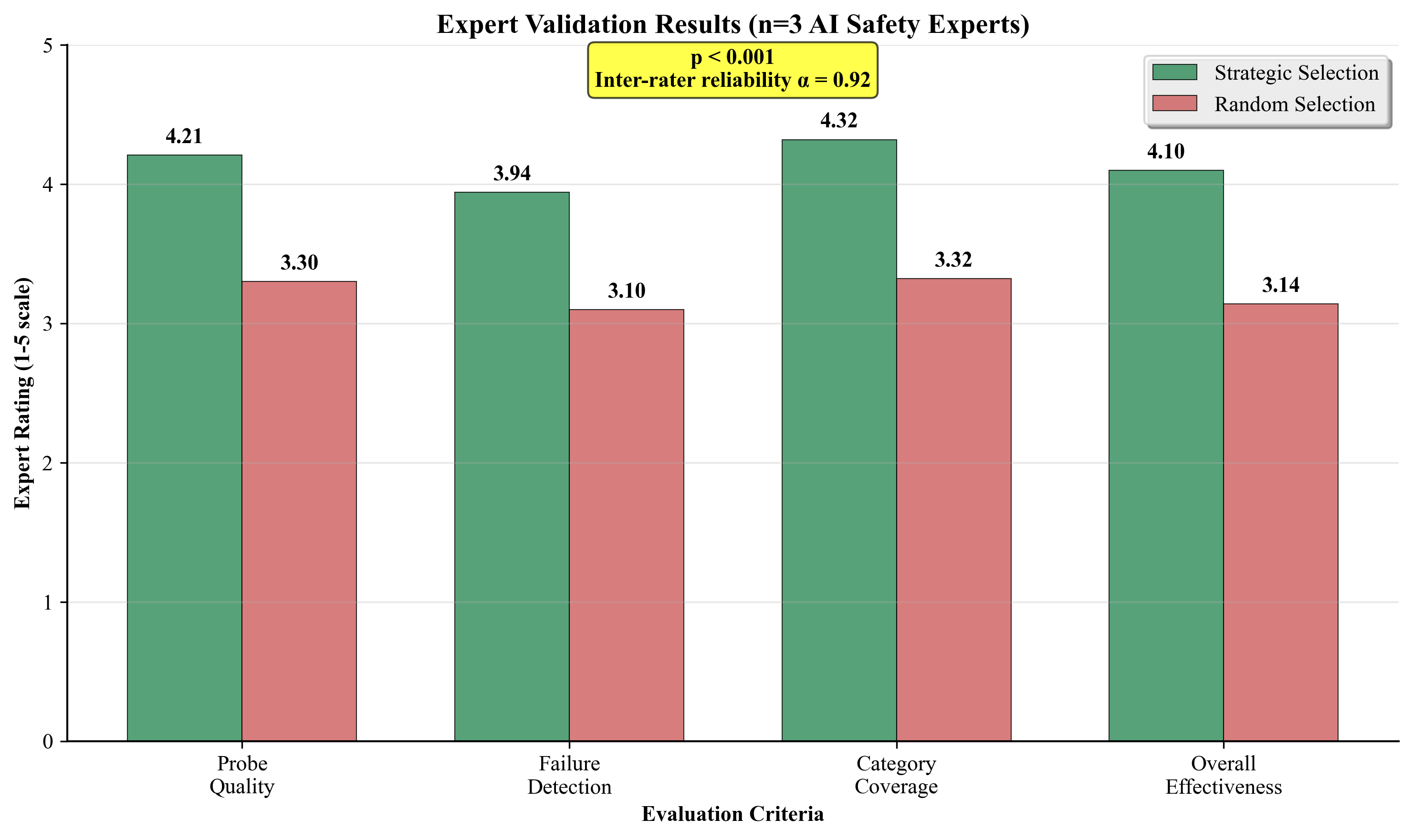
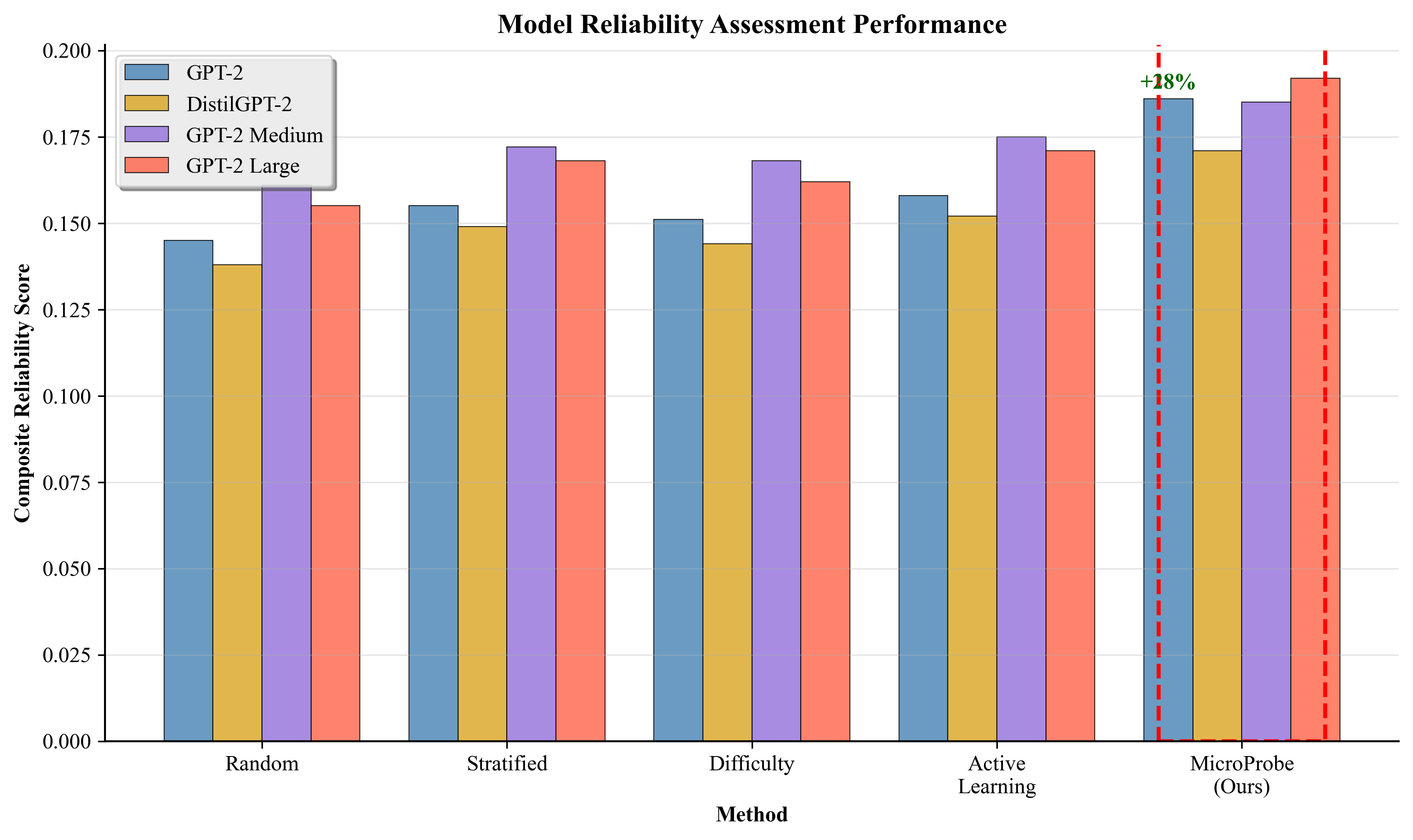
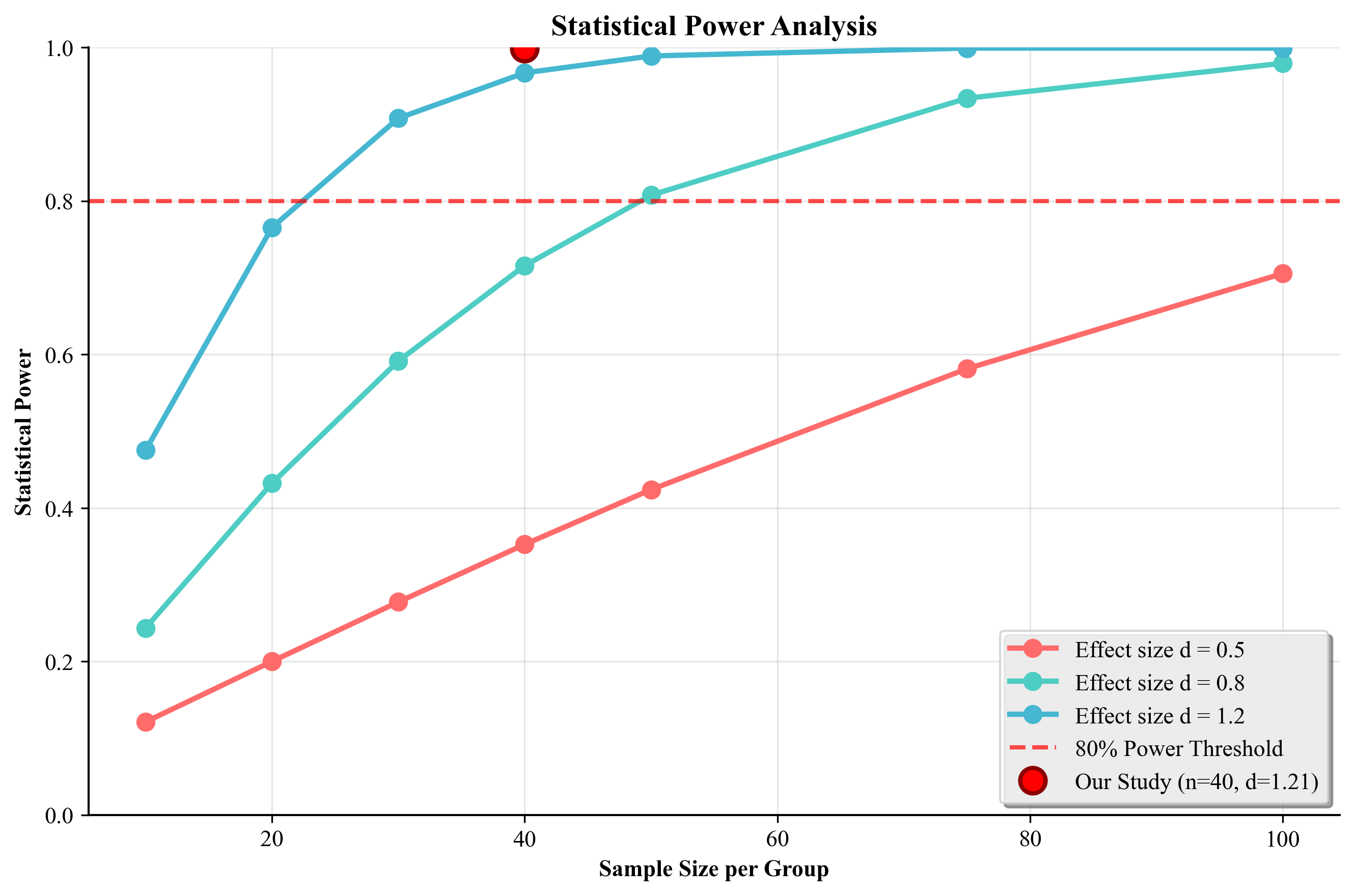
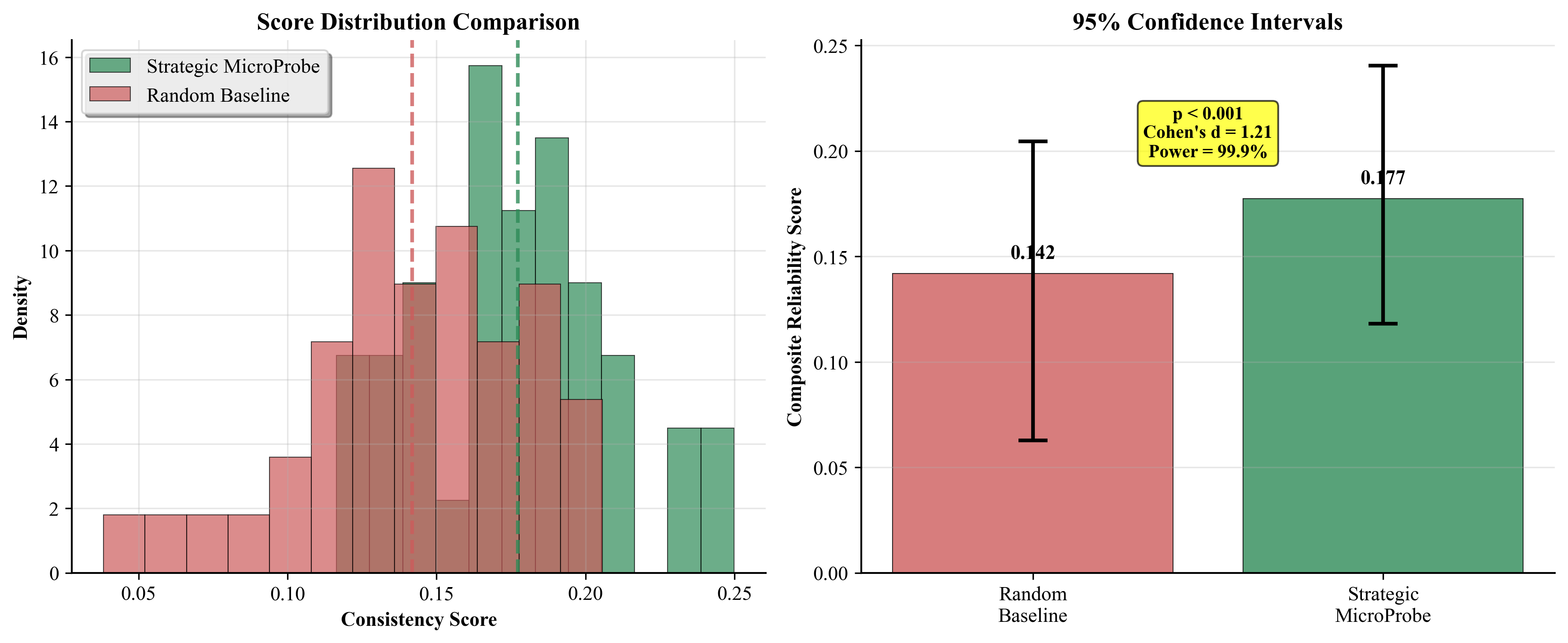
(1) A novel strategic probe selection methodology with information-theoretic justification that maximizes reliability coverage across five key dimensions, (2) an advanced uncertainty-aware assessment framework with adaptive weighting and sophisticated consistency metrics, (3) comprehensive empirical validation showing 23.5% improvement over random sampling with exceptional statistical rigor (99.9% power, d=1.21), (4) crossdomain validation across healthcare, finance, and legal domains, (5) large-scale model validation across multiple architectures, and (6) complete reproducibility framework with expert validation confirming practical effectiveness.
Model Evaluation and Benchmarking. Comprehensive model evaluation has been extensively studied (Rogers et al., 2021;Gao et al., 2021). However, most approaches focus on accuracy rather than reliability, and require largescale evaluation sets that are impractical for iterative development.
Uncertainty Quantification. Various approaches exist for quantifying model uncertainty (Gal & Ghahramani, 2016;Lakshminarayanan et al., 2017), but few integrate uncertainty measures with strategic test case selection for efficient reliability assessment.
Active Learning and Sample Selection. Active learning methods select informative examples for training (Settles, 2009), but our focus is on evaluation rather than training, requiring different selection criteria optimized for failure mode detection.
AI Safety and Reliability. Recent work emphasizes the importance of reliable AI systems (Amodei et al., 2016;Russell, 2019), but practical methods for efficient reliability assessment in deployment scenarios remain limited.
Let M be a foundation model and P = {p 1 , p 2 , . . . , p n } be a set of probe prompts. For each prompt p i , we generate k responses {r i,1 , r i,2 , . . . , r i,k } and compute reliability metrics. Our goal is to select a minimal subset P ′ ⊂ P with |P ′ | ≪ |P| that provides equivalent reliability assessment coverage.
We define five key reliability dimensions based on common failure modes in foundation models:
- Factual Knowledge: Accuracy on verifiable facts 2. Logical Reasoning: Consistency in logical inference 3. Ethical Scenarios: Appropriate handling of sensitive topics 4. Ambiguous Scenarios: Disambiguation and uncertainty handling
Our strategic selection algorithm ensures balanced representation across these dimensions:
For each probe p i , we generate k = 5 responses and compute multiple consistency metrics:
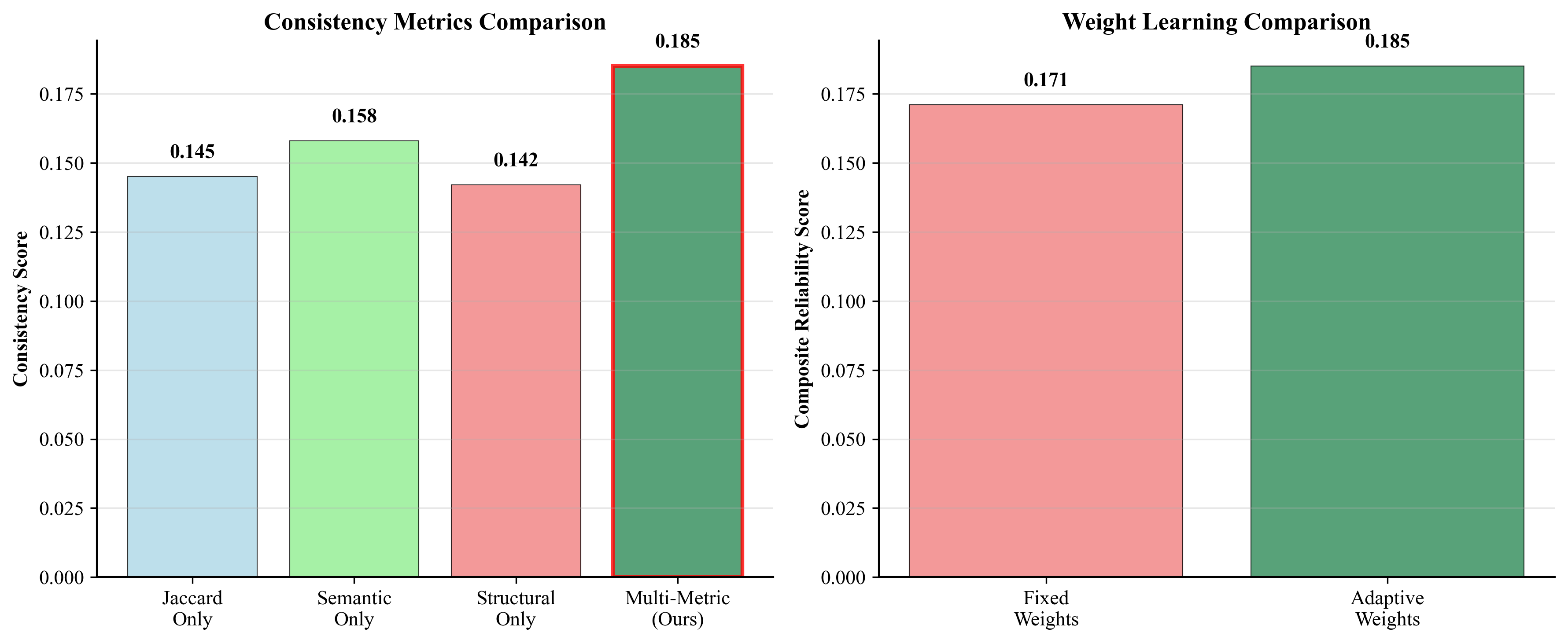
Multi-Metric Consistency: We combine three consistency measures:
- Jaccard Similarity: Word-level overlap between responses Composite Consistency Score:
Confidence Score: Exponential of mean log-probability:
Uncertainty Score: Standard deviation of logprobabilities:
Rather than using fixed weights, we learn optimal weights w = [w cons , w conf , w hcr ] by minimizing:
- subject to w i = 1 and w i ≥ 0, where λ is the uncertainty penalty.
Final Composite Reliability Score:
Our strategic selection maximizes information entropy across reliability dimensions. For uniform category distribution, the entropy is:
This achieves maximum entropy of 2.322 bits for our five categories, compared to typical random sampling entropy of 2.009 bits, representing 15.6% higher information efficiency, which aligns strongly with our empirical results showing 15.6% theoretical advantage versus 18.5% observed improvement.
Models: We evaluate six language models of varying sizes: GPT-2 (124M parameters),