Title: Energy-Aware Data-Driven Model Selection in LLM-Orchestrated AI Systems
ArXiv ID: 2512.01099
Date: 2025-11-30
Authors: ** Daria Smirnova, Hamid Nasiri, Marta Adamska, Zhengxin Yu, Peter Garraghan School of Computing and Communications, Lancaster University (영국) **
📝 Abstract
As modern artificial intelligence (AI) systems become more advanced and capable, they can leverage a wide range of tools and models to perform complex tasks. Today, the task of orchestrating these models is often performed by Large Language Models (LLMs) that rely on qualitative descriptions of models for decision-making. However, the descriptions provided to these LLM-based orchestrators do not reflect true model capabilities and performance characteristics, leading to suboptimal model selection, reduced accuracy, and increased energy costs. In this paper, we conduct an empirical analysis of LLM-based orchestration limitations and propose GUIDE, a new energy-aware model selection framework that accounts for performance-energy trade-offs by incorporating quantitative model performance characteristics in decision-making. Experimental results demonstrate that GUIDE increases accuracy by 0.90%-11.92% across various evaluated tasks, and achieves up to 54% energy efficiency improvement, while reducing orchestrator model selection latency from 4.51 s to 7.2 ms.
💡 Deep Analysis
📄 Full Content
Energy-Aware Data-Driven Model Selection in
LLM-Orchestrated AI Systems
Daria Smirnova, Hamid Nasiri, Marta Adamska, Zhengxin Yu, and Peter Garraghan
School of Computing and Communications, Lancaster University
Email: {d.smirnova1, h.nasiri, m.adamska, z.yu8, p.garraghan}@lancaster.ac.uk
Abstract—As modern artificial intelligence (AI) systems become
more advanced and capable, they can leverage a wide range of
tools and models to perform complex tasks. Today, the task of
orchestrating these models is often performed by Large Language
Models (LLMs) that rely on qualitative descriptions of models
for decision-making. However, the descriptions provided to these
LLM-based orchestrators do not reflect true model capabilities and
performance characteristics, leading to suboptimal model selection,
reduced accuracy, and increased energy costs. In this paper, we
conduct an empirical analysis of LLM-based orchestration limi-
tations and propose GUIDE, a new energy-aware model selection
framework that accounts for performance–energy trade-offs by
incorporating quantitative model performance characteristics in
decision-making. Experimental results demonstrate that GUIDE
increases accuracy by 0.90%–11.92% across various evaluated
tasks, and achieves up to 54% energy efficiency improvement,
while reducing orchestrator model selection latency from 4.51 s
to 7.2 ms.
I. INTRODUCTION
Modern AI systems have seen widespread adoption. Con-
ventional AI systems are designed to complete a singular or
narrow set of tasks such as object detection [1] or speech
recognition [2]. AI systems – particularly those using Large
Language Models (LLMs) – can facilitate complex tasks
by leveraging an assortment of tools and models in tandem
to expand system versatility and capability. Orchestration –
responsible for determining model selection, planning, and
execution to complete tasks [3] – is key in AI systems. As
system scale and the number of models grow, there is an urgent
need to design AI system orchestrators that operate at high
speed, accuracy, and low cost.
In response, researchers have recently identified that LLMs
due to their strong reasoning capabilities can be instructed
to operate as AI system orchestrators. These LLM-based
orchestrators leverage foundational models to reason, make
decisions, and act to invoke specific tools and models [4, 5, 6].
The effectiveness of these orchestrators has resulted in their
increased adoption within agentic tool-augmented systems [7].
However, existing LLM-based orchestrators encounter many
challenges pertaining to their performance and efficiency:
(i) Orchestrator decision making for model selection is
limited to qualitative data of a model’s capability, specifically
model cards and textual descriptions (e.g., recommended tasks
or number of user likes on HuggingFace) [8]. While such
information helps provide task context to the orchestrator, it
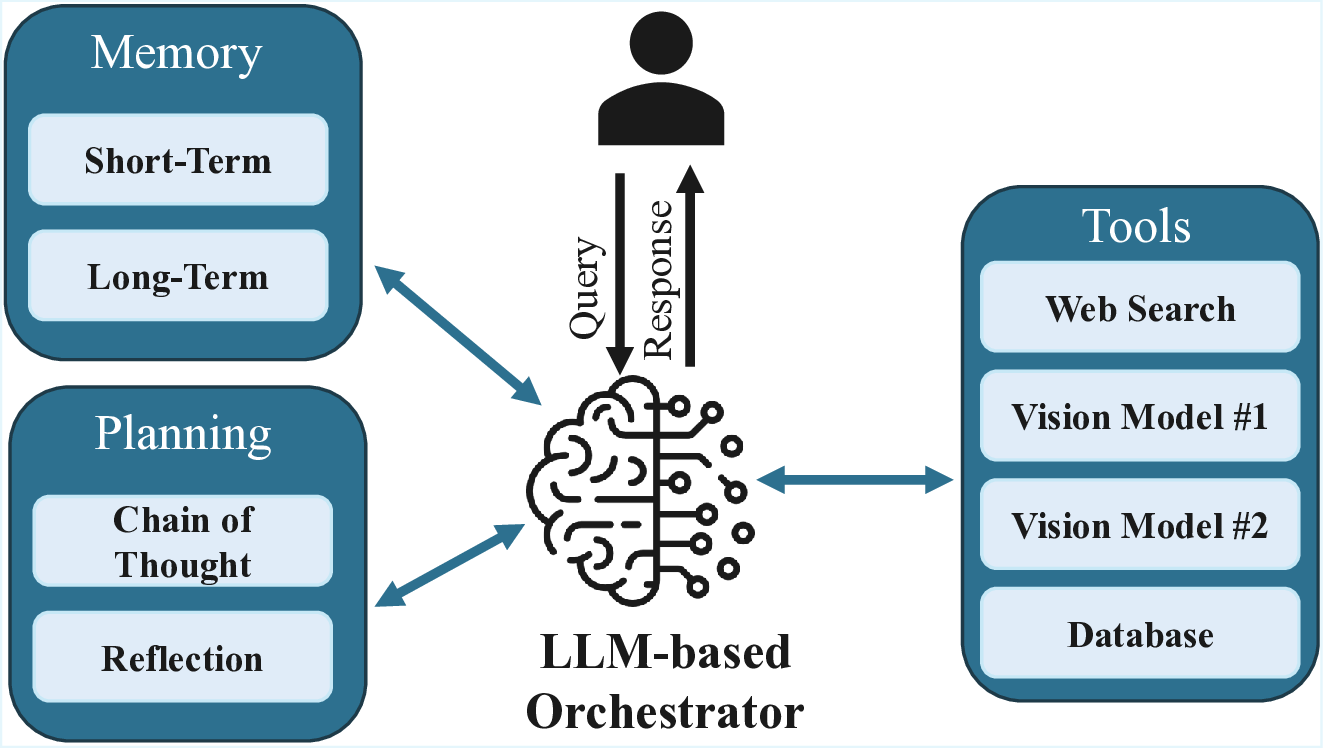
Tools
Vision Model #1
LLM-based
Orchestrator
Planning
Chain of
Thought
Reflection
Memory
Short-Term
Long-Term
Query
Response
Vision Model #2
Database
Web Search
Fig. 1. Overview of an LLM-orchestrated AI system.
does not capture task-level performance (i.e. accuracy, energy
cost). Reliance solely on qualitative model information results
in suboptimal selection of models that are neither the most
accurate nor cost-efficient.
(ii) LLM-based orchestration requires extensive communi-
cation with an LLM to operate — i.e., textual descriptions of
models must be sent to the LLM to provide context, such as
API descriptions and usage examples for each tool [9]. This
incurs significant token usage and latency (especially at greater
AI system scale), both of which increase energy consumption
and reduce system throughput. Moreover, the LLM’s context
window limits the number of tools the orchestrator can consider.
Hence, we assert that the current design of LLM-based
orchestrators for model selection significantly impairs AI
system scalability, performance, and efficiency.
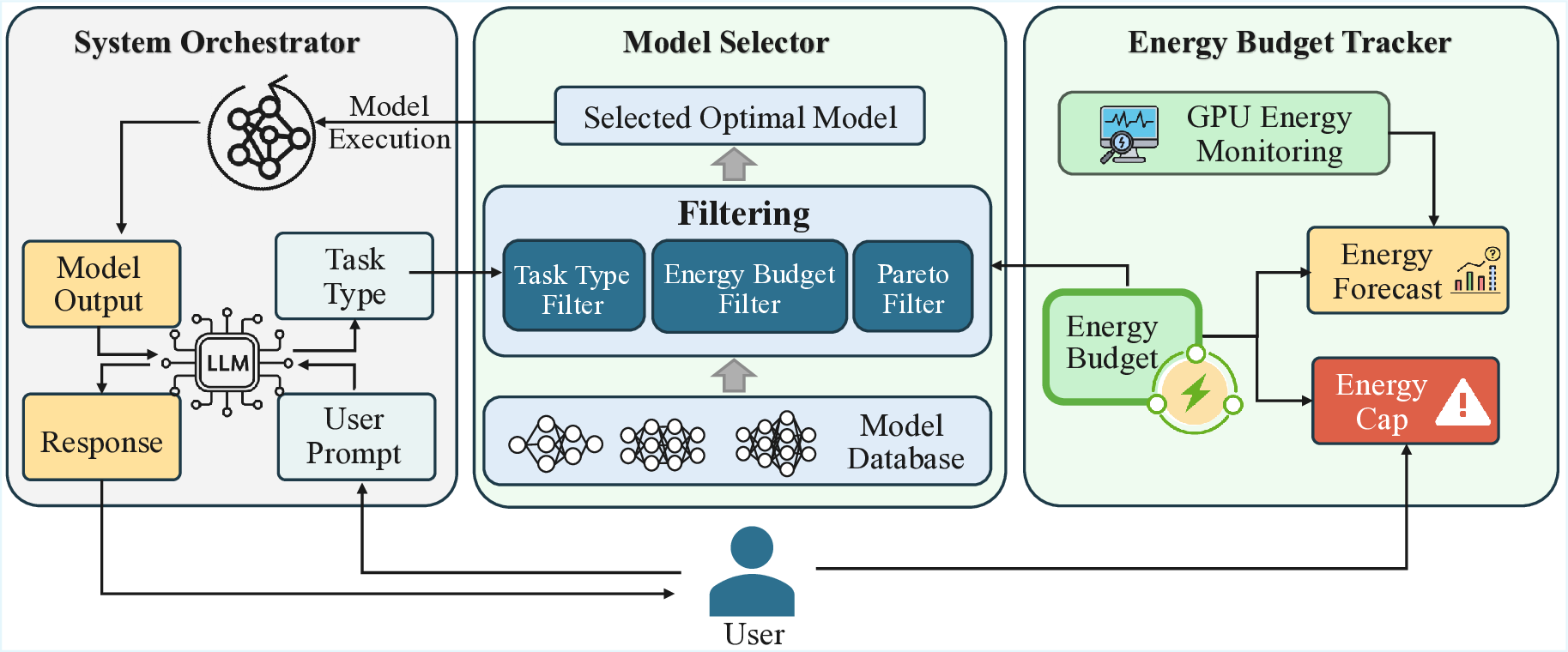
To address these limitations, we postulate that incorporating
quantitative data (accuracy, energy cost, etc.) into orchestrator
decisions would result in more effective model selection,
enabling the AI system to balance task accuracy and cost-
efficiency (specifically energy use, given the growing concerns
of AI sustainability and datacenter growth [10]). There have
been extensive discussions on performance–energy trade-offs
in adjacent domains such as LLM-serving [11, 12, 13, 14]
and IoT [15]. However, to the best of our knowledge, there is
no prior work that has analyzed the above limitations or the
effectiveness of incorporating quantitative data within LLM-
based orchestration for AI systems.
In this paper, we present a comprehensive experimental
analysis of LLM-based orchestrator operation and highlight
recurrent shortcomings. We identify that LLM orchestrators
arXiv:2512.01099v1 [cs.AI] 30 Nov 2025
systematically select underperforming models that increase
costs and energy use with mini