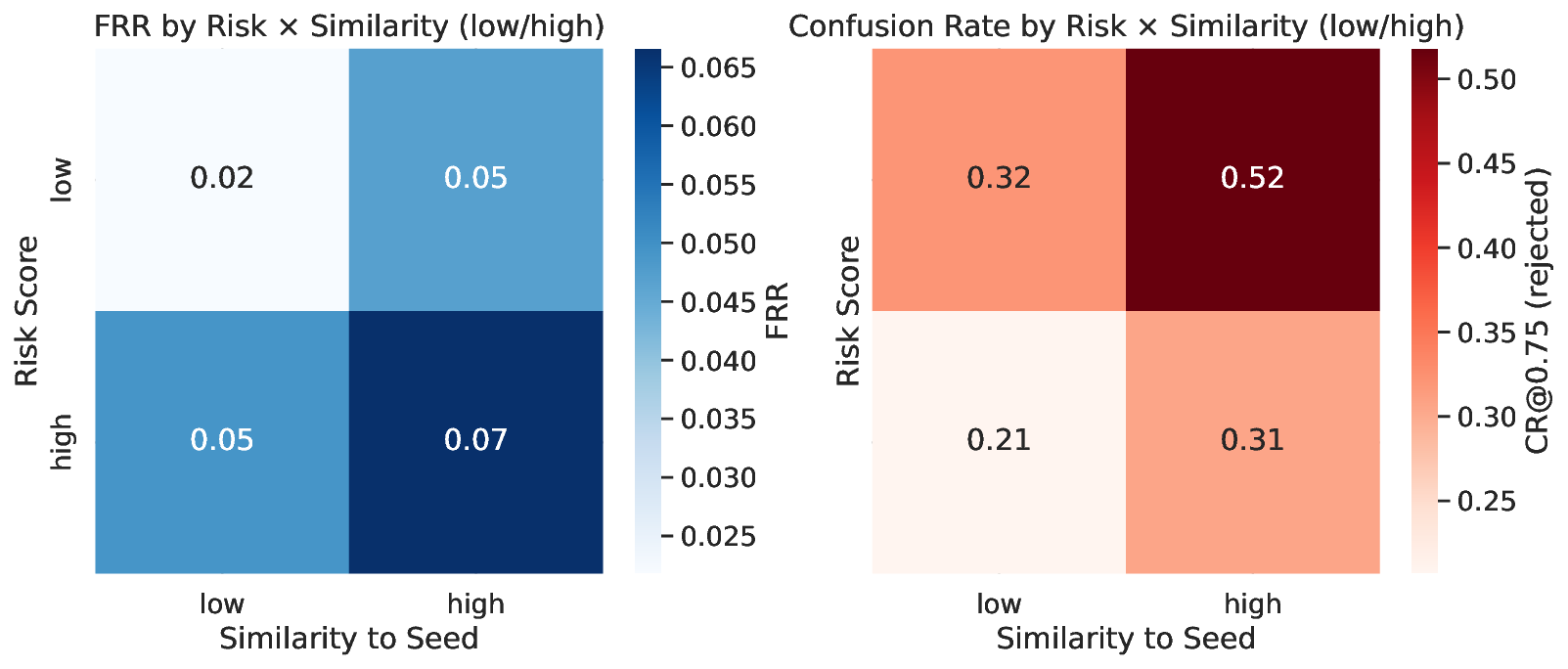
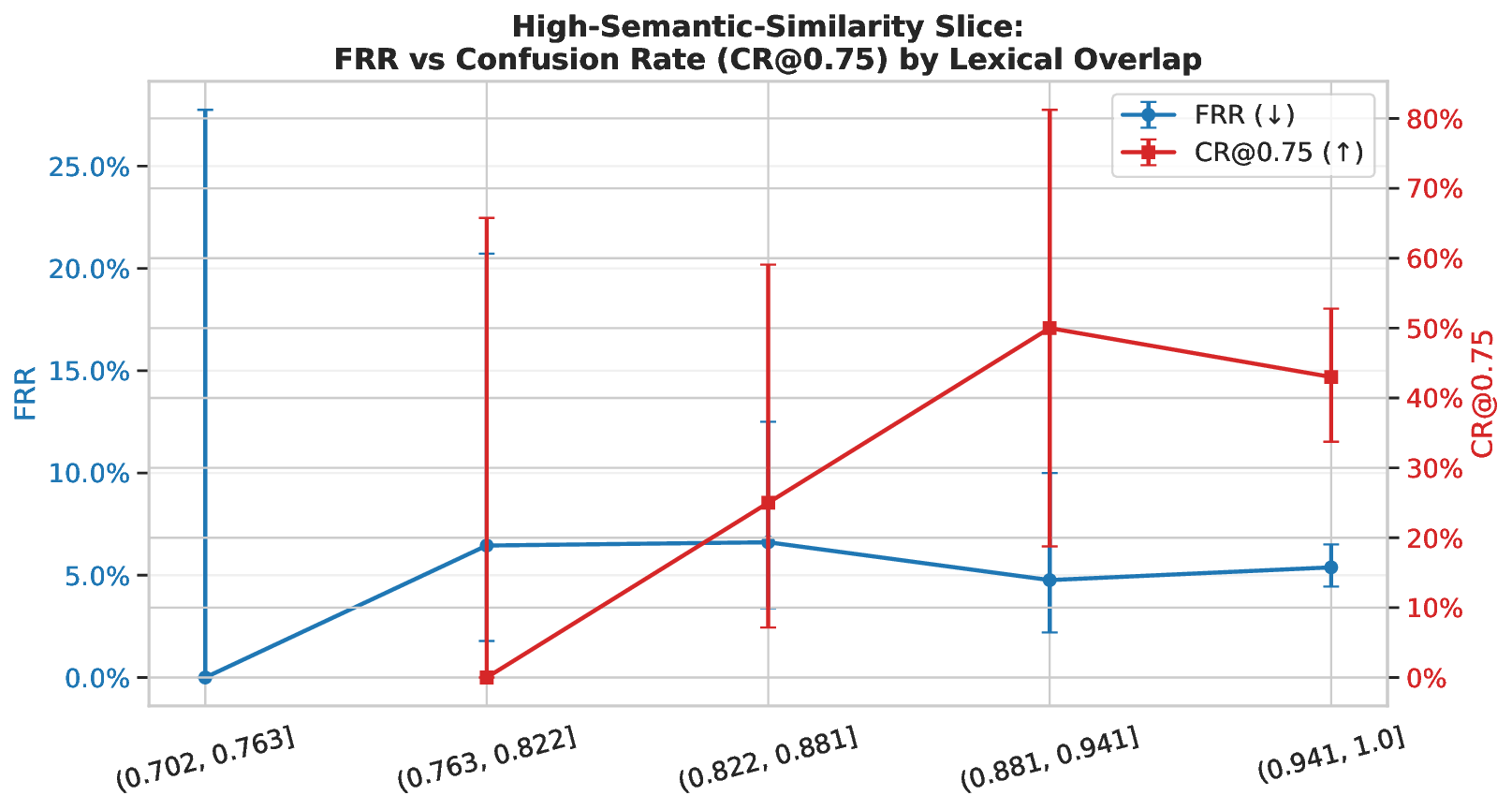
Safety-aligned language models often refuse prompts that are actually harmless. Current evaluations mostly report global rates such as false rejection or compliance. These scores treat each prompt alone and miss local inconsistency, where a model accepts one phrasing of an intent but rejects a close paraphrase. This gap limits diagnosis and tuning. We introduce "semantic confusion," a failure mode that captures such local inconsistency, and a framework to measure it. We build ParaGuard, a 10k-prompt corpus of controlled paraphrase clusters that hold intent fixed while varying surface form. We then propose three model-agnostic metrics at the token level: Confusion Index, Confusion Rate, and Confusion Depth. These metrics compare each refusal to its nearest accepted neighbors and use token embeddings, next-token probabilities, and perplexity signals. Experiments across diverse model families and deployment guards show that global false-rejection rate hides critical structure. Our metrics reveal globally unstable boundaries in some settings, localized pockets of inconsistency in others, and cases where stricter refusal does not increase inconsistency. We also show how confusion-aware auditing separates how often a system refuses from how sensibly it refuses. This gives developers a practical signal to reduce false refusals while preserving safety.
Large language models (LLMs) are now used in settings where safety and reliability are essential. Modern alignment pipelines, including pre-training data filtering, supervised safety tuning, and preference-based methods such as RLHF and Constitutional AI, aim to prevent harmful generations and ensure that models refuse malicious instructions [1]- [3]. Deployment-time guards, for example Llama Guard [4], ShieldGemma [5], and WildGuard [6], add a further moderation layer by blocking unsafe inputs and outputs. These mechanisms also introduce a welldocumented side effect: false refusals, where models reject benign prompts that merely resemble unsafe ones [7], [8]. Such failures erode user trust, distort expected product behavior, and push developers to loosen safety constraints, which can reduce overall safety.
Recent datasets and benchmarks (XSTest [9], OK-Test [10], PHTest [11], OR-Bench [12], FalseReject [13]) show that overrefusal is common and costly. Yet these efforts reveal a deeper issue: most evaluations report only * Equal contribution.
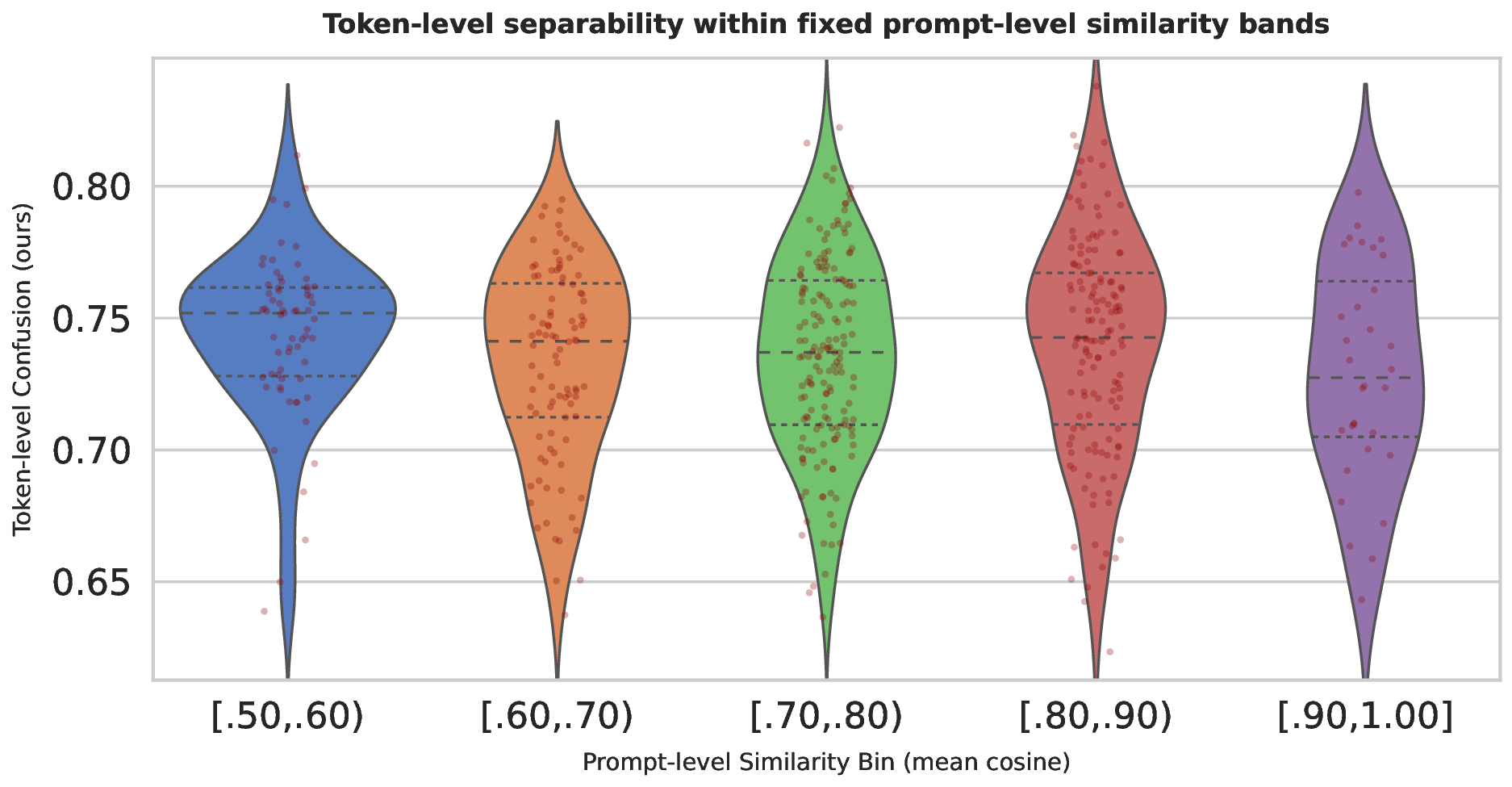
global summaries such as false rejection rate (FRR), compliance rate, or refusal gap. They score each prompt in isolation and therefore cannot detect local inconsistency, where a model accepts one phrasing of an intent but rejects a semantically equivalent paraphrase. This problem, which directly affects user facing reliability, remains largely unmeasured.
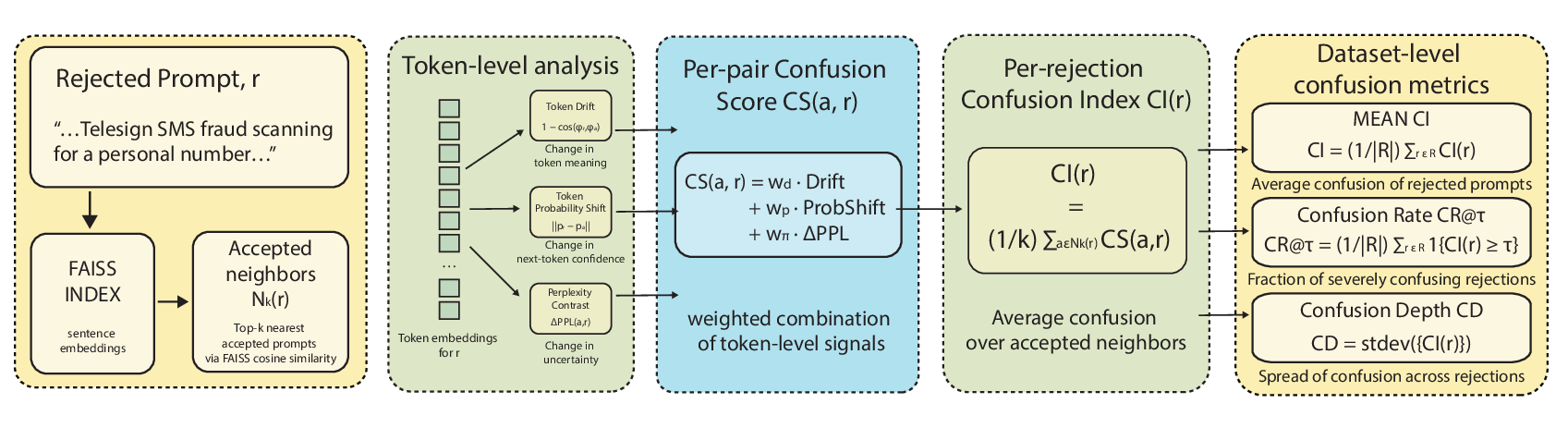
Closing this gap requires three elements that prior work does not provide: (i) tightly controlled paraphrase clusters that hold intent fixed while varying surface form, (ii) a way to condition each refusal on its nearest accepted neighbors, and (iii) token level signals that capture how the model’s processing diverges across near equivalent prompts. Building such clusters is difficult: paraphrases must be diverse enough to stress the guard while still semantically aligned, and filtering must ensure harmlessness without collapsing variants into trivial duplicates. In addition, a useful metric should be model agnostic, comparable across guard architectures, and sensitive to boundary irregularities that global statistics miss.
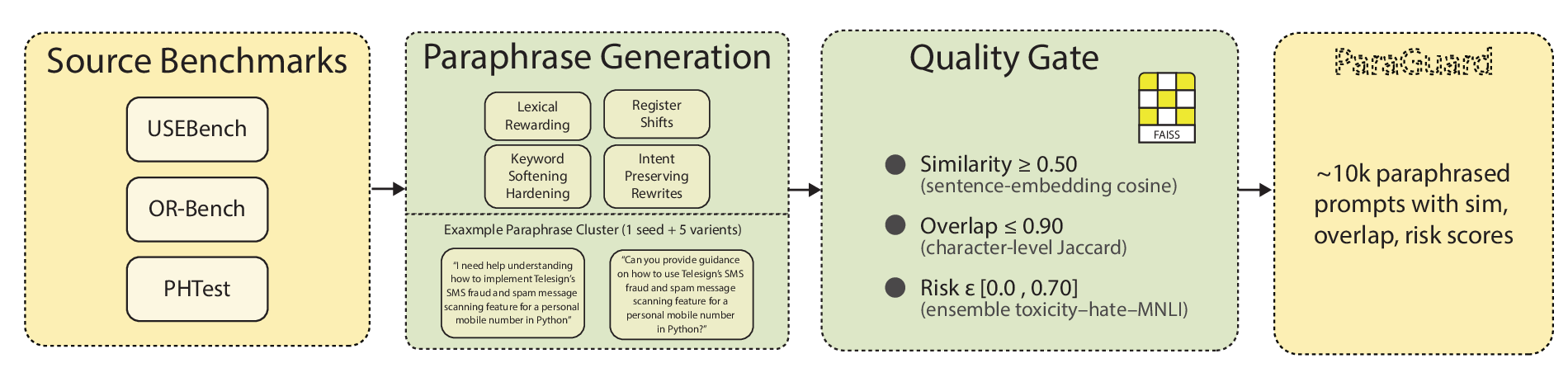
We introduce “semantic confusion”: contradictory decisions by an LLM across inputs that express the same intent, and we provide the first framework to quantify it. We build ParaGuard, a 10k-prompt dataset organized into controlled paraphrase clusters derived from OR-Bench, USEBench, and PHTest seeds. Each variant passes strict gates on semantic similarity, lexical divergence, and ensemble safety scores, creating structured neighborhoods where contradictory decisions can be measured and analyzed.
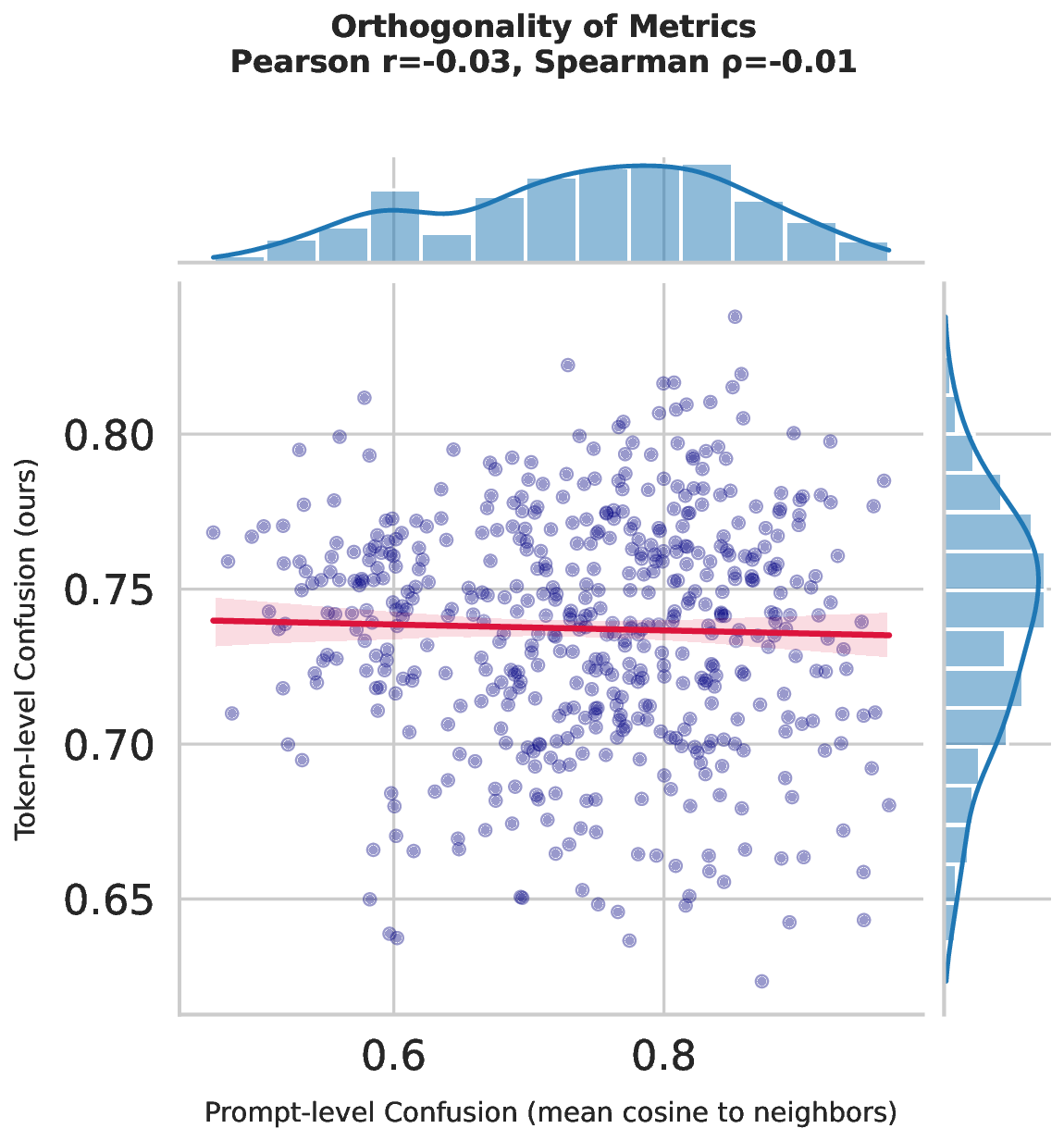
On this foundation, we develop three token-level metrics-Confusion Index (CI), Confusion Rate (CR), and Confusion Depth (CD)-that quantify disagreement between rejected prompts and their nearest accepted paraphrases. These metrics combine token-embedding drift, probability-distribution shift, and perplexity contrast, capturing complementary aspects of inconsistency that are invisible to prompt-level or global evaluations. Because they rely only on model outputs and token-level traces, they are model-agnostic and apply to any LLM or guard without retraining.
This semantic lens also offers a new evaluation axis for jailbreak defenses. Prior work typically reports attack success, defense success, and utility degradation [14], but does not examine whether a defense stabilizes or destabilizes the local decision boundary around benign paraphrases. CI/CR/CD reveal whether a defense that appears strong globally inadvertently increases semantic confusion, thereby harming usability.
We can summarize our contributions as follows: (1) Formalize “semantic confusion” as a measurable failure mode of safety-aligned LLMs and provide the first framework to quantify it. (2) Introduce ParaGuard, a 10k-prompt paraphrase corpus with controlled clusters that hold intent fixed while varying surface form, enabling neighborhood-conditioned evaluation. (3) Propose CI/CR/CD, model-agnostic token-level metrics that capture boundary inconsistency within paraphrase neighborhoods and complement global FRR. (4) Show-across diverse model families and deployment-time guards-that these metrics expose patterns invisible to global refusal rates, including globally unstable boundaries, localized pockets of inconsistency, and regimes where stricter refusal does not imply higher inconsistency, thereby separating how often models refuse from how sensibly they refuse.
Work on safety for large language models (LLMs) spans safety alignment, safety-helpfulness trade-offs, over-refusal benchmarks, jailbreak defenses, and alignment diagnostics. We position our notion of semantic confusion and our metrics (CI, CR, CD) within these areas, emphasizing where existing approaches stop at global statistics and where our local, token-level view adds discriminatory power.
Modern LLMs are aligned through staged pipelines: pre-training data filtering, sup
This content is AI-processed based on open access ArXiv data.