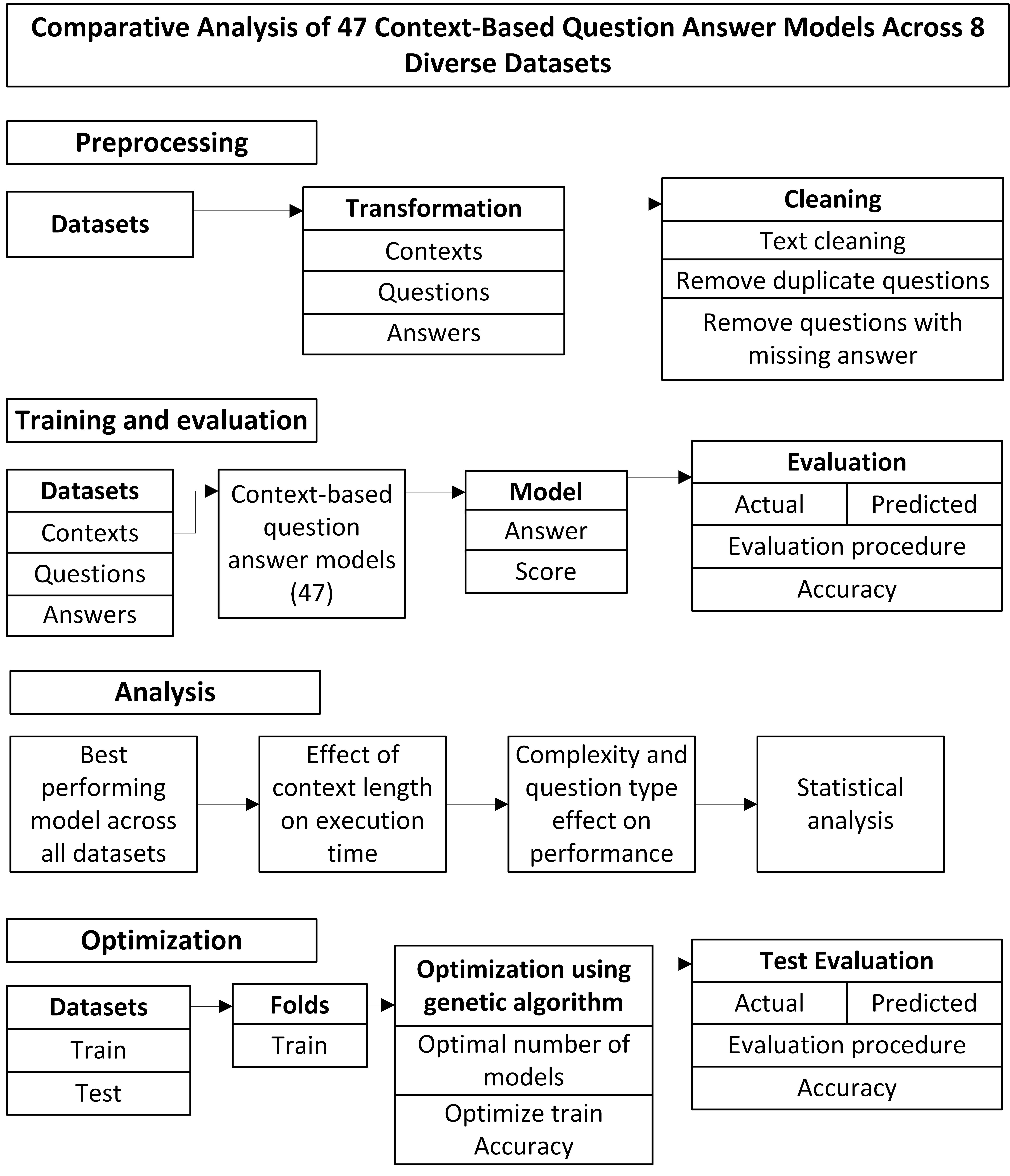
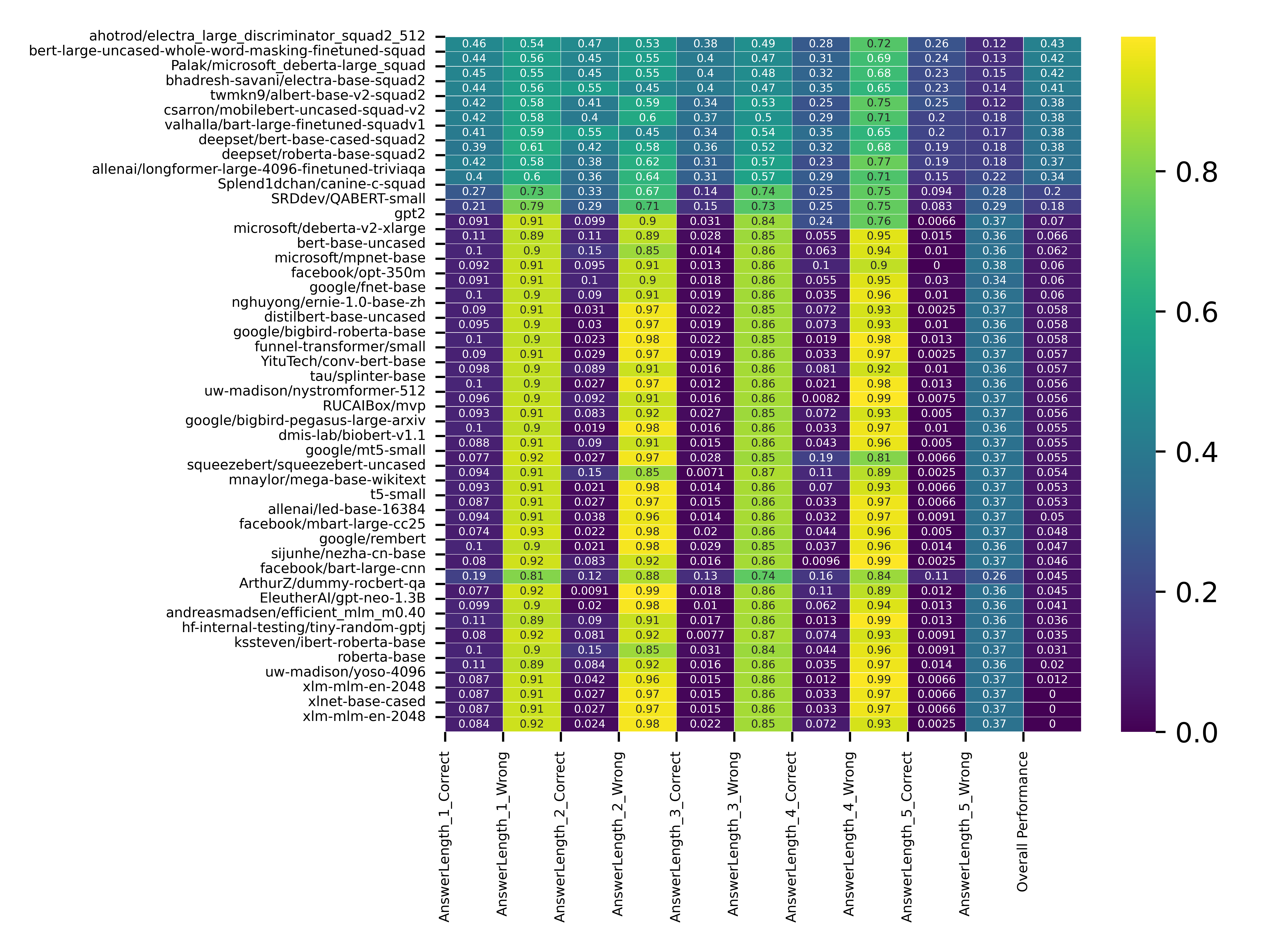
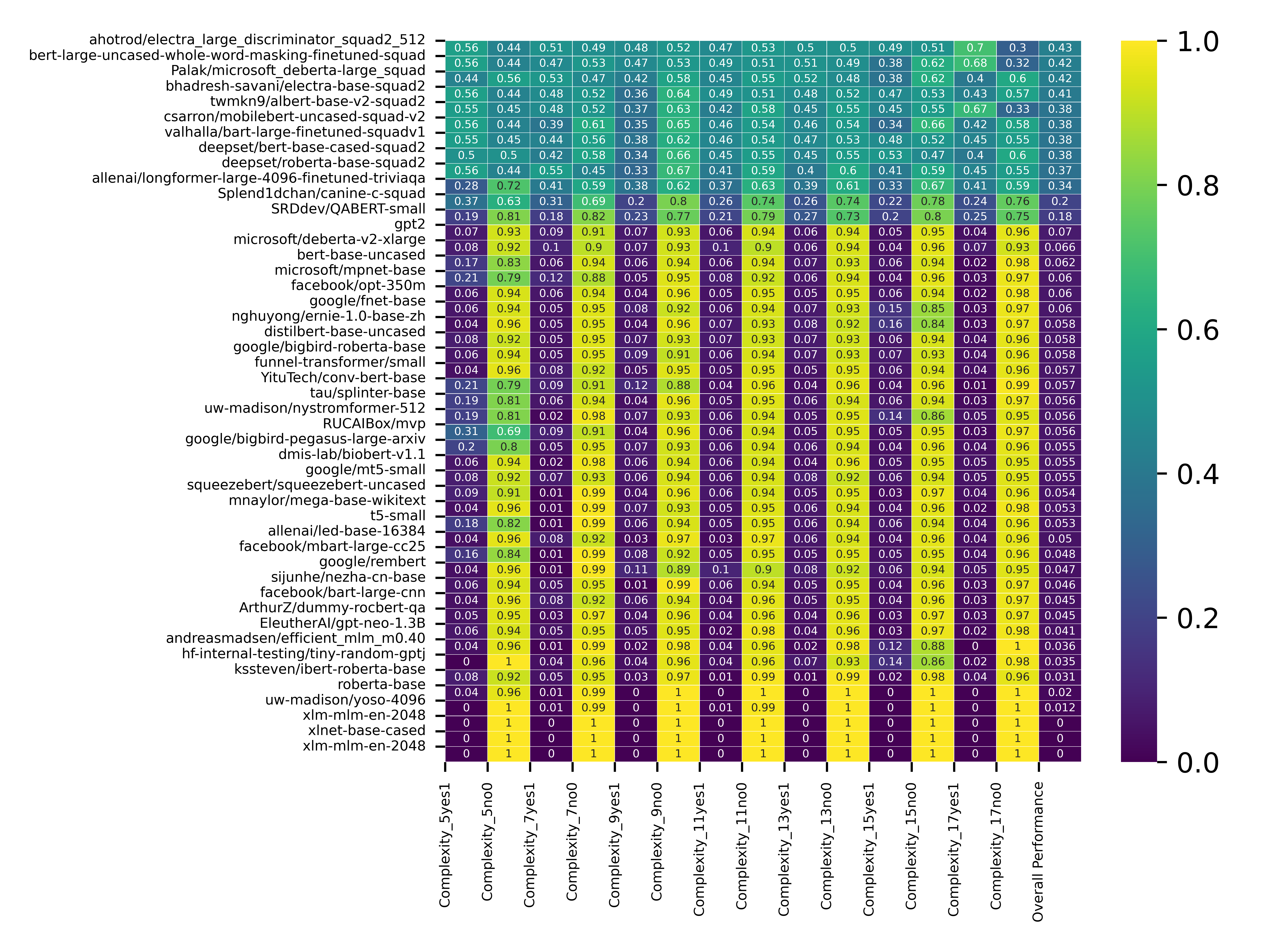
Title: Comparative Analysis of 47 Context-Based Question Answer Models Across 8 Diverse Datasets
ArXiv ID: 2512.00323
Date: 2025-11-29
Authors: Muhammad Muneeb, David B. Ascher, Ahsan Baidar Bakht
📝 Abstract
Context-based question answering (CBQA) models provide more accurate and relevant answers by considering the contextual information. They effectively extract specific information given a context, making them functional in various applications involving user support, information retrieval, and educational platforms. In this manuscript, we benchmarked the performance of 47 CBQA models from Hugging Face on eight different datasets. This study aims to identify the best-performing model across diverse datasets without additional fine-tuning. It is valuable for practical applications where the need to retrain models for specific datasets is minimized, streamlining the implementation of these models in various contexts. The best-performing models were trained on the SQuAD v2 or SQuAD v1 datasets. The best-performing model was ahotrod/electra_large_discriminator_squad2_512, which yielded 43\% accuracy across all datasets. We observed that the computation time of all models depends on the context length and the model size. The model's performance usually decreases with an increase in the answer length. Moreover, the model's performance depends on the context complexity. We also used the Genetic algorithm to improve the overall accuracy by integrating responses from other models. ahotrod/electra_large_discriminator_squad2_512 generated the best results for bioasq10b-factoid (65.92\%), biomedical\_cpgQA (96.45\%), QuAC (11.13\%), and Question Answer Dataset (41.6\%). Bert-large-uncased-whole-word-masking-finetuned-squad achieved an accuracy of 82\% on the IELTS dataset.
💡 Deep Analysis
📄 Full Content
Comparative Analysis of 47 Context-Based Question
Answer Models Across 8 Diverse Datasets
Muhammad Muneeb1,2, David B. Ascher1,2,*, and Ahsan Baidar Bakht3
1School of Chemistry and Molecular Biology, The University of Queensland, Brisbane, 4067, Australia
2Computational Biology and Clinical Informatics, Baker Heart and Diabetes Institute, Melbourne, 3004, Australia
3Mechanical Engineering Department, Khalifa University, Abu Dhabi, UAE
*d.ascher@uq.edu.au
ABSTRACT
Context-based question answering (CBQA) models provide more accurate and relevant answers by considering the con-
textual information. They effectively extract specific information given a context, making them functional in various appli-
cations involving user support, information retrieval, and educational platforms. In this manuscript, we benchmarked the
performance of 47 CBQA models from Hugging Face on eight different datasets. This study aims to identify the best-
performing model across diverse datasets without additional fine-tuning. It is valuable for practical applications where
the need to retrain models for specific datasets is minimized, streamlining the implementation of these models in vari-
ous contexts. The best-performing models were trained on the SQuAD v2 or SQuAD v1 datasets. The best-performing
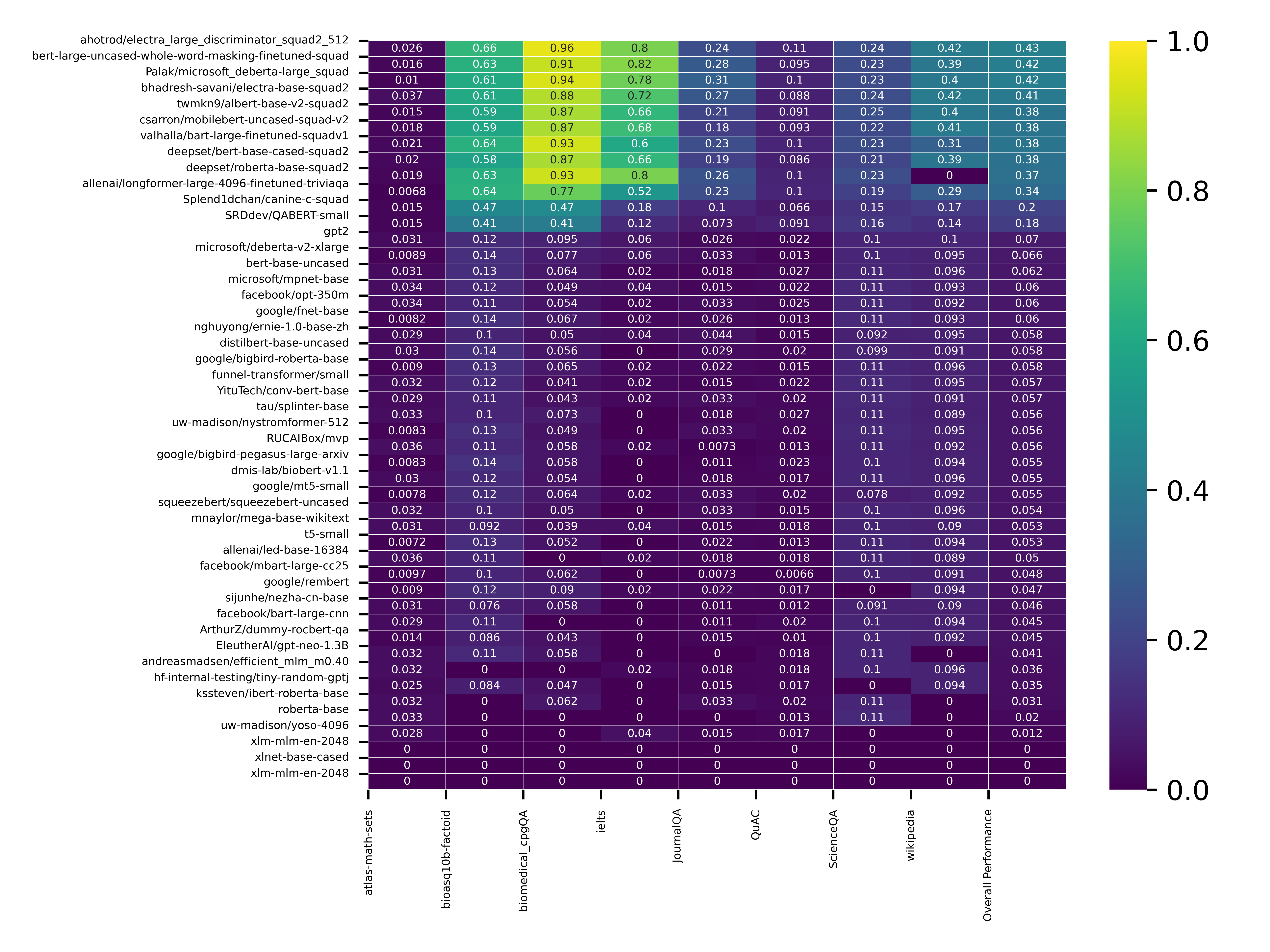
model was ahotrod/electra_large_discriminator_squad2_512, which yielded 43% accuracy across all datasets. We observed
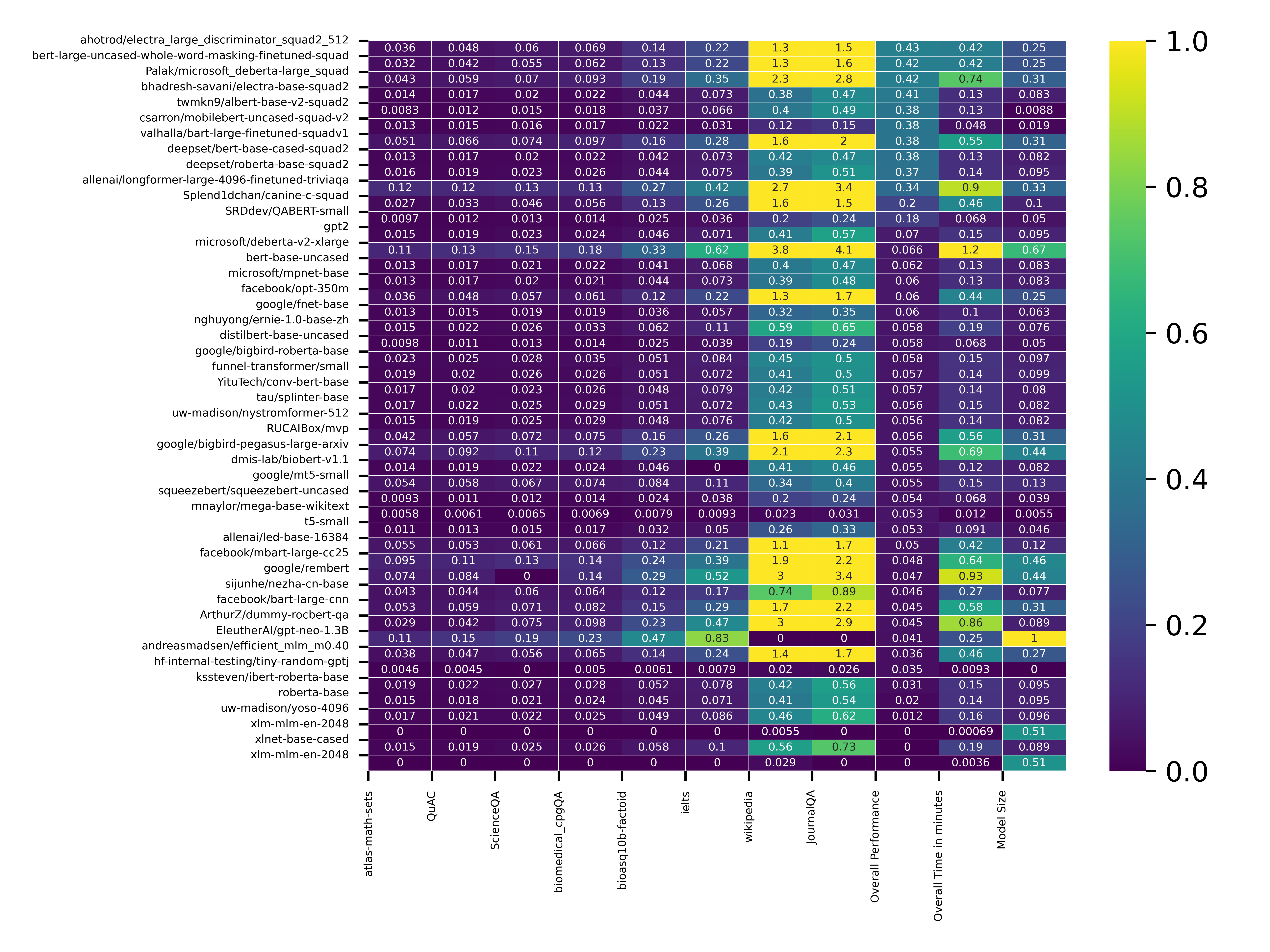
that the computation time of all models depends on the context length and the model size. The model’s performance
usually decreases with an increase in the answer length. Moreover, the model’s performance depends on the context com-
plexity. We also used the Genetic algorithm to improve the overall accuracy by integrating responses from other models.
ahotrod/electra_large_discriminator_squad2_512 generated the best results for bioasq10b-factoid (65.92%), biomedical_cpgQA
(96.45%), QuAC (11.13%), and Question Answer Dataset (41.6%). Bert-large-uncased-whole-word-masking-finetuned-squad
achieved an accuracy of 82% on the IELTS dataset. Palak/microsoft_deberta-large_squad accuracy was 31% on the JournalQA
dataset. Twmkn9/albert-base-v2-squad2 was the best-performing model for the ScienceQA dataset with an accuracy of 24.6%.
This study contributes to the broader goal of optimizing the use of CBQA models across diverse datasets by providing insights
into the impact of context complexity, answer length, and question types on model performance.
Introduction
In the era of information abundance, the need for efficient extraction and retrieval of relevant information from vast textual
repositories has become paramount1,2. Question-answering (QA) models are pivotal in facilitating human-machine interaction
by interpreting complex linguistic structures, discerning contextual nuances, and generating accurate responses3. QA tasks
are categorized into three classes: Answer generation, where the answer is generated based on the question; answer selection,
where models choose answers from multiple options; and answer extraction, where models extract answers from the context4.
We considered models that use a question and context to extract an answer.
A context-based question answering (CBQA) model is a type of natural language processing (NLP) model designed
to understand and respond to questions in the context of a given passage or document5–9. The exigency for QA models is
underscored by their applications across diverse domains, including information retrieval10, customer support, education11,
and medical literature12–14, QA models also aid in extracting information from research articles, enhancing the efficiency of
literature reviews and evidence-based decision-making15.
CBQA models initiate their process with tokenization16 that combines the question with the context, and the data is then
segmented into smaller units known as tokens. These tokens are represented as vectors in a high-dimensional space through
embedding, encompassing token, position, and segment embedding (capturing the semantic meaning and relationships between
words)17. The embeddings are passed to the transformer, which uses a self-attention mechanism18 to capture dependencies
between words, irrespective of their position in the sequence. Subsequently, QA models undergo pre-training on extensive
datasets with a specific objective19. For instance, in the Masked Language Model (MLM) objective20, a portion of tokens is
masked (replaced with a unique token called MASK), and the model predicts the correct token in place of MASK to acquire
contextualized language representations21. This pretraining phase aids the model in developing a broad understanding of
language. Following pretraining22, the model undergoes fine-tuning23 on a task-specific dataset for QA. The question-answering
head is added at this stage for fine-tuning the QA datasets, which predicts the answer’s start and end token.
arXiv:2512.00323v1 [cs.CL] 29 Nov 2025
The evaluation of CBQA models typically i