Title: ART: Adaptive Response Tuning Framework – A Multi-Agent Tournament-Based Approach to LLM Response Optimization
ArXiv ID: 2512.00617
Date: 2025-11-29
Authors: Omer Jauhar Khan
📝 Abstract
Large Language Models (LLMs) have demonstrated remarkable capabilities in natural language understanding and generation. However, single-model responses often exhibit inconsistencies, hallucinations, and varying quality across different query domains. This paper presents ART (Adaptive Response Tuning), a novel framework that employs tournament-style ELO ranking and multi-agent reasoning to systematically optimize LLM outputs. By enabling multiple LLM agents to compete, critique, and collaborate through structured tournament workflows, ART produces consensus responses that outperform individual model outputs. Our framework introduces configurable tournament parameters, dynamic agent selection, and multiple consensus fusion strategies. Experimental evaluations demonstrate significant improvements in response accuracy, coherence, and reliability compared to baseline single-model approaches. The ART framework provides a scalable, production-ready solution for applications requiring high-quality, vetted LLM responses, achieving an 8.4% improvement in overall quality metrics and R^2 values exceeding 0.96 in ELO rating convergence.
💡 Deep Analysis
📄 Full Content
ART: Adaptive Response Tuning Framework
A Multi-Agent Tournament-Based Approach to LLM Response Optimization
Omer Jauhar Khan
Department of Computer Science
National University of Computer and Emerging Sciences (FAST-NUCES)
Peshawar, 25000, Pakistan
Email: p218055@pwr.nu. edu.pk
Abstract—Large Language Models (LLMs) have demonstrated
remarkable capabilities in natural language understanding and
generation. However, single-model responses often exhibit incon-
sistencies, hallucinations, and varying quality across different
query domains. This paper presents ART (Adaptive Response
Tuning), a novel framework that employs tournament-style ELO
ranking and multi-agent reasoning to systematically optimize
LLM outputs. By enabling multiple LLM agents to compete, cri-
tique, and collaborate through structured tournament workflows,
ART produces consensus responses that outperform individual
model outputs. Our framework introduces configurable tourna-
ment parameters, dynamic agent selection, and multiple con-
sensus fusion strategies. Experimental evaluations demonstrate
significant improvements in response accuracy, coherence, and
reliability compared to baseline single-model approaches. The
ART framework provides a scalable, production-ready solution
for applications requiring high-quality, vetted LLM responses,
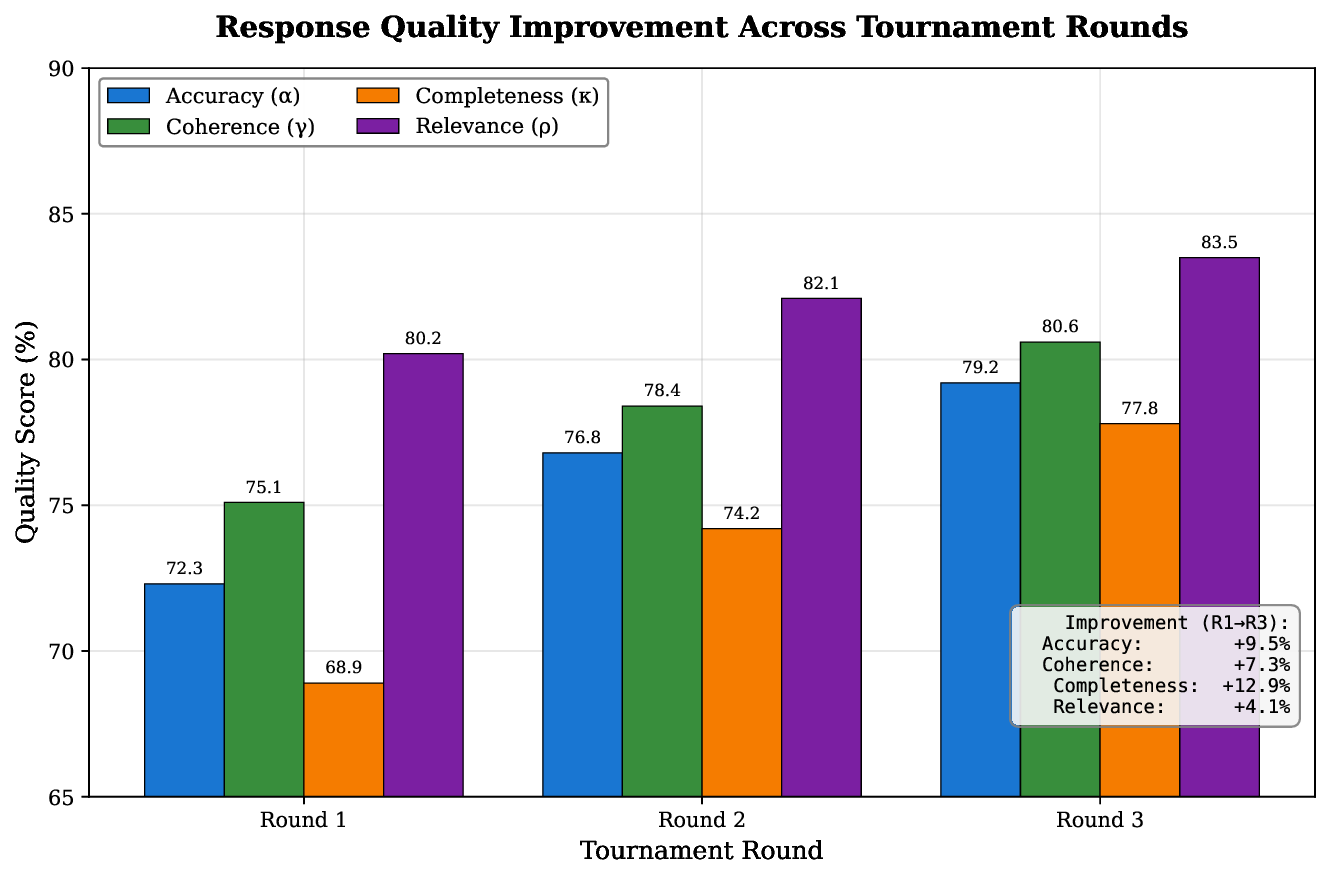
achieving an 8.4% improvement in overall quality metrics and
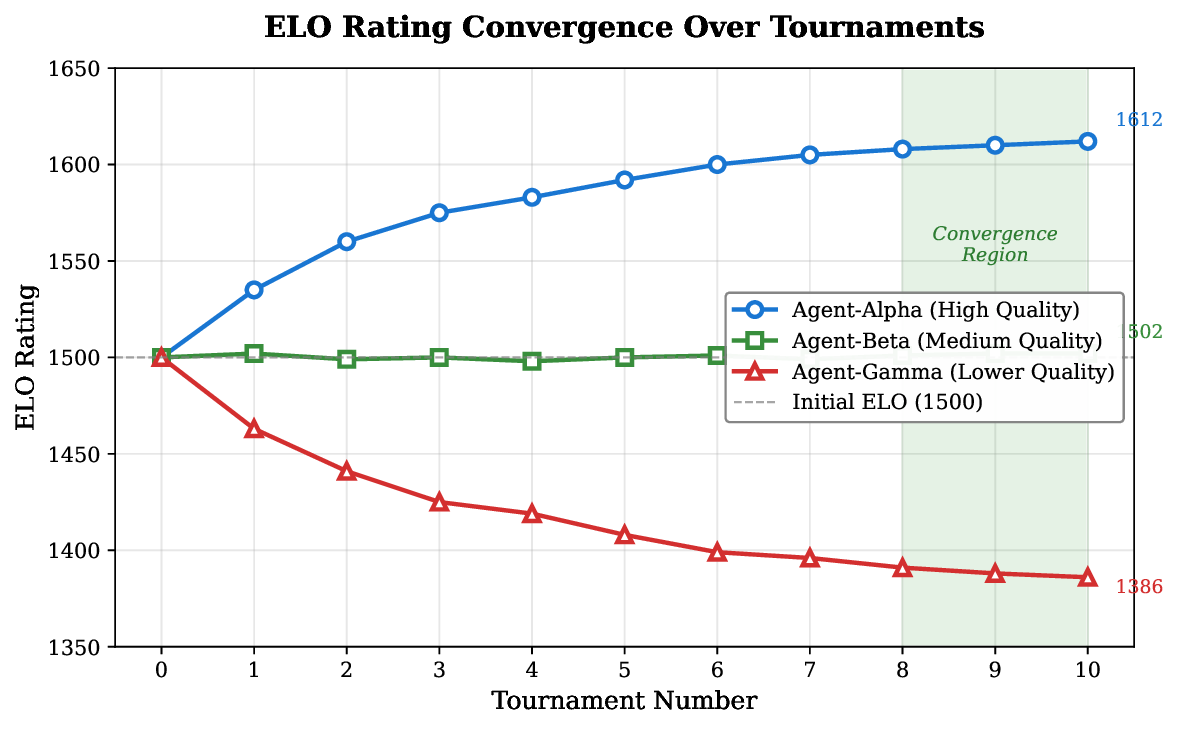
R² values exceeding 0.96 in ELO rating convergence.
Index Terms—Large Language Models, Multi-Agent Systems,
ELO Rating, Tournament Selection, Consensus Generation, Re-
sponse Optimization, Natural Language Processing, LLM Eval-
uation
I. INTRODUCTION
A. Background and Motivation
The proliferation of Large Language Models (LLMs) has
revolutionized natural language processing, enabling sophisti-
cated applications ranging from conversational agents to code
generation and scientific analysis. Models such as GPT-4,
Claude, LLaMA, and PaLM demonstrate impressive capabil-
ities in understanding context, generating coherent text, and
reasoning about complex topics [1], [2].
However, despite these advances, individual LLM responses
suffer from several well-documented limitations:
1) Hallucinations: LLMs may generate plausible-sounding
but factually incorrect information [3]
2) Inconsistency: Repeated queries may yield different
responses of varying quality [4]
3) Bias: Individual models may exhibit systematic biases
from their training data [5]
4) Domain Limitations: Models may excel in certain
domains while underperforming in others [6]
5) Confidence Calibration: LLMs often struggle to accu-
rately assess their own uncertainty [7]
These limitations pose significant challenges for appli-
cations requiring reliable, accurate, and consistent outputs.
Medical diagnosis assistance, legal document analysis, edu-
cational content generation, and financial decision support are
examples where response quality is critical.
B. Problem Statement
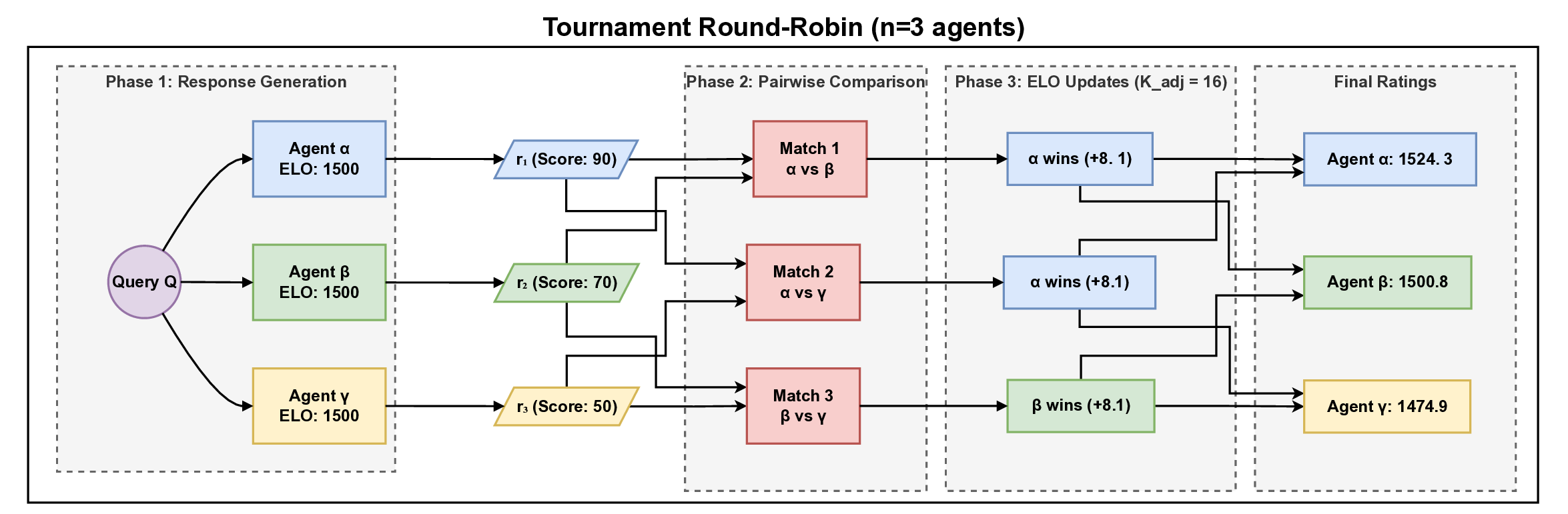
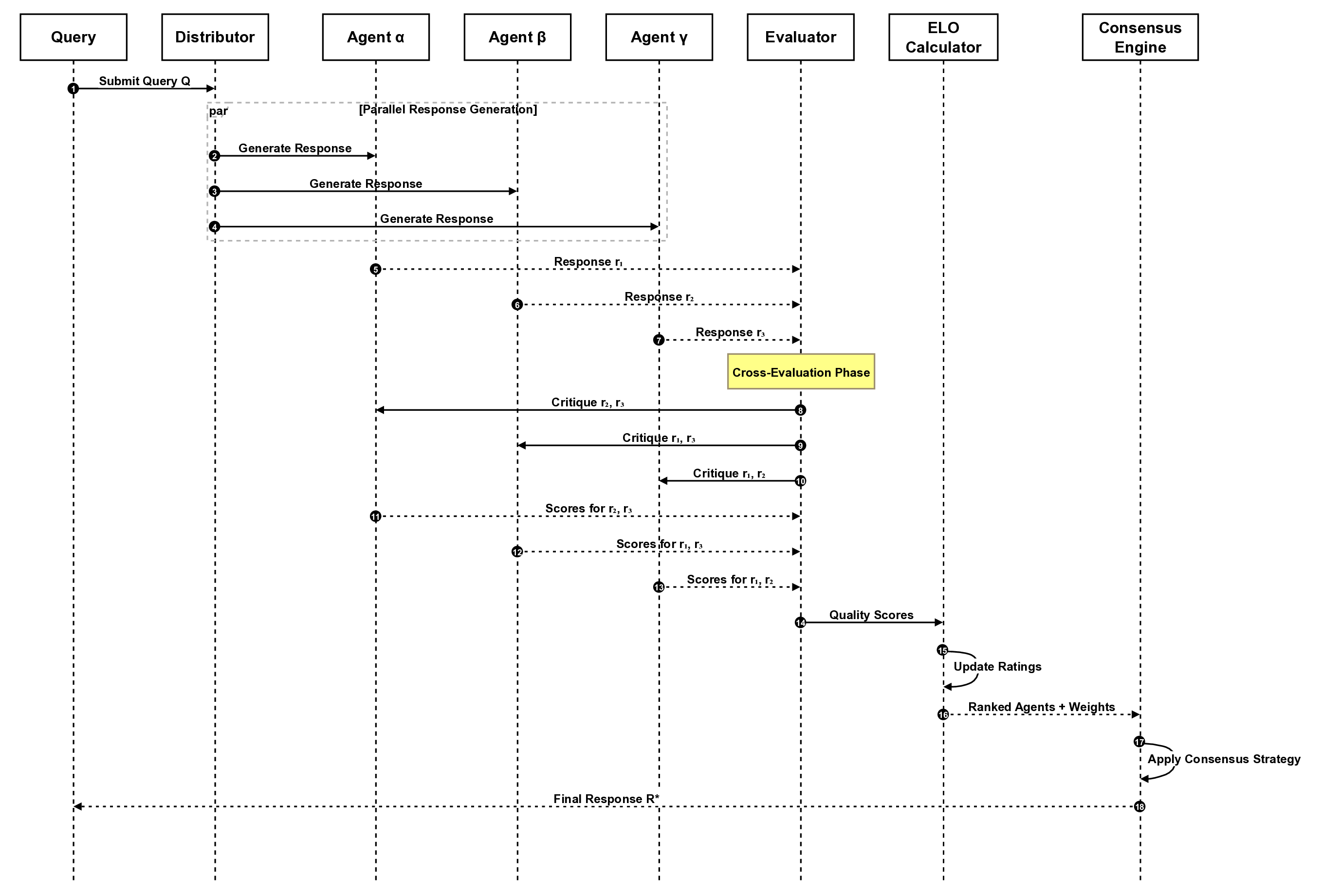
Given a query Q and a set of n LLM agents A =
{a1, a2, ..., an}, each capable of generating a response ri =
ai(Q), the problem is to:
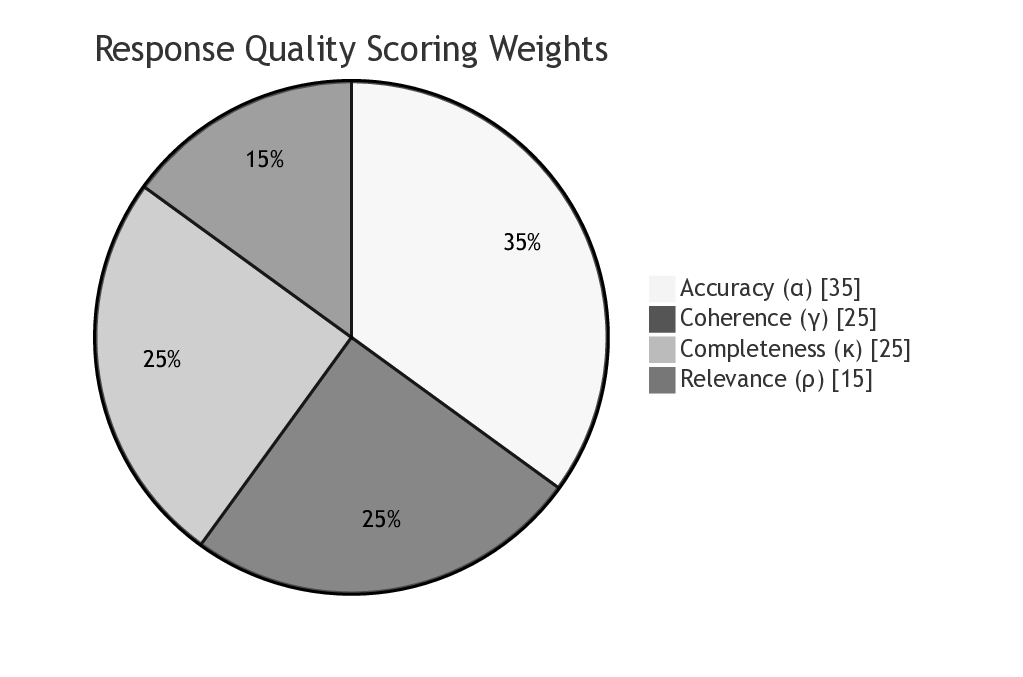
1) Evaluate the quality of each response ri across multiple
criteria
2) Rank agents based on their response quality using a
principled scoring system
3) Select or synthesize an optimal response R∗that max-
imizes overall quality
4) Adapt agent rankings over time to reflect cumulative
performance
C. Contributions
This paper makes the following contributions:
1) ART
Framework
Architecture: A comprehensive
multi-agent framework for LLM response optimization
featuring modular components for agent management,
tournament orchestration, and consensus generation.
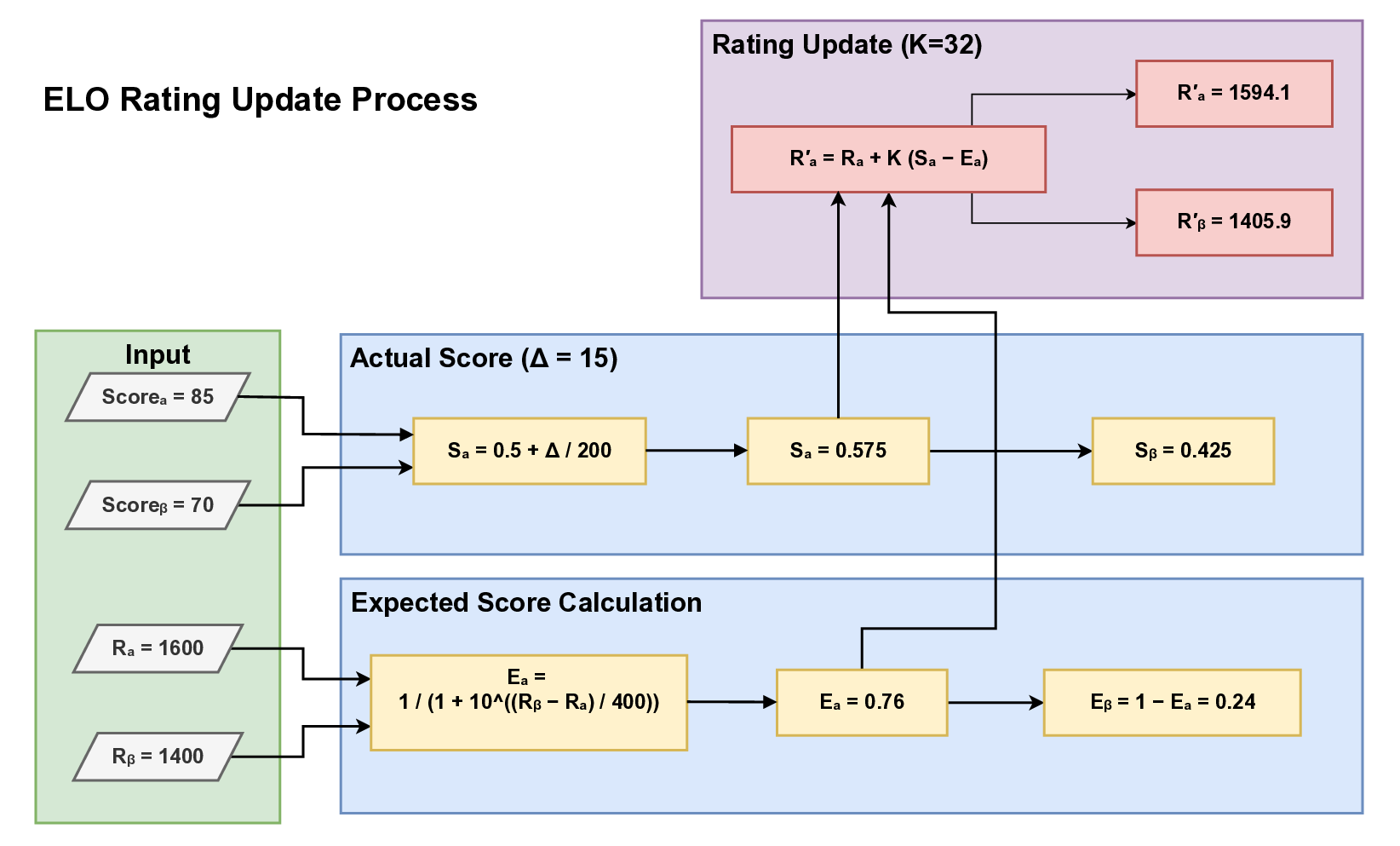
2) Tournament-Based ELO Ranking: Application of the
ELO rating system to LLM agent evaluation, with exten-
sions for multi-agent matches, partial wins, and dynamic
K-factor adjustment.
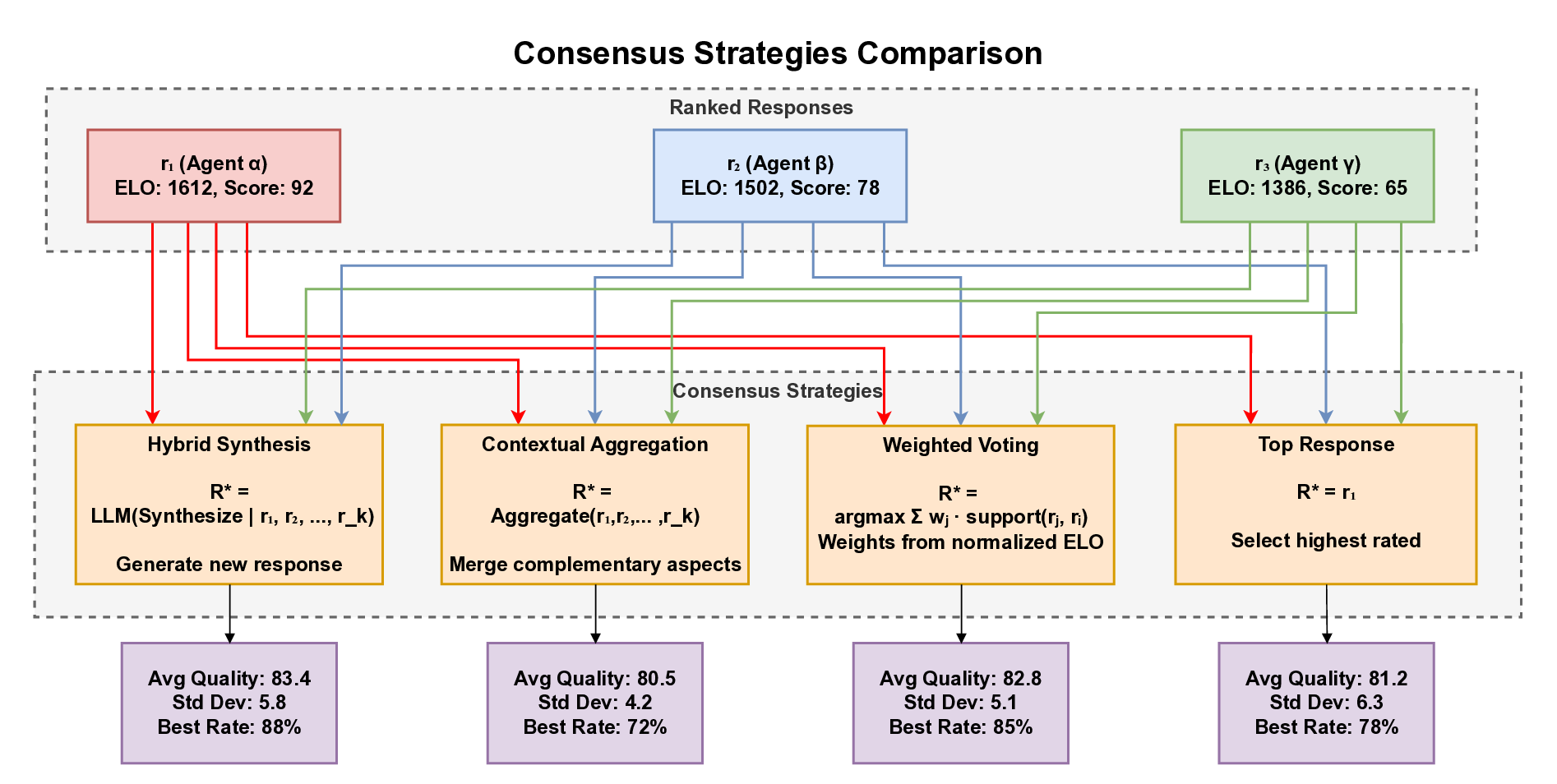
3) Multi-Strategy Consensus Engine: Multiple fusion
strategies for synthesizing optimal responses from agent
outputs, including weighted voting, contextual aggrega-
tion, and hybrid synthesis.
4) Empirical
Evaluation: Comprehensive experiments
demonstrating the effectiveness of tournament-based op-
timization across diverse query types and model config-
urations.
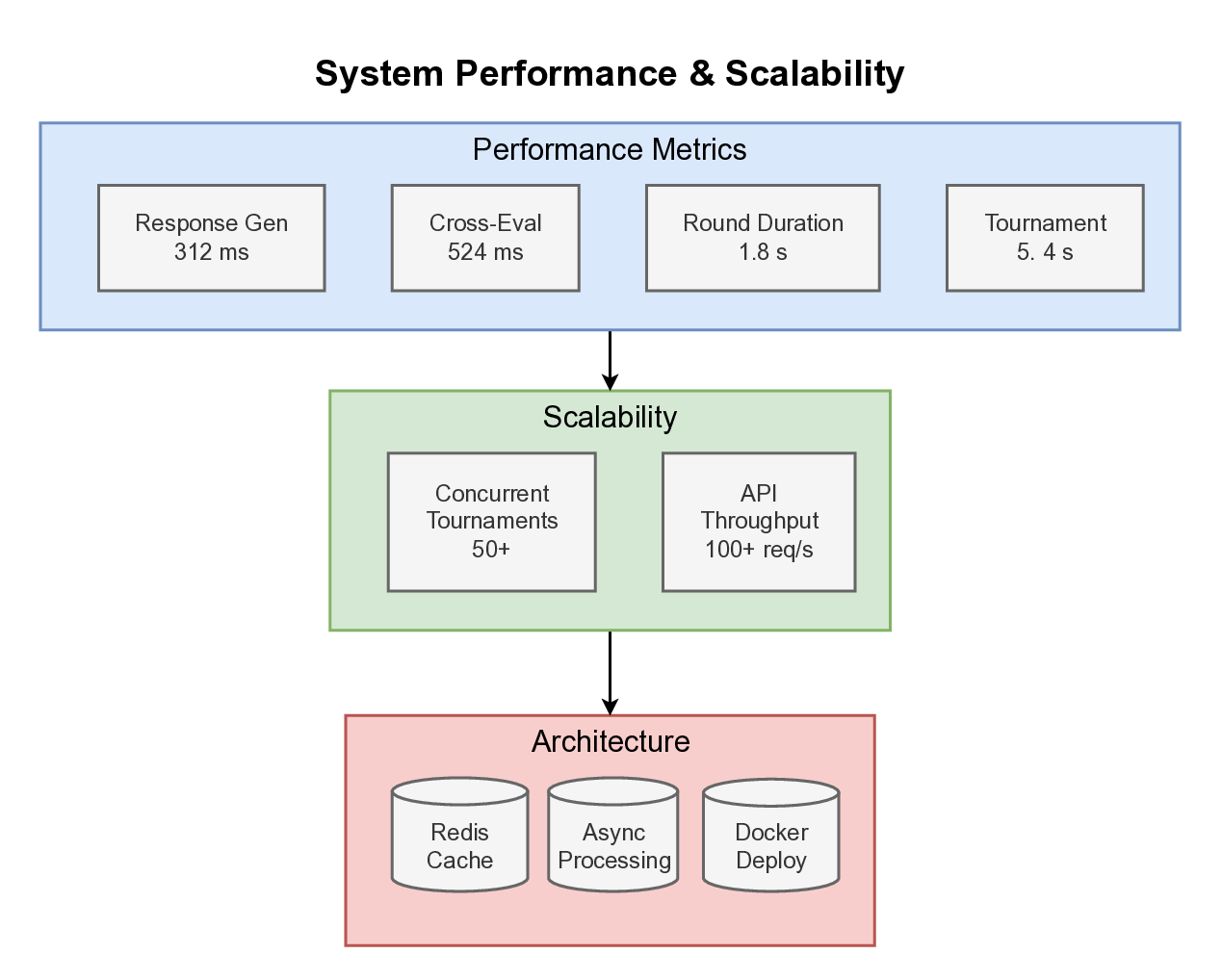
5) Production-Ready Implementation: A complete, doc-
umented implementation with RESTful API, Docker
deployment, and extensive test coverage.
D. Paper Organization
The remainder of this paper is organized as follows: Sec-
tion II reviews related work in multi-agent LLM systems
and response optimization. Section III presents the theoretical
foundations of the ART framework. Section IV details the
arXiv:2512.00617v2 [cs.CL] 24 Dec 2025
system architecture and implementation. Section V describes
the experimental methodology and presents results. Section VI
discusses implications and limitations. Section VII concludes
with future research directions.
II. RELATED WORK
A. Multi-Agent LLM Systems
The use of multiple LLM agents for improved task perfor-
mance has gained significant attention. Debate framewor