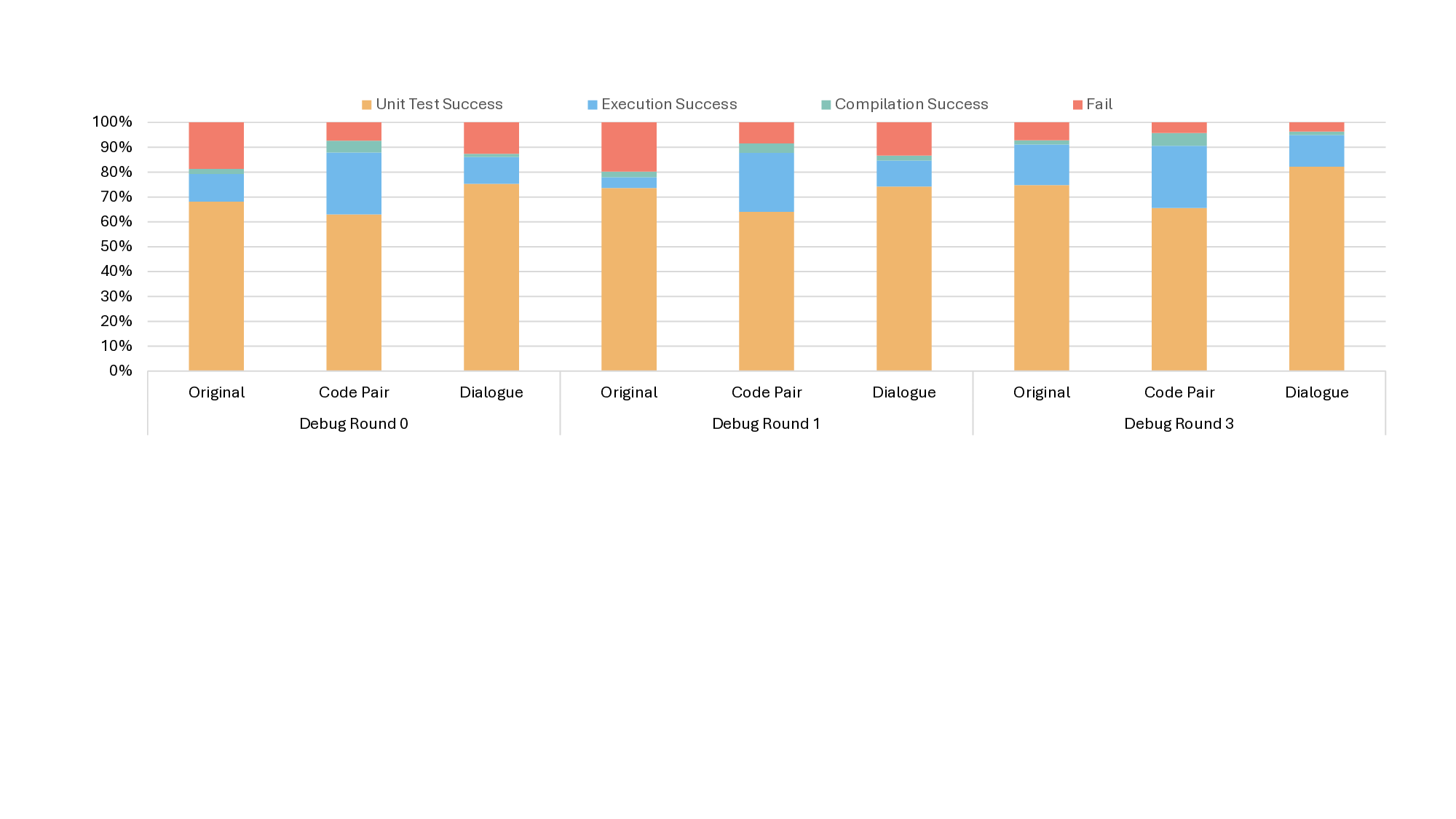Title: Beyond Code Pairs: Dialogue-Based Data Generation for LLM Code Translation
ArXiv ID: 2512.03086
Date: 2025-11-29
Authors: ** Le Chen¹* , Nuo Xu²* , Winson Chen³ , Bin Lei² , Pei‑Hung Lin⁴ , Dunzhi Zhou² , Rajeev Thakur¹ , Caiwen Ding² , Ali Jannesari³ , Chunhua Liao⁴ ¹ Argonne National Laboratory, Lemont, USA ² University of Minnesota, Minneapolis, USA ³ Iowa State University, Ames, USA ⁴ Lawrence Livermore National Laboratory, Livermore, USA **
📝 Abstract
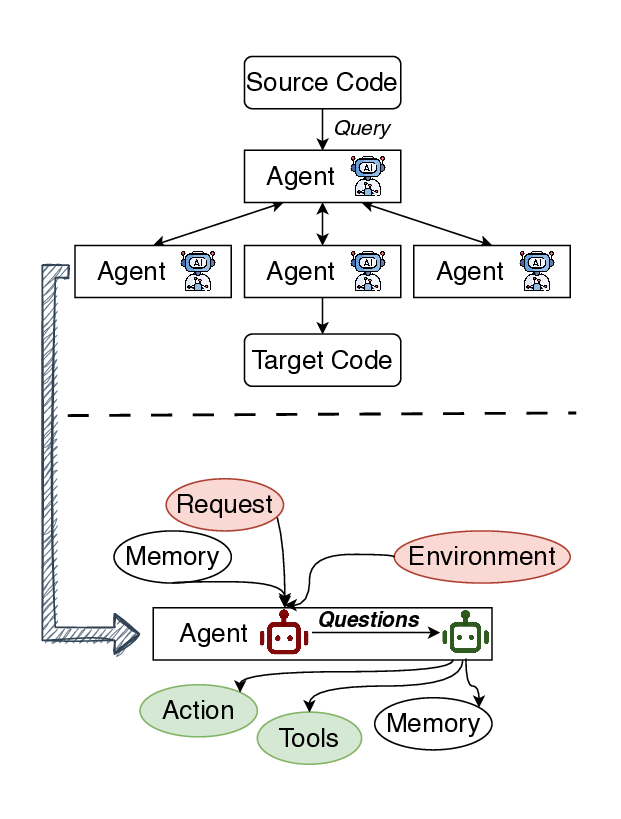
Large language models (LLMs) have shown remarkable capabilities in code translation, yet their performance deteriorates in low-resource programming domains such as Fortran and emerging frameworks like CUDA, where high-quality parallel data are scarce. We present an automated dataset generation pipeline featuring a dual-LLM Questioner-Solver design that incorporates external knowledge from compilers and runtime feedback. Beyond traditional source-target code pair datasets, our approach additionally generates (1) verified translations with unit tests for assessing functional consistency, and (2) multi-turn dialogues that capture the reasoning process behind translation refinement. Applied to Fortran -> C++ and C++ -> CUDA, the pipeline yields 3.64k and 3.93k dialogues, respectively. Fine-tuning on this data yields dramatic improvements in functional correctness, boosting unit test success rates by over 56% on the challenging C++-to-CUDA task. We show this data enables a 7B open-weight model to significantly outperform larger proprietary systems on key metrics like compilation success.
💡 Deep Analysis
📄 Full Content
Beyond Code Pairs: Dialogue-Based Data Generation for LLM Code
Translation
Le Chen1* Nuo Xu2* Winson Chen3 Bin Lei2 Pei-Hung Lin4
Dunzhi Zhou2 Rajeev Thakur1 Caiwen Ding2 Ali Jannesari3 Chunhua Liao4
1Argonne National Laboratory, Lemont, USA
2University of Minnesota, Minneapolis, USA
3Iowa State University, Ames, USA
4Lawrence Livermore National Laboratory, Livermore, USA
lechen@anl.gov, liao6@llnl.gov
Abstract
Large language models (LLMs) have shown
remarkable capabilities in code translation, yet
their performance deteriorates in low-resource
programming domains such as Fortran and
emerging frameworks like CUDA, where high-
quality parallel data are scarce. We present
an automated dataset generation pipeline fea-
turing a dual-LLM Questioner–Solver design
that incorporates external knowledge from com-
pilers and runtime feedback. Beyond tradi-
tional source–target code pair datasets, our ap-
proach additionally generates (1) verified trans-
lations with unit tests for assessing functional
consistency, and (2) multi-turn dialogues that
capture the reasoning process behind transla-
tion refinement. Applied to Fortran→C++ and
C++→CUDA, the pipeline yields 3.64k and
3.93k dialogues, respectively. Fine-tuning on
this data yields dramatic improvements in func-
tional correctness, boosting unit test success
rates by over 56% on the challenging C++-to-
CUDA task. We show this data enables a 7B
open-weight model to significantly outperform
larger proprietary systems on key metrics like
compilation success.
1
Introduction
Automated code translation has long been a goal
in programming languages and systems research,
enabling developers to migrate software across lan-
guages, frameworks, and hardware platforms (Ah-
mad et al., 2021; Feng et al., 2020; Lachaux et al.,
2020). In high-performance computing (HPC) and
scientific computing, this problem is particularly
pressing since legacy codes need to interoperate
with modern ecosystems while new frameworks
such as CUDA and OpenMP continue to emerge to
exploit specialized hardware (Czarnul et al., 2020;
Dhruv and Dubey, 2025). Large language mod-
els (LLMs) have recently demonstrated impressive
capabilities in code understanding and generation,
*Equal contribution.
motivating their application to code translation. Yet
their effectiveness is uneven, with good results in
popular languages such as Python and Java, but
substantially weaker performance in low-resource
domains and specialized frameworks where train-
ing data is scarce and structural complexity is high.
For example, LLMs often produce translations that
compile but fail unit tests or generate code that is
syntactically invalid without guidance from exter-
nal tools (Chen et al., 2024).
Agent-based approaches have been widely
adopted to address the limitations of LLMs in code
translation. Most existing systems follow a source-
to-target workflow (Dearing et al., 2024; Bitan
et al., 2025; Chen et al., 2025), where multiple
agents iteratively perform translation, verification,
and refinement until a syntactically valid target
program is produced (Figure 1, up). The result-
ing outputs are typically source–target code pairs,
which are well suited for traditional supervised
learning pipelines (Chen et al., 2021). Although
these approaches can produce correct translations,
they discard valuable intermediate information that
could further enhance the performance of LLMs.
These information, such as compiler feedback, run-
time diagnostics, and interactions with external
tools or scripts, has been shown to be crucial for en-
abling deeper reasoning about program semantics
and functional behavior (Ding et al., 2024).
To address this gap, we introduce a dual-LLM
Questioner–Solver design within each LLM agent,
which automatically collects and generates reason-
ing process data during the agent-based translation
workflow (Figure 1, bottom). Instead of producing
only final code pairs, our framework automatically
generates question-solution data covering interme-
diate queries, responses, and tool interactions that
occur during translation. The Questioner analyzes
the current state, formulates targeted questions,
and incorporates external signals such as compiler
errors or runtime outputs, while the Solver exe-
1
arXiv:2512.03086v1 [cs.PL] 29 Nov 2025
Source Code
Target Code
Query
Agent
Agent
Agent
Agent
Agent
Memory
Environment
Request
Memory
Action
Tools
Questions
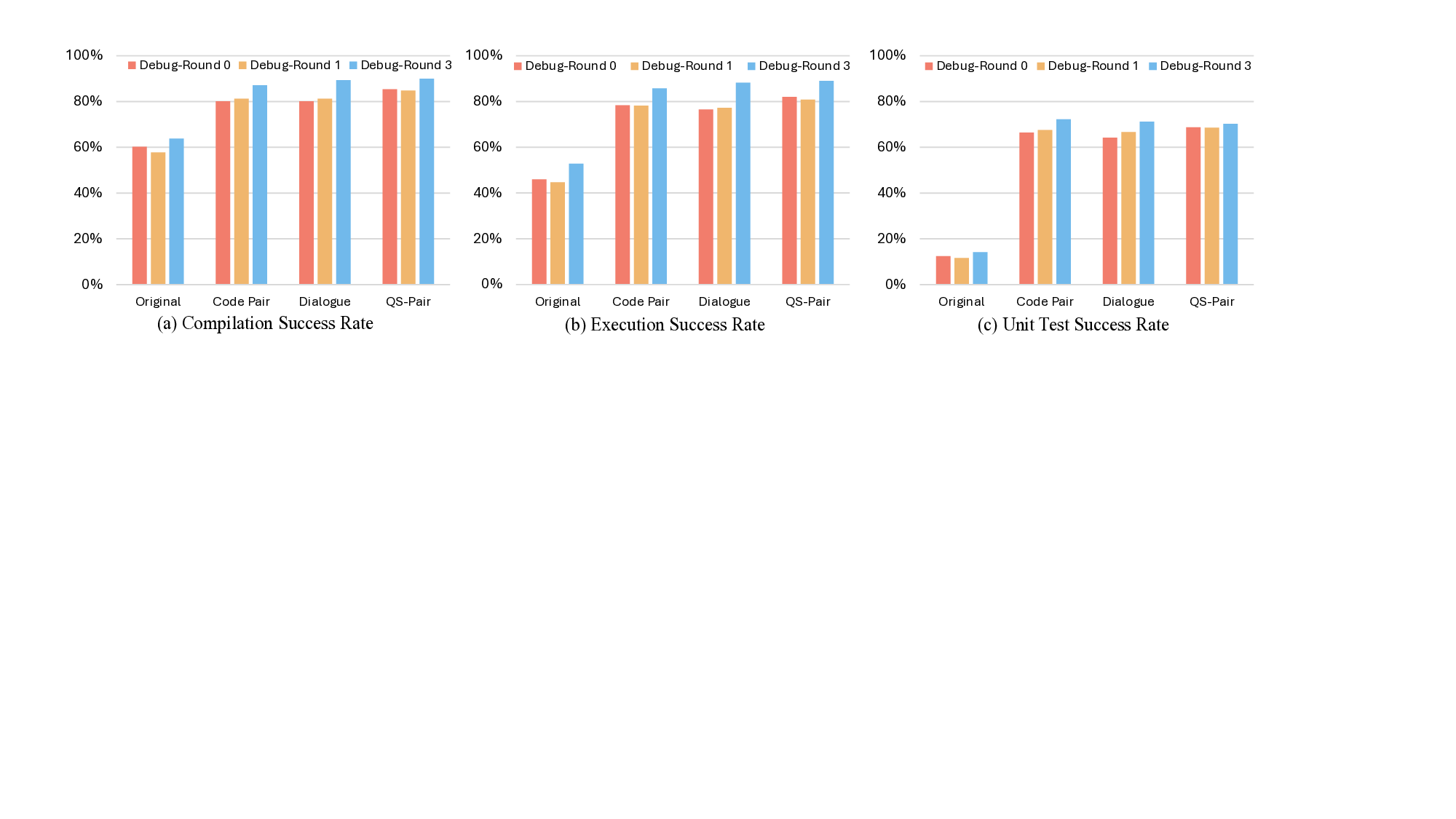
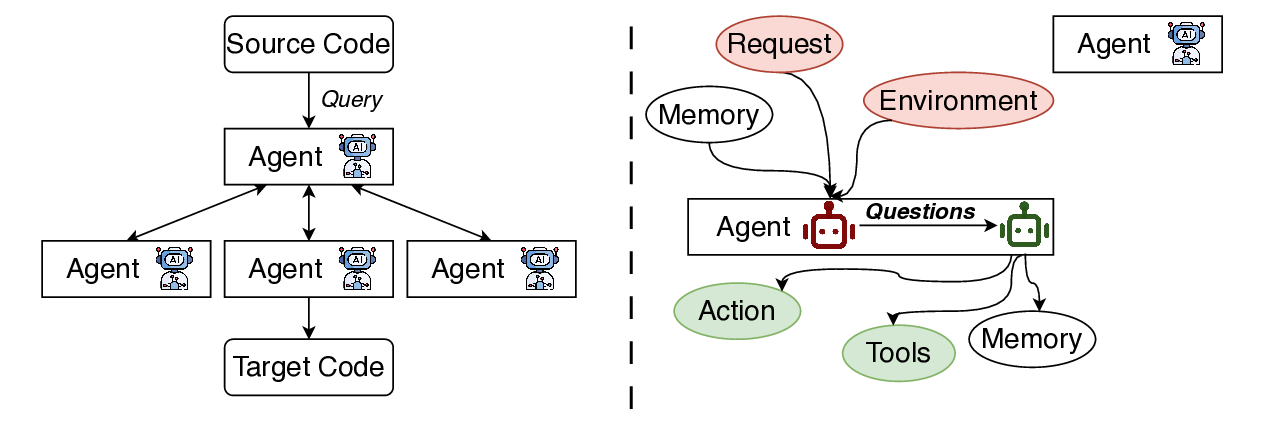
Figure 1:
High-level architecture of the Ques-
tioner–Solver module in our design to replace the sin-
gle LLM core in regular LLM agent frameworks. The
Questioner analyzes state and formulates queries using
dialogue memory and external tools (e.g., compilers,
runtime environments, scripts), while the Solver gen-
erates translations, unit tests, and repairs. Their itera-
tive interaction enables reasoning separation, external
knowledge integration, and progressive refinement of
translations.
cutes translations