Title: Learning to Prioritize IT Tickets: A Comparative Evaluation of Embedding-based Approaches and Fine-Tuned Transformer Models
ArXiv ID: 2512.17916
Date: 2025-11-28
Authors: Minh Tri LÊ, Ali Ait-Bachir
📝 Abstract
Prioritizing service tickets in IT Service Management (ITSM) is critical for operational efficiency but remains challenging due to noisy textual inputs, subjective writing styles, and pronounced class imbalance. We evaluate two families of approaches for ticket prioritization: embedding-based pipelines that combine dimensionality reduction, clustering, and classical classifiers, and a fine-tuned multilingual transformer that processes both textual and numerical features. Embedding-based methods exhibit limited generalization across a wide range of thirty configurations, with clustering failing to uncover meaningful structures and supervised models highly sensitive to embedding quality. In contrast, the proposed transformer model achieves substantially higher performance, with an average F1-score of 78.5% and weighted Cohen's kappa values of nearly 0.80, indicating strong alignment with true labels. These results highlight the limitations of generic embeddings for ITSM data and demonstrate the effectiveness of domain-adapted transformer architectures for operational ticket prioritization.
💡 Deep Analysis
📄 Full Content
LEARNING TO PRIORITIZE IT TICKETS: A COMPARATIVE
EVALUATION OF EMBEDDING-BASED APPROACHES AND
FINE-TUNED TRANSFORMER MODELS
Minh Tri LÊ
Global AI Lab
EasyVista
mle@easyvista.com
Ali AIT BACHIR
Global AI Lab
EasyVista
aaitbachir@easyvista.com
December 23, 2025
ABSTRACT
Prioritizing service tickets in IT Service Management (ITSM) is critical for operational efficiency
but remains challenging due to noisy textual inputs, subjective writing styles, and pronounced class
imbalance. We evaluate two families of approaches for ticket prioritization: embedding-based
pipelines that combine dimensionality reduction, clustering, and classical classifiers, and a fine-
tuned multilingual transformer that processes both textual and numerical features. Embedding-based
methods exhibit limited generalization across a wide range of thirty configurations, with clustering
failing to uncover meaningful structures and supervised models highly sensitive to embedding quality.
In contrast, the proposed transformer model achieves substantially higher performance, with an
average F1-score of 78.5% and weighted Cohen’s kappa values of nearly 0.80, indicating strong
alignment with true labels. These results highlight the limitations of generic embeddings for ITSM
data and demonstrate the effectiveness of domain-adapted transformer architectures for operational
ticket prioritization.
Keywords Text Classification · Transformer · Embedding · Prioritization · AIOps
1
Introduction
In today’s digital enterprises, IT Service Management (ITSM) platforms generate a continuously growing volume
of user-submitted support tickets. These tickets are often expressed in natural language, unstructured, and written
in a variety of styles, languages, and technical registers. Managing such heterogeneous data manually is not only
labor-intensive but also introduces human bias, delays, and inefficiencies that impact both service quality and user
satisfaction. Prioritization, deciding which issues to address first, is a critical aspect of IT support, especially in
large-scale environments where operational decisions must balance urgency and business impact in real time.
Recent advances in Natural Language Processing (NLP) offer promising avenues for automating both the categorization
[Mohanna and Ait-Bachir, 2025] and prioritization of IT tickets. However, as several studies have shown, off-the-shelf
machine learning approaches struggle to adapt to the IT ticket domain. Traditional models, such as those based on
TF-IDF or Word2Vec, are limited in their ability to understand sentence-level semantics and contextual relationships,
particularly in noisy, domain-specific, and multilingual datasets ( Do et al. [2021]; Fuchs et al. [2022]; da Costa et al.
[2023]). Moreover, classical machine learning methods lack the ability to jointly process text with numerical features,
such as impact or urgency scores, which are essential for effective prioritization.
While pre-trained language models like BERT and XLNet have demonstrated improved performance on general NLP
tasks, their application in ITSM scenarios remains challenging. As noted by Zangari et al. [2023], even advanced
deep learning techniques yield F1-scores barely exceeding 50% when applied to IT ticket data. It is largely due to
the specialized jargon, ambiguous labels, and inconsistent structure found in real world support logs. Furthermore,
Cohen’s Kappa, a common metric used to assess classification reliability ( Cohen [1968]; DATAtab Team [2024]), tends
arXiv:2512.17916v1 [cs.CL] 28 Nov 2025
Prioritizing IT Tickets: Embedding Clustering and Fine-Tuned Transformer Models
to be sensitive to class imbalances, which is particularly problematic for prioritization tasks where low-frequency but
high-criticality tickets are underrepresented.
To address these challenges, we launched a research and development initiative with two complementary objectives:
(1) to develop a robust automatic categorization system capable of suggesting relevant IT ticket categories based on
free-text input, and (2) to design a prioritization engine that predicts operational impact and urgency to rank tickets by
criticality. This second objective, prioritization, is the focus of our paper.
The prioritization task requires sophisticated modeling techniques that can integrate semantic understanding of ticket
descriptions with structured indicators of business risk. This includes handling noisy, multilingual input; combining
textual and numerical data; and addressing unbalanced class distributions. Moreover, the system must operate under
real-time constraints and scale across a wide range of ticket types and service domains.
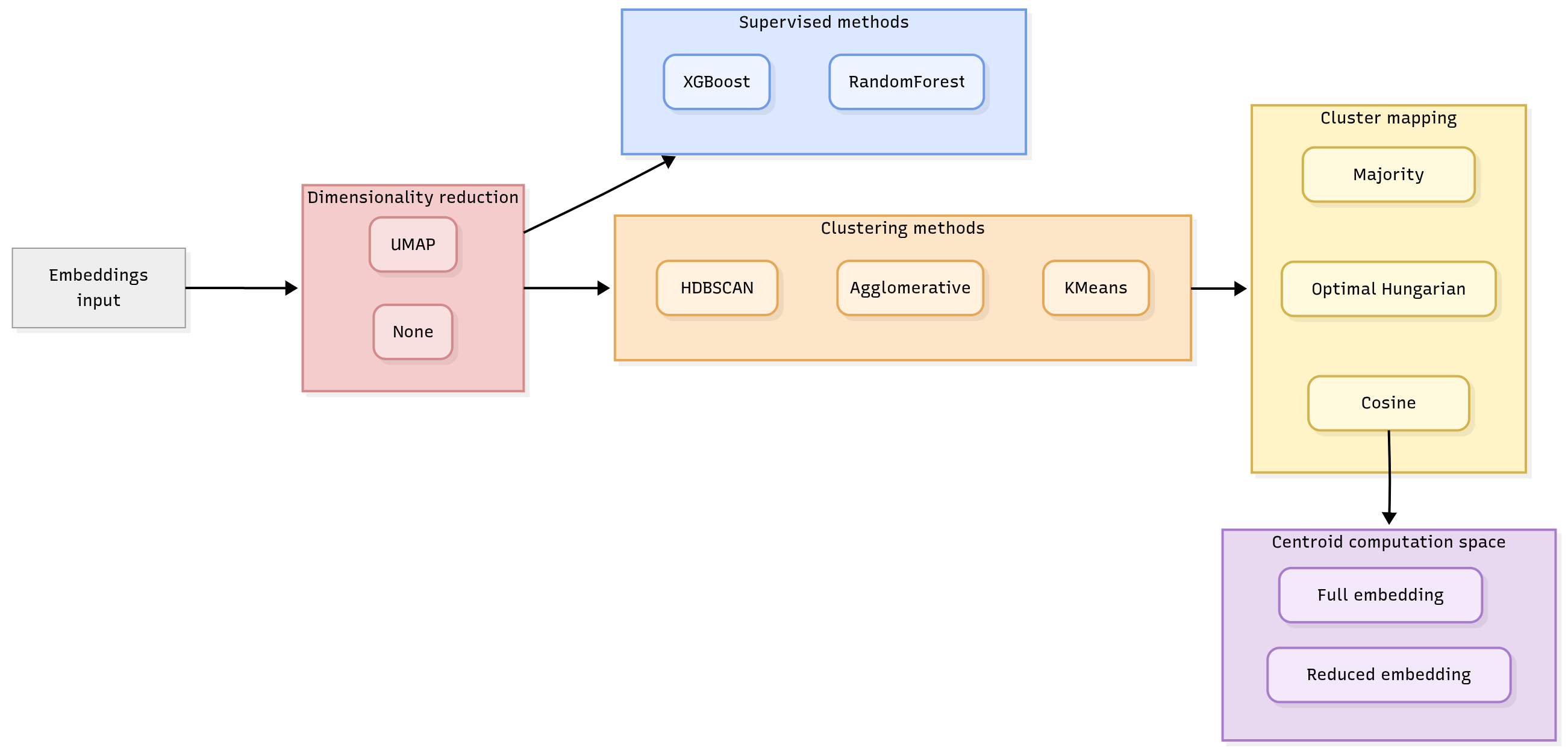
In this paper, we explore hybrid architectures that combine contextual embeddings from pre-trained language models
with numerical features and domain-specific adaptations. We also evaluate prioritization accuracy using multiple
performance metrics, including weighted Cohen’s Kappa, to better reflect operational needs i