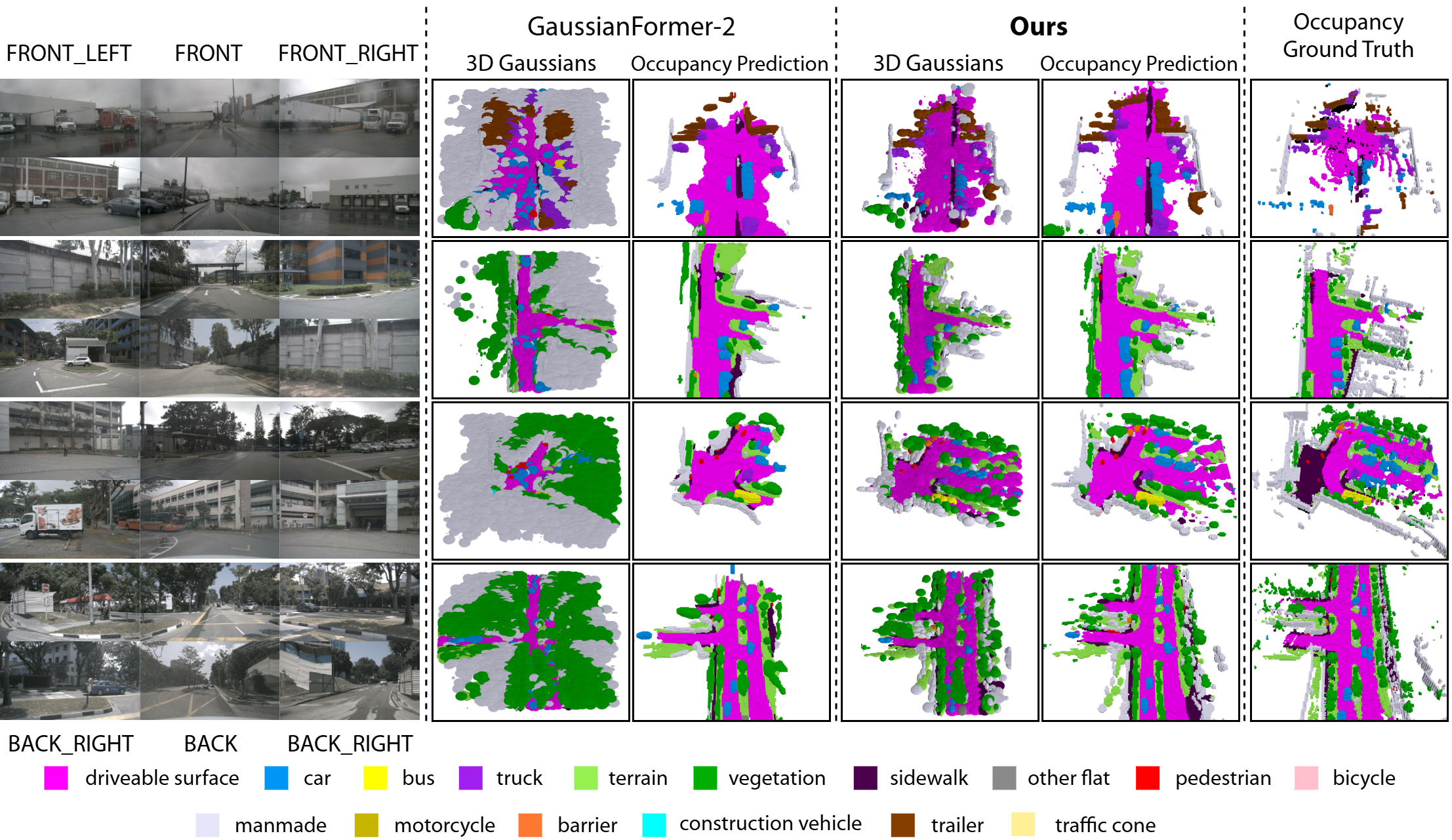
Generating a coherent 3D scene representation from multi-view images is a fundamental yet challenging task. Existing methods often struggle with multi-view fusion, leading to fragmented 3D representations and sub-optimal performance. To address this, we introduce VG3T, a novel multi-view feed-forward network that predicts a 3D semantic occupancy via a 3D Gaussian representation. Unlike prior methods that infer Gaussians from single-view images, our model directly predicts a set of semantically attributed Gaussians in a joint, multi-view fashion. This novel approach overcomes the fragmentation and inconsistency inherent in view-by-view processing, offering a unified paradigm to represent both geometry and semantics. We also introduce two key components, Grid-Based Sampling and Positional Refinement, to mitigate the distance-dependent density bias common in pixel-aligned Gaussian initialization methods. Our VG3T shows a notable 1.7%p improvement in mIoU while using 46% fewer primitives than the previous state-of-the-art on the nuScenes benchmark, highlighting its superior efficiency and performance.
Vision-centric systems [1], [2], [3], [4] are gaining prominence in autonomous driving due to their inherent cost-effectiveness compared to LiDAR-based solutions [5], [6], [7], [8], [9], [10], [11]. However, these 1 J. Kim, S. Lee are with the School of Electrical Engineering, Kookmin University, Seoul 02707, South Korea, {jhk00,sungonce}@kookmin.ac.kr systems face a critical challenge: a lack of explicit 3D geometric and semantic understanding. This limitation manifests as fragmented 3D scene representations and can compromise safety when navigating complex and dynamic environments. The emergence of 3D semantic occupancy prediction directly addresses this limitation by generating a fine-grained representation of the surrounding environment, jointly capturing both its geometry and semantic meaning [12], [13], [14], [15], [16], [17], [18], [19], [20]. While promising, 3D occupancy methods have struggled with efficiency, primarily due to the use of dense representations like voxels. These voxel-based methods, while offering high fidelity, are computationally intensive and inefficient as they fail to leverage the inherent spatial sparsity of real-world scenes. This has motivated a shift towards more efficient and sparse representations [21], [22]. A promising direction models occupancy as 3D Gaussians with learnable attributes [23], [24]. This approach is particularly compelling due to its ability to capture the spatial sparsity of real-world scenes, providing a flexible and differentiable representation that models complex geometries with high computational efficiency.
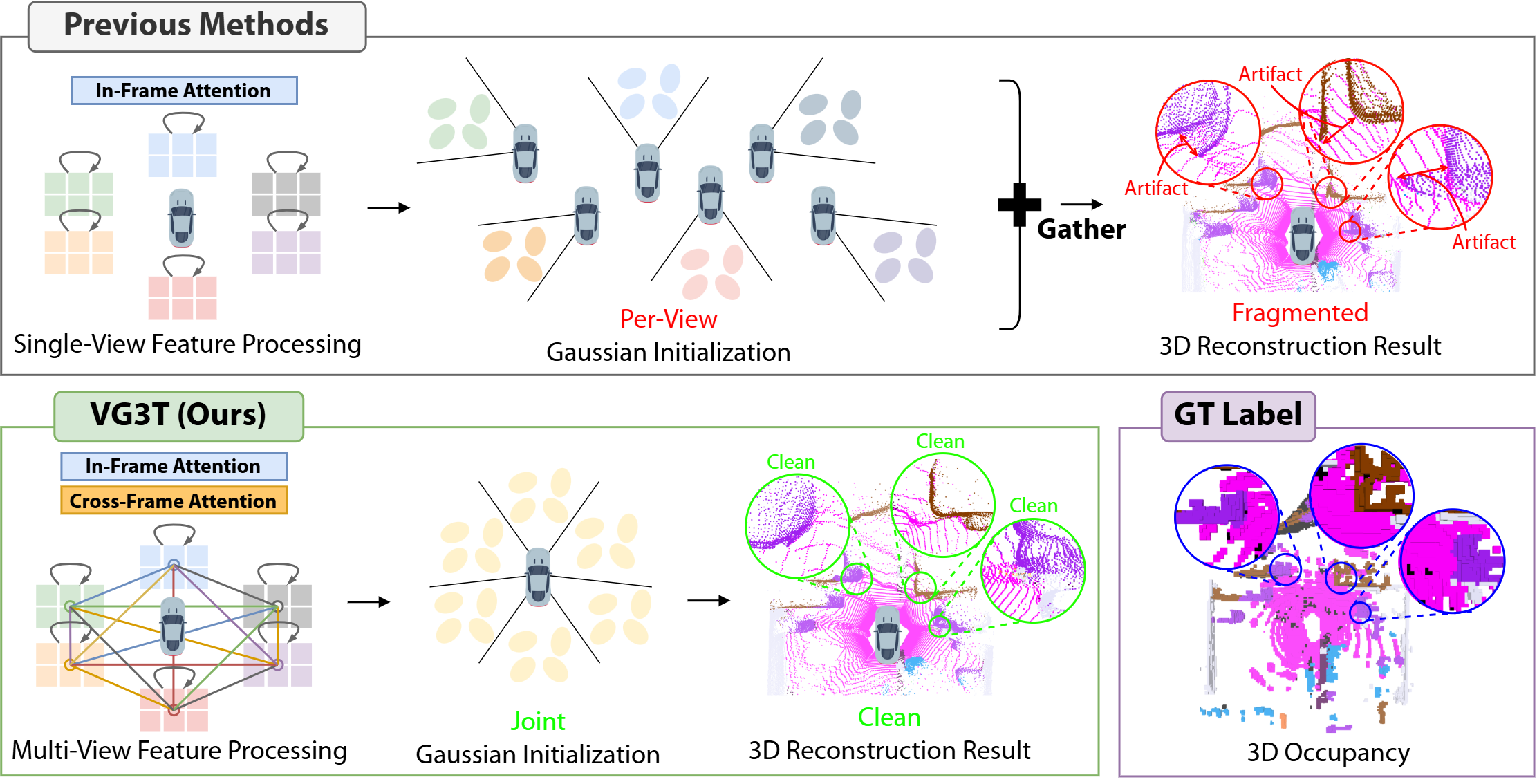
Despite the promise of 3D Gaussian representations, existing methods, such as GaussianFormer [23] and GaussianFormer-2 [24], face two critical challenges. First, they rely on a fragmented, view-by-view paradigm where features from each camera are processed independently. This approach makes it difficult to establish coherent cross-view correspondences, resulting in inconsistent and geometrically fragmented 3D representations. A second challenge is a distance-dependent density bias, where Gaussians are oversampled near the camera and under-represented in distant regions. This imbalance compromises both efficiency and accuracy, as it leads to redundant primitives and a lack of fine-grained detail where it is most needed. These two limitations, fragmented multi-view fusion and density bias, collectively hinder the generation of accurate and efficient 3D occupancy predictions vital for autonomous driving.
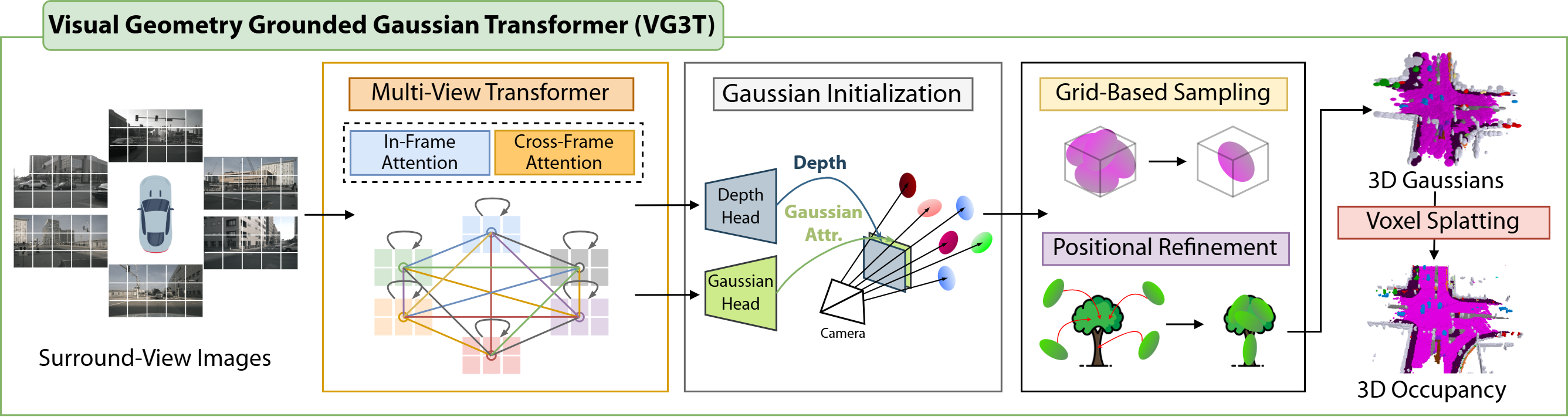
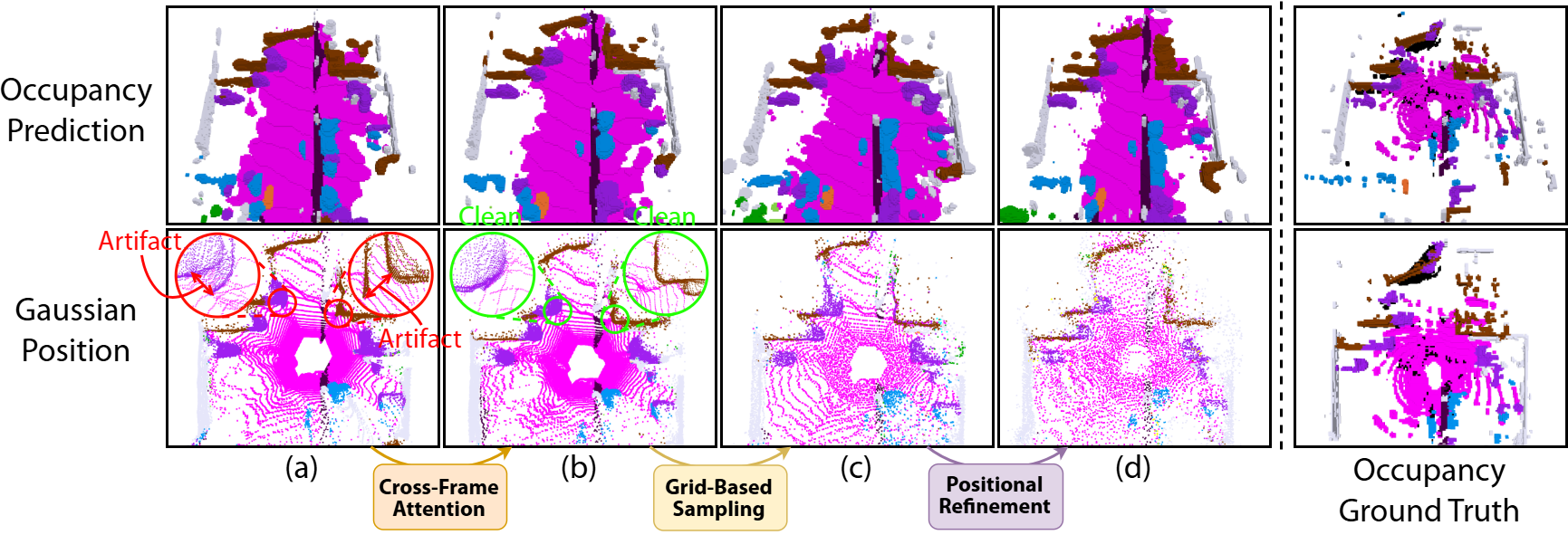
In this paper, we introduce Visual Geometry Grounded Gaussian Transformer, dubbed as VG3T, a novel multiview feed-forward network that directly addresses these challenges. VG3T models a set of semantically-attributed 3D Gaussians from surround-view images. Unlike prior work [23], [24], our model is a unified, end-to-end framework that leverages early multi-view feature correlation. This allows us to fuse multi-view information more coherently, leading to precise geometric and semantic predictions that capture the scene’s full 3D structure without relying on external supervisory data. To mitigate the critical distancedependent density bias, our approach employs a two-staged strategy. First, a Grid-Based Sampling module efficiently removes redundant Gaussians from over-represented areas, guaranteeing an even spatial distribution. Second, the Residual Refinement module precisely adjusts the properties of the remaining Gaussians, enabling them to better capture fine details in previously under-represented areas.
Our main contributions can be summarized as follows:
• We present VG3T, a novel multi-view feed-forward network that directly predicts 3D semantic occupancy with a Gaussian representation. By leveraging early cross-view feature correlation, our model overcomes the fragmentation inherent in existing view-by-view approaches, enabling a more unified and coherent 3D scene understanding. • To address the fundamental problem of distancedependent density bias, we propose a two-staged strategy: Grid-Based Sampling, which efficiently removes redundant primitives from over-represented areas, and a Positional Refinement module, which precisely adjusts remaining Gaussians to capture fine-grained details. • Our end-to-end trainable model, VG3T, achieves a new state-of-the-art on the nuScenes 3D semantic occupancy benchmark. We demonstrate a notable 1.7%p improvement in mIoU while using 46% fewer primitives than the previous state-of-the-art method, highlighting the superior efficiency and effectiveness of our approach.
3D semantic occupancy prediction is a critical task for autonomous driving, providing a comprehensive and fine-grained understanding of the surrounding environment. While LiDAR-based methods offer strong performance, their high cost and weather-related vulnerabilities have spurred the development of camera-based alternatives. Early visioncentric methods relied on dense voxel-based representations [14], [15]. While these methods achieve
This content is AI-processed based on open access ArXiv data.