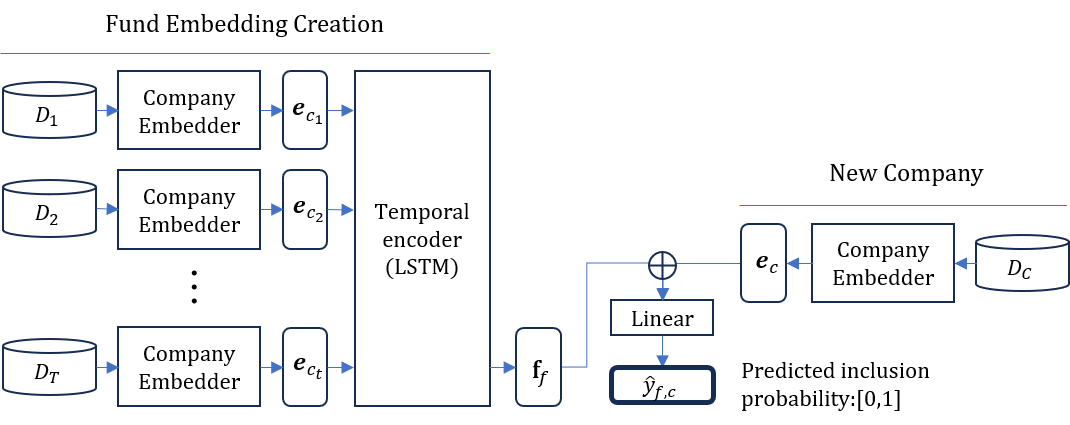
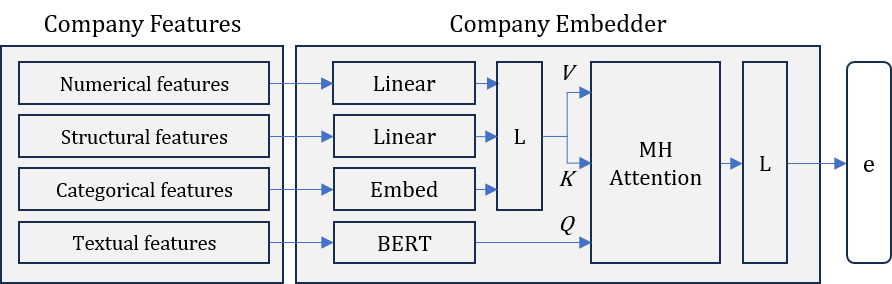
This study proposes a method for predicting startup inclusion, estimating the probability that a venture capital (VC) fund will invest in a given startup. Unlike general recommendation systems, which typically rank multiple candidates, our approach formulates the problem as a binary classification task tailored to each fund-startup pair. Each startup is represented by integrating textual, numerical, and structural features, with Node2Vec capturing network context and multi-head attention enabling feature fusion. Fund investment histories are encoded as LSTM-based sequences of past investees. Experiments on Japanese startup data demonstrate that the proposed method achieves higher accuracy than a static baseline. The results indicate that incorporating structural features and modeling temporal investment dynamics are effective in capturing fund-startup compatibility.
💡 Deep Analysis
📄 Full Content
Predicting Startup–VC Fund Matches with
Structural Embeddings and Temporal Investment
Data
Koutarou Tamura
Uzabase, Inc., Japan.
Email: koutarou.tamura@uzabase.com, k.tamura.phd@gmail.com
Abstract—This study proposes a method for predicting startup
inclusion, estimating the probability that a venture capital (VC)
fund will invest in a given startup. Unlike general recommen-
dation systems, which typically rank multiple candidates, our
approach formulates the problem as a binary classification task
tailored to each fund–startup pair. Each startup is represented
by integrating textual, numerical, and structural features, with
Node2Vec capturing network context and multi-head attention
enabling feature fusion. Fund investment histories are encoded
as LSTM-based sequences of past investees.
Experiments on Japanese startup data demonstrate that the
proposed method achieves higher accuracy than a static baseline.
The results indicate that incorporating structural features and
modeling temporal investment dynamics are effective in captur-
ing fund–startup compatibility.
Index Terms—Startup Investment, Fund Portfolio, Dynamic
Embedding, Matching Model, Natural Language Processing,
Graph Representation, Venture Capital
I. INTRODUCTION
In recent years, investment in startup companies has inten-
sified both domestically and internationally. Accordingly, the
importance of making portfolio decisions based on rigorous
evaluation of individual firms’ growth potential and future
prospects has increased. In Japan, notably, the government
launched a five-year national startup support initiative led
by the Cabinet Office [1], resulting in a broader range of
industries and business stages becoming eligible for venture
funding.
These startup companies are typically supported during their
early growth stages through investments from corporate firms
and venture capital (VC) funds. The presence or absence of
such financial support can exert a significant influence on the
trajectory of business development. In recent years, overseas
venture capital firms have also been increasing their presence,
contributing to a growing volume of investment activity in the
Japanese market. In fact, domestic startup funding peaked in
2022 and has since remained at a high level—approximately
800 billion yen annually—with the average amount raised per
company continuing to increase [2].
Under such circumstances, fund managers and investment
support institutions are required to identify appropriate invest-
ment targets from among the growing and diverse pool of
emerging startups, and to make informed decisions regarding
their inclusion in investment portfolios. In the financial do-
main, portfolio construction is typically grounded in quantita-
tive assessment and optimization of risk and return. While such
evaluations can be conducted based on stock prices in the case
of publicly listed companies, unlisted startups generally lack
real-time market valuation data. As a result, investment deci-
sions for startups often rely on qualitative information, such
as business descriptions and industry classifications. However,
these types of information are typically updated infrequently
and may fail to capture temporal changes. Consequently,
investment decisions are also informed by relational infor-
mation—such as historical co-investment patterns and shared
portfolio holdings with previous funds—indicating that startup
evaluation often depends not only on intrinsic attributes, but
also on their position within the broader investment network.
To address these challenges, this study proposes a method
for estimating the likelihood that a newly emerging startup
will be included in a venture capital (VC) fund’s portfolio. The
approach involves designing both startup and fund embeddings
by integrating semantic information—such as firm-specific
qualitative and quantitative attributes (e.g., numerical indica-
tors and textual business descriptions)—with structural fea-
tures derived from inter-firm relationships as captured by his-
torical portfolio co-investment data. This fusion of meaning-
based and structure-based features enables a representation
that reflects both the intrinsic characteristics of individual
firms and their relational positioning within the investment
ecosystem.
In this study, we frame startup investment recommendation
as an inclusion prediction task. Rather than ranking multiple
candidates, we aim to estimate whether a specific candidate
startup will be included in a particular VC fund’s portfolio,
given its historical investments. We adopt the term “inclusion
prediction” throughout this paper to refer to this fund-specific
binary classification task.
II. RELATED WORK
In the context of estimating the likelihood that a startup
will be included in a VC fund’s portfolio, existing research
can be broadly categorized into three major approaches: (1)
learning embedding representations of individual companies,
(2) modeling company–fund relationships