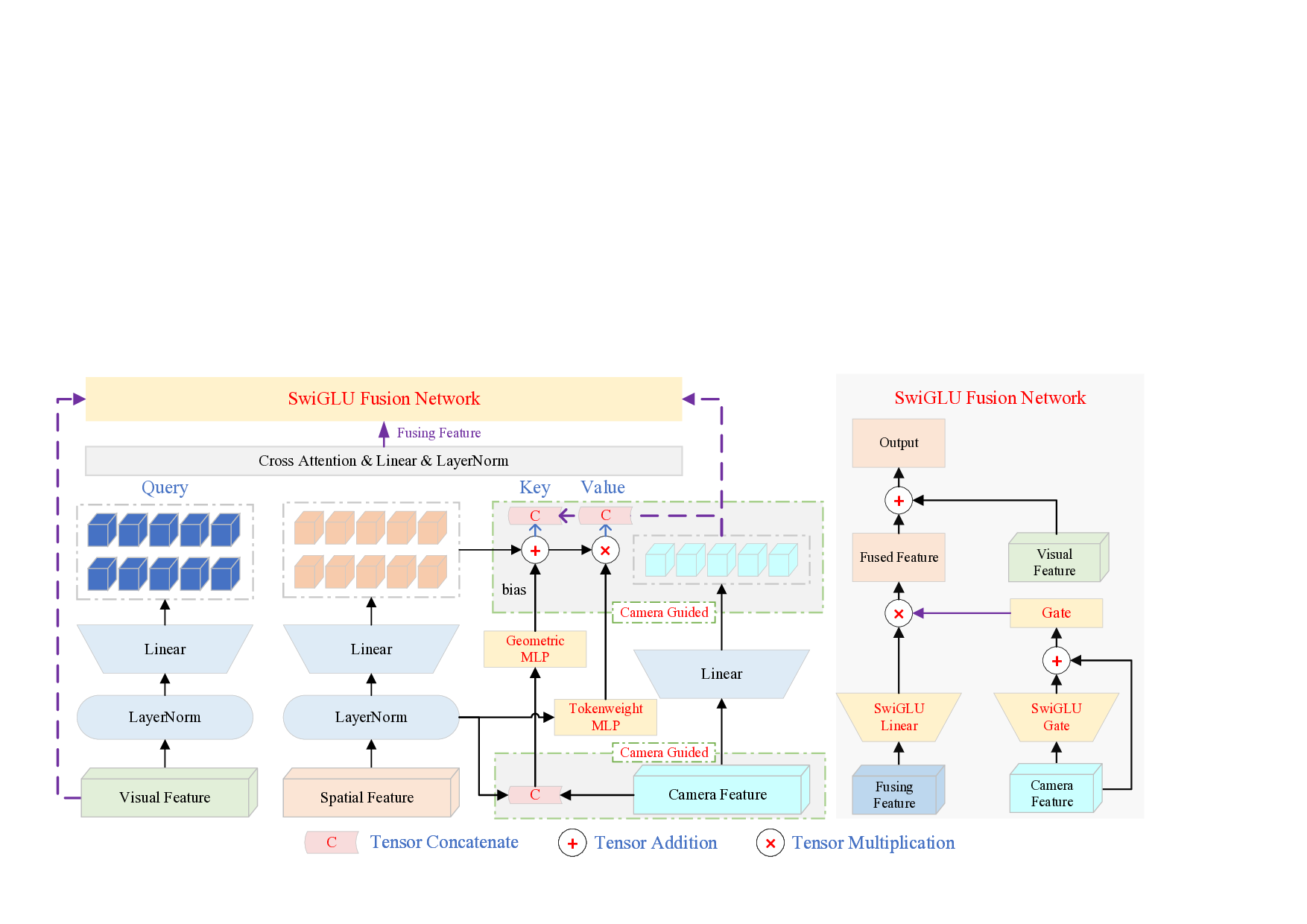
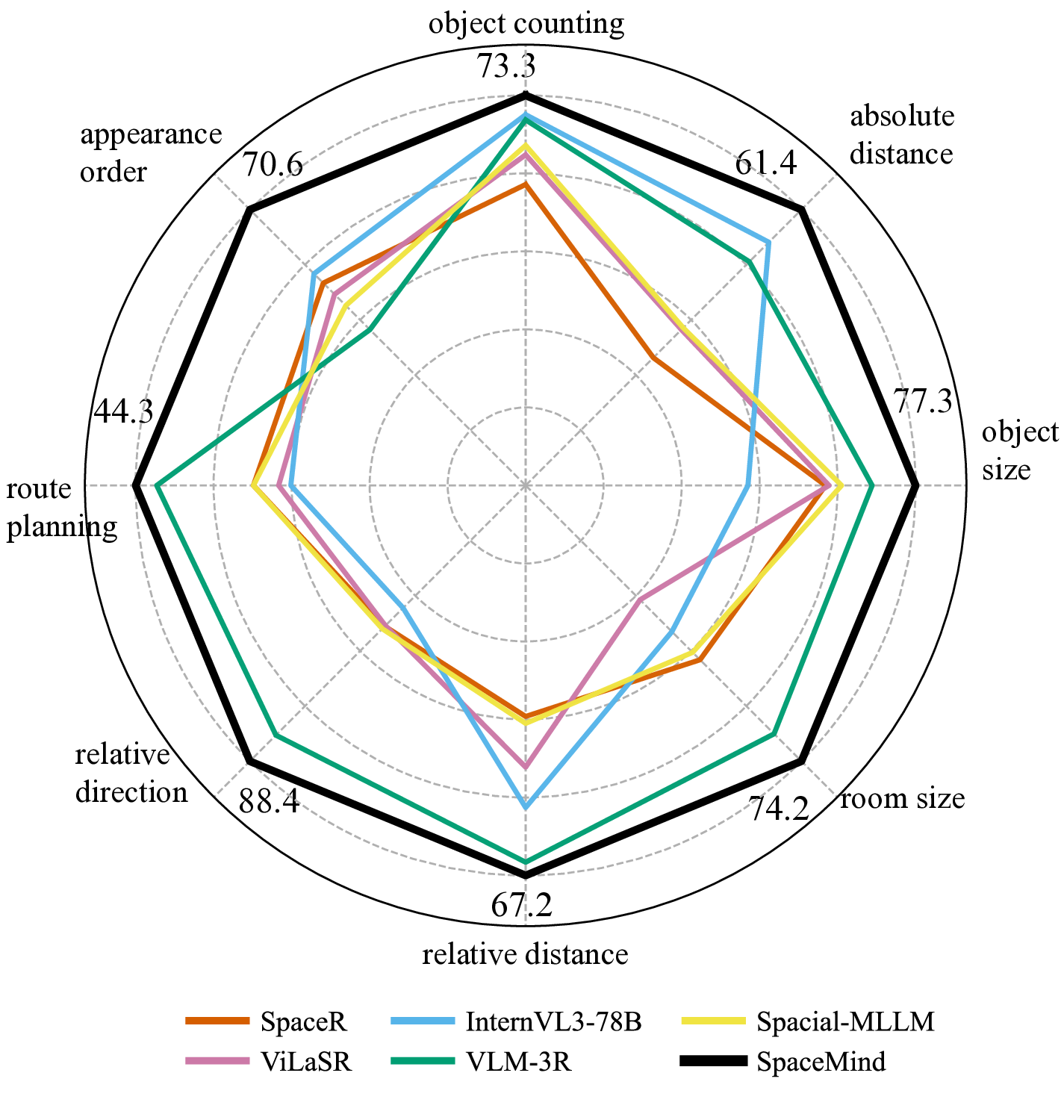
Large vision-language models (VLMs) show strong multimodal understanding but still struggle with 3D spatial reasoning, such as distance estimation, size comparison, and cross-view consistency. Existing 3D-aware methods either depend on auxiliary 3D information or enhance RGB-only VLMs with geometry encoders through shallow feature fusion. We propose SpaceMind, a multimodal large language model explicitly designed for spatial reasoning solely from RGB inputs. The model adopts a dual-encoder architecture, integrating VGGT as a spatial understanding encoder and InternViT as a 2D visual encoder. The key idea is to treat the camera representation as an active guiding modality rather than passive metadata. Specifically, SpaceMind introduces a lightweight Camera-Guided Modality Fusion module before the language model to replace shallow fusion. It applies camera-conditioned biasing to spatial tokens, assigns query-independent weights reflecting their geometric importance, and uses the camera embedding to gate the fused representation. Empirically, SpaceMind establishes new state-of-the-art results on VSI-Bench, SQA3D and SPBench, surpassing both open and proprietary systems on VSI-Bench and SPBench by large margins and achieving state-of-the-art performance on SQA3D. These results demonstrate that camera-guided modality fusion is an effective and practical inductive bias for equipping VLMs with genuinely spatially grounded intelligence. We will release code and model checkpoints to support future research.
Humans perceive space not merely by seeing, but by understanding from where they see. This coupling be- tween visual observation and viewpoint underlies our ability to estimate distances, compare sizes, infer connectivity, and navigate unfamiliar environments. Endowing multimodal models with such spatial intelligence [68] is crucial for a wide range of applications. However, despite remarkable progress in large language models (LLMs) [6,7,29,46,48,49,56,57,63,76] and multimodal large language models (MLLMs) [1-3, 9, 20, 21, 27, 35, 40] on open-ended reasoning, instruction following, and long-context understanding, recent studies consistently show that they struggle with explicitly 3D-aware tasks, such as metric comparison, layout inference, and multi-view consistency.
Existing approaches to spatially grounded multimodal reasoning can be roughly grouped into two families. The first family augments language or vision-language models with explicit 3D inputs, such as point clouds, depth maps, reconstructed meshes, or BEV/voxel features [14,26,42,44,61,71,77,78,81,82]. These methods leverage depth sensors or multi-view reconstruction pipelines to build 3D scene representations, which are then encoded and aligned with language. They can capture rich geometric details, but inherit several structural limitations: reliance on specialized hardware or pre-scanned environments, heavy multistage processing, sensitivity to reconstruction failures and scale ambiguity, and difficulty scaling to unconstrained inthe-wild video. The second family, exemplified by recent 3D-aware MLLMs, targets visual-based spatial intelligence from monocular or multi-view RGB [16,65]. They typically combine a general-purpose visual encoder [3,72] with a feed-forward geometry encoder [58,59] and then fuse the resulting features via simple mechanisms such as MLP projection or one-stage cross-attention. These designs avoid explicit 3D supervision and are more scalable, but the way they integrate spatial cues remains largely ad hoc.
A closer look at these two lines of work reveals a common limitation. Explicit-3D methods over-commit to precomputed geometry and do not address how viewpoint should interact with language-native reasoning. Visualbased methods, on the other hand, tend to treat all geometric signals-image features, spatial features, and camera information-as if they belonged to a single homogeneous feature space. In practice, camera-related signals are often appended as auxiliary embeddings or implicitly blended into fusion layers. This conflation ignores a principle long emphasized in 3D vision [28,36,51,58,74]: camera (ego/viewpoint) and scene (allocentric content) play fundamentally different roles.
Motivated by this insight, we present SpaceMind, a large vision-language model explicitly designed for 3D spatial reasoning from RGB inputs. SpaceMind treats the camera representation as a dedicated modality that guides how spatial information is injected into the visual stream, rather than as a passive conditioning vector. Concretely, Space-Mind uses a visual encoder [9] and a spatial encoder [58] to obtain semantic and geometry-aware tokens, and introduces a Camera-Guided Modality Fusion (CGMF) module before the language model. CGMF applies camera-conditioned biasing over spatial tokens, a query-independent spatial importance weighting, and camera-conditioned gating on fused features, making the role of the camera explicit in the fusion process while preserving the interface of standard VLMs. This design is intentionally simple-built from standard components-but aligns viewpoint, spatial cues, and semantics within a unified multimodal framework. Empirically, SpaceMind achieves a new state of the art on VSI-Bench [68], with a clear margin over existing open and proprietary systems, and delivers comparable or superior performance on other spatial reasoning benchmarks such as SQA3D [41] and SPBench [55], indicating strong generalization across datasets and task formats. In summary, our contributions are four-fold:
Multimodal large language models extend large language models to vision and other modalities by aligning visual and textual tokens in a shared embedding space. CLIP [50] and ALIGN [1] learn joint image-text representations via contrastive pretraining, enabling strong zero-shot transfer. Flamingo [1] and BLIP-2 [35] introduce tokenlevel or feature-level fusion modules (e.g., Q-Former, crossattention bridges) to couple frozen LLM backbones with vision encoders, while instruction-tuned systems such as the LLaVA family [32,33,38,39,75], MiniGPT-4 [79], Qwen-VL [3], and InternVL [9] further enhance open-ended visual QA. Recent video MLLMs [37,43,54,64,73] extend these designs to temporal inputs through spatiotemporal pooling, causal attention over frame tokens, or long-context architectures, and achieve strong performance on video understanding benchmarks.
Despite their success, these models are mostly optimized for semantic and
This content is AI-processed based on open access ArXiv data.