Title: Retrieval-Augmented Few-Shot Prompting Versus Fine-Tuning for Code Vulnerability Detection
ArXiv ID: 2512.04106
Date: 2025-11-28
Authors: Fouad Trad, Ali Chehab
📝 Abstract
Few-shot prompting has emerged as a practical alternative to fine-tuning for leveraging the capabilities of large language models (LLMs) in specialized tasks. However, its effectiveness depends heavily on the selection and quality of in-context examples, particularly in complex domains. In this work, we examine retrieval-augmented prompting as a strategy to improve few-shot performance in code vulnerability detection, where the goal is to identify one or more security-relevant weaknesses present in a given code snippet from a predefined set of vulnerability categories. We perform a systematic evaluation using the Gemini-1.5-Flash model across three approaches: (1) standard few-shot prompting with randomly selected examples, (2) retrieval-augmented prompting using semantically similar examples, and (3) retrieval-based labeling, which assigns labels based on retrieved examples without model inference. Our results show that retrieval-augmented prompting consistently outperforms the other prompting strategies. At 20 shots, it achieves an F1 score of 74.05% and a partial match accuracy of 83.90%. We further compare this approach against zero-shot prompting and several fine-tuned models, including Gemini-1.5-Flash and smaller open-source models such as DistilBERT, DistilGPT2, and CodeBERT. Retrieval-augmented prompting outperforms both zero-shot (F1 score: 36.35%, partial match accuracy: 20.30%) and fine-tuned Gemini (F1 score: 59.31%, partial match accuracy: 53.10%), while avoiding the training time and cost associated with model fine-tuning. On the other hand, fine-tuning CodeBERT yields higher performance (F1 score: 91.22%, partial match accuracy: 91.30%) but requires additional training, maintenance effort, and resources.
💡 Deep Analysis
📄 Full Content
Retrieval-Augmented Few-Shot Prompting Versus
Fine-Tuning for Code Vulnerability Detection
Fouad Trad
Electrical and Computer Engineering
American University of Beirut
Beirut, Lebanon
fat10@mail.aub.edu
Ali Chehab
Electrical and Computer Engineering
American University of Beirut
Beirut, Lebanon
chehab@aub.edu.lb
Abstract—Few-shot prompting has emerged as a practical
alternative to fine-tuning for leveraging the capabilities of large
language models (LLMs) in specialized tasks. However, its
effectiveness depends heavily on the selection and quality of
in-context examples, particularly in complex domains. In this
work, we examine retrieval-augmented prompting as a strategy
to improve few-shot performance in code vulnerability detection,
where the goal is to identify one or more security-relevant
weaknesses present in a given code snippet from a predefined set
of vulnerability categories. We perform a systematic evaluation
using the Gemini-1.5-Flash model across three approaches: (1)
standard few-shot prompting with randomly selected examples,
(2) retrieval-augmented prompting using semantically similar
examples, and (3) retrieval-based labeling, which assigns labels
based on retrieved examples without model inference. Our results
show that retrieval-augmented prompting consistently outper-
forms the other prompting strategies. At 20 shots, it achieves
an F1 score of 74.05% and a partial match accuracy of 83.90%.
We further compare this approach against zero-shot prompting
and several fine-tuned models, including Gemini-1.5-Flash and
smaller open-source models such as DistilBERT, DistilGPT2,
and CodeBERT. Retrieval-augmented prompting outperforms
both zero-shot (F1 score: 36.35%, partial match accuracy:
20.30%) and fine-tuned Gemini (F1 score: 59.31%, partial match
accuracy: 53.10%), while avoiding the training time and cost
associated with model fine-tuning. On the other hand, fine-
tuning CodeBERT yields higher performance (F1 score: 91.22%,
partial match accuracy: 91.30%) but requires additional training,
maintenance effort, and resources. These results underscore the
value of semantically relevant example selection for few-shot
prompting and position retrieval-augmented prompting as a
practical trade-off between performance and deployment cost
in code analysis tasks.
Index
Terms—Retrieval-Augmented
Generation,
Few-Shot
Prompting, Large Language Models, In-Context Learning, Code
Vulnerability Detection
I. INTRODUCTION
Large Language Models (LLMs) have demonstrated strong
performance across a wide range of natural language pro-
cessing tasks, including code understanding and software vul-
nerability detection [1]. Fine-tuning these models for specific
tasks has become a standard approach to adapting them to
specialized domains. However, fine-tuning is resource inten-
sive, may require access to model weights, and entails non-
trivial training time and maintenance costs [2], [3]. This can
be particularly limiting in security-focused applications, where
data distributions evolve frequently and model updates must
be efficient and repeatable.
Few-shot prompting has emerged as an alternative that
avoids the need for model retraining. In this setup, a small
number of labeled input-output examples are embedded di-
rectly into the prompt to guide the model during inference.
This approach leverages the capabilities of general-purpose
LLMs without modifying their internal parameters. While
promising, few-shot prompting suffers from high variance
depending on the quality and relevance of in-context examples.
In complex tasks such as multi-label code vulnerability detec-
tion, selecting examples that are semantically mismatched or
too generic can lead to degraded performance.
In this work, we explore retrieval-augmented prompting
strategies to improve the effectiveness of few-shot learning
for code vulnerability detection. Our hypothesis is that pro-
viding semantically similar in-context examples can improve
prediction accuracy without requiring any model fine-tuning.
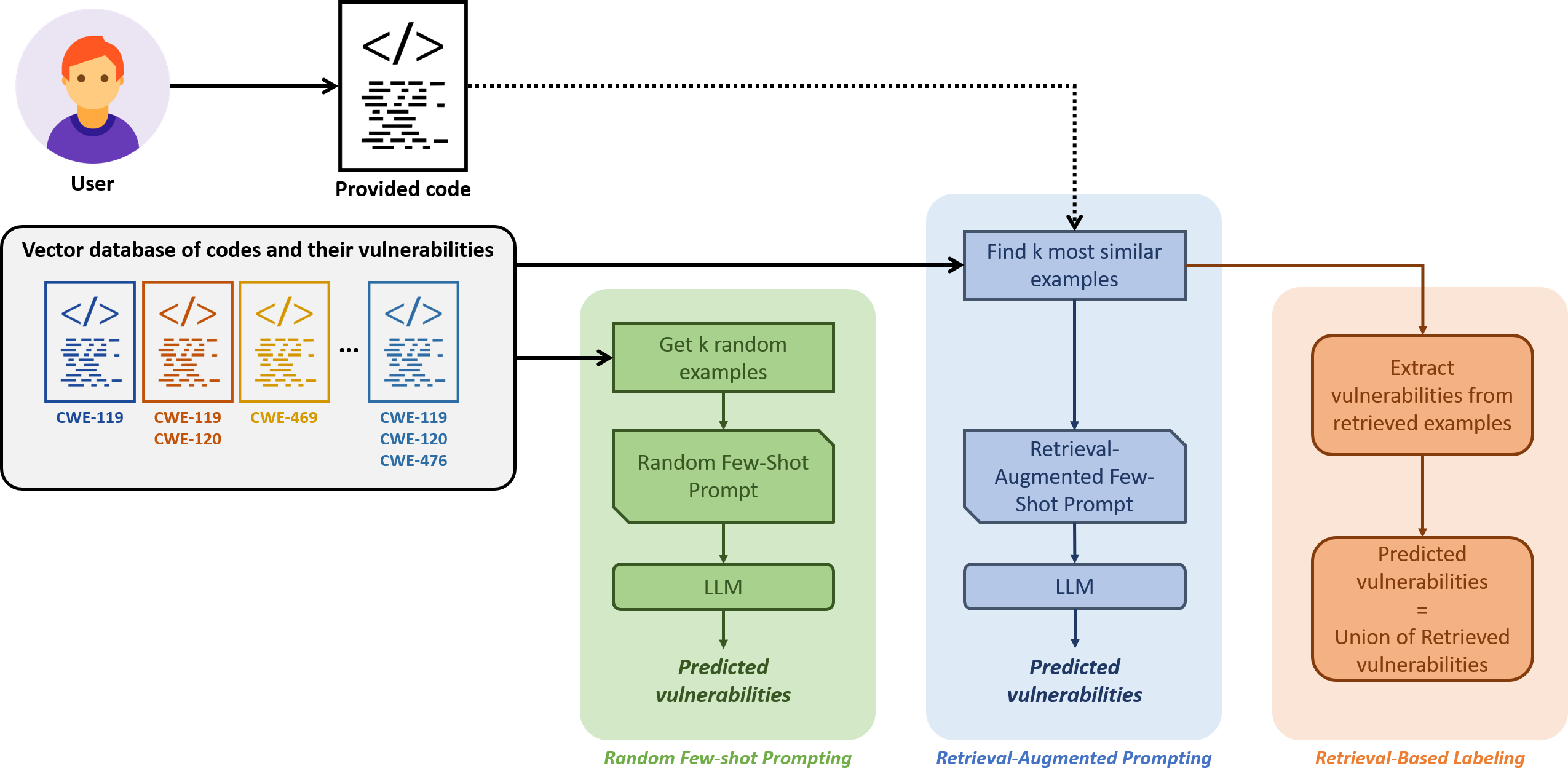
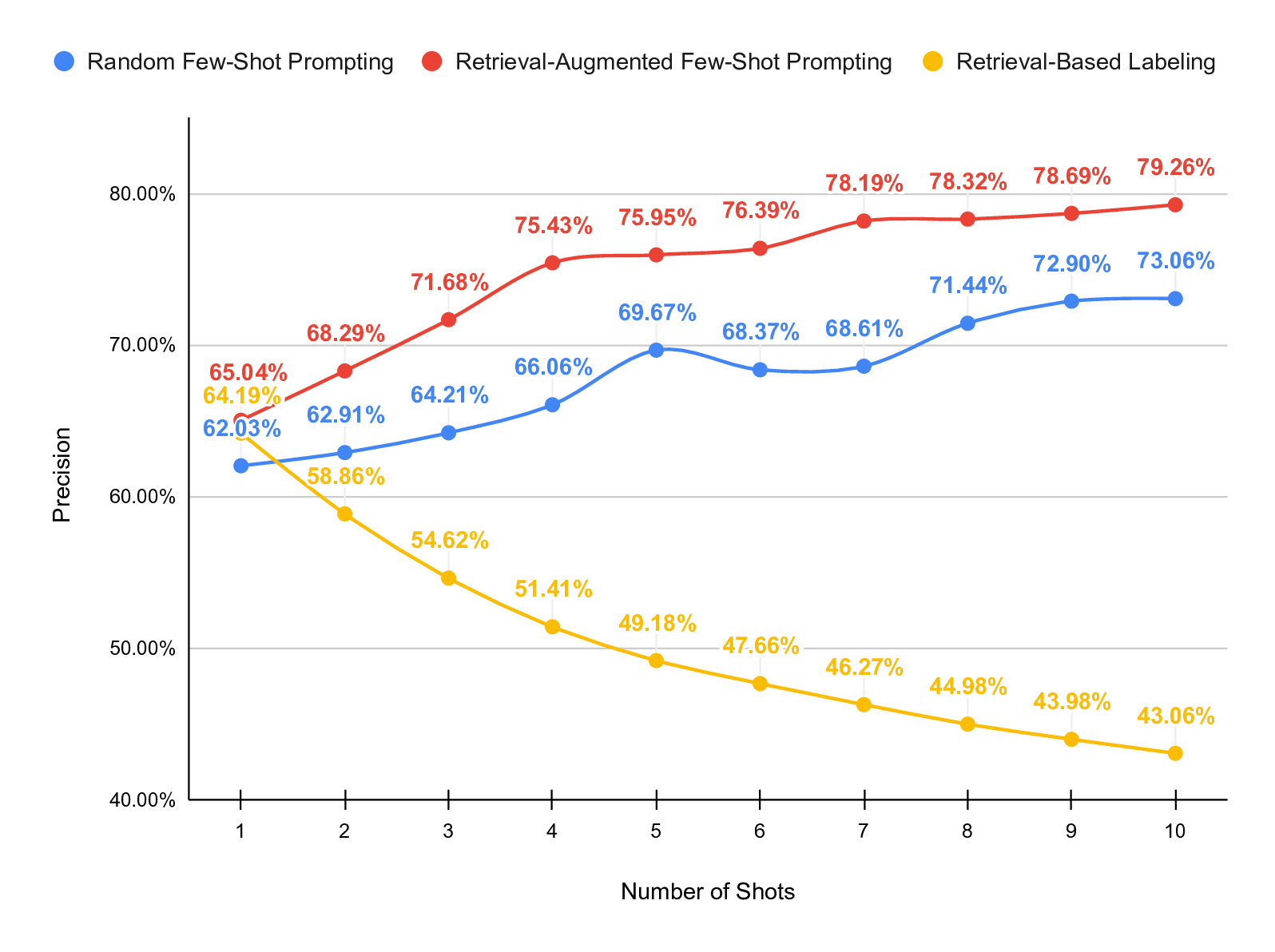
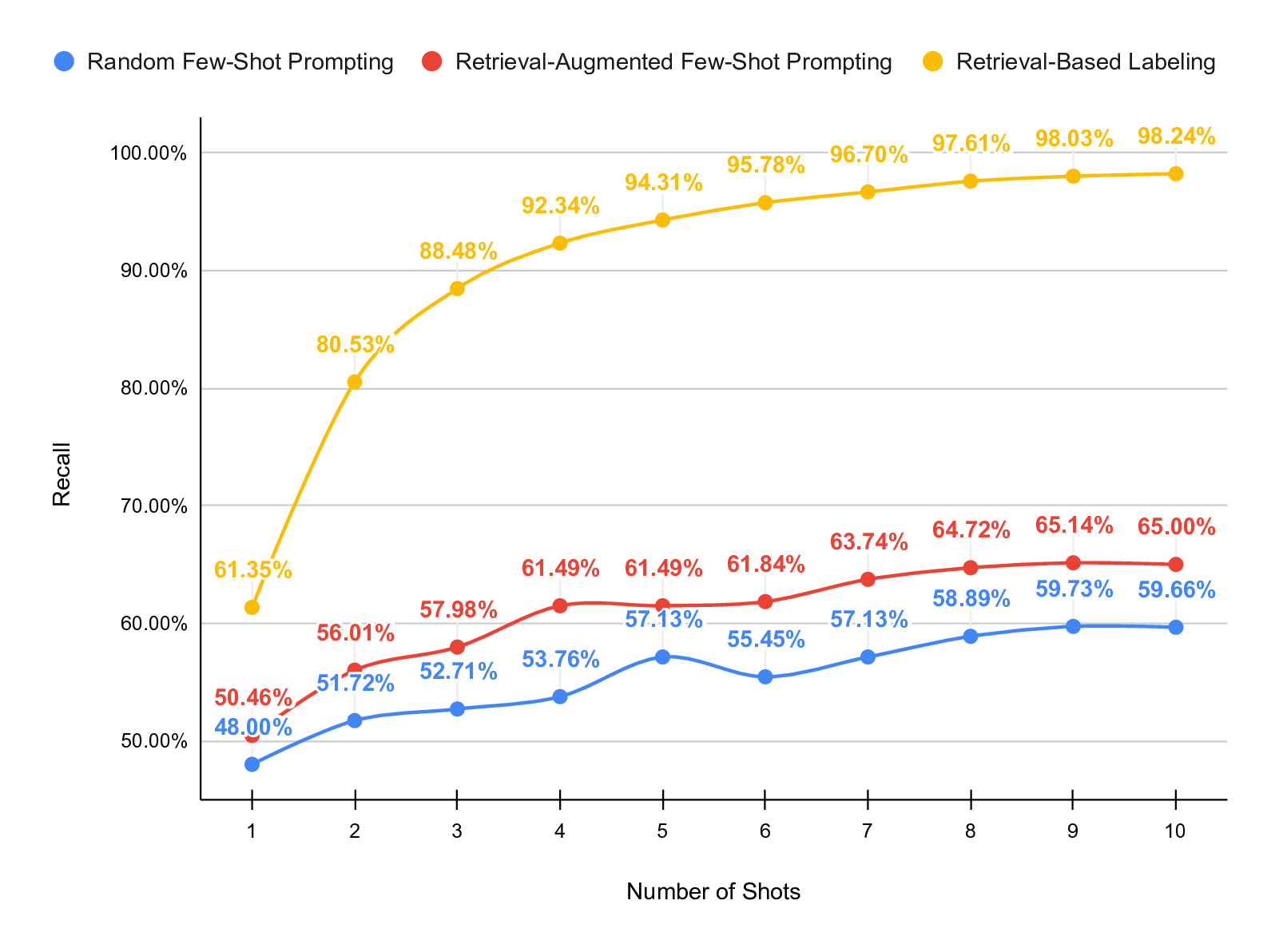
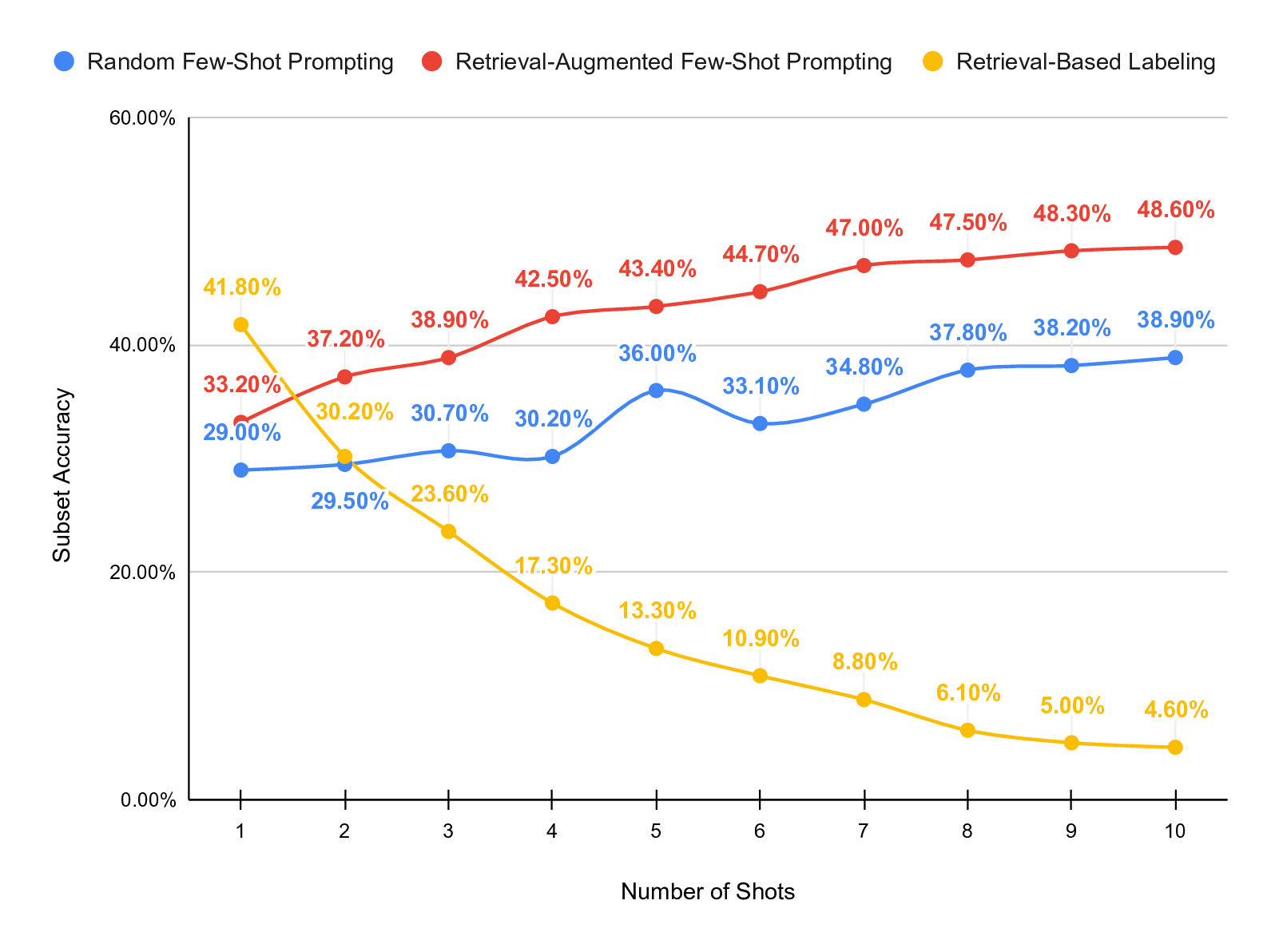
To evaluate this, we implement and compare three prompting
strategies:
• Random Few-Shot Prompting: in-context examples are
randomly sampled from the training set.
• Retrieval-Augmented Few-Shot Prompting: examples
are selected based on semantic similarity to the target
input using an embedding-based retrieval mechanism.
• Retrieval-Based Labeling: labels are inferred by re-
trieving the most similar examples and propagating their
labels directly, without using the LLM for inference.
We conducted a detailed evaluation using the Gemini-1.5-
Flash model on a multi-label code vulnerability detection
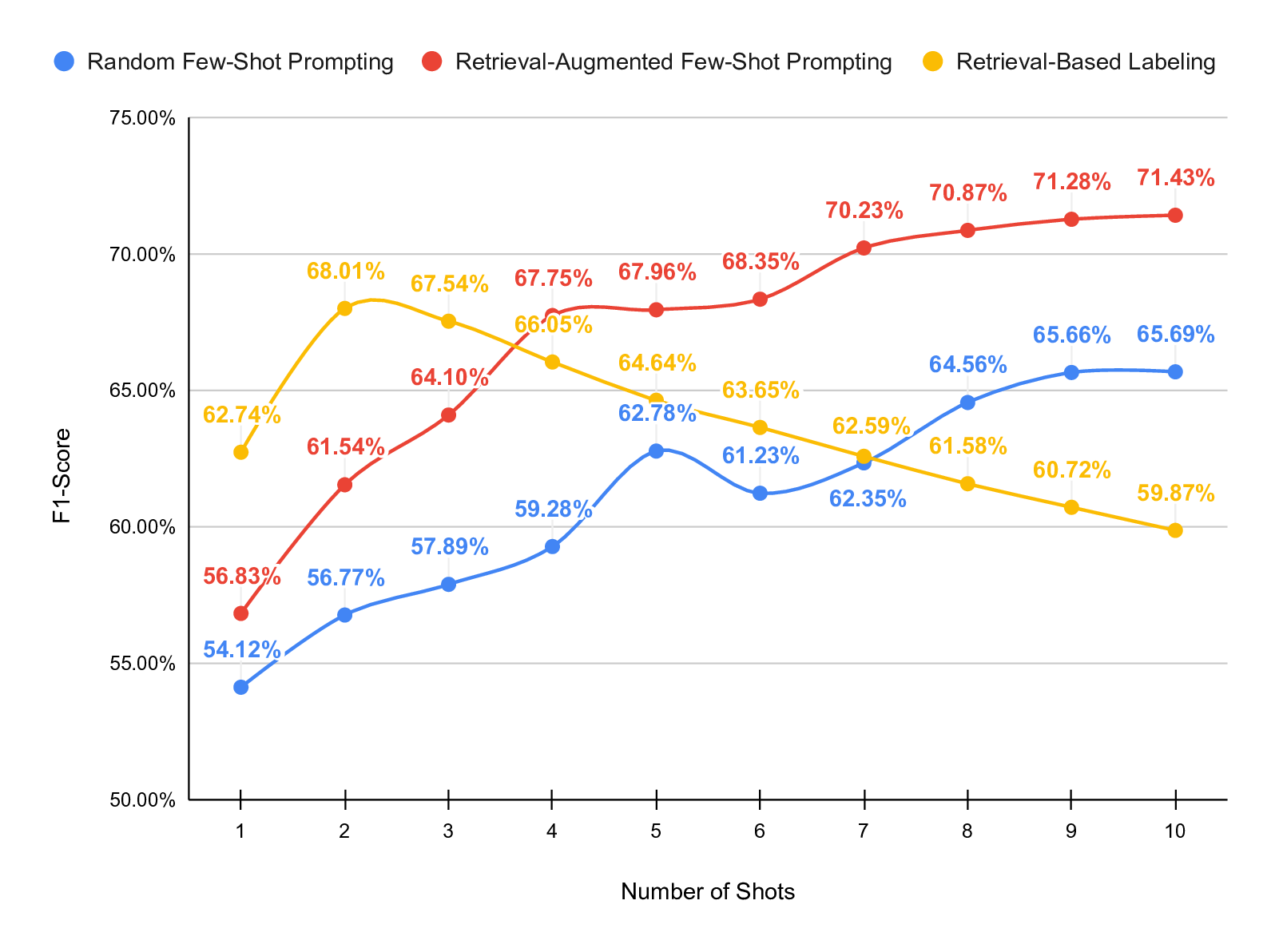
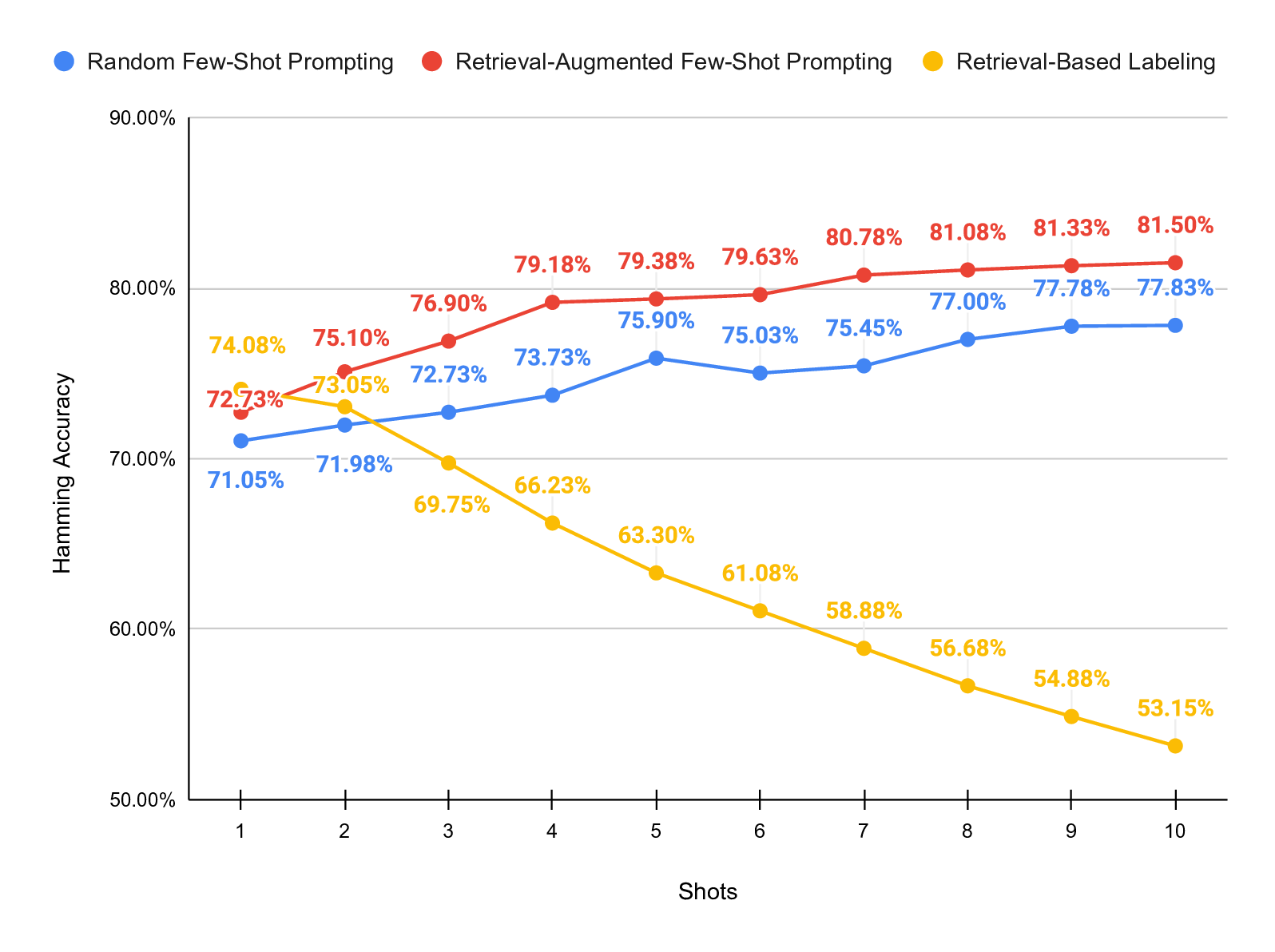
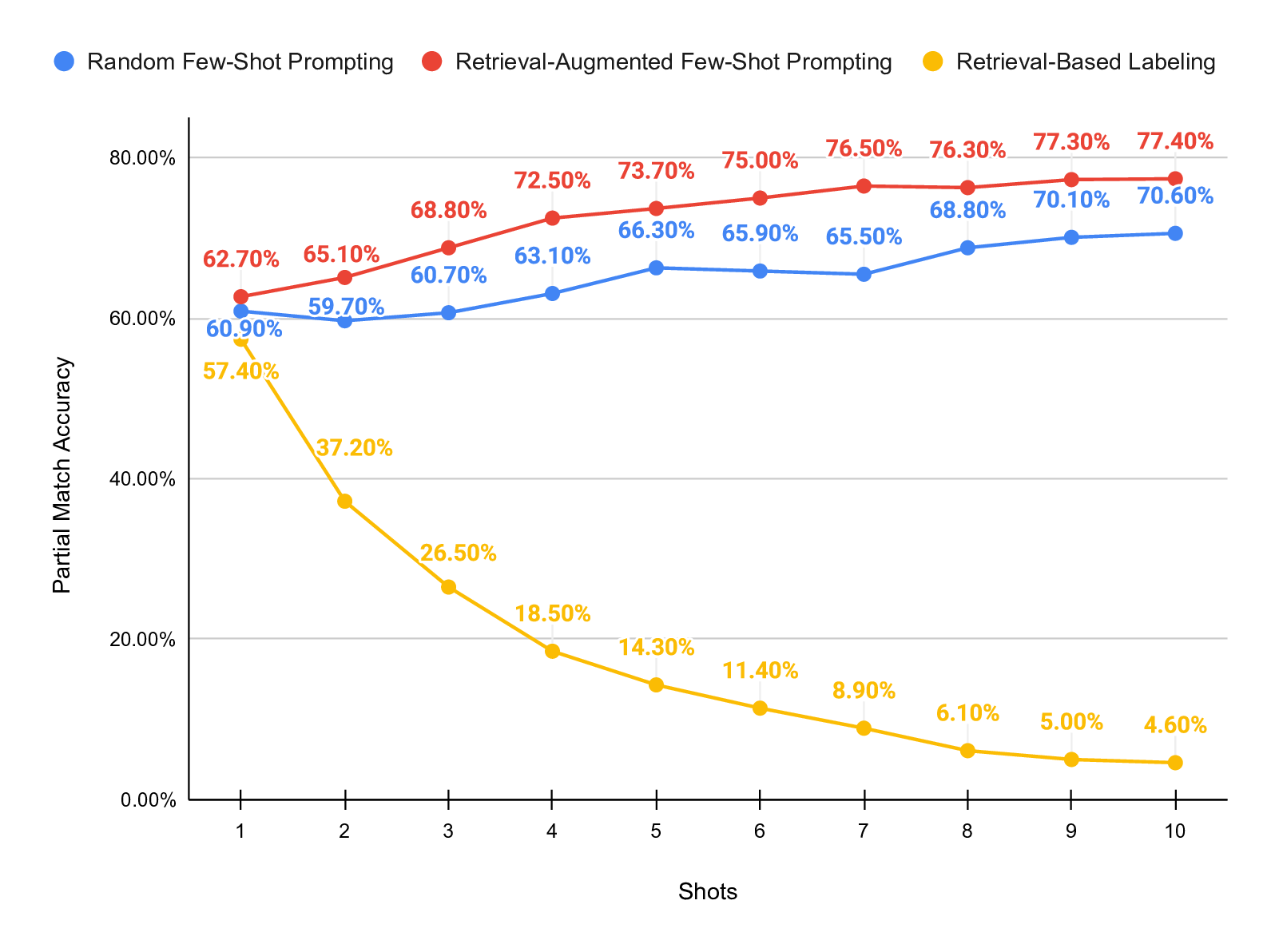
dataset. Our results show that retrieval-augmented prompting
consistently outperforms both random prompting and retrieval-
based labeling. With 20 shots, retrieval-augmented prompting
achieves an F1 score of 74.05% and a partial match accuracy
of 83.90%, substantially outperforming zero-shot prompting
and the other investigated strategies.
To compare with fine-tu