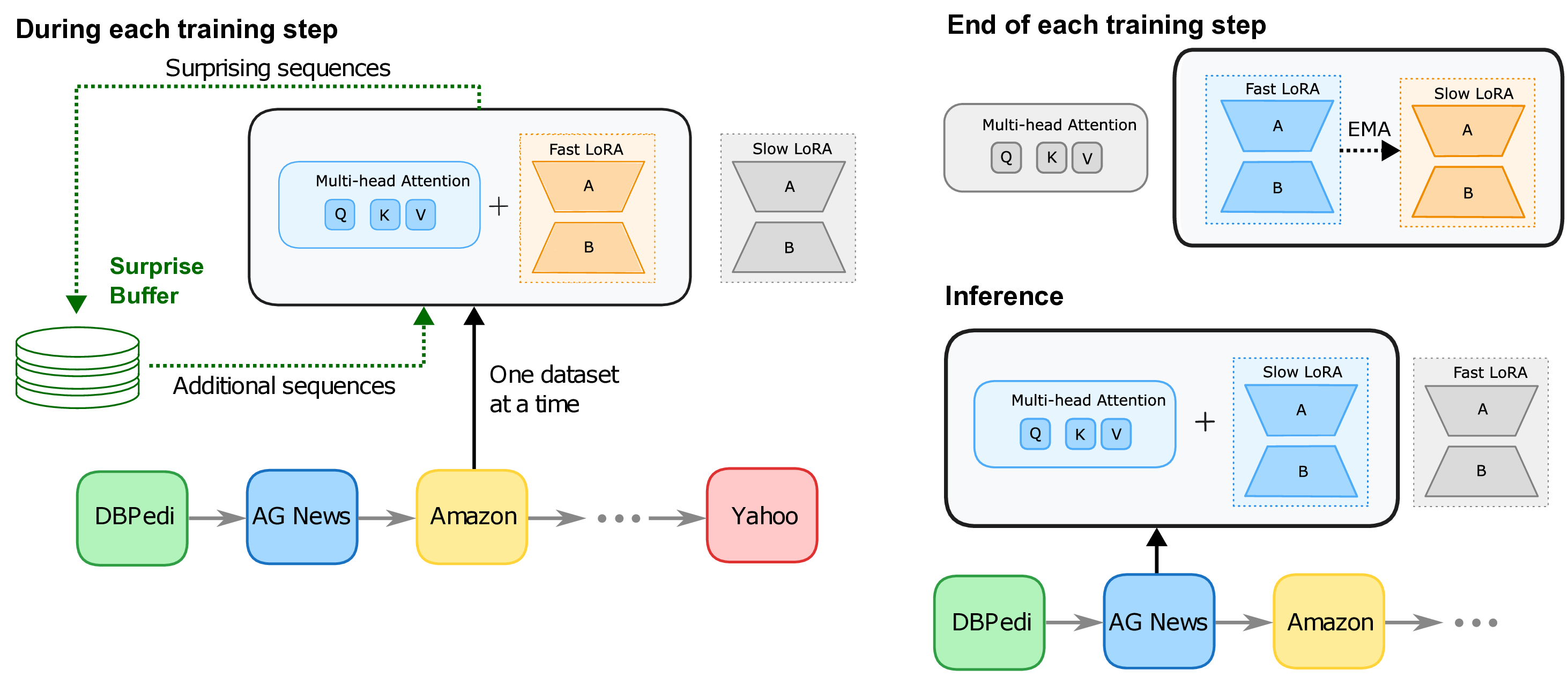
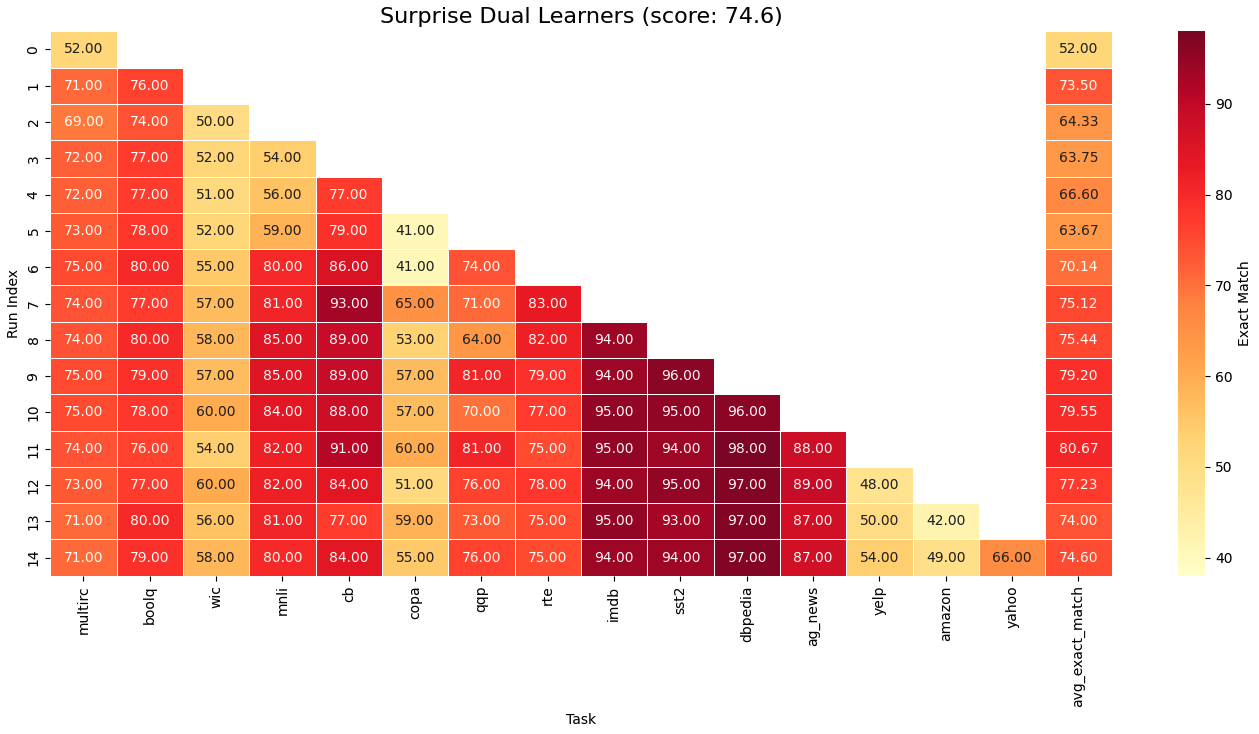
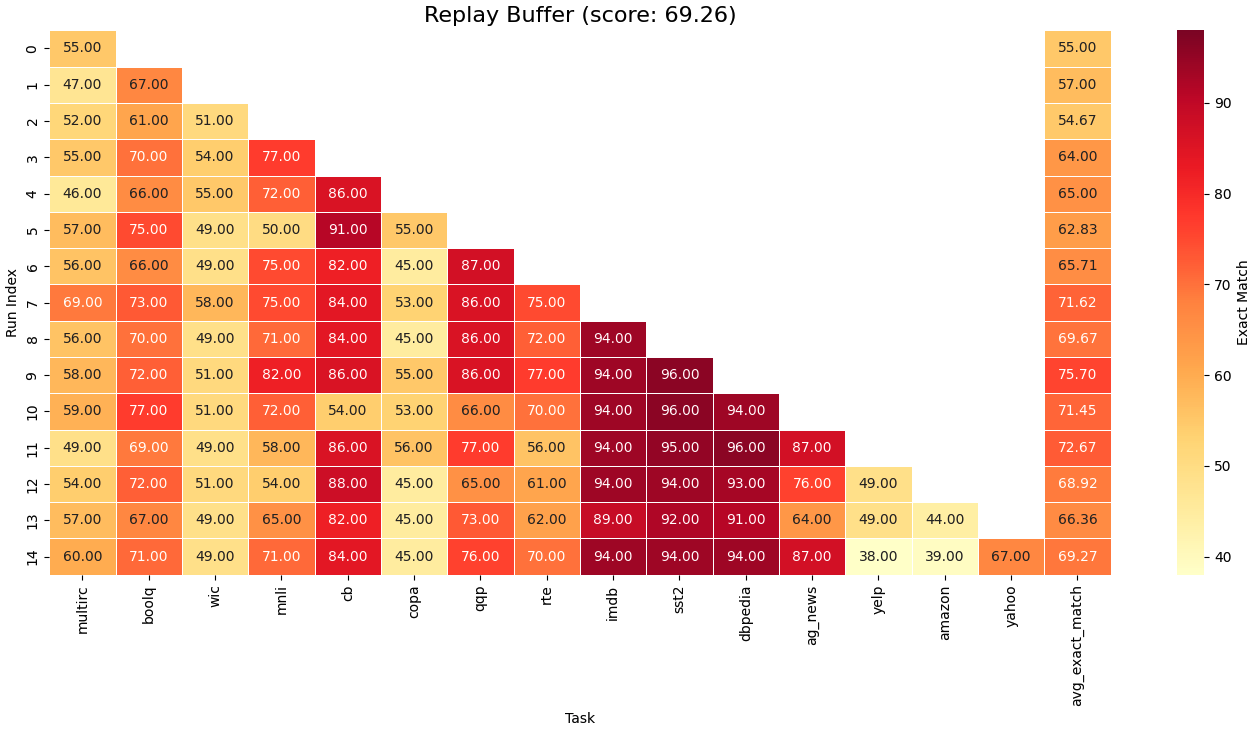
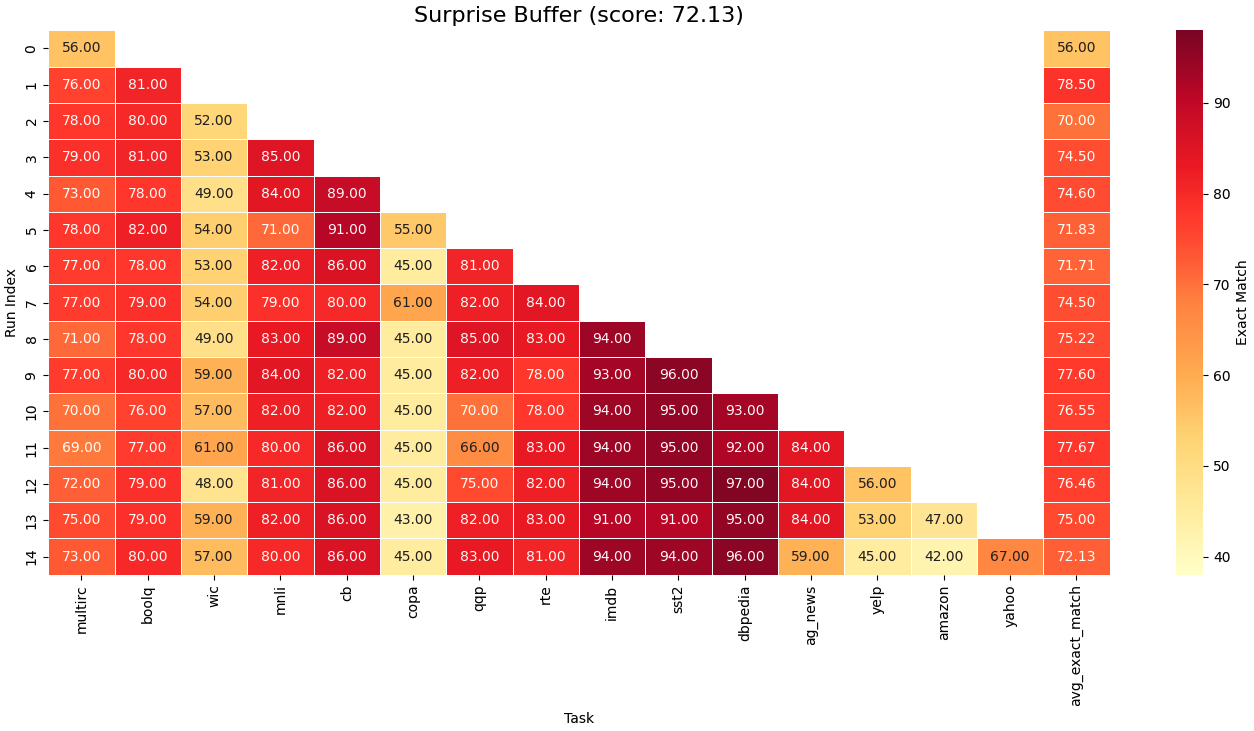
Continual learning, one's ability to adapt to a sequence of tasks without forgetting previously acquired knowledge, remains a major challenge in machine learning and a key gap between artificial and human intelligence. While regularisation and replay perform well in vision, they lag behind multi-task learning for large language models (LLMs), especially at scale with many tasks. We revisit replay and argue that two failure modes drive this gap: selection (what to rehearse) and integration (how to consolidate new knowledge). To address selection, we propose Surprise-prioritised Replay (SuRe), a simple, architecture-agnostic rule that ranks and stores the most surprising (high Negative Log-Likelihood) sequences. SuRe achieves state-of-the-art performance in the Large Number of Tasks (LNT) setting and delivers the best overall average across both Standard CL and LNT benchmarks. To address integration, we add a dual-learner design with fast and slow LoRA adapters merged via an exponential moving average (EMA), enabling rapid adaptation while stabilising long-term knowledge. Combining SuRe with the dual learner yields further gains, including improvements of up to +5 accuracy points on LNT over prior SOTA. Ablation studies confirm that our proposed method remains robust under reduced replay frequency and small buffer size, demonstrating both effectiveness and sample efficiency. Taken together, our results establish replay as a strong baseline for continual LLM fine-tuning and demonstrate that surprise-based selection and slow-weight consolidation are complementary components for mitigating catastrophic forgetting.
By nature, humans can easily learn new information and acquire new skills one at a time with few examples, an ability which is often taken for granted but proves extremely difficult for machine learning models. This problem framing, often referred to as continual or lifelong learning (CL), has attracted increasing attention as model capabilities have advanced over the past decade. Early research of CL in deep learning focused primarily on vision and reinforcement learning tasks (Kirkpatrick et al., 2017;Aljundi et al., 2018;Rolnick et al., 2019). Recently, the field has expanded toward Natural Language Processing (NLP), motivated by the rapid rise of large language models (LLMs).
While most machine learning models are static by design, a recent shift in paradigm, thanks to advances in In-Context Learning, has shown a promising avenue for more adaptable models (Sun et al., 2025;Zhang et al., 2025;Yang et al., 2025b). While allowing for more flexible models that can leverage current context to NLP tasks, these advances remain limited by the effective size of the context window. CL goes further when it comes to designing flexible models, as it not only requires effective adaptation to new datasets (plasticity) but also effective retention of previously acquired skills (stability). This plasticity-stability dilemma (Mermillod et al., 2013) is at the centre of CL, with one of the main challenges being a lack of stability, leading to catastrophic forgetting (McCloskey & Cohen, 1989;Ratcliff, 1990), performance on previously trained datasets drops as new tasks, domains or classes are introduced. These three framings, referred to as Task-Incremental, Domain-Incremental and Class-Incremental respectively (van de Ven et al., 2022), each come with their own challenge. Often, because the label space expands over time while task identity is unavailable at test time, forcing the model to distinguish among old and new classes without seeing them jointly, class-incremental is considered to be the hardest setting (van de Ven & Tolias, 2019). This is especially the case when dealing with large number of tasks, a setting where most methods rely on known task identity during training, but still struggle to match the performance of Multi-Task Learning (MTL).
Here, we formalise catastrophic forgetting as the sum of two complementary sources of error: (i) selection error from imperfect replay distribution estimates, and (ii) integration error from how new knowledge updates are consolidated. We show these errors are additive and complementary, the strongest methods against catastrophic forgetting should address both.
To explore this idea in practice, we first focus on replay, one of the simplest solutions to the selection problem. We show that previous studies of LLM CL often underestimate replay’s performance and effectiveness in the Class-Incremental scenario. In particular, prior comparisons often mix online, task-agnostic replay with methods that assume known task boundaries (Wang et al., 2023;Qiao & Mahdavi, 2024), potentially leading to lower performance and unfair comparison. We therefore evaluate replay under the same assumption set (known boundaries), yielding a fairer comparison. Notably, we find that under fair comparison, surprise-based selection outperforms random replay and achieves state-of-the-art results in the LNT setting, while also providing the strongest overall average performance across both Standard CL and LNT benchmarks. Finally, for integration error, we show that a simple EMA approach, which stabilises the consolidation of new representations, yields complementary improvements. This confirms our additive error hypothesis, and combining SuRe with EMA further improves performance, particularly in the LNT setting, achieving gains of up to +5 points over prior state-of-the-art.
Our contributions can be summarised as follows: (1) We formalise forgetting as the sum of selection and integration errors, motivating complementary mechanisms for each. (2) We propose Surprise prioritised Replay (SuRe) to improve sample selection efficiency. (3) We show that combining SuRe with a simple integration mechanism (EMA), following the duallearning framework (Pham et al., 2021;Gao et al., 2023), yields strong overall performance, achieving SOTA in LNT and the best average across both benchmarks, empirically confirming (1).
Three lines of research have emerged to approach catastrophic forgetting, replay, regularisation and architecture. These were first developed in the vision and Reinforcement Learning literature before being adapted to the modern architecture of Large Language Models (LLMs) and Vision Language Models (VLMs). For the purpose of efficiency, we focus on replay and methods which were introduced in the CL with LLM literature.
Replay Based Methods. Each replay method can be described by a few design choices: how is the buffer updated, which samples should be replayed and when, and, are the rehearsed sample
This content is AI-processed based on open access ArXiv data.