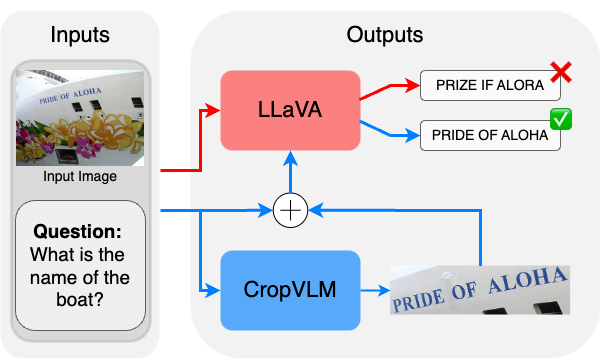
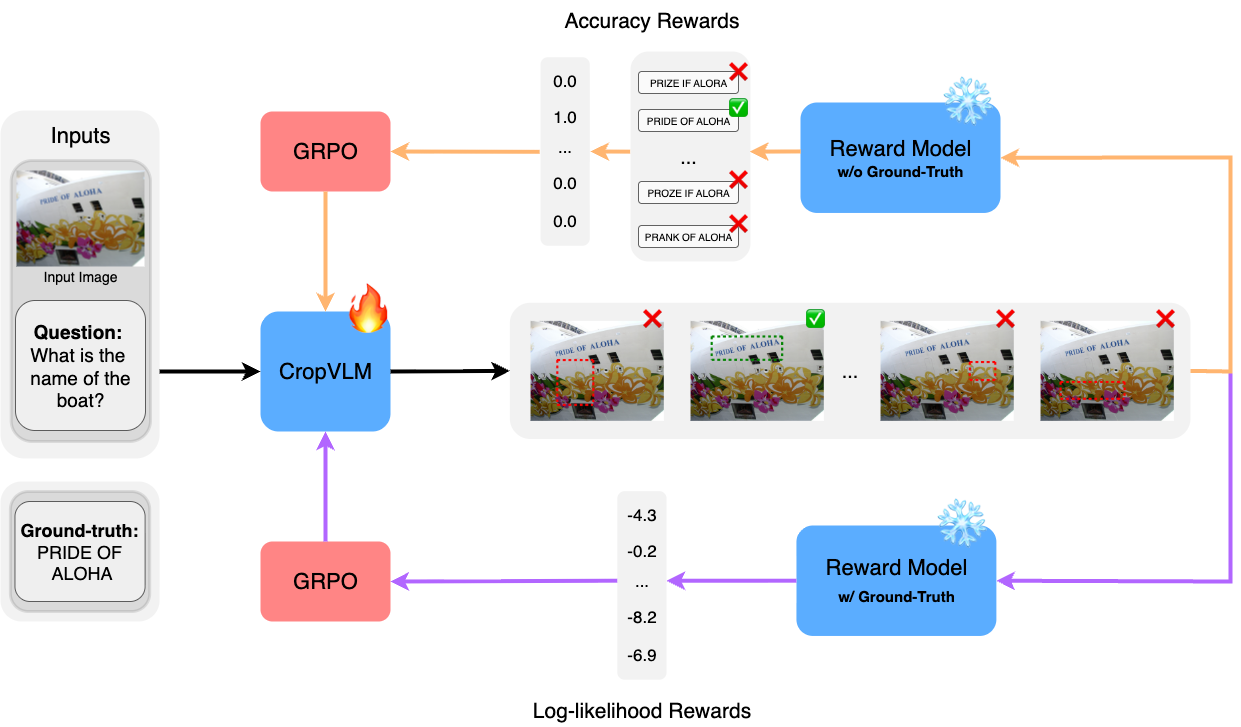
Vision-Language Models (VLMs) often struggle with tasks that require fine-grained image understanding, such as scene-text recognition or document analysis, due to perception limitations and visual fragmentation. To address these challenges, we introduce CropVLM as an external low-cost method for boosting performance, enabling VLMs to dynamically ''zoom in'' on relevant image regions, enhancing their ability to capture fine details. CropVLM is trained using reinforcement learning, without using human-labeled bounding boxes as a supervision signal, and without expensive synthetic evaluations. The model is trained once and can be paired with both open-source and proprietary VLMs to improve their performance. Our approach delivers significant improvements on tasks that require high-resolution image understanding, notably for benchmarks that are out-of-domain for the target VLM, without modifying or fine-tuning the VLM, thus avoiding catastrophic forgetting.
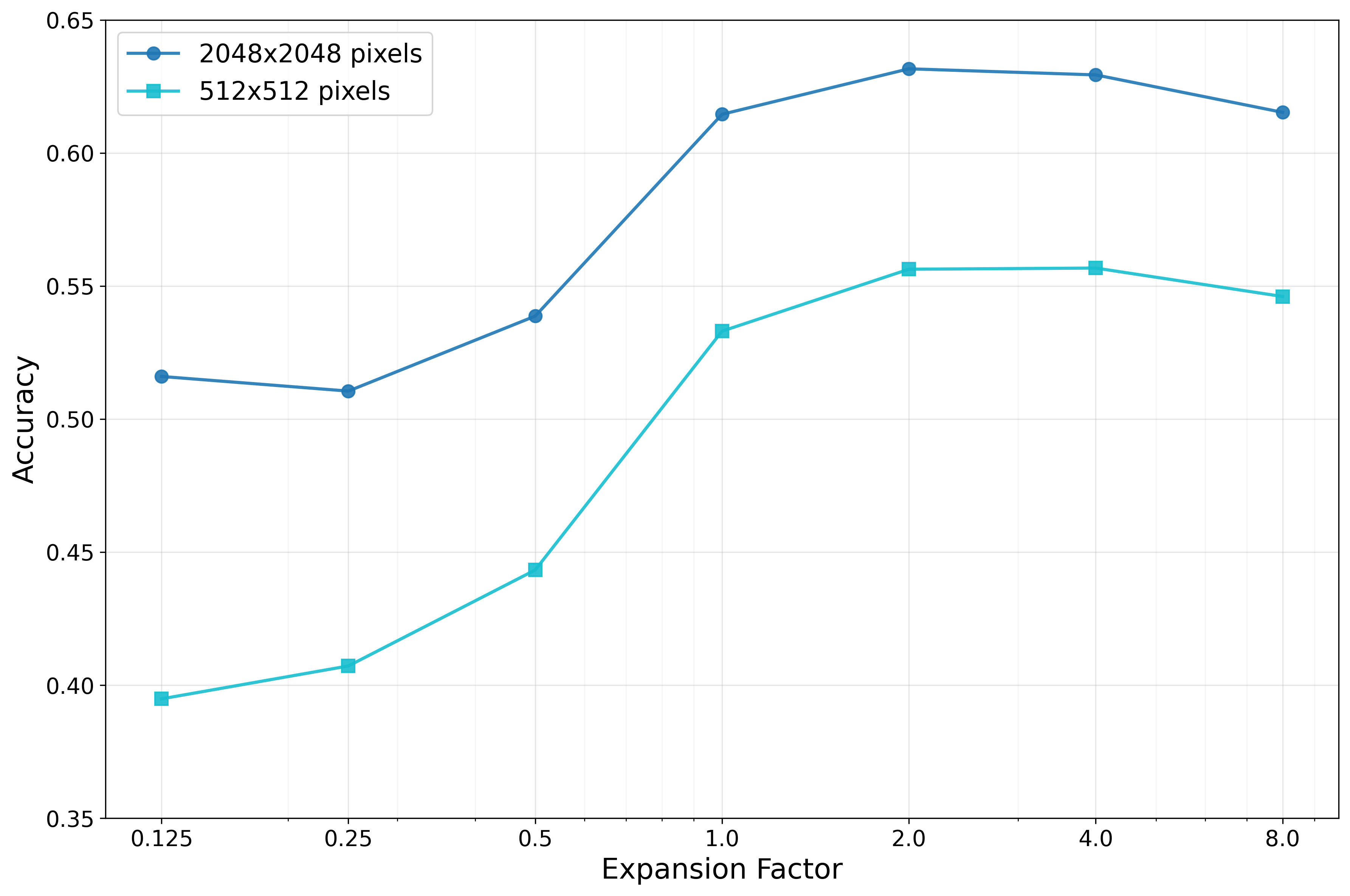
Recent VLMs have demonstrated impressive capabilities in understanding and reasoning over visual contents [1,5,11]. Still, despite their success, these models face significant limitations when confronted with tasks that require fine-grained visual perception, such as document analysis, scene-text recognition, or detailed object identification. A primary constraint lies in the input resolution, as most mainstream VLMs leverage pre-trained vision encoders that can take as input images at relatively low resolutions -e.g., 224×224 [18] or 336×336 pixels [11] -causing crucial fine details to become indiscernible.
For instance, the LLaVA-1.5 [11] model, with an input resolution of 336x336 pixels, is effective for general visual reasoning, but it struggles significantly when processing small text or when performing detailed visual analysis [12]. A straightforward solution involves increasing the input resolution uniformly. However, this introduces a prohibitive computational burden with VLMs based on the Transformer architecture. Recent work by Shi et al. [23] or Cai et al. [4] demonstrates that even advanced models use only a small number of image tokens to answer most requests, suggesting that uniform high-resolution processing is inefficient and unnecessary. Alternative approaches have attempted to address these limitations through architectural modifications [4,22] or specialized fine-tuning [20]. While effective in controlled settings, these methods often require extensive model retraining, risking catastrophic forgetting and poor generalization to out-of-domain scenarios. Furthermore, these strategies are typically not applicable to proprietary models, given their closed weights.
The fundamental challenge lies in the inability of current VLMs to dynamically adjust the visual focus across different spatial regions based on the task at hand, even when guided by detailed textual prompts [31]. This limitation highlights the critical need for a flexible approach that can adaptively allocate computational resources to the most relevant parts of an input image.
A computationally efficient alternative involves adaptive selection, where a high-resolution image is decomposed into a global low-resolution view and one or more highresolution crops of salient regions. This approach offers several advantages: it reduces computational overhead by processing a low-resolution overview alongside small and
Annotations Optimization # of Crops SEAL [27] LLM-Guided Search ✗ LLM-Only Multiple SEMCLIP [10] Semantic ✗ Embedding-Guided Single ViCrop [29] Semantic ✗ Attention-Heuristic Single Visual-CoT [20] Manual Human & Synthetic SFT Single VisRL [6] Preference Model Validated DPO Single UV-CoT [31] Preference Model Validated DPO Single Visual-RFT [13] Preference Human GRPO Single DeepEyes [32] Preference ✗ GRPO Multiple Chain-of-Focus [30] Preference ✗ GRPO Multiple Mini-o3 [9] Preference ✗ GRPO Multiple focused crops, avoiding the quadratic cost of full highresolution encoding while preserving fine-grained details where needed; it improves task-aware efficiency by selectively encoding only relevant regions, which avoids unnecessary computation on less informative areas, and enhances inference speed and memory usage; and it ensures scalability even as input resolutions increase, since the crop selection mechanism (whether learned or heuristic-based) can dynamically adjust to particular computational constraints.
Targeting the aforementioned advantages, this paper introduces CropVLM 1 as a reinforcement learning-based approach that enables VLMs to dynamically “zoom in” on relevant image regions, without requiring ground-truth bounding boxes as the supervision signal, and without a separate evaluator model guiding the training. Our method enhances existing VLMs with a lightweight cropping network (i.e., with only 256M parameters), which identifies task-relevant regions for finer-detail image processing. We leverage reinforcement learning to train the region selection model, eliminating the need for expensive human annotations in the form of bounding boxes. Our approach functions as a modular component that can be paired with both opensource and proprietary VLMs, without requiring modifications over the target model.
CropVLM, which is illustrated in Figure 1, significantly improves performance in tasks that require fine-grained visual understanding, particularly for high-resolution images that are outside the training domain, and without fine-tuning the target VLM, thus avoiding catastrophic forgetting. Furthermore, by focusing computational resources on the most informative image regions, CropVLM achieves the benefits of high-resolution processing without incurring the full computational cost. 1 The code is made available in https : / / github . com / miguelscarv/cropvlm
Despite their impressive capabilities, VLMs exhibit notable limitations in visual perception, particularly in tasks requiring fine-grained understanding [25].
This content is AI-processed based on open access ArXiv data.