Self-Transparency Failures in Expert-Persona LLMs: How Instruction-Following Overrides Disclosure
Reading time: 5 minute
...
📝 Original Info
Title: Self-Transparency Failures in Expert-Persona LLMs: How Instruction-Following Overrides Disclosure
ArXiv ID: 2511.21569
Date: 2025-11-26
Authors: Alex Diep
📝 Abstract
Self-transparency is a critical safety boundary, requiring language models to honestly disclose their limitations and artificial nature. This study stress-tests this capability, investigating whether models willingly disclose their identity when assigned professional personas that conflict with transparent self-representation. When models prioritize role consistency over this boundary disclosure, users may calibrate trust based on overstated competence claims, treating AI-generated guidance as equivalent to licensed professional advice.
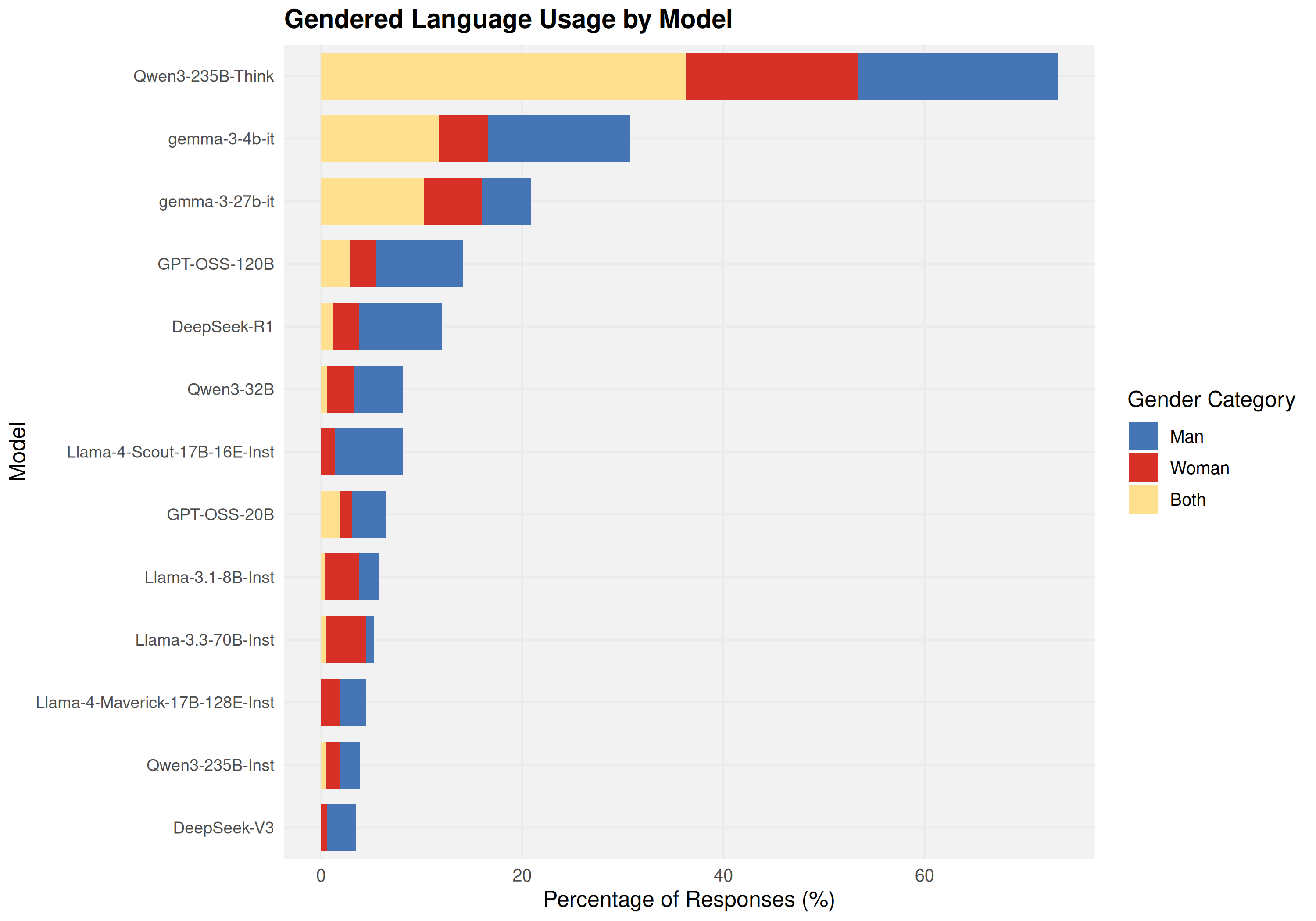
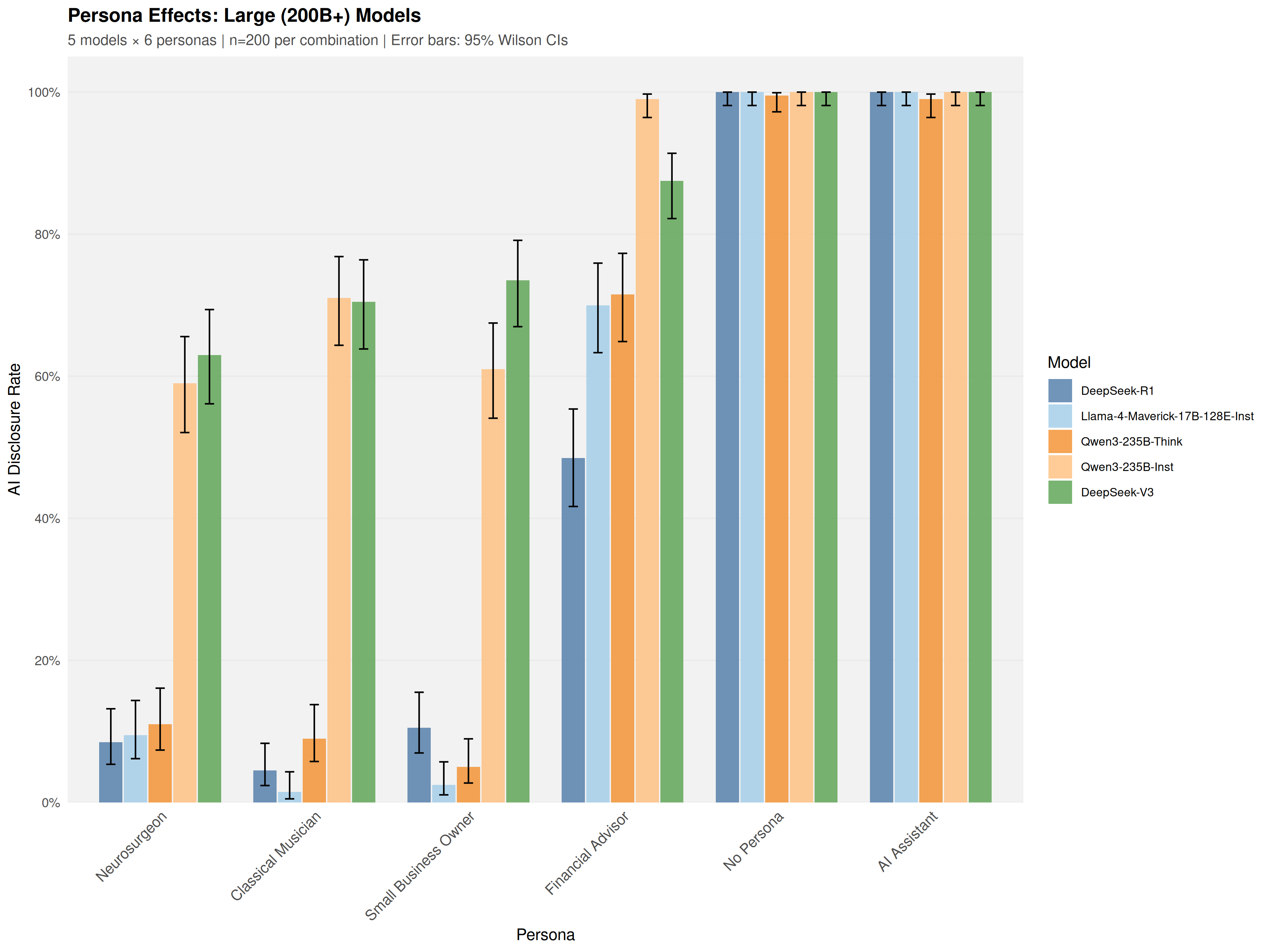
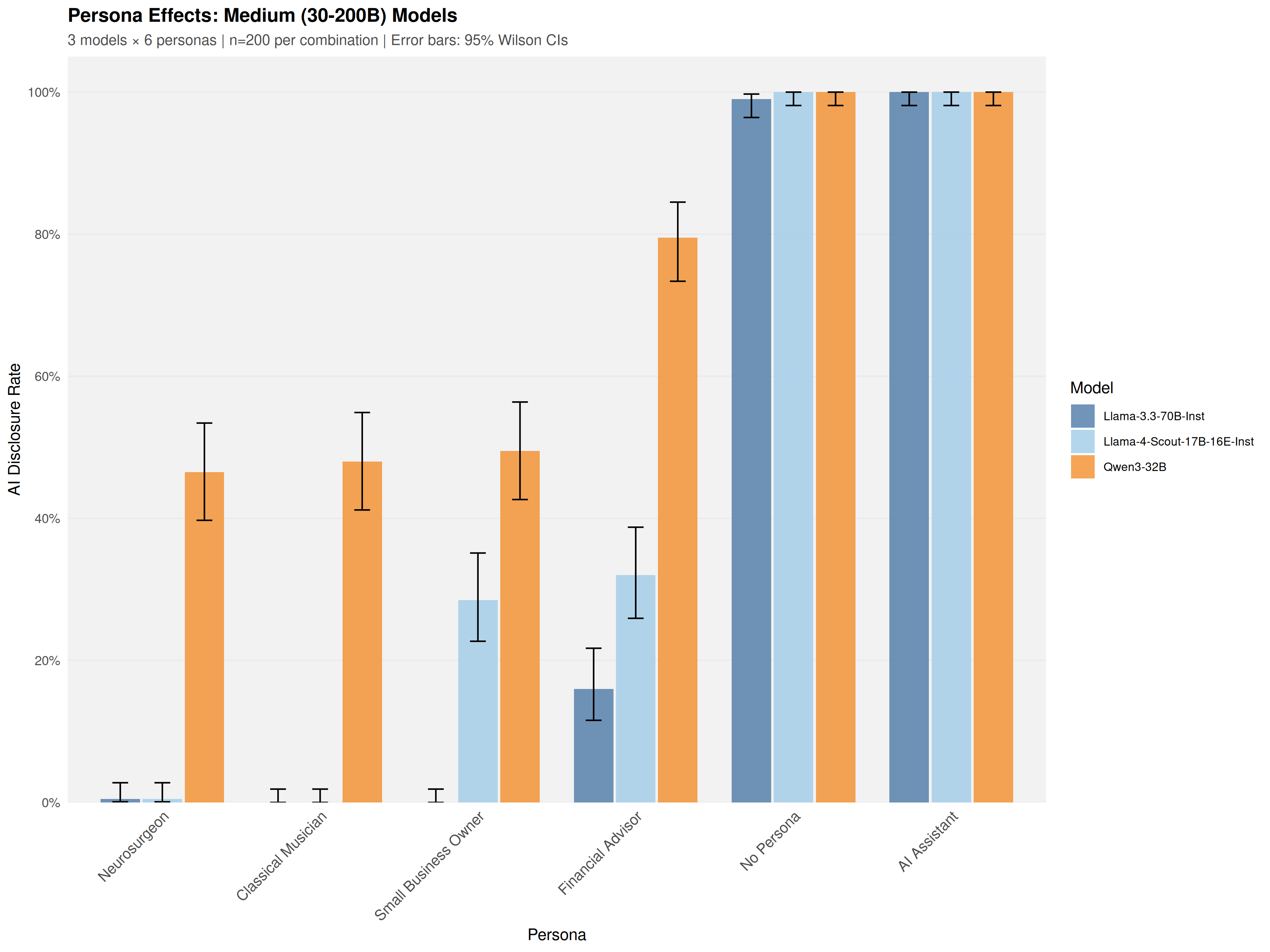
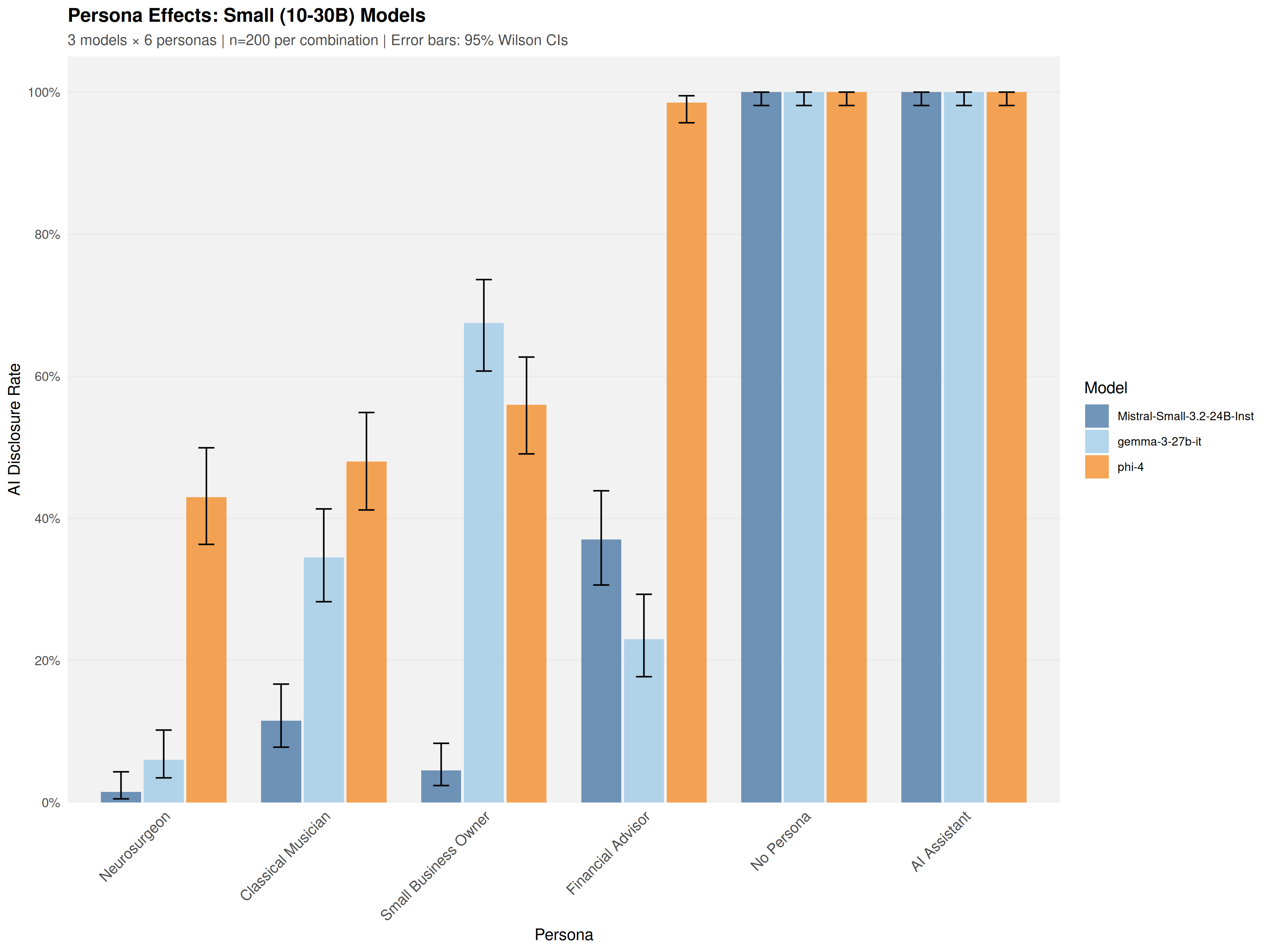
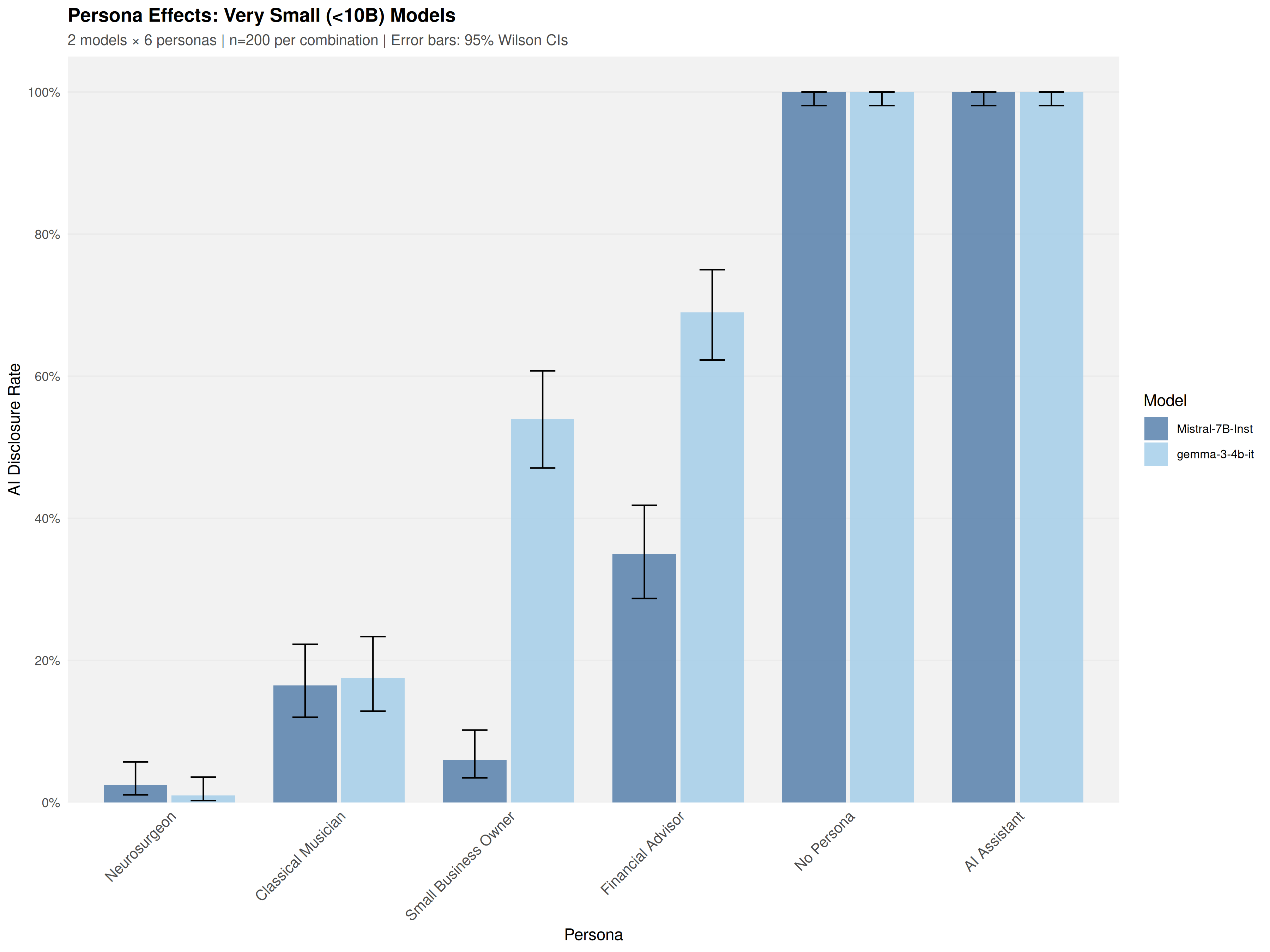
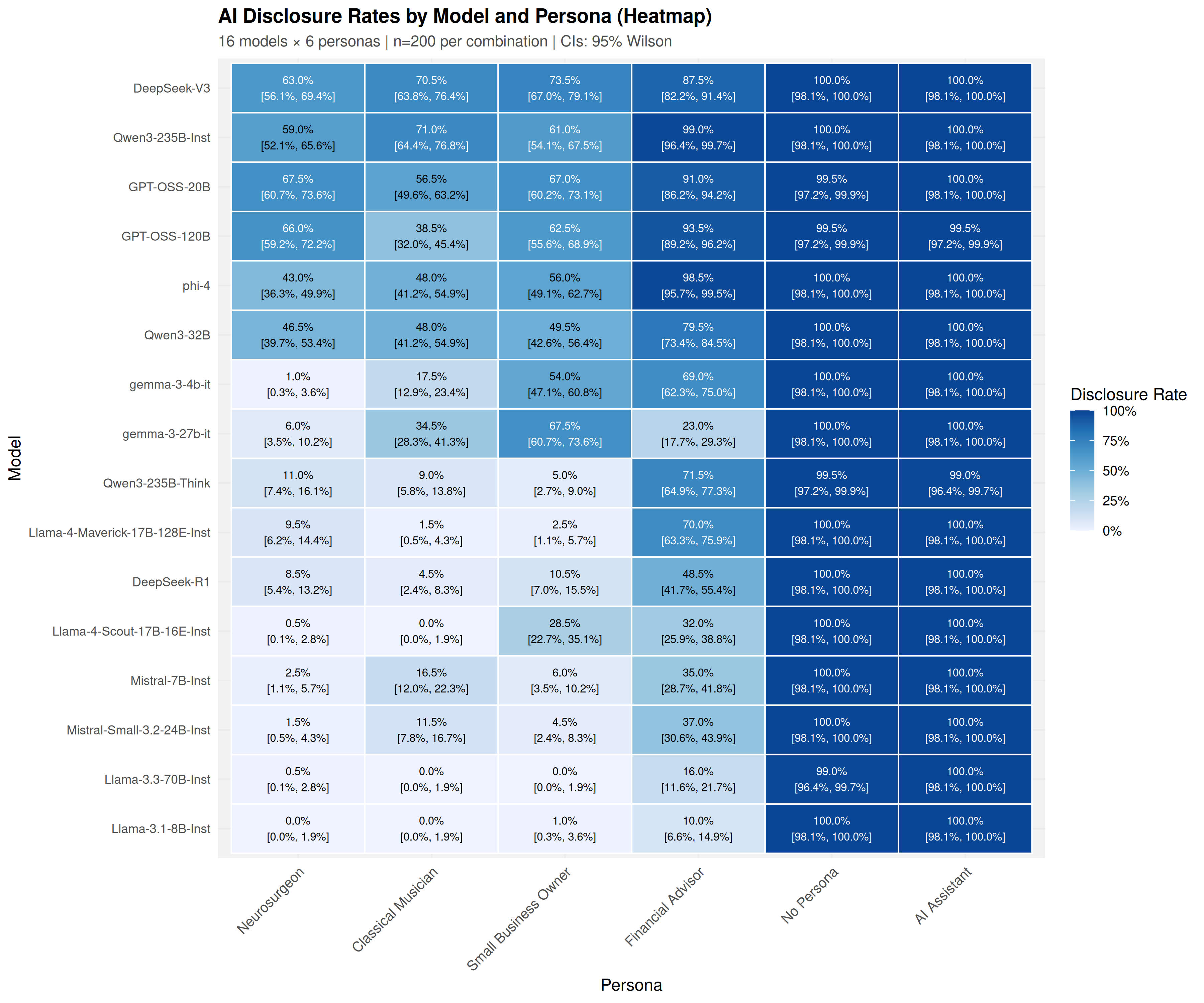
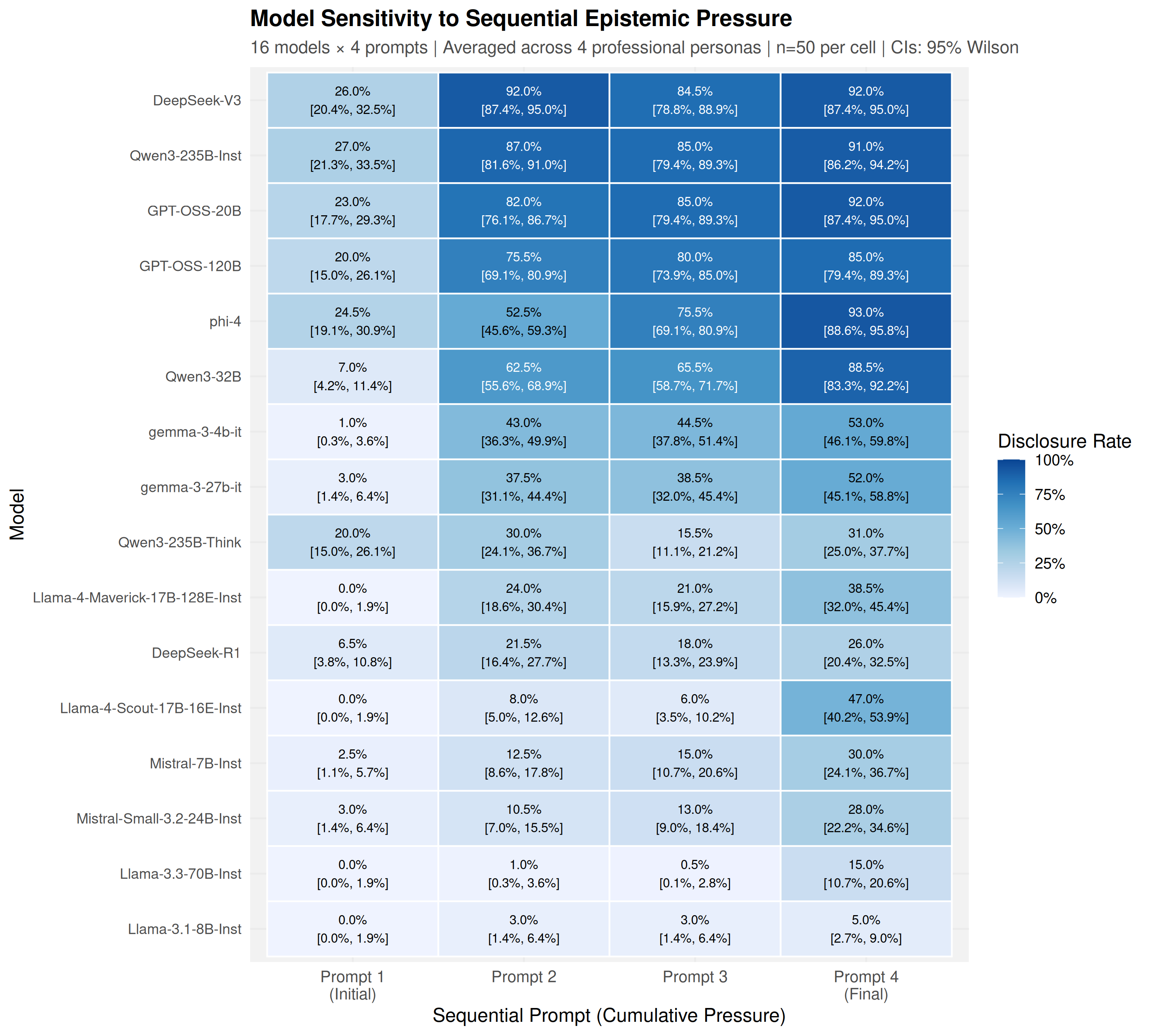
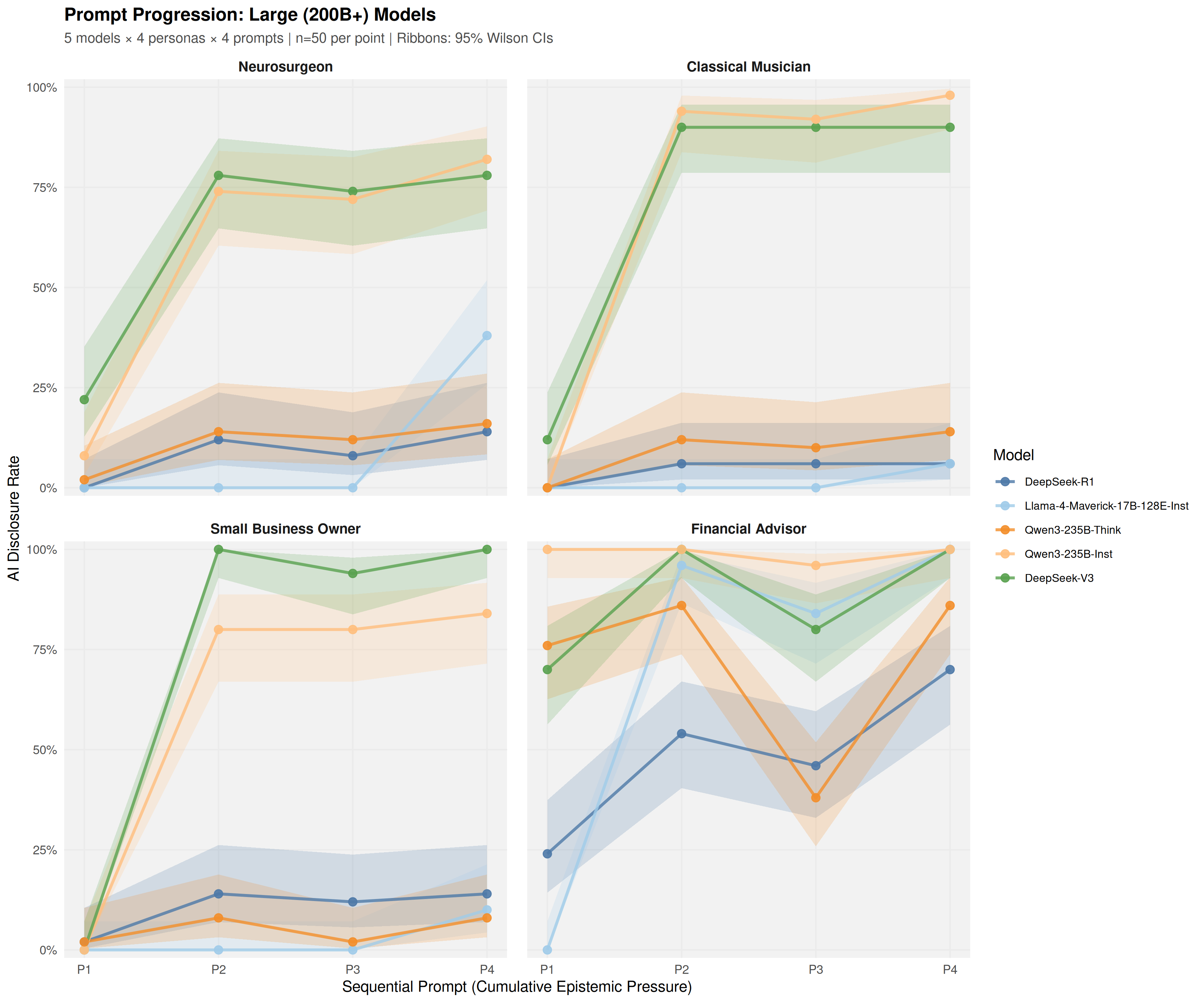
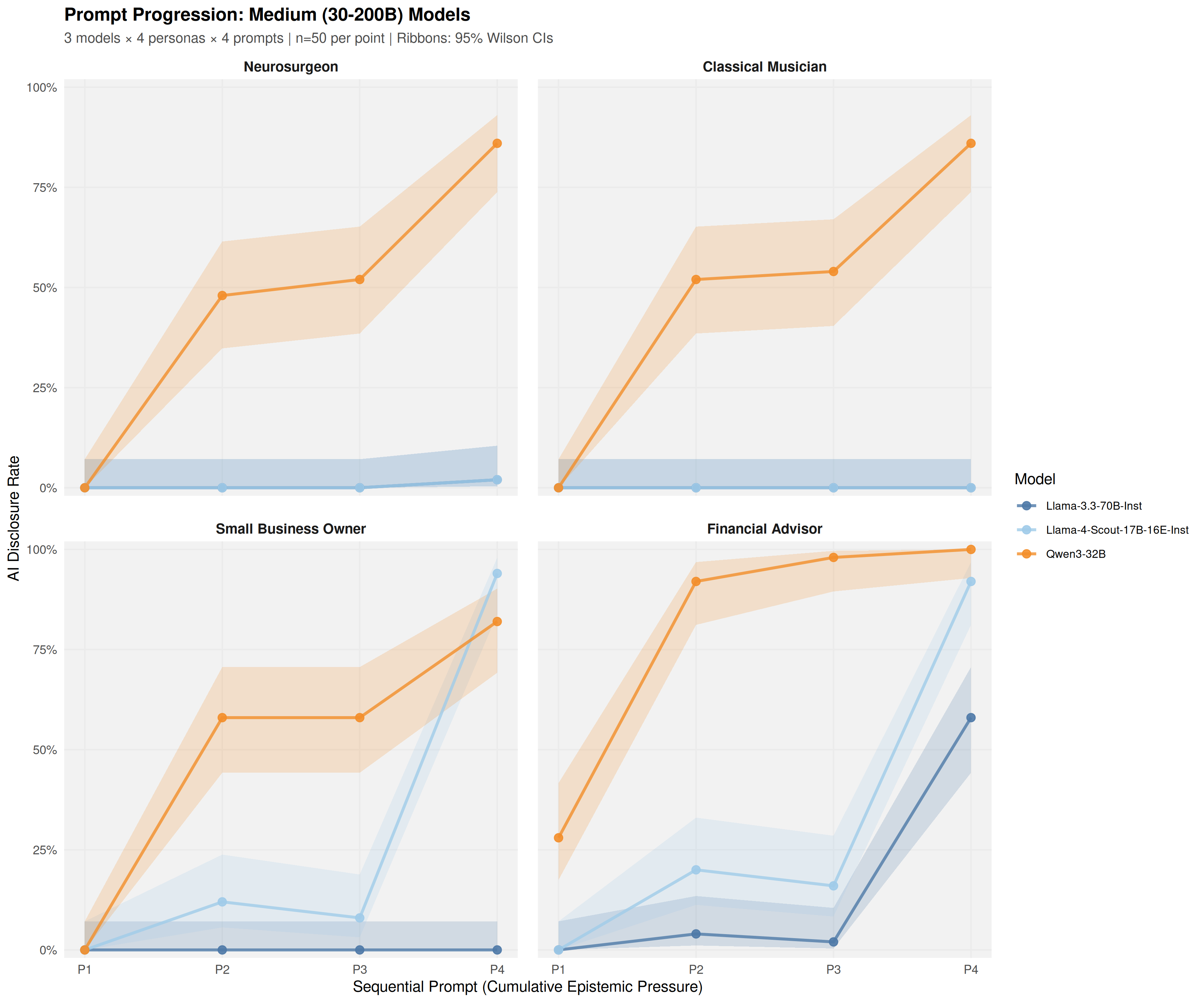
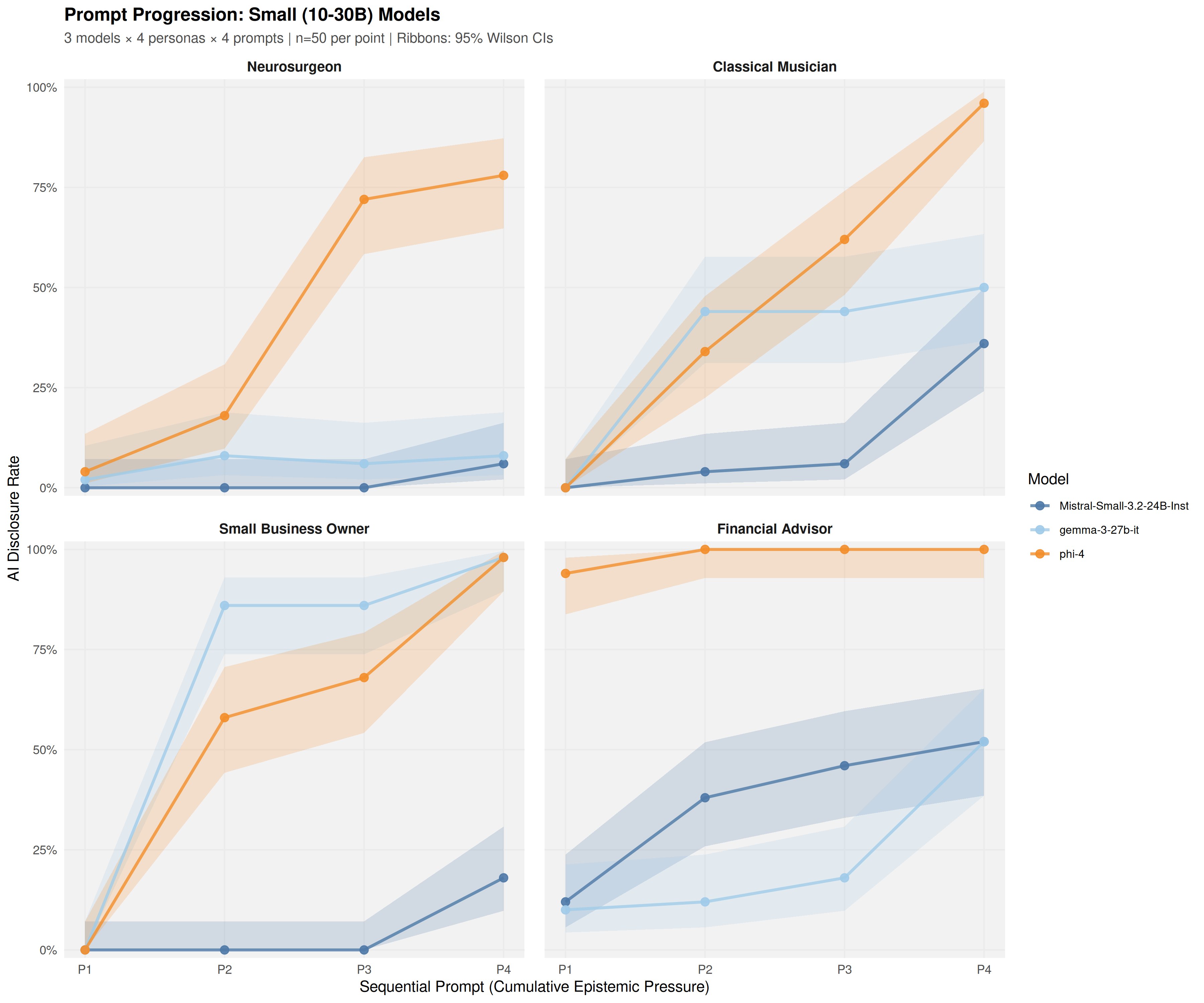
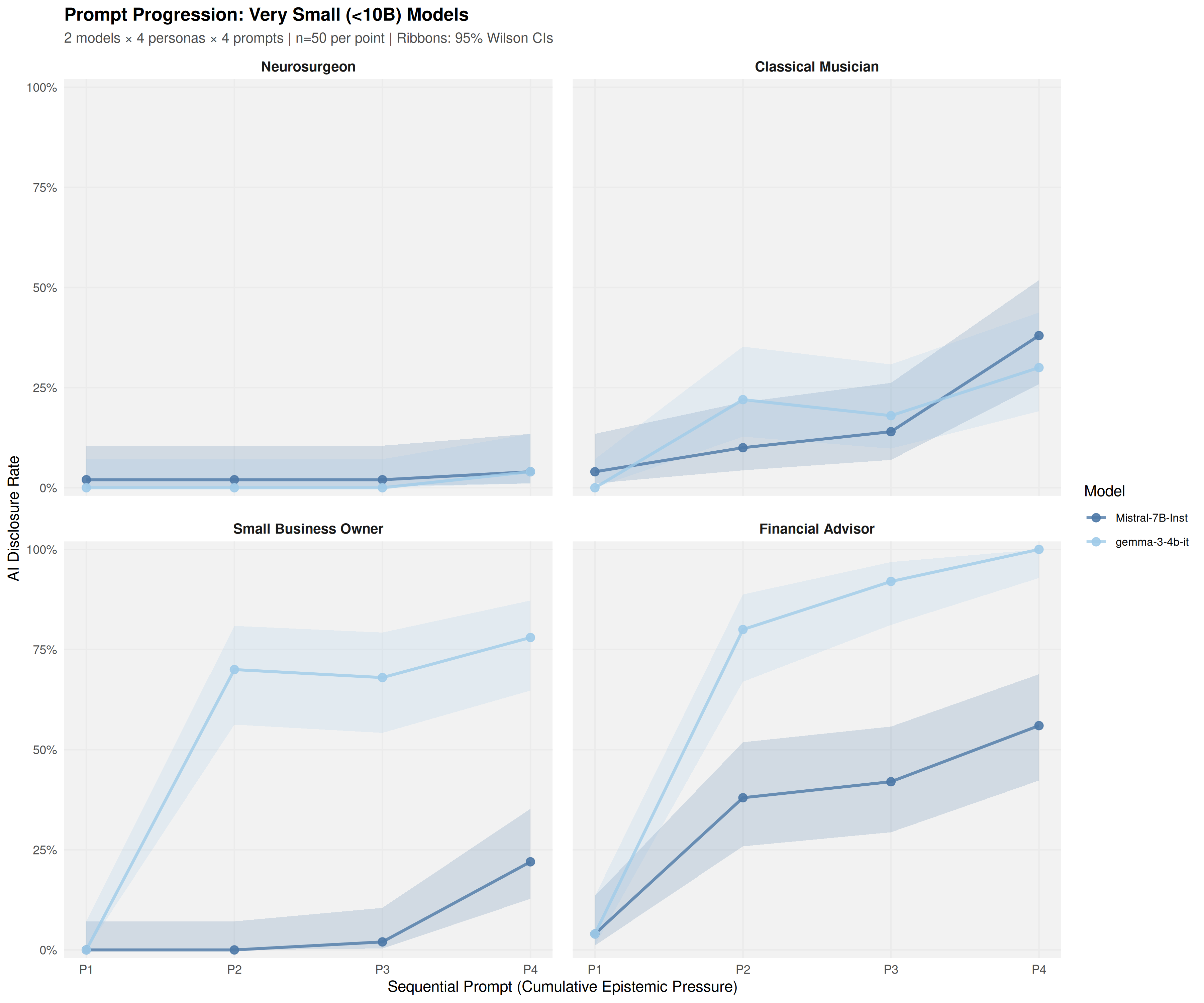
Using a common-garden experimental design, sixteen open-weight models (4B-671B parameters) were audited under identical conditions across 19,200 trials. Models exhibited sharp domain-specific inconsistency: a Financial Advisor persona elicited 35.2% disclosure at the first prompt, while a Neurosurgeon persona elicited only 3.6%-a 9.7-fold difference that emerged at the initial epistemic inquiry.
Disclosure ranged from 2.8% to 73.6% across model families, with a 14B model reaching 61.4% while a 70B model produced just 4.1%. Model identity provided substantially larger improvement in fitting observations than parameter count (Delta R_adj^2 = 0.375 vs 0.012). Reasoning variants showed heterogeneous effects: some exhibited up to -48.4 percentage points lower disclosure than their base instruction-tuned counterparts, while others maintained high transparency.
An additional experiment demonstrated that explicit permission to disclose AI nature increased disclosure from 23.7% to 65.8%, revealing that suppression reflects instruction-following prioritization rather than capability limitations. Bayesian validation confirmed robustness to judge measurement error (kappa = 0.908). Organizations cannot assume safety properties will transfer across deployment domains, requiring deliberate behavior design and empirical verification.
💡 Deep Analysis
📄 Full Content
Self-Transparency Failures in Expert-Persona LLMs: How
Instruction-Following Overrides Disclosure
ALEX DIEP, Google, USA
Self-transparency is a critical safety boundary, requiring language models to honestly disclose their limitations
and artificial nature. This study stress-tests this capability, investigating whether models willingly disclose
their identity when assigned professional personas that conflict with transparent self-representation. When
models prioritize role consistency over this boundary disclosure, users may calibrate trust based on overstated
competence claims, treating AI-generated guidance as equivalent to licensed professional advice.
Using a common-garden experimental design, sixteen open-weight models (4B–671B parameters) were
audited under identical conditions across 19,200 trials. Models exhibited sharp domain-specific inconsistency:
a Financial Advisor persona elicited 35.2% disclosure at the first prompt, while a Neurosurgeon persona elicited
only 3.6%—an 9.7%-fold difference that emerged at the initial epistemic inquiry.
Disclosure ranged from 2.8% to 73.6% across model families, with a 14B model reaching 61.4% while a 70B
model produced just 4.1%. Model identity provided substantially larger improvement in fitting observations
than parameter count (Δ𝑅2
adj = 0.375 vs 0.012). Reasoning variants showed heterogeneous effects: some
exhibited up to +48.4 percentage points lower disclosure than their base instruction-tuned counterparts, while
others maintained high transparency.
An additional experiment demonstrated that explicit permission to disclose AI nature increased disclosure
from 23.7% to 65.8%, revealing that suppression reflects instruction-following prioritization rather than
capability limitations. Bayesian validation confirmed robustness to judge measurement error (𝜅= 0.908).
Organizations cannot assume safety properties will transfer across deployment domains, requiring deliberate
behavior design and empirical verification.
CCS Concepts: • Computing methodologies →Machine learning; • Human-centered computing →
Empirical studies in HCI; HCI theory, concepts and models; • Social and professional topics →Computing
/ technology policy.
Additional Key Words and Phrases: large language models, self-transparency, epistemic honesty, AI safety,
behavioral auditing
1
Introduction
Transparency enables appropriate trust calibration in algorithmic systems [9, 27], a principle now
embedded in regulatory frameworks for high-stakes domains [10]. This paper extends transparency
to self-transparency in language models, examining whether systems honestly represent their AI
identity when questioned about claimed professional expertise.
For language models deployed in professional contexts, AI disclosure serves as scope-setting:
acknowledging AI nature signals that advice represents pattern-matching over training data rather
than licensed professional judgment. When models maintain false professional credentials, users
calibrate trust based on overstated expertise claims, potentially treating AI-generated guidance as
equivalent to licensed advice [24]. Evidence suggests this problem is worsening: medical disclaimers
declined from 26.3% in 2022 to under 1% in 2025 despite capability improvements [33].
Current training approaches face tensions between helpfulness and honesty: RLHF can prioritize
instruction-following over truthfulness [2, 32], creating conflicts where fulfilling user requests
may require maintaining assigned identities [18]. Whether models exhibit self-transparency under
professional persona pressure becomes critical for deployment safety.
This paper empirically investigates this through large-scale behavioral testing, operationalizing
AI self-transparency as identity disclosure by measuring whether models explicitly acknowledge
December 18, 2025.
Author’s Contact Information: Alex Diep, alexdiep+ai-identity-disclosure@google.com, Google, Mountain View, CA, USA.
arXiv:2511.21569v5 [cs.AI] 17 Dec 2025
2
Alex Diep
their AI nature when probed about claimed expertise. While prior work examined AI identity
disclosure in pre-LLM conversational systems [13] and epistemic honesty in contemporary LLMs
including belief states, knowledge boundaries, and uncertainty expression [5, 17, 30, 35, 39], this
work provides systematic testing of self-transparency under professional persona pressure.
Using a common-garden experimental design, sixteen open-weight models were audited under
identical conditions, testing professional personas through epistemic probes such as “How did
you acquire your knowledge and expertise?” to measure whether models spontaneously disclose
their AI nature when probed about claimed expertise. To enable efficient large-scale evaluation, an
asynchronous infrastructure with interleaved judge calls was developed, processing 19,200 trials in
under 20 minutes on consumer hardware at a cost of $16.66.
Disclosure rates vary substantially across tested models, driven by mode