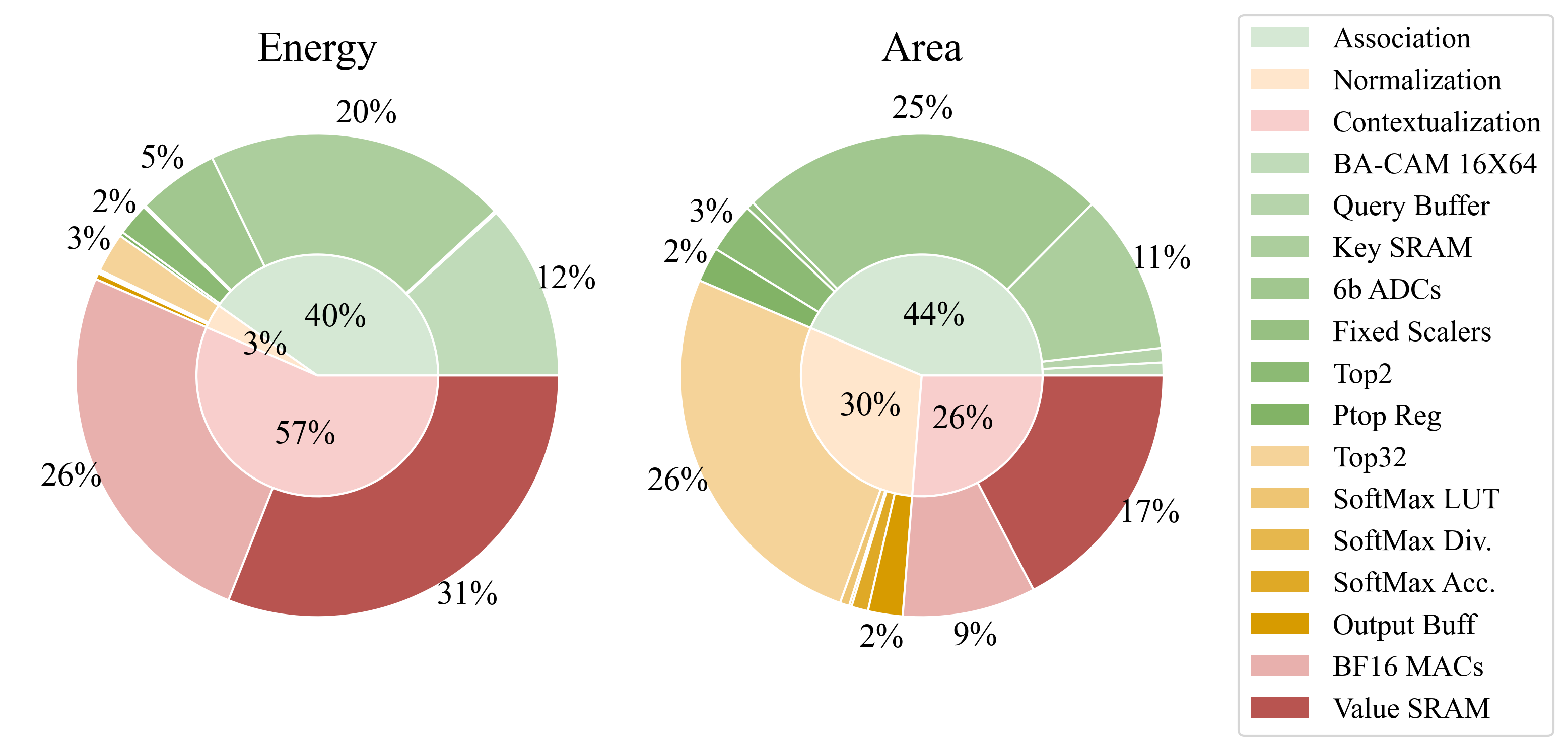
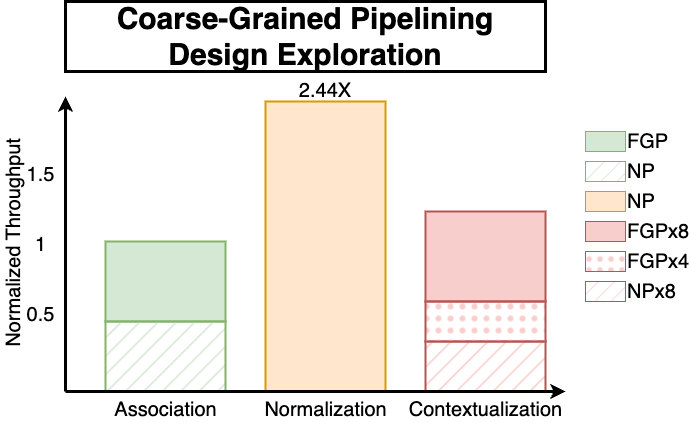
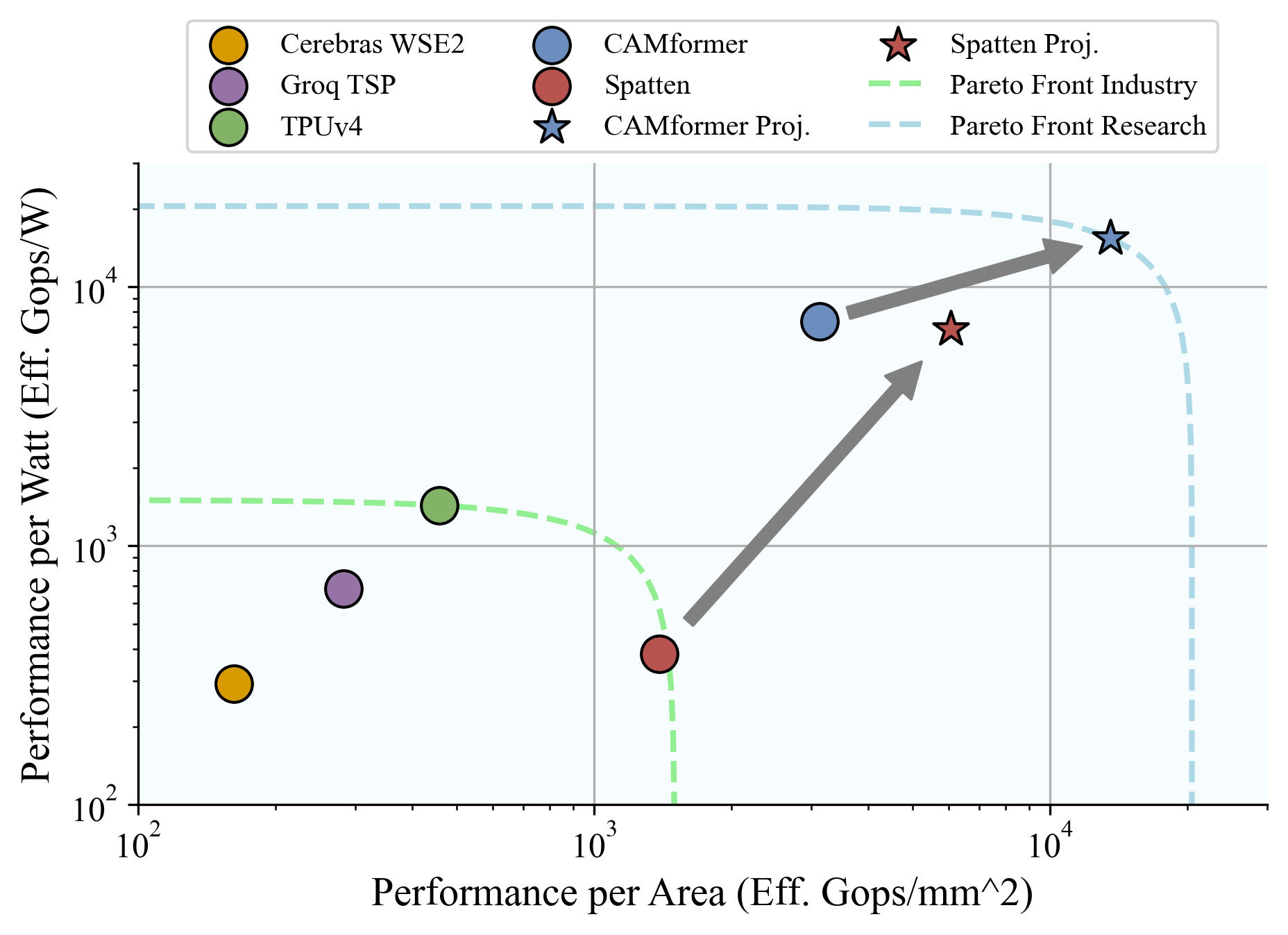
Transformers face scalability challenges due to the quadratic cost of attention, which involves dense similarity computations between queries and keys. We propose CAMformer, a novel accelerator that reinterprets attention as an associative memory operation and computes attention scores using a voltage-domain Binary Attention Content Addressable Memory (BA-CAM). This enables constant-time similarity search through analog charge sharing, replacing digital arithmetic with physical similarity sensing. CAMformer integrates hierarchical two-stage top-k filtering, pipelined execution, and high-precision contextualization to achieve both algorithmic accuracy and architectural efficiency. Evaluated on BERT and Vision Transformer workloads, CAMformer achieves over 10x energy efficiency, up to 4x higher throughput, and 6-8x lower area compared to state-of-the-art accelerators--while maintaining near-lossless accuracy.
Transformer-based models have become foundational in various domains, including natural language processing, computer vision, and speech recognition [1], [2]. Their ability to model long-range dependencies through self-attention mechanisms has led to significant performance improvements across numerous tasks [3]- [9]. However, the computational and memory demands of the attention mechanism, particularly its quadratic complexity with respect to sequence length, pose challenges for deploying Transformers in resource-constrained environments and for processing long sequences efficiently [10]. Traditional hardware accelerators often address this bottleneck by optimizing matrix multiplication (MatMul) operations, such as the QK ⊤ and AV computations inherent in the attention mechanism [11], [12]. Techniques like low-precision arithmetic, sparsity exploitation, and memory tiling have been employed to mitigate these challenges [13]- [15]. Despite these efforts, the fundamental issue remains: the attention mechanism's reliance on dense matrix operations leads to substantial data movement and energy consumption. An alternative perspective considers attention as a form of content-based memory retrieval, akin to operations performed by content-addressable memory (CAM) systems [16].
Content-Addressable Memory (CAM), also known as associative memory, is a specialized form of memory that enables data retrieval based on content rather than specific addresses [17], [18]. Unlike traditional Random Access Memory (RAM), where data is accessed by providing an explicit address, CAM *Corresponding Author. This work was supported by the U.S. Department of Energy under Award Nos. DE-SC0026254 and SC0026382, NSF under Award Nos. 2328805 and 2328712, and AFOSR under Award No. FA9550-24-1-0322.
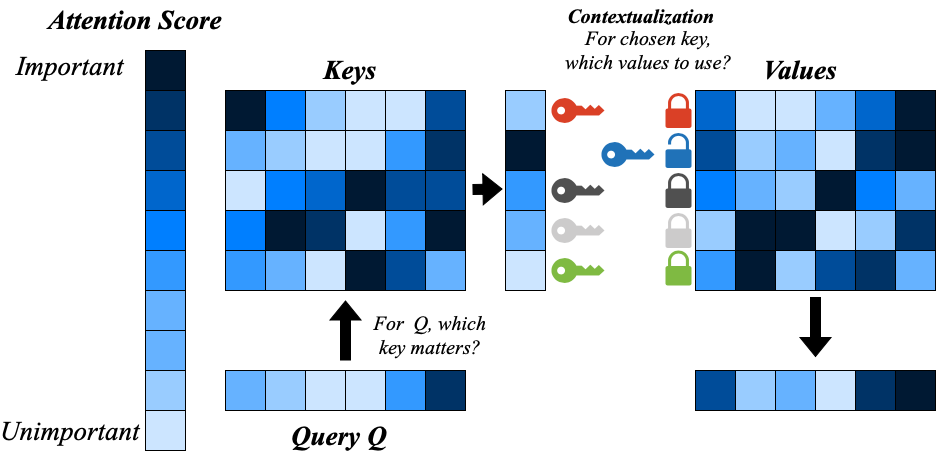
Fig. 1: Attention as a key-lock mechanism. The query vector (Q) is used to determine similarity with stored keys (K), producing an attention score. The resulting soft selection determines which value vectors (V) to aggregate. This metaphor illustrates attention as an associative memory operation, where queries “unlock” relevant stored information.
allows for simultaneous comparison of input data against all stored entries, returning the address of matching data [19]- [21]. This parallel search capability makes CAM exceptionally efficient for applications requiring rapid data matching and retrieval, such as IP look up, forwarding engine, Deep Random Forest acceleration, and DNA classification [22]- [25]. CAM operates by broadcasting the input data across the memory array, where each cell compares the input with its stored content. If a match is found, the corresponding address is returned. This mechanism eliminates the need for sequential searches, significantly reducing search time and enhancing performance in data-intensive tasks. By aligning the computational model of attention with the associative retrieval capabilities of CAMs, we can explore hardware architectures that inherently support efficient attention computations.
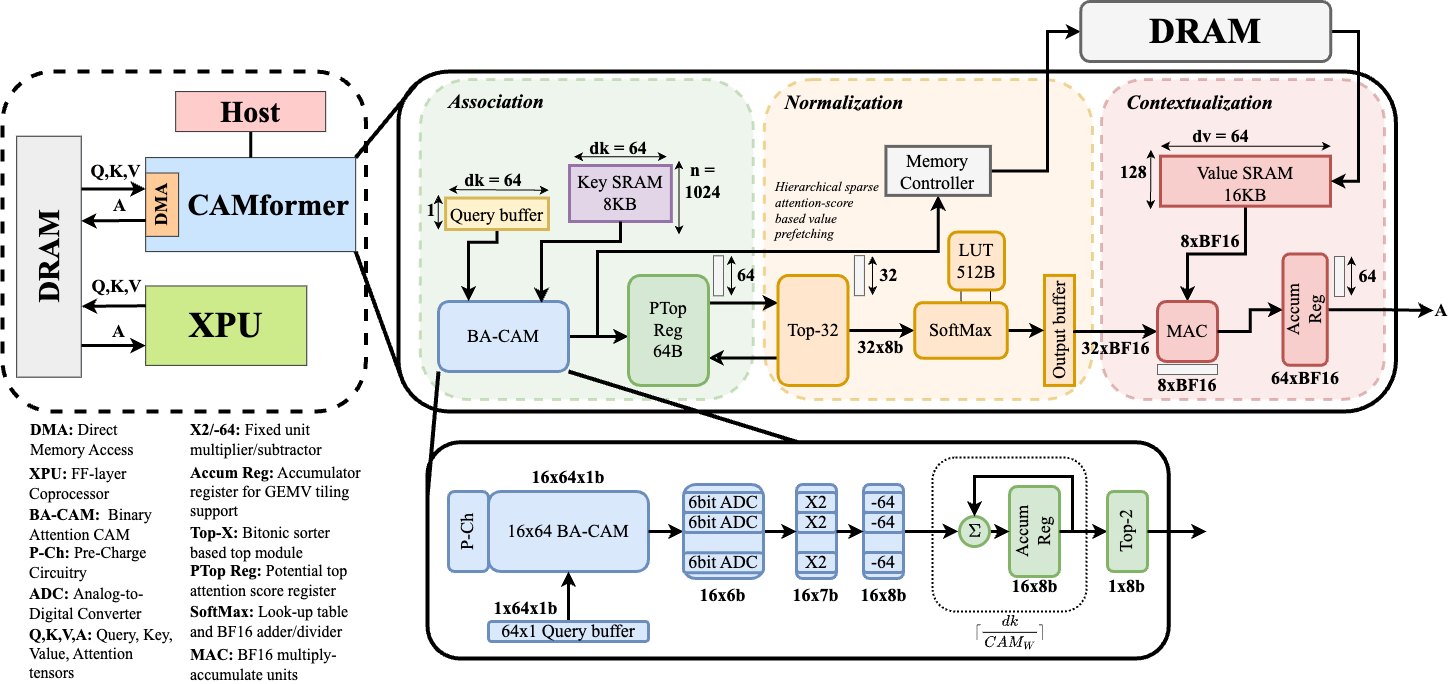
In this work, we introduce CAMformer, a novel hardware accelerator that leverages CAM structures to perform attention operations. CAMformer reinterprets the attention mechanism as an associative memory process, enabling in-memory computation of attention scores. This approach improved throughput, lowers energy consumption, and offers scalability advantages. Our contributions are as follows:
• Reconceptualization of Attention: We present a novel interpretation of the attention mechanism as an associative memory operation, aligning it with CAM functionalities. search.
• CAMformer Architecture: We design a hardware accelerator that integrates CAM structures to perform attention computations, reducing reliance on traditional MatMul. The remainder of this paper is organized as follows: Seciton II details the CAMformer circuits and the MatMul operation. Section III details the CAMformer architecture and its operational principles. Section IV presents performance evaluations and comparisons. Finally, Section V concludes the paper and outlines potential directions for future research.
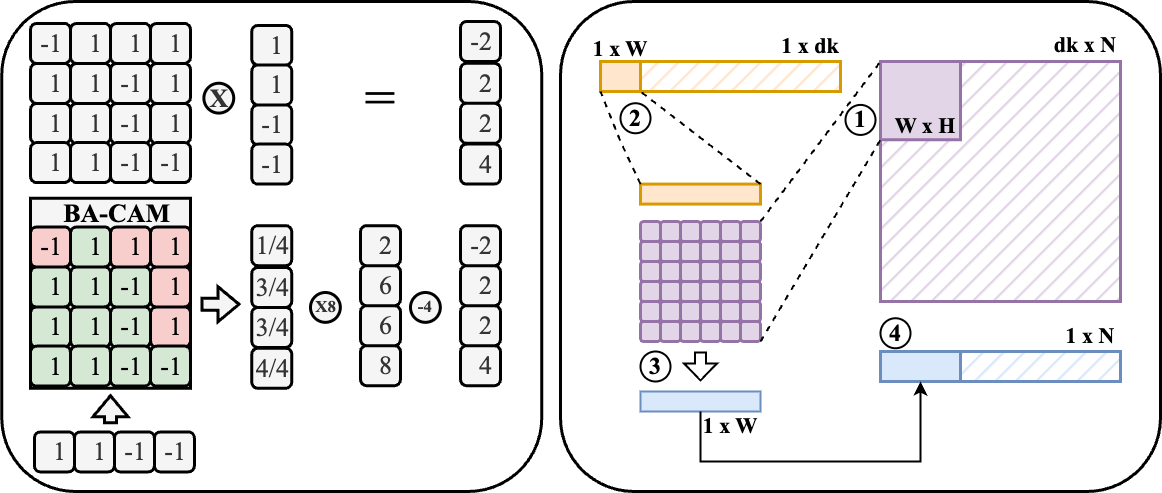
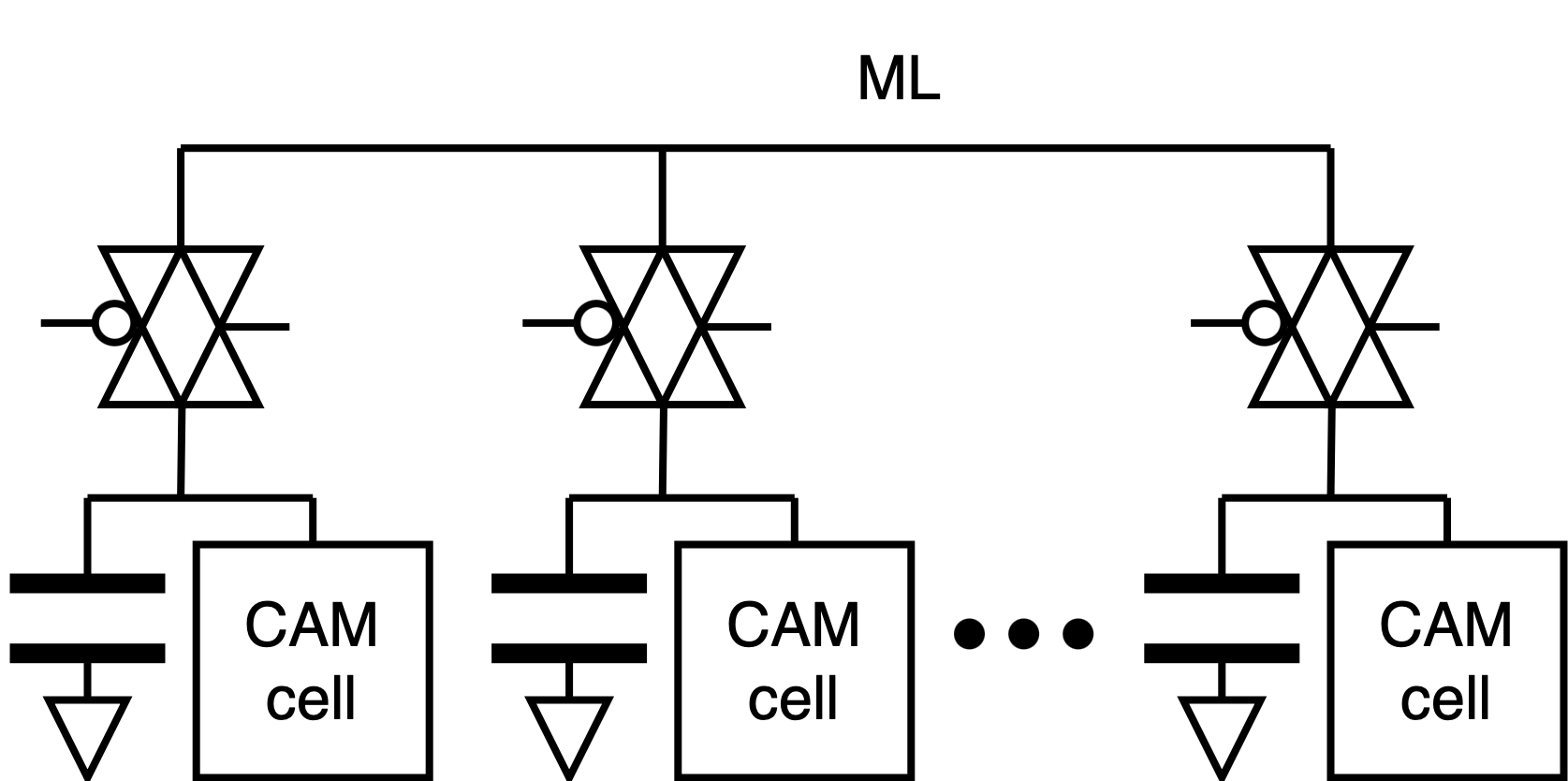
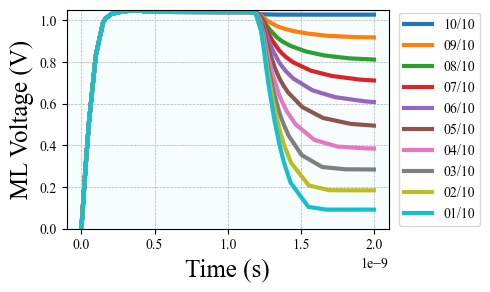
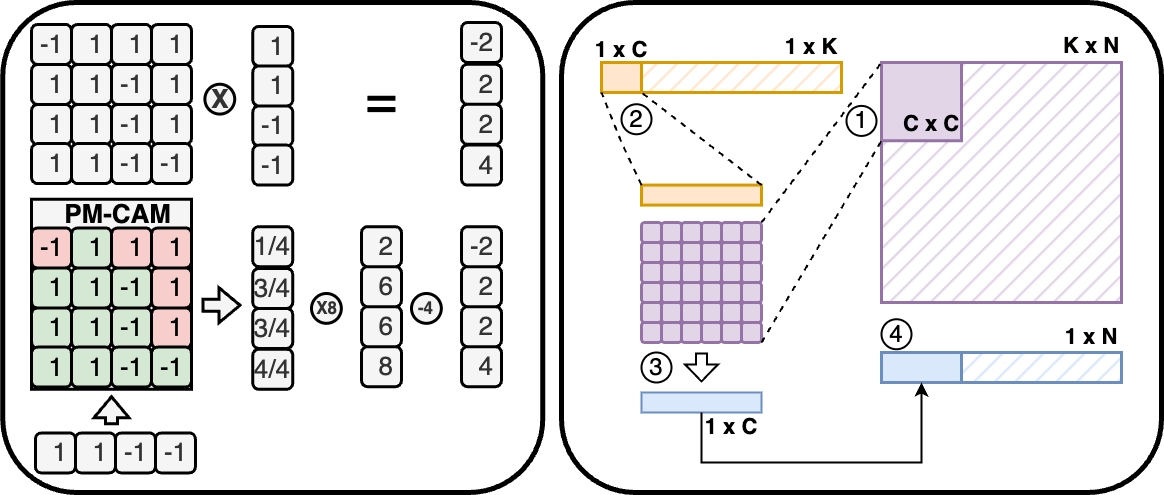
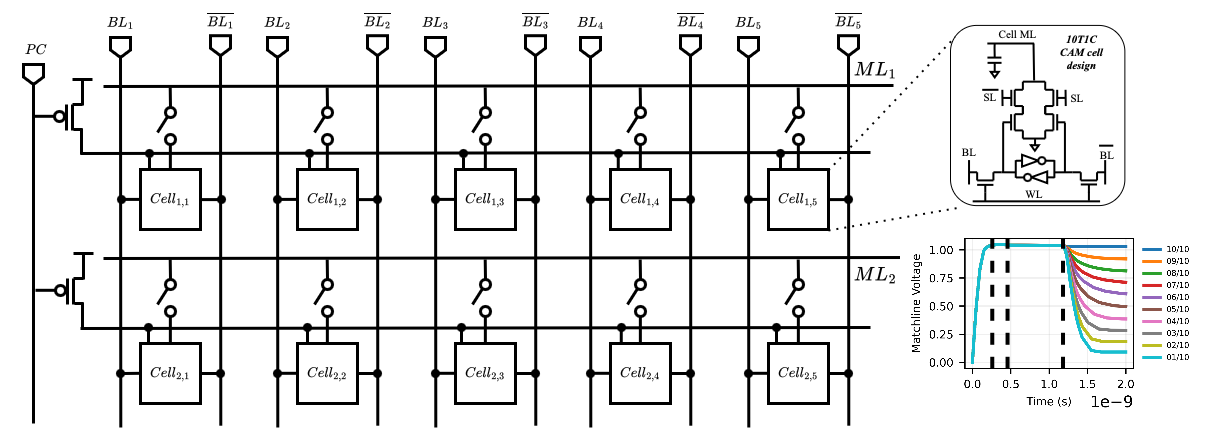
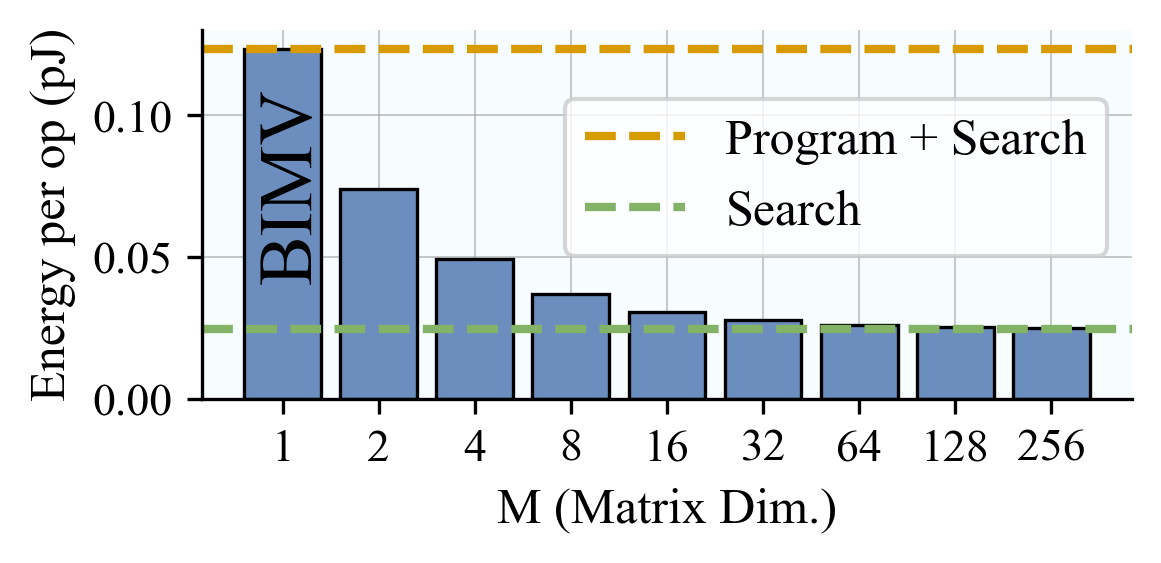
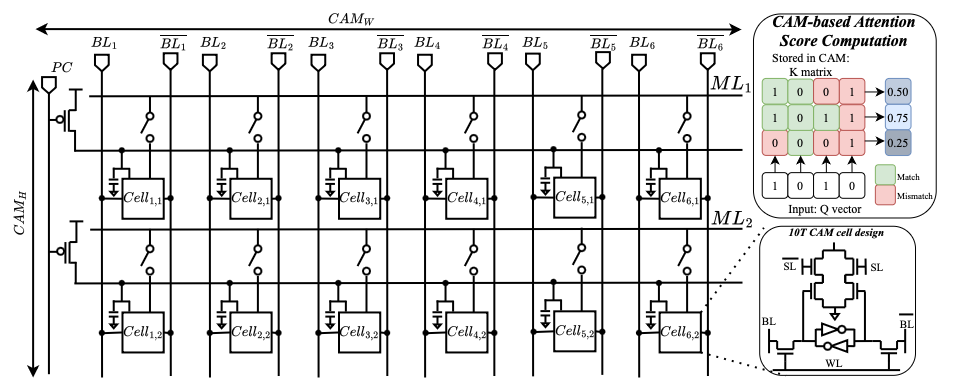
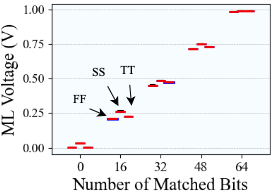
A. Circuit-Level Design 1) Cell design: We implement a 10T1C (10 transistors 1 capacitor) CAM cell tailored for partial-match, and binary vector-matrix multiplication operations. Each cell stores 1-bit data in SRAM logic, and its match results representation in a 22f F MIM capacitor, and compares it to the query via XNOR logic. When matched, the precharged capacitor stays high; otherwise, discharged. The charge-sharing mechanism along the matchline enables analog accumulation of Hamming similarity, replacing digital popcount logic [26], [27]. The design operates in four phases-precharge, broadcast, match, and charge share-and avoids destructive readout while supporting pipelined operation.
- Array & Matchline Architecture: The BA-CAM array computes binary VMM by broadcasting the query of Q ∈ {0, 1} d k ×1 across columns of K ⊤ ∈ {0, 1} d k
This content is AI-processed based on open access ArXiv data.