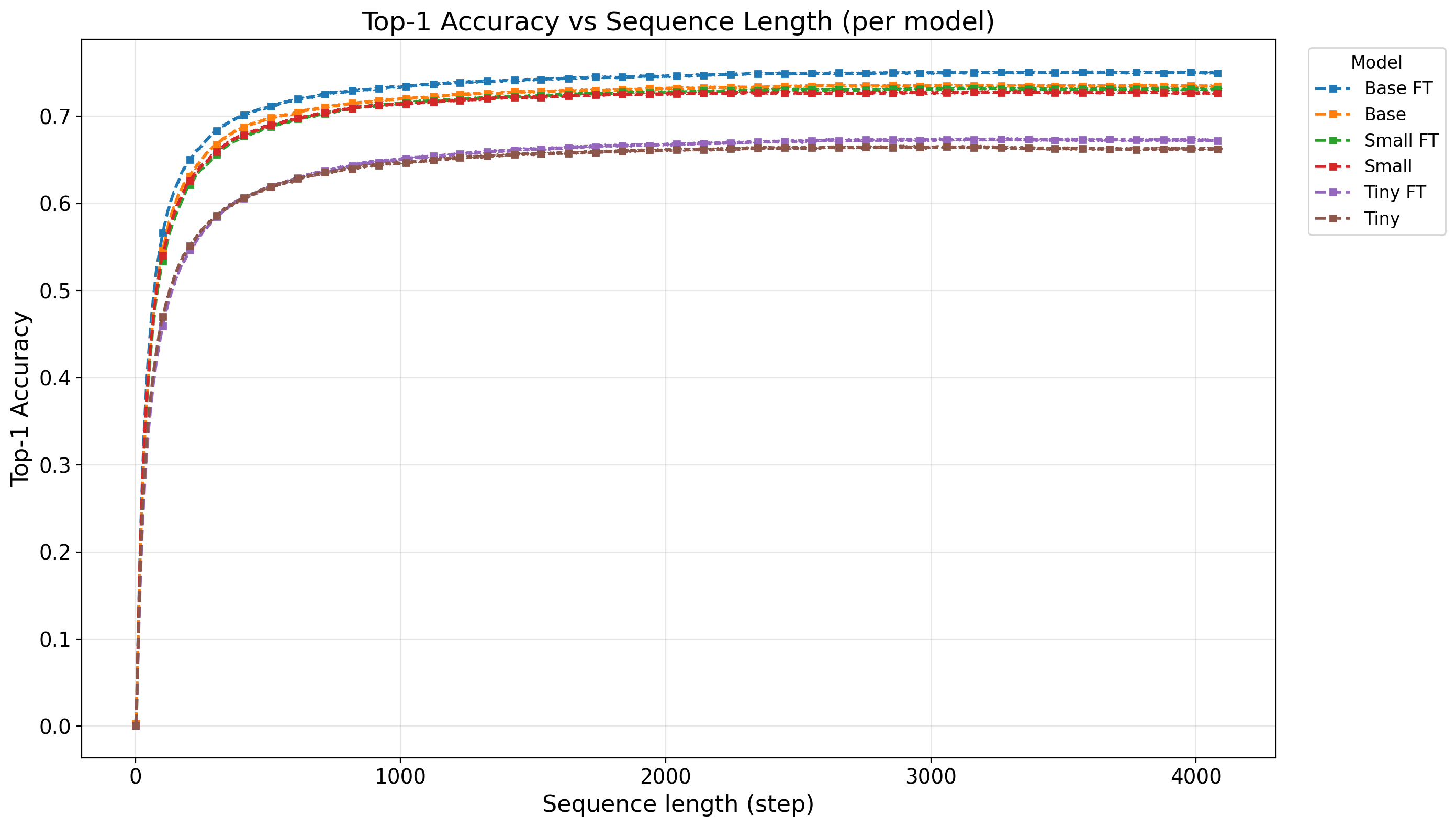
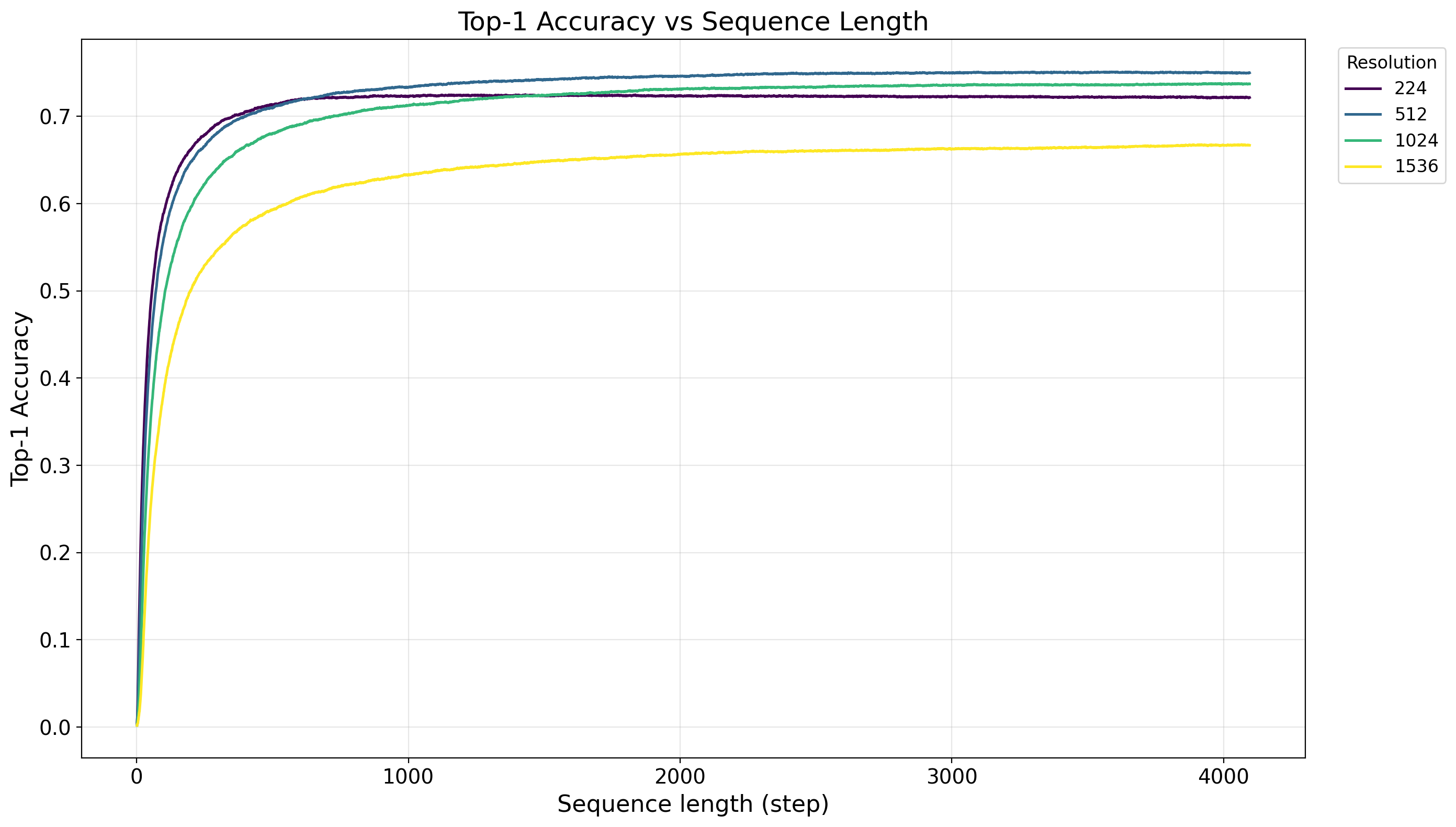
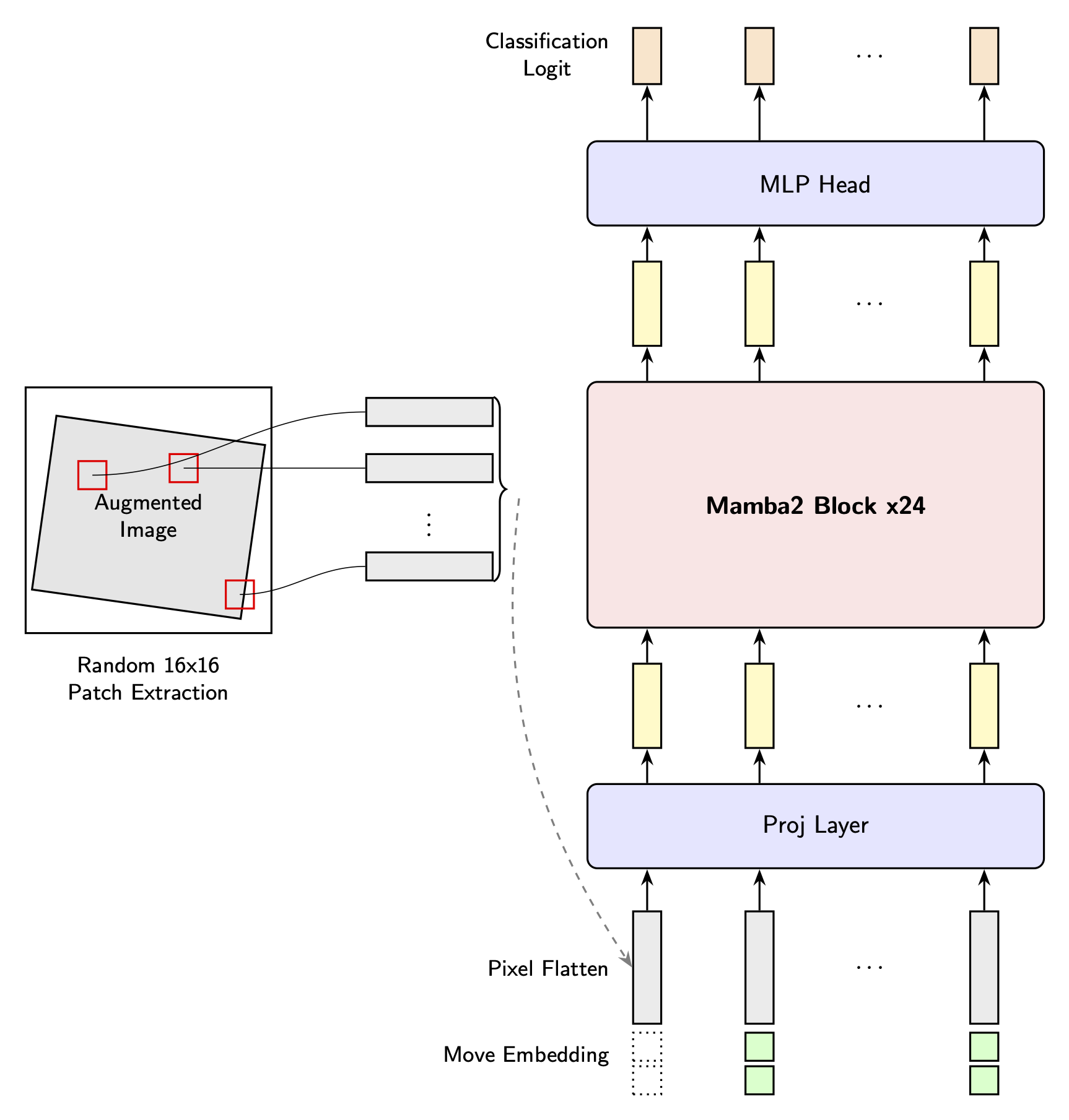
Despite decades of progress, a truly input-size agnostic visual encoder-a fundamental characteristic of human vision-has remained elusive. We address this limitation by proposing \textbf{MambaEye}, a novel, causal sequential encoder that leverages the low complexity and causal-process based pure Mamba2 backbone. Unlike previous Mamba-based vision encoders that often employ bidirectional processing, our strictly unidirectional approach preserves the inherent causality of State Space Models, enabling the model to generate a prediction at any point in its input sequence. A core innovation is our use of relative move embedding, which encodes the spatial shift between consecutive patches, providing a strong inductive bias for translation invariance and making the model inherently adaptable to arbitrary image resolutions and scanning patterns. To achieve this, we introduce a novel diffusion-inspired loss function that provides dense, step-wise supervision, training the model to build confidence as it gathers more visual evidence. We demonstrate that MambaEye exhibits robust performance across a wide range of image resolutions, especially at higher resolutions such as $1536^2$ on the ImageNet-1K classification task. This feat is achieved while maintaining linear time and memory complexity relative to the number of patches.
💡 Deep Analysis
📄 Full Content
MambaEye: A Size-Agnostic Visual Encoder with Causal Sequential Processing
Changho Choi
Korea University
changho98@korea.ac.kr
Minho Kim
MIT
lgmkim@mit.edu
Jinkyu Kim
Korea University
jinkyukim@korea.ac.kr
Abstract
Despite decades of progress, a truly input-size agnostic vi-
sual encoder—a fundamental characteristic of human vi-
sion—has remained elusive. We address this limitation by
proposing MambaEye, a novel, causal sequential encoder
that leverages the low complexity and causal-process based
pure Mamba2 backbone. Unlike previous Mamba-based vi-
sion encoders that often employ bidirectional processing,
our strictly unidirectional approach preserves the inherent
causality of State Space Models, enabling the model to gen-
erate a prediction at any point in its input sequence. A core
innovation is our use of relative move embedding, which
encodes the spatial shift between consecutive patches, pro-
viding a strong inductive bias for translation invariance and
making the model inherently adaptable to arbitrary image
resolutions and scanning patterns. To achieve this, we intro-
duce a novel diffusion-inspired loss function that provides
dense, step-wise supervision, training the model to build
confidence as it gathers more visual evidence. We demon-
strate that MambaEye exhibits robust performance across a
wide range of image resolutions, especially at higher res-
olutions such as 15362 on the ImageNet-1K classification
task. This feat is achieved while maintaining linear time
and memory complexity relative to the number of patches.
1. Introduction
A central goal in computer vision is a truly input-size ag-
nostic encoder. These encoders will ideally operate on arbi-
trary resolutions and allocates resources based on availabil-
ity, without committing to a fixed input size. While high
resolution media is becoming more common, most vision
encoders are limited on their ability to work on various in-
put dimensions. Instead, these encoders typically resize or
crop during the data piping process, incurring unavoidable
information loss which could be detrimental to the task.
The disadvantages from this lack of versatility is already
well-known in many models but is difficult to solve. Con-
volutional Neural Networks (CNNs) [8, 14], while endowed
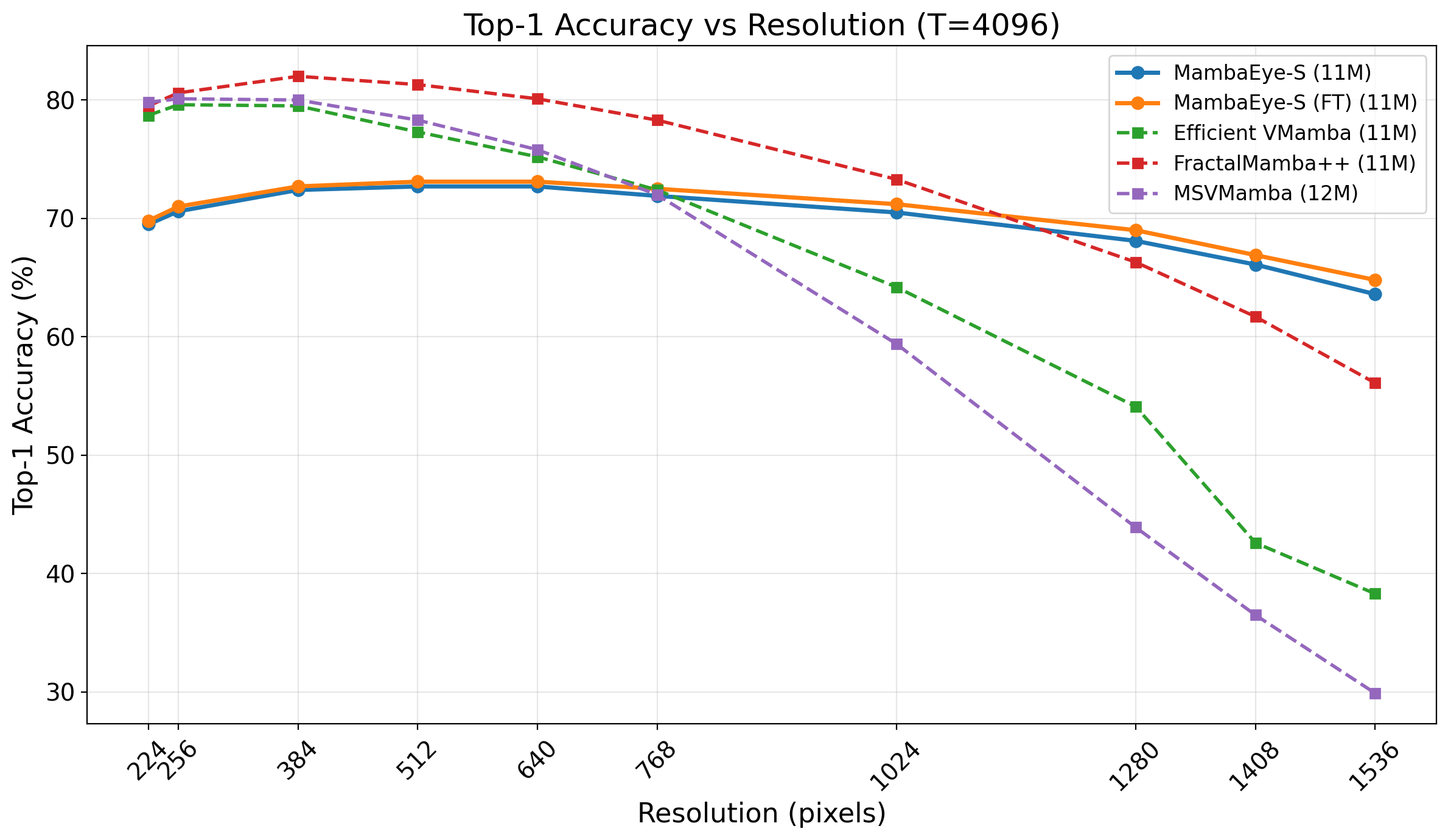
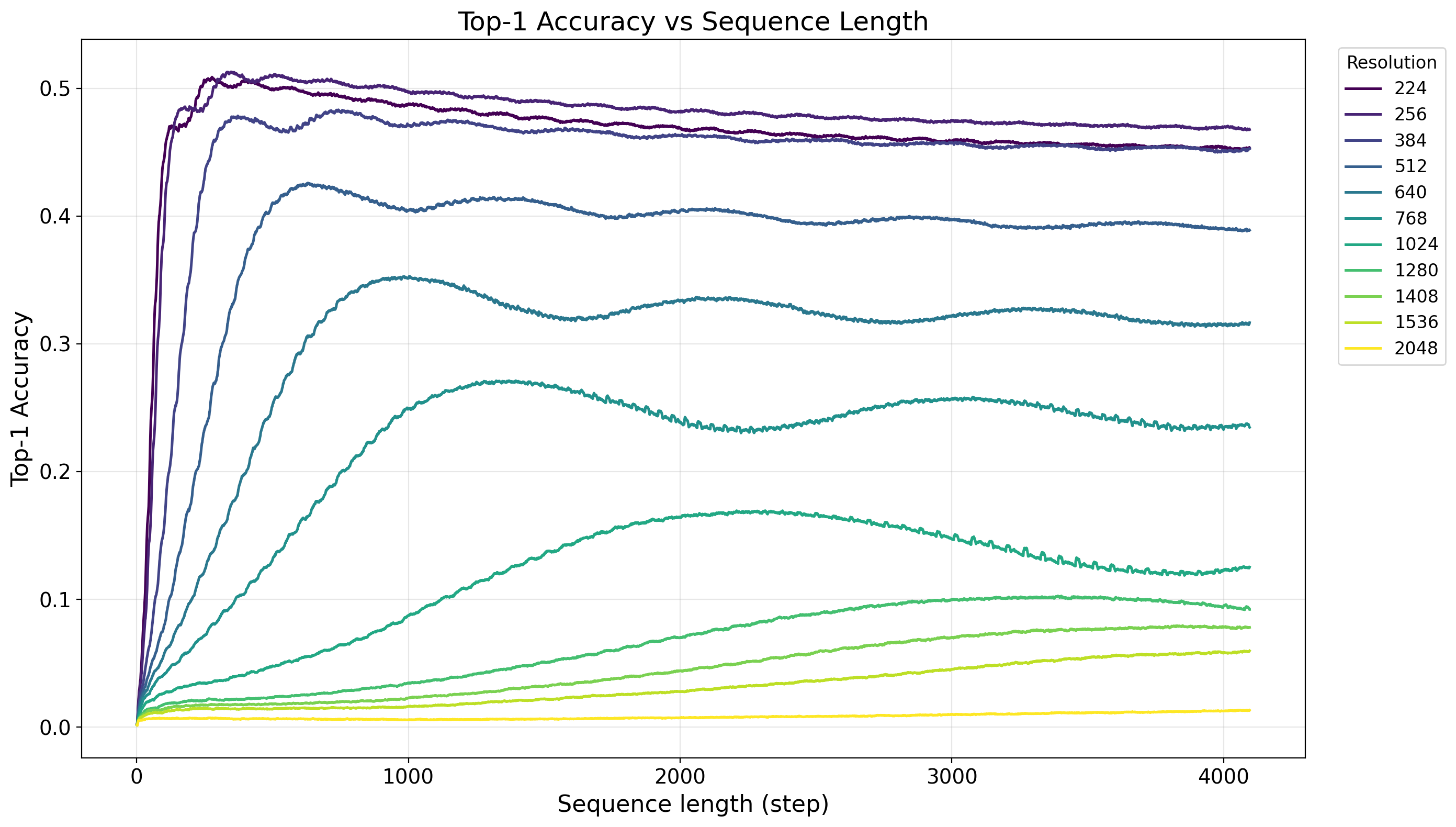
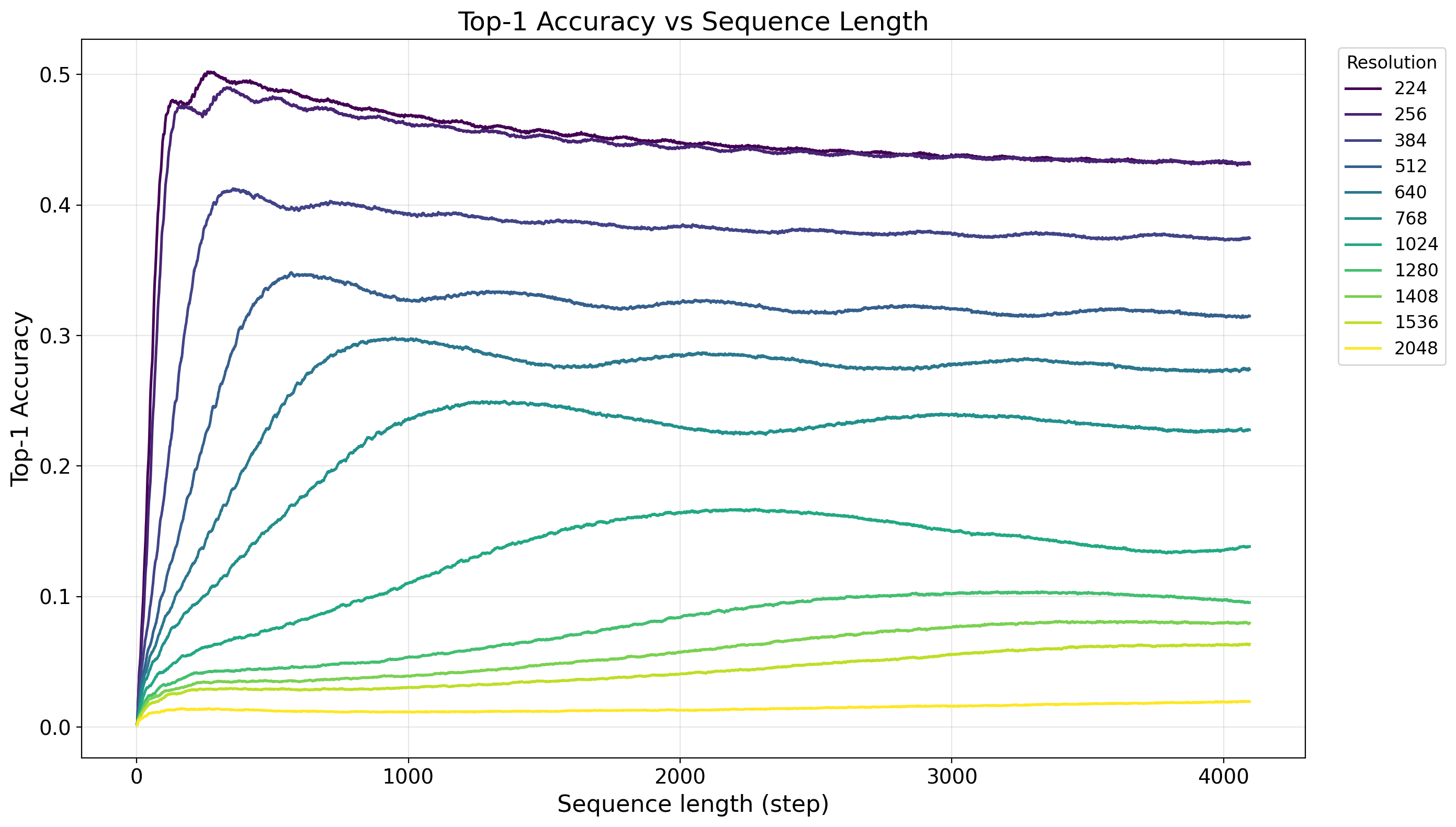
Figure 1.
MambaEye Resolution Scaling Our MambaEye-S
(11M params) models are benchmarked against Mamba-based
models of similar size. While deterministic scanning methods like
FractalMamba++ [15] achieve higher peak accuracy at medium
resolutions, our model demonstrates superior scaling at extreme
resolutions. Notably, MambaEye outperforms FractalMamba++
at resolutions over 12802, despite using only a naive random sam-
pling policy. This highlights our architecture’s inherent robustness
and size-agnostic capabilities.
with strong inductive biases, rely on fixed-size kernels
whose effective receptive field grows slowly with depth,
making global reasoning at high resolution costly.
Vi-
sion Transformers (ViTs) [5] provide global receptive fields
but incur quadratic complexity in the number of patches,
which rapidly becomes prohibitive for native-resolution in-
puts [24]. Previous remedies such as linear/sparse atten-
tion [16, 34, 38] reduce the cost at the expense of expressiv-
ity. To complicate matters, standard ViT pipelines require
resizing and often overfits to the image size of the training
data by learning the absolute positional embeddings. Even
with sophisticated training strategies such as FixRes [32]
or relative encodings (e.g., RoPE) [10, 31], the resolution
brittleness persists.
State Space Models (SSMs) such as Mamba [6], offer
a better chance of realizing an input-size agnostic encoder
due to their linear-time scaling and constant-memory recur-
rent inference, making them attractive for long sequences.
However, when adapted to vision, most approaches seri-
1
arXiv:2511.19963v1 [cs.CV] 25 Nov 2025
alize images with fixed, hand-crafted scanning paths [13]
(e.g., raster scanning), disrupting 2D locality. Many Mamba
based encoders also rely on bidirectional processing to com-
pensate [19, 39], which forfeits the memory advantages
of causal recurrence. Recent work on fractal/space-filling
traversals improves locality [15, 33] but still enforces a pre-
defined, holistic scan and does not eliminate the need to
pick a fixed resolution up front.
To have a truly size-agnostic model, we can once again
turn to human vision perception. A human gathers infor-
mation by dynamically scanning a scene, not by processing
with a certain deterministic path. From this, unlike other ar-
chitectures, we emphasize the importance of causal and se-
quential nature of vision perception. An ideal model should
see the same part of the image multiple times, without a de-
pendence in the order they are seen. Human vision rarely
concludes the scene in one shot; instead, it cumulates infor-
mation through time to build a confident understanding.
With these motivations in mind, we propose Mam