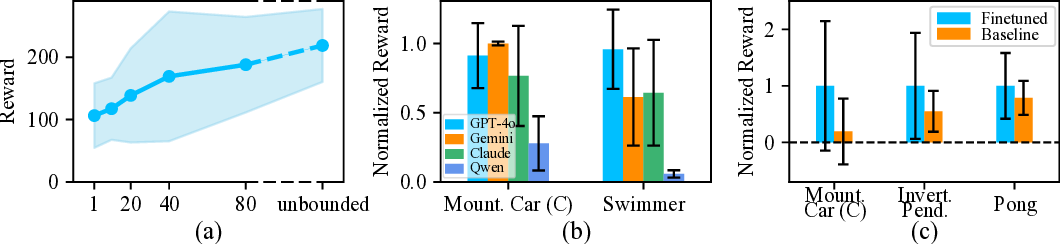
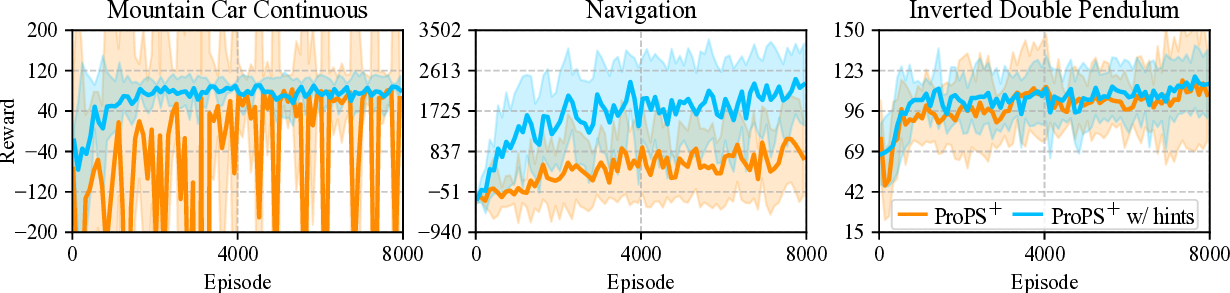
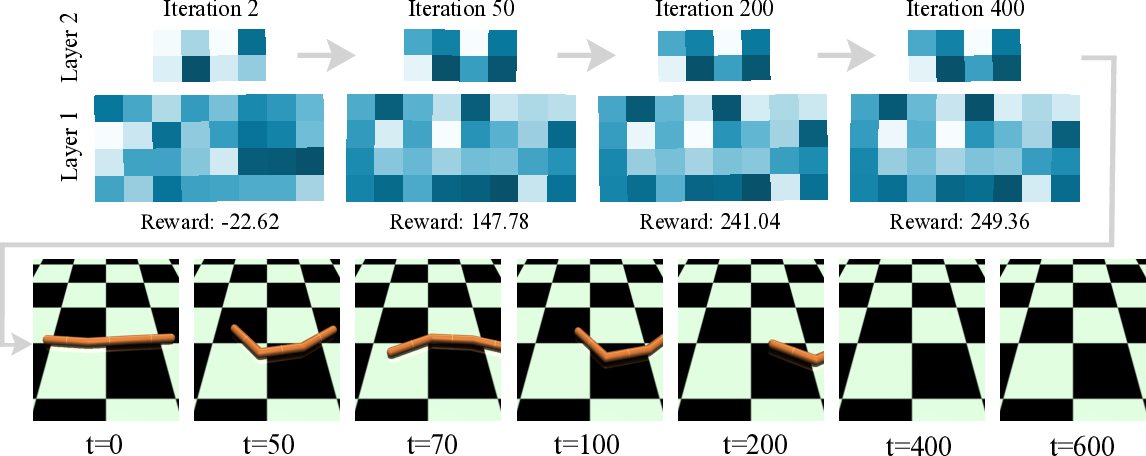
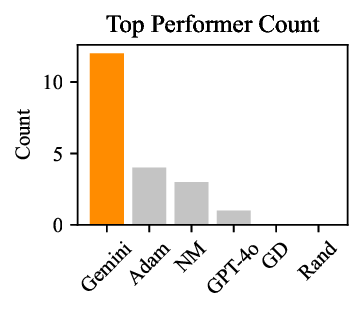
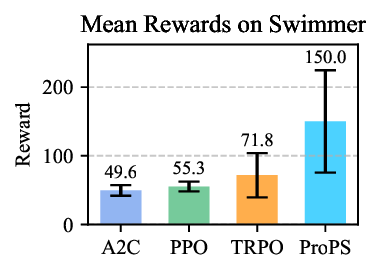
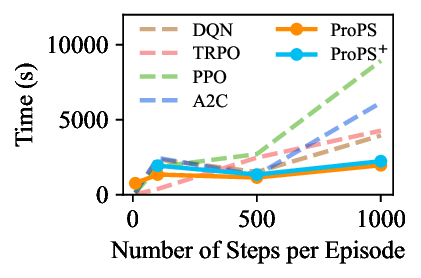
Reinforcement Learning (RL) traditionally relies on scalar reward signals, limiting its ability to leverage the rich semantic knowledge often available in real-world tasks. In contrast, humans learn efficiently by combining numerical feedback with language, prior knowledge, and common sense. We introduce Prompted Policy Search (ProPS), a novel RL method that unifies numerical and linguistic reasoning within a single framework. Unlike prior work that augment existing RL components with language, ProPS places a large language model (LLM) at the center of the policy optimization loop-directly proposing policy updates based on both reward feedback and natural language input. We show that LLMs can perform numerical optimization in-context, and that incorporating semantic signals, such as goals, domain knowledge, and strategy hints can lead to more informed exploration and sample-efficient learning. ProPS is evaluated across fifteen Gymnasium tasks, spanning classic control, Atari games, and MuJoCo environments, and compared to seven widely-adopted RL algorithms (e.g., PPO, SAC, TRPO). It outperforms all baselines on eight out of fifteen tasks and demonstrates substantial gains when provided with domain knowledge. These results highlight the potential of unifying semantics and numerics for transparent, generalizable, and human-aligned RL.
💡 Deep Analysis
📄 Full Content
Prompted Policy Search: Reinforcement Learning
through Linguistic and Numerical Reasoning in LLMs
Yifan Zhou1,∗, Sachin Grover1,∗, Mohamed El Mistiri1, Kamalesh Kalirathnam1,
Pratyush Kerhalkar1, Swaroop Mishra3,†, Neelesh Kumar2, Sanket Gaurav2,
Oya Aran2, Heni Ben Amor1
1Interactive Robotics Lab, Arizona State University
2Research & Development, Procter & Gamble
1{yzhou298,sgrover6,melmisti,kamales1,pkerhalk,hbenamor}@asu.edu
2{kumar.n.40,gaurav.s,aran.o}@pg.com, 3swaroopranjanmishra@gmail.com
Abstract
Reinforcement Learning (RL) traditionally relies on scalar reward signals, limiting
its ability to leverage the rich semantic knowledge often available in real-world
tasks. In contrast, humans learn efficiently by combining numerical feedback
with language, prior knowledge, and common sense. We introduce Prompted
Policy Search (ProPS), a novel RL method that unifies numerical and linguistic
reasoning within a single framework. Unlike prior work that augment existing RL
components with language, ProPS places a large language model (LLM) at the
center of the policy optimization loop—directly proposing policy updates based on
both reward feedback and natural language input. We show that LLMs can perform
numerical optimization in-context, and that incorporating semantic signals, such as
goals, domain knowledge, and strategy hints can lead to more informed exploration
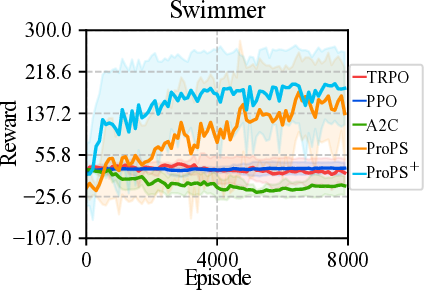
and sample-efficient learning. ProPS is evaluated across 15 Gymnasium tasks,
spanning classic control, Atari games, and MuJoCo environments, and compared
to seven widely-adopted RL algorithms (e.g., PPO, SAC, TRPO). It outperforms
all baselines on 8 out of 15 tasks and demonstrates substantial gains when provided
with domain knowledge. These results highlight the potential of unifying semantics
and numerics for transparent, generalizable, and human-aligned RL.
1
Introduction
Reinforcement Learning (RL) [56] represents a foundational paradigm shift within the broader field
of machine learning. It allows autonomous agents to learn optimal behaviors through interactions
with their environment, i.e., through repeated trial and error. Over the past decades, RL has resulted
in remarkable successes across a range of challenging domains, including mastering strategic games
such as Backgammon [60] and Go [55], achieving human-level performance in robot table-tennis [12]
or contributing to scientific breakthroughs such as protein folding [26]. Traditional RL relies
exclusively on numerical feedback in the form of scalar rewards. By contrast, humans often learn
and reason using natural language, prior knowledge, and common sense [37, 45]. Many real-world
tasks are accompanied by rich linguistic context such as manuals, domain descriptions, and expert
instructions which standard RL algorithms are unable to exploit. Yet, this information can serve as a
powerful inductive bias: guiding exploration, encoding constraints, and expressing useful heuristics
to accelerate learning.
∗Corresponding Authors.
†Currently working at Microsoft AI
39th Conference on Neural Information Processing Systems (NeurIPS 2025).
arXiv:2511.21928v1 [cs.LG] 26 Nov 2025
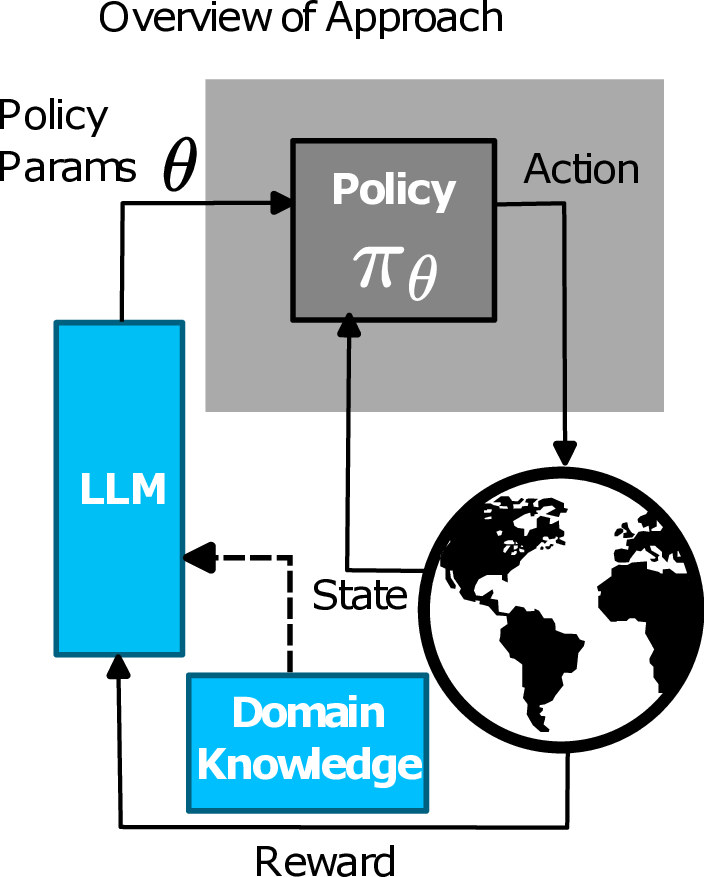
To bridge this gap between numerics and semantics, we introduce Prompted Policy Search (ProPS),
a new method that unifies numerical and linguistic reasoning within a single framework. ProPS
enables language models to process and act on both reward signals and natural language inputs, such as
high-level goals, domain knowledge, or strategic hints. This results in a more informed and adaptable
policy search process. While prior works have used Large Language Models (LLMs) [39] to augment
specific components of the RL pipeline (e.g., reward shaping [69], Q-function modeling [64], or
action generation [20]), these approaches still depend on conventional RL algorithms for optimization.
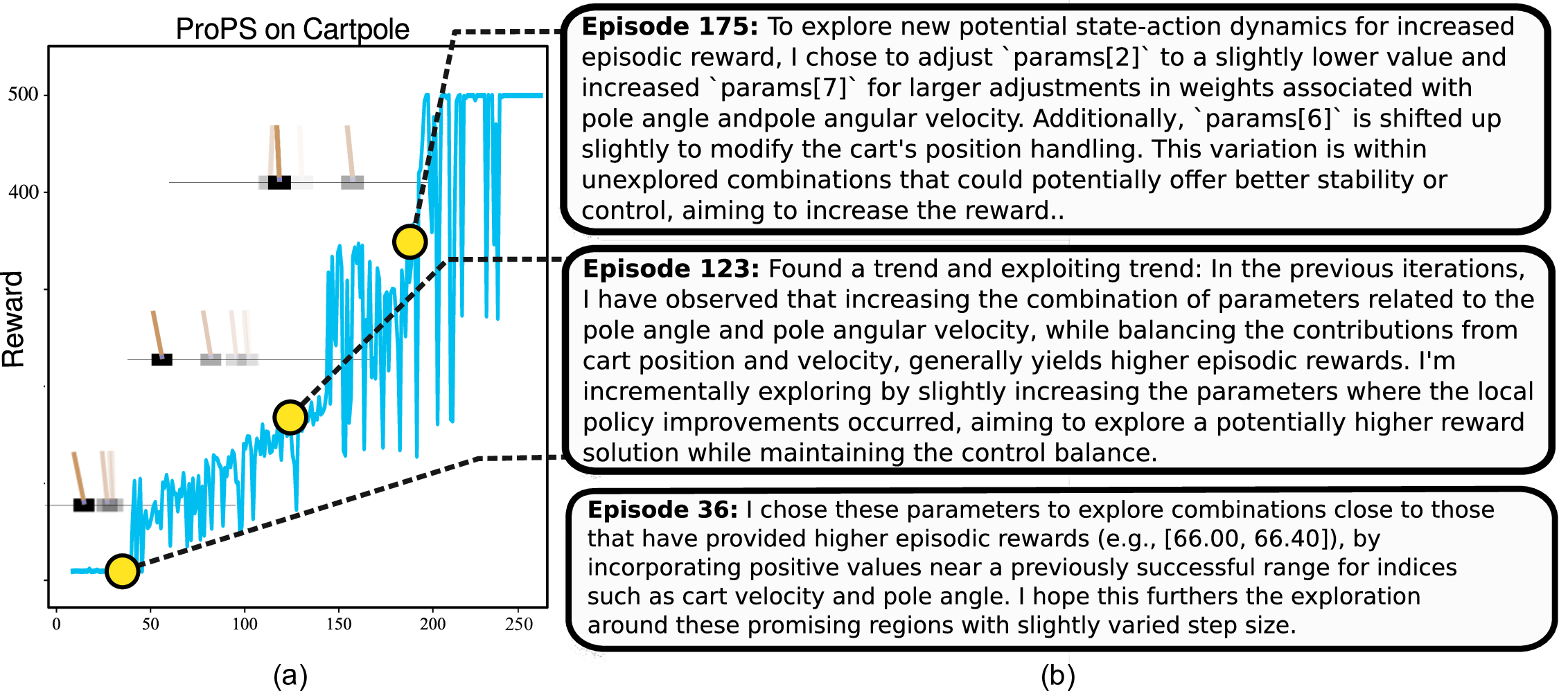
In contrast, we show that LLMs can directly perform policy search, treating optimization as an
in-context reasoning problem. To this end, first, we demonstrate that LLMs are capable of numerical
optimization for RL tasks. We then extend this capability to incorporate linguistic abstractions,
enabling a unified reasoning strategy where semantic and quantitative signals complement one
another. The resulting approach accelerates convergence by incorporating prior knowledge, enforcing
constraints, and refining exploration. Moreover, it offers additional transparency by providing natural
language justifications of the proposed policy updates: an essential feature for domains requiring
transparency, safety, and human oversight. Our primary contributions are as follows:
(C1) Unifying Numerical and Linguistic Reasoning for RL: We propose Prompted Policy Search
(ProPS), a framework to integrate scalar reward signals with natural language guidance
in a unified optimization loop, enabling language models to reason over both quantitative
feedback and semantic abstractions.
(C2) Flexible Integration of Human-Centric Knowledge: ProPS leverages the symbolic a