Language-Independent Sentiment Labelling with Distant Supervision: A Case Study for English, Sepedi and Setswana
Reading time: 5 minute
...
📝 Original Info
Title: Language-Independent Sentiment Labelling with Distant Supervision: A Case Study for English, Sepedi and Setswana
ArXiv ID: 2511.19818
Date: 2025-11-25
Authors: - Koena Ronny Mabokela (University of Johannesburg, South Africa) - Tim Schlippe (IU International University of Applied Sciences, Germany) - Mpho Raborife (University of Johannesburg, South Africa) - Turgay Celik (University of the Witwatersrand, South Africa)
📝 Abstract
Sentiment analysis is a helpful task to automatically analyse opinions and emotions on various topics in areas such as AI for Social Good, AI in Education or marketing. While many of the sentiment analysis systems are developed for English, many African languages are classified as low-resource languages due to the lack of digital language resources like text labelled with corresponding sentiment classes. One reason for that is that manually labelling text data is time-consuming and expensive. Consequently, automatic and rapid processes are needed to reduce the manual effort as much as possible making the labelling process as efficient as possible. In this paper, we present and analyze an automatic language-independent sentiment labelling method that leverages information from sentimentbearing emojis and words. Our experiments are conducted with tweets in the languages English, Sepedi and Setswana from SAfriSenti, a multilingual sentiment corpus for South African languages. We show that our sentiment labelling approach is able to label the English tweets with an accuracy of 66%, the Sepedi tweets with 69%, and the Setswana tweets with 63%, so that on average only 34% of the automatically generated labels remain to be corrected.
💡 Deep Analysis
📄 Full Content
Language-Independent Sentiment Labelling with Distant Supervision:
A Case Study for English, Sepedi and Setswana
Koena Ronny Mabokela∗, Tim Schlippe$, Mpho Raborife∗, Turgay Celik∥
∗University of Johannesburg, South Africa
$IU International University of Applied Sciences, Germany
∥University of the Witwatersrand, South Africa
krmabokela@gmail.com
Abstract
Sentiment analysis is a helpful task to automatically analyse opinions and emotions on various topics in areas such as AI for Social
Good, AI in Education or marketing. While many of the sentiment analysis systems are developed for English, many African languages
are classified as low-resource languages due to the lack of digital language resources like text labelled with corresponding sentiment
classes. One reason for that is that manually labelling text data is time-consuming and expensive. Consequently, automatic and rapid
processes are needed to reduce the manual effort as much as possible making the labelling process as efficient as possible. In this paper,
we present and analyze an automatic language-independent sentiment labelling method that leverages information from sentiment-
bearing emojis and words. Our experiments are conducted with tweets in the languages English, Sepedi and Setswana from SAfriSenti,
a multilingual sentiment corpus for South African languages. We show that our sentiment labelling approach is able to label the English
tweets with an accuracy of 66%, the Sepedi tweets with 69%, and the Setswana tweets with 63%, so that on average only 34% of the
automatically generated labels remain to be corrected.
Keywords: sentiment analysis, artificial intelligence, natural language processing, South African languages
1.
Introduction
Sentiment analysis helps analyze and extract informa-
tion about polarity from textual feedback and opinions.
Sentiment analysis draws attention in business environ-
ments (Rokade and Kumari, 2019) and other areas, like
medicine (Zucco et al., 2018), education (Mabokela et al.,
2022; Rakhmanov and Schlippe, 2022) and AI for Social
Good (Mabokela and Schlippe, 2022b).
Sentiment analysis for under-resourced language still is a
skewed research area. Although, there are some consid-
erable efforts in emerging African countries to develop
resources for under-resourced languages, some languages
such as indigenous South African languages still suffer
from a lack of datasets. One reason for that is that man-
ually labelling text data is time-consuming and expensive.
Consequently, automatic and rapid processes are needed
to reduce the manual effort as much as possible making
the labelling process as efficient as possible. In this paper,
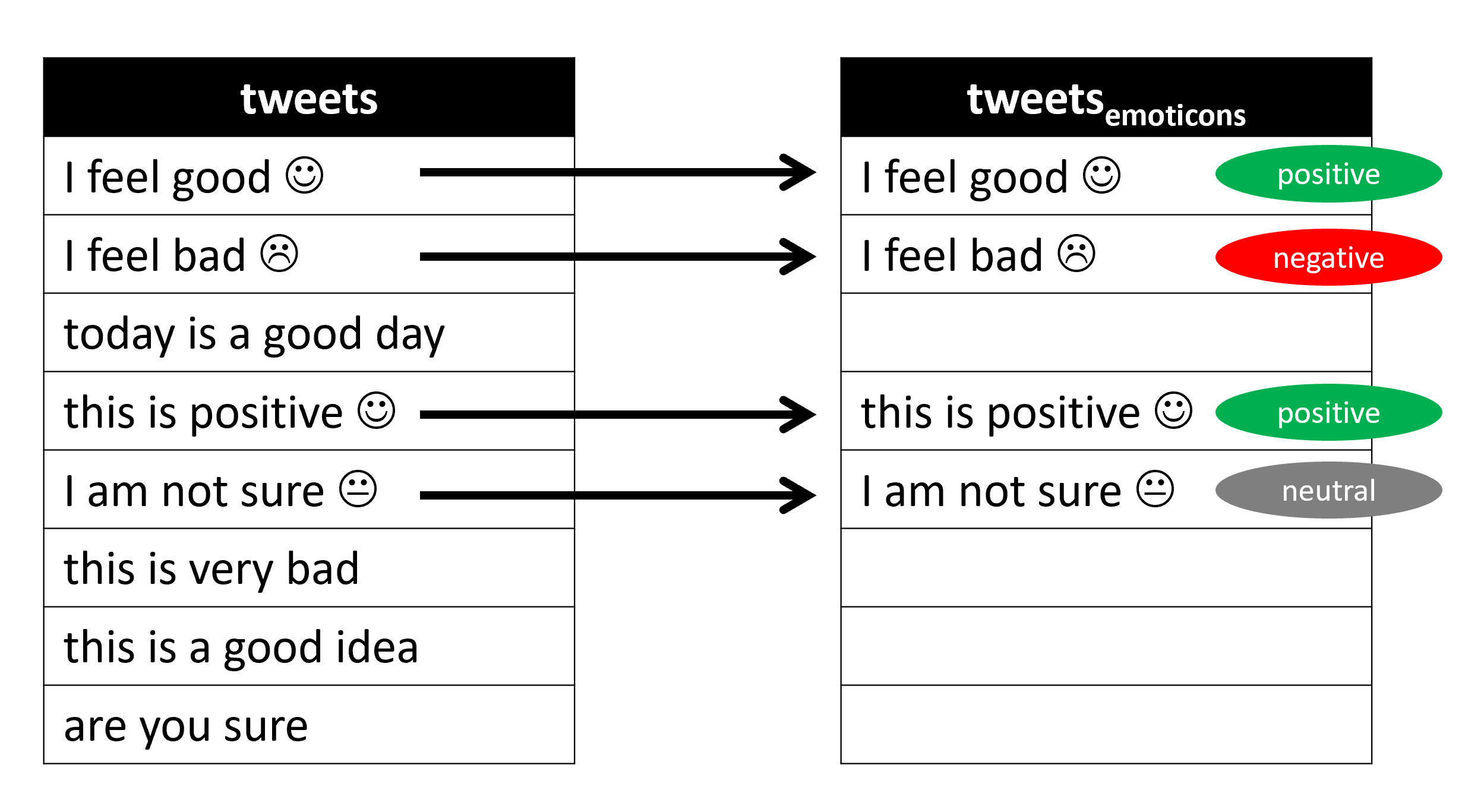
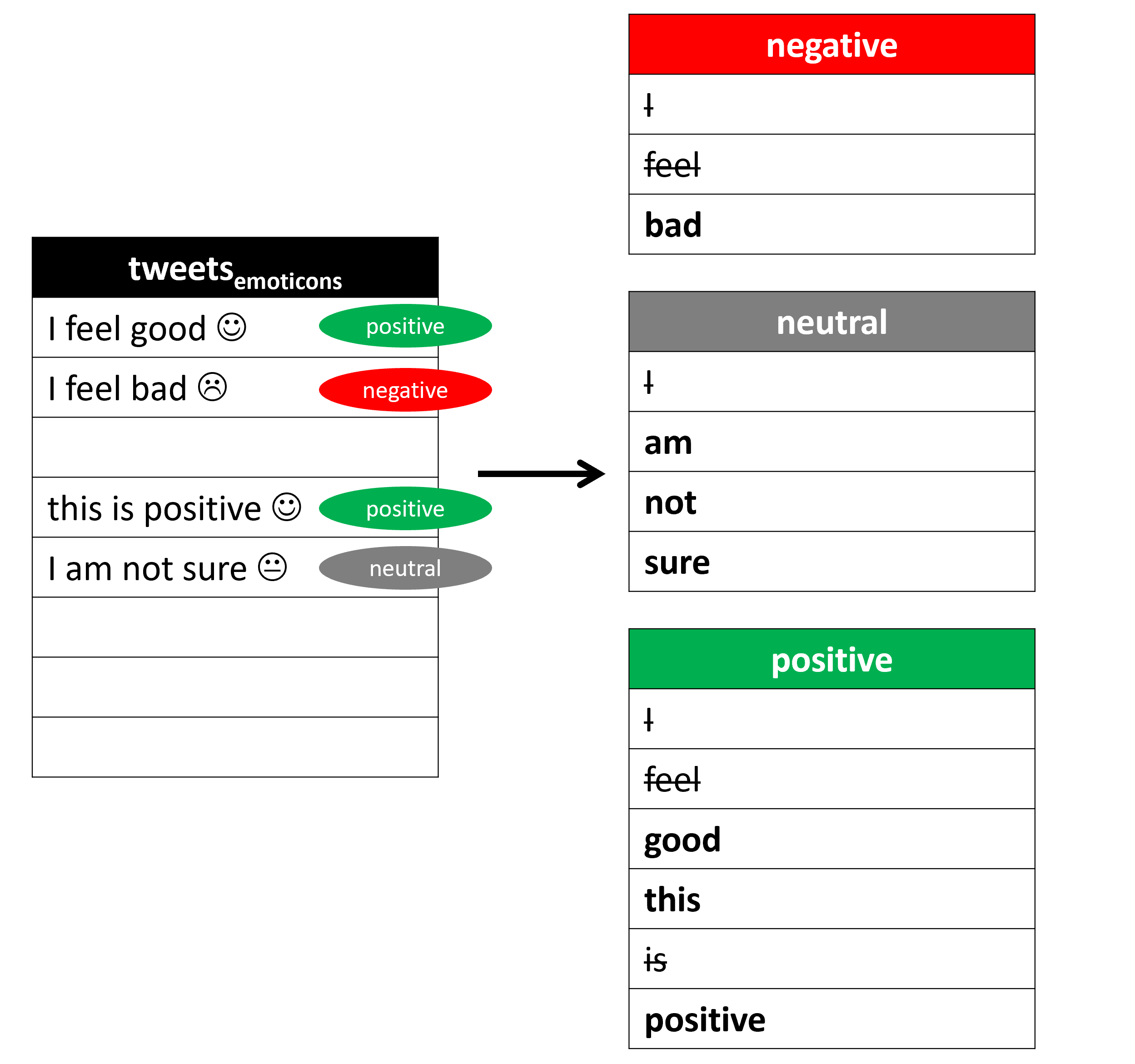
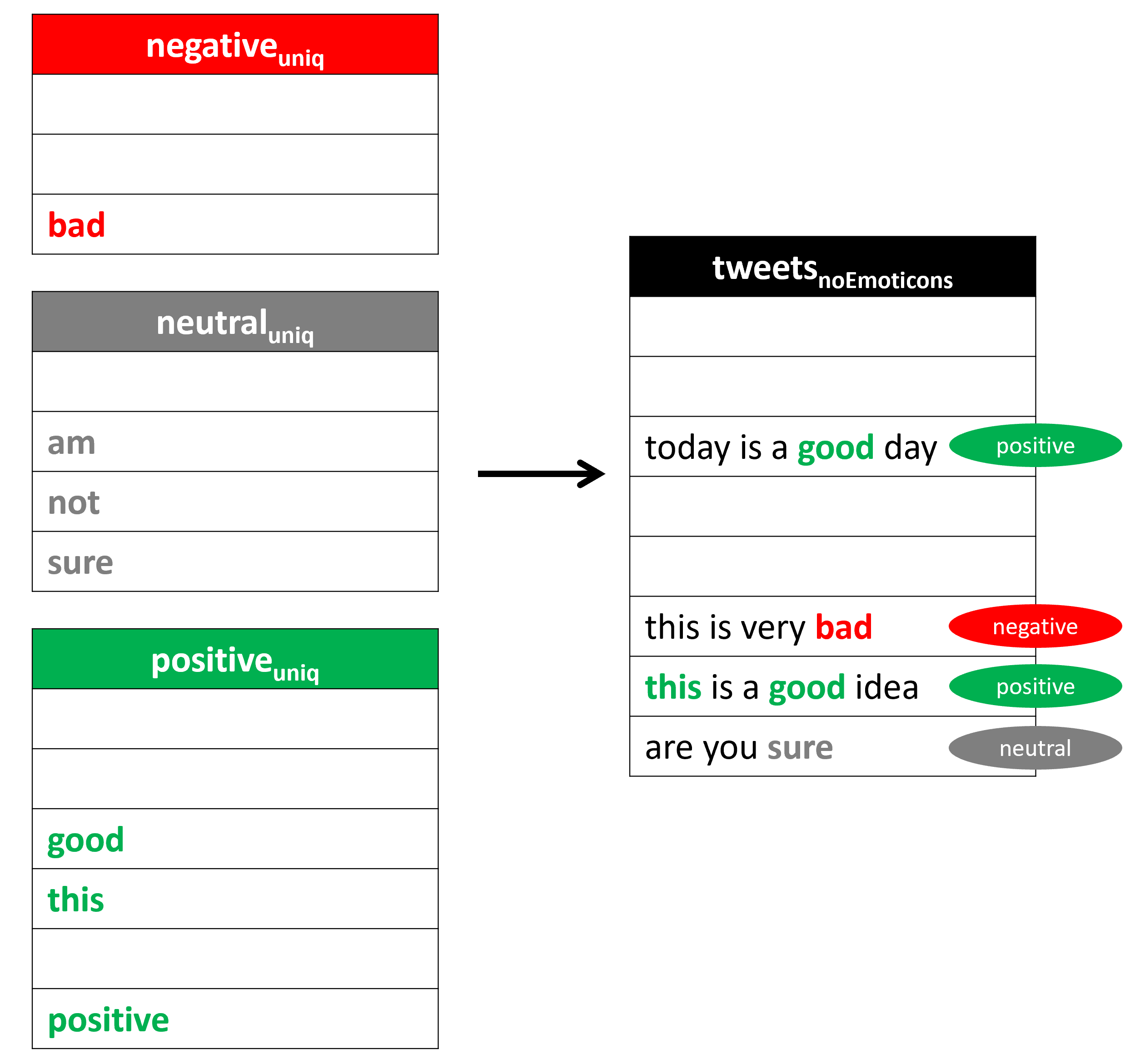
we present and analyze an automatic language-independent
sentiment labelling algorithm that leverages information
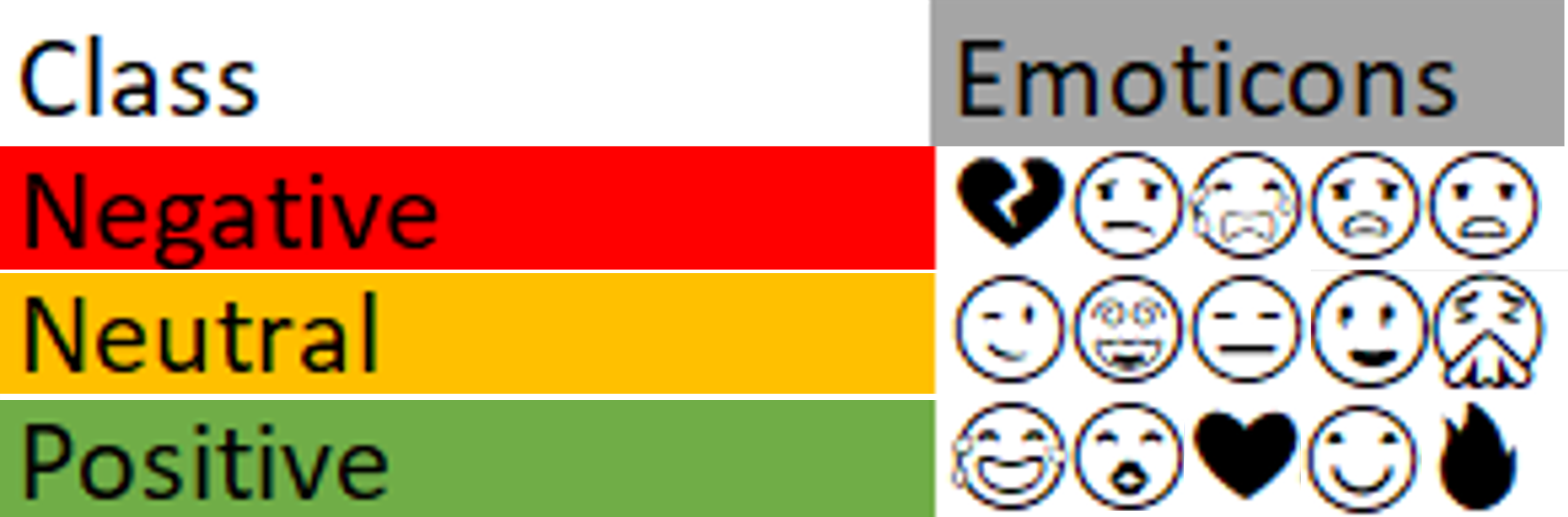
from sentiment-bearing emojis1 and words. We will eval-
uate our algorithm on a subset of our SAfriSenti corpus
(Mabokela and Schlippe, 2022a; Mabokela and Schlippe,
2022b) with English, Sepedi and Setswana tweets.
Se-
pedi is mainly spoken in the northern parts of South Africa
by 4.7 million people and Setswana by 4.5 million peo-
ple (Statista, 2022).
In the next section, we will describe related work. In sec-
tion 3 we will present our language-independent algorithm
1Emojis are pictorial representations of emotions, ideas,
or objects in electronic communication to add emotional
context.
for sentiment labelling.
The experimental setup will be
characterised in Section 4. In Section 5 we will summarise
the results of our experiments. We will conclude our work
in Section 6 and indicate possible future work.
2.
Related Work
Previous studies investigated sentiment data collection
strategies for under-resourced languages on Twitter (Pak
and Paroubek, 2010; Vosoughi et al., 2016). The methods
focus on labelling only two sentiment classes —positive
and negative. Meanwhile other research work has explored
strategies to label three sentiment classes in Twitter—
positive, neutral, and negative —using human annotators
(Pang et al., 2002; Pak and Paroubek, 2010; Vilares et al.,
2016; Nakov et al., 2019). Despite the attempt to automate
the data labelling process (Kranjc et al., 2015), the hand-
crafted annotation is to date the most preferred method of
data labelling in many natural language processing tasks
(Chakravarthi et al., 2020). However, manual annotation
presents challenges and it is deemed an expensive process.
Notably, (Jamatia et al., 2020; Gupta et al., 2021) employed
manually annotated tweets, while other studies focus on
automated data labelling solutions (Kranjc et al., 2015).
(Vosoughi et al., 2016) investigated various pipelines to
collect data on Twitter using distant supervised learning.
In this approach, they use positive and negative emojis as
indicators to annotate tweets.
(Go et al., 2009) explored distant supervision methods to
label millions of tweets using positive and negative search
terms (i.e. term queries) in the Twitter API and emojis
to pre-classify the