Authors: ** - Anglin Liu¹* - Rundong Xue²* - Xu R. Cao³† - Yifan Shen³ - Yi Lu¹ - Xiang Li³ - Qianqian Chen⁴ - Jintai Chen¹⁵† ¹ 홍콩과학기술대학 (광저우) ² 시안교통대학 ³ 일리노이 대학교 어배너-샴페인 ⁴ 동남대학 ⁵ 홍콩과학기술대학 * 공동 1저자 † 교신 저자 — **
📝 Abstract
Medical image segmentation is fundamental for biomedical discovery. Existing methods lack generalizability and demand extensive, time-consuming manual annotation for new clinical application. Here, we propose MedSAM-3, a text promptable medical segmentation model for medical image and video segmentation. By fine-tuning the Segment Anything Model (SAM) 3 architecture on medical images paired with semantic conceptual labels, our MedSAM-3 enables medical Promptable Concept Segmentation (PCS), allowing precise targeting of anatomical structures via open-vocabulary text descriptions rather than solely geometric prompts. We further introduce the MedSAM-3 Agent, a framework that integrates Multimodal Large Language Models (MLLMs) to perform complex reasoning and iterative refinement in an agent-in-the-loop workflow. Comprehensive experiments across diverse medical imaging modalities, including X-ray, MRI, Ultrasound, CT, and video, demonstrate that our approach significantly outperforms existing specialist and foundation models. We will release our code and model at https://github.com/Joey-S-Liu/MedSAM3.
💡 Deep Analysis
📄 Full Content
MedSAM3: Delving into Segment Anything with Medical Concepts
Anglin Liu1*, Rundong Xue2,∗, Xu R. Cao3,†, Yifan Shen3, Yi Lu1, Xiang Li3, Qianqian Chen4,
Jintai Chen1,5,†
1 The Hong Kong University of Science and Technology (Guangzhou)
2 Xi’an Jiaotong University
3 University of Illinois Urbana-Champaign
4 Southeast University
5 The Hong Kong University of Science and Technology
Abstract
Medical image segmentation is fundamental for biomedi-
cal discovery. Existing methods lack generalizability and
demand extensive, time-consuming manual annotation for
new clinical application. Here, we propose MedSAM-3, a
text promptable medical segmentation model for medical
image and video segmentation. By fine-tuning the Segment
Anything Model (SAM) 3 architecture on medical images
paired with semantic conceptual labels, our MedSAM-3 en-
ables medical Promptable Concept Segmentation (PCS), al-
lowing precise targeting of anatomical structures via open-
vocabulary text descriptions rather than solely geometric
prompts. We further introduce the MedSAM-3 Agent, a
framework that integrates Multimodal Large Language Mod-
els (MLLMs) to perform complex reasoning and iterative
refinement in an agent-in-the-loop workflow. Comprehen-
sive experiments across diverse medical imaging modalities,
including X-ray, MRI, Ultrasound, CT, and video, demon-
strate that our approach significantly outperforms exist-
ing specialist and foundation models. We will release our
code and model at https://github.com/Joey-S-
Liu/MedSAM3.
1. Introduction
Medical segmentation is the cornerstone of the modern
healthcare system, providing the quantitative analysis nec-
essary for accurate diagnosis, precise treatment planning,
and effective monitoring of disease progression [5]. While
deep learning has driven considerable progress, the develop-
ment of specialist models for every unique task, modality,
and pathology is inefficient and scales poorly. Such models
*Co-first authors.
†Corresponding to: jintaiCHEN@hkust-gz.edu.cn (J. Chen),
xucao2@illinois.edu (X. Cao).
lack generalizability and demand extensive, time-consuming
manual annotation for each new clinical application.
The emergence of large-scale foundation models, such as
the Segment Anything Model (SAM) [28, 47], has marked
a paradigm shift towards building generalist systems that
can handle diverse tasks. In the medical field, this approach
was successfully validated by models like MedSAM [41],
MedSAM-2 [64] and MedSAM2 [43], which adapted the
original SAM for medical-specific challenges. MedSAM2,
in particular, demonstrated the power of a promptable foun-
dation model for segmenting 3D medical images and videos,
proving that such systems can drastically reduce manual an-
notation costs [43]. However, these models primarily rely
on geometric prompts, which can still be laborious for com-
plex structures and do not fully capture the rich semantic
intent of clinicians. In addition, these models can only serve
as one tool, lacking potential to connect with the agentic
ecosystem supported by multimodal large language models
(LLMs) [2, 33, 58].
The recent introduction of SAM 3 marks a significant
leap in interactive segmentation with its “Promptable Con-
cept Segmentation” (PCS) capability [4]. Unlike methods
reliant on geometric cues, SAM 3 can detect and segment
objects based on open-vocabulary conceptual prompts, such
as natural language descriptions (e.g., “a yellow school bus”)
or visual exemplars. This ability to operate on semantic
concepts presents a transformative opportunity for medical
imaging, where clinical language is inherently conceptual
(e.g., “segment the tumor and surrounding edema” or “iden-
tify all enlarged lymph nodes”). This directly addresses a
fundamental limitation of prior text-guidance segmentation
models, such as BiomedParse [62], which were constrained
to a fixed, pre-defined vocabulary and thus could not gener-
alize to the vast and nuanced range of concepts encountered
in clinical practice [61].
To address these limitations, we present MedSAM-3, a
concept-driven framework designed to segment medical im-
arXiv:2511.19046v1 [cs.CV] 24 Nov 2025
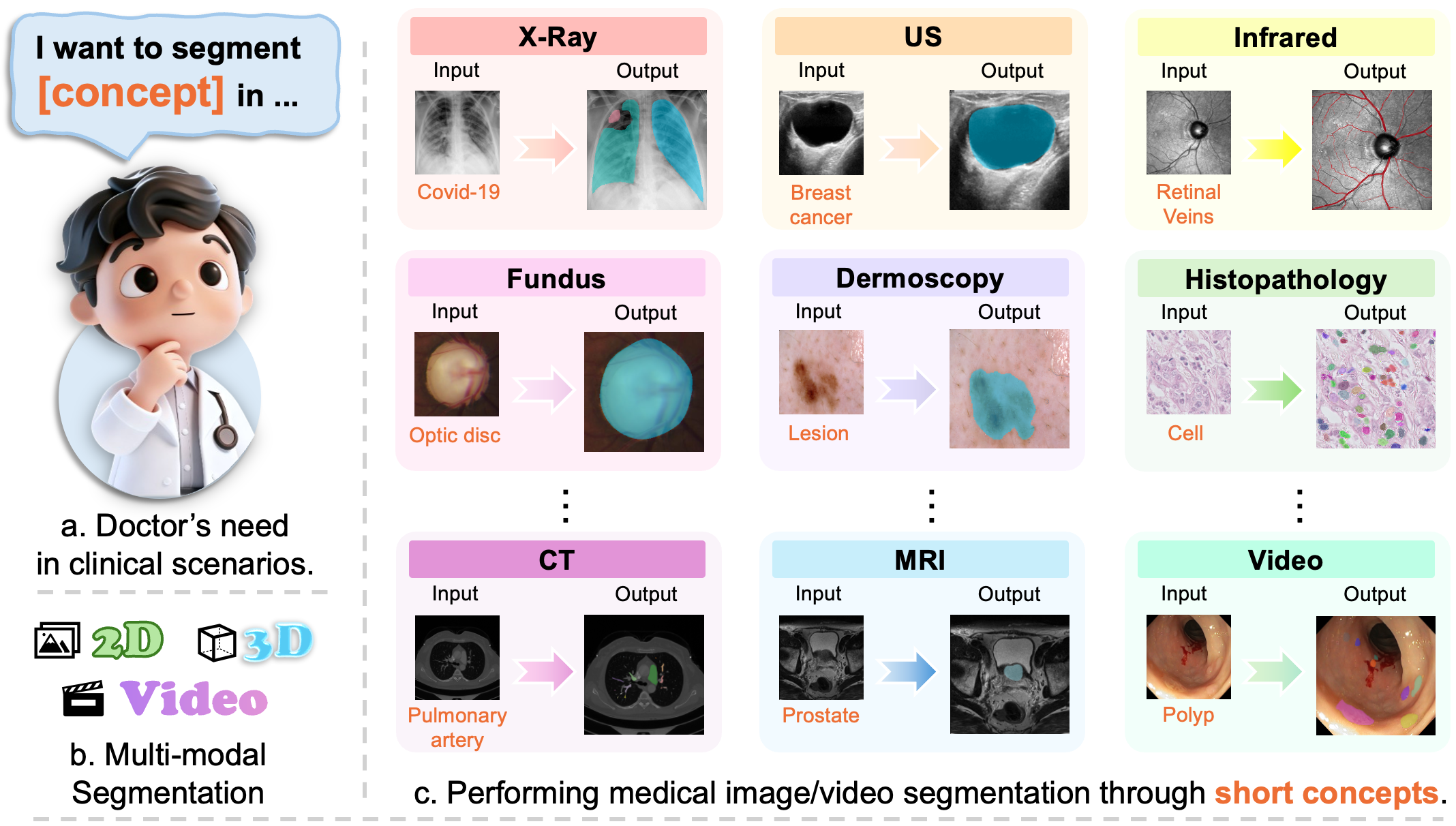
Figure 1. Overview of concept-driven medical image and video segmentation across multiple modalities using MedSAM-3, highlighting that
concise clinical concepts directly guide MedSAM-3 to produce reliable segmentations and thereby simplify physicians’ workflow.
agery through semantic guidance (Figure 1). We began by
benchmarking the original SAM 3 on multiple medical seg-
mentation datasets to validate its baseline capabilities on
both text prompting and visual prompting. However, raw
SAM 3 struggled with the healthcare domain. Consequently,
we fine-tuned the architecture on a curated dataset of diverse
medical images paired with rich conceptual labels. The
resulting model allows users to segment complex anatom-
ical structures and pathologies using simple text descrip-
tions or visual references from inter- or intra-scan exam