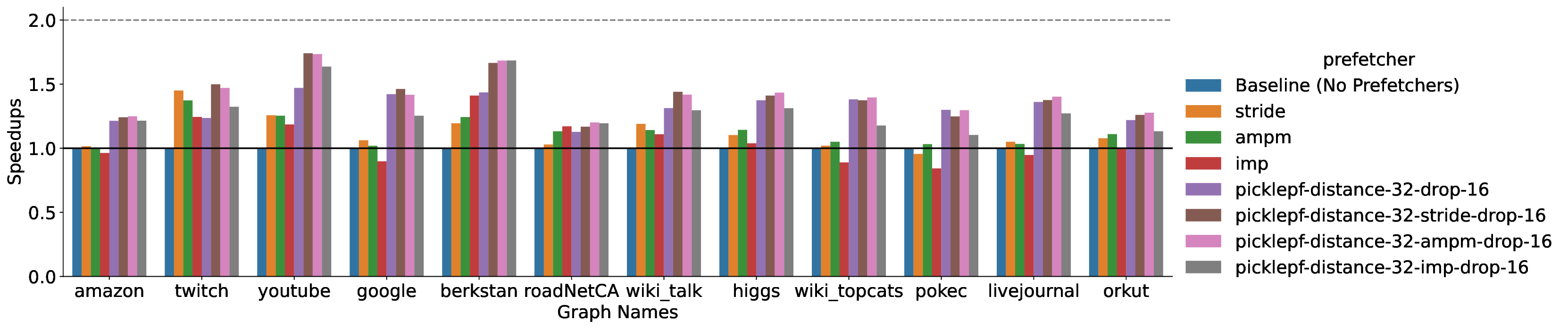
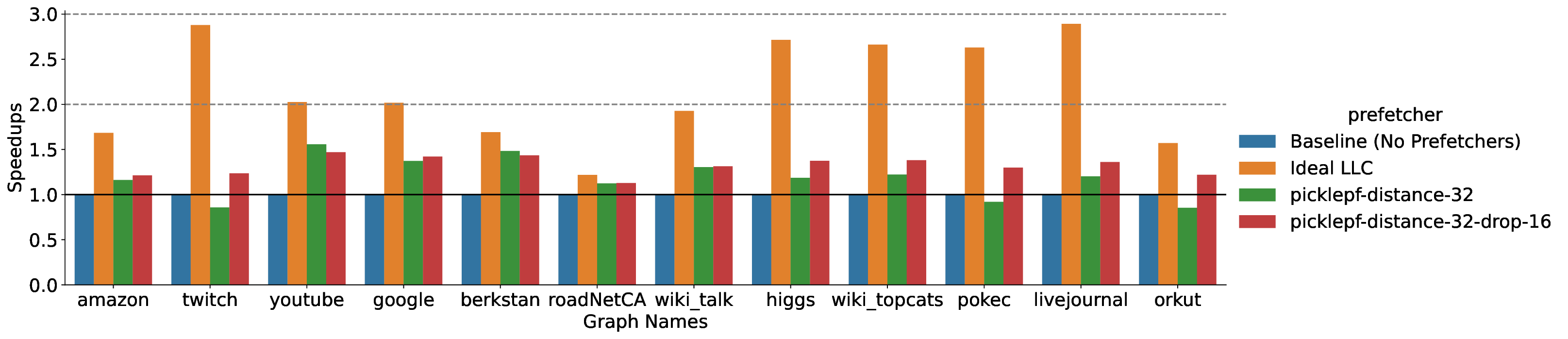
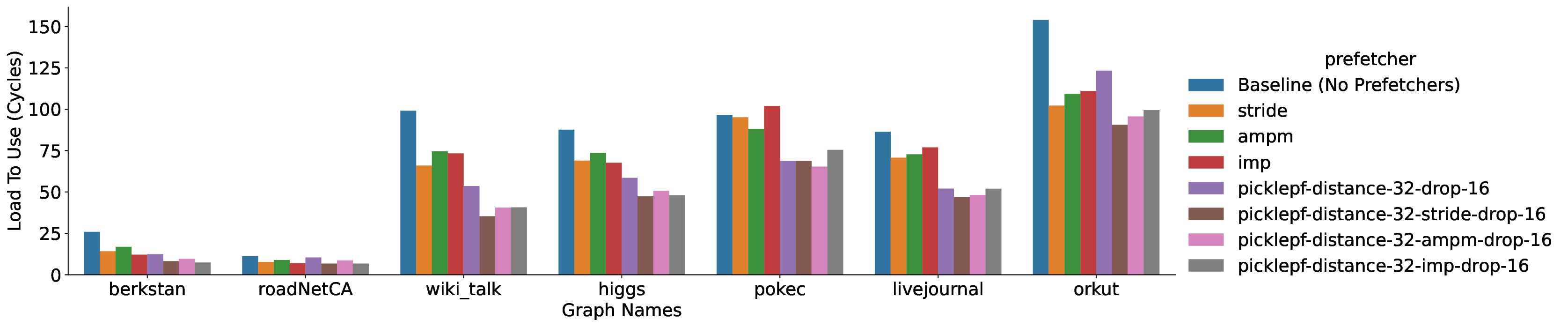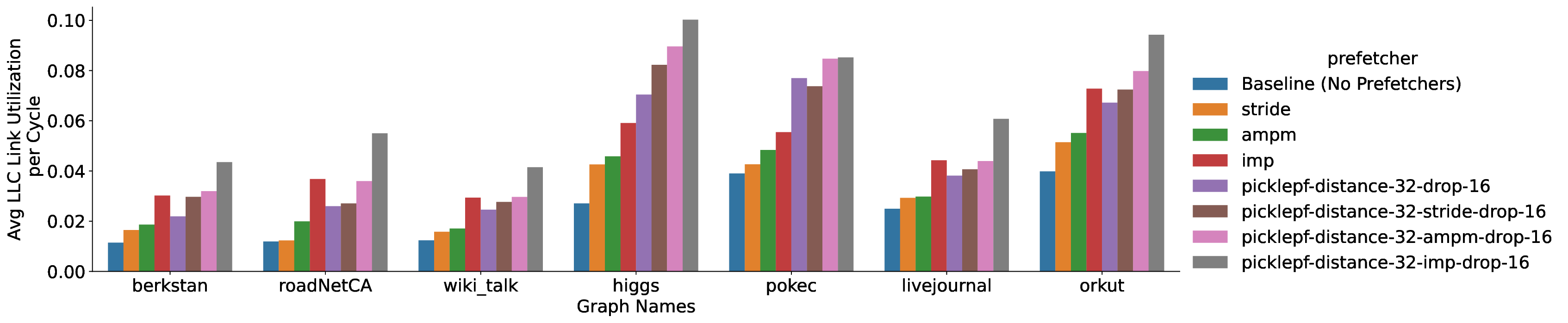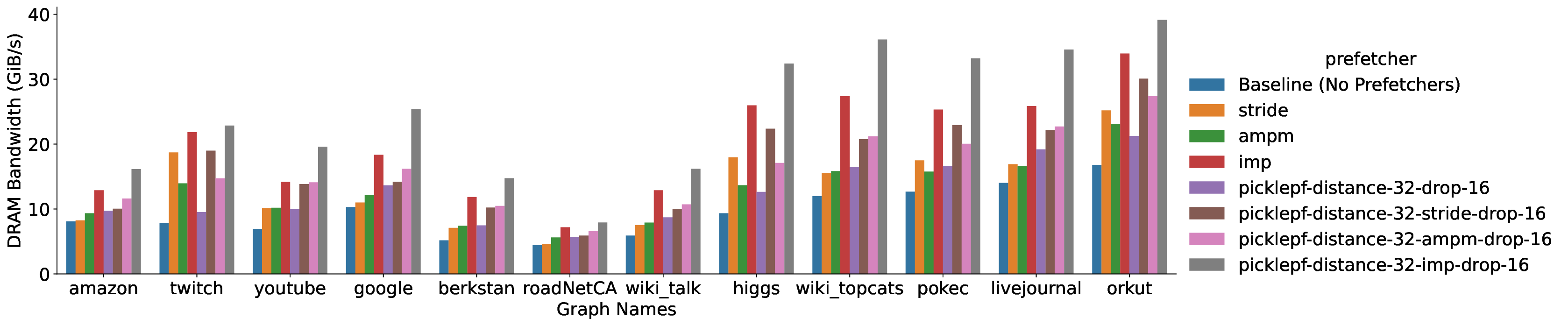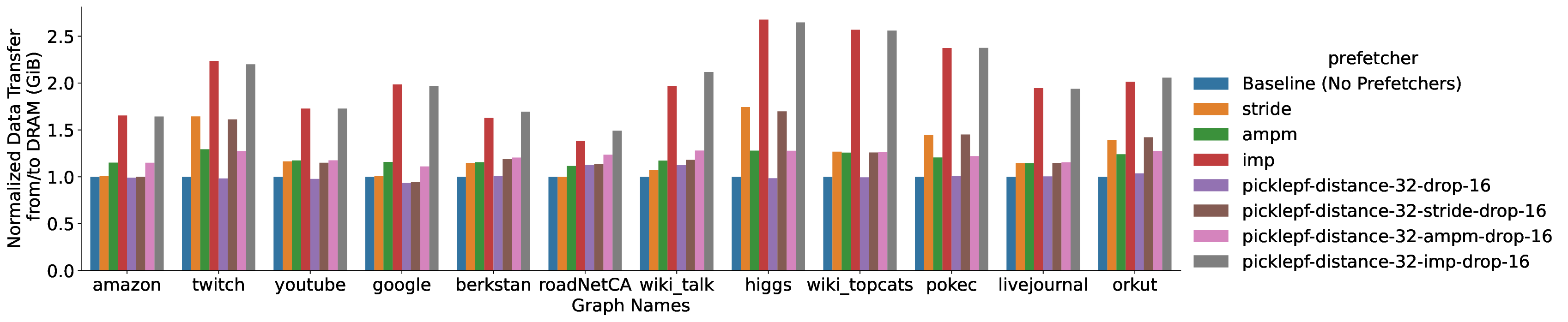Modern high-performance architectures employ large last-level caches (LLCs). While large LLCs can reduce average memory access latency for workloads with a high degree of locality, they can also increase latency for workloads with irregular memory access patterns. Prefetchers are widely used to reduce memory latency by prefetching data into the cache hierarchy before it is accessed by the core. However, existing prediction-based prefetchers often struggle with irregular memory access patterns, which are especially prevalent in modern applications. This paper introduces the Pickle Prefetcher, a programmable and scalable LLC prefetcher designed to handle independent irregular memory access patterns effectively. Instead of relying on static heuristics or complex prediction algorithms, Pickle Prefetcher allows software to define its own prefetching strategies using a simple programming interface without expanding the instruction set architecture (ISA). By trading the logic complexity of hardware prediction for software programmability, Pickle Prefetcher can adapt to a wide range of access patterns without requiring extensive hardware resources for prediction. This allows the prefetcher to dedicate its resources to scheduling and issuing timely prefetch requests. Graph applications are an example where the memory access pattern is irregular but easily predictable by software. Through extensive evaluations of the Pickle Prefetcher on gem5 full-system simulations, we demonstrate tha Pickle Prefetcher significantly outperforms traditional prefetching techniques. Our results show that Pickle Prefetcher achieves speedups of up to 1.74x on the GAPBS breadth-first search (BFS) implementation over a baseline system. When combined with private cache prefetchers, Pickle Prefetcher provides up to a 1.40x speedup over systems using only private cache prefetchers.
Prefetchers are ubiquitous in modern high-performance computing systems. By prefetching data into the private caches and last-level cache (LLC) before the data is accessed by the core, prefetchers can significantly reduce the average memory access latency for workloads with a high degree of locality and recognizable memory access patterns.
However, existing memory access pattern prediction-based prefetchers often struggle with detecting irregular memory access patterns with a large memory footprint. This type of pattern is especially prevalent in modern applications, such as graph processing, machine learning, and data analytics. There has been active research on improving prefetchers to handle irregular memory access patterns for specific applications. However, these approaches often require complex hardware prediction logic or static heuristics that are not easily adaptable to different workloads [1], [18], [40].
Prodigy [35] is an example towards generalization of hardware prefetchers which can handle common irregular memory access patterns present in graph processing while being generic enough to be used in other applications. However, the Prodigy prefetcher is still limited by the hardware resources available in the core and is sensitive to prefetch distance and long-latency accesses. In addition, prefetchers are sensitive to prefetch parameters, such as prefetch distance, which can vary significantly across different workloads. While a stream pattern in a memcpy function can be benefited from an aggressive prefetch distance, a graph traversal pattern in a breadth-first search (BFS) algorithm can be harmed by the same prefetch distance and aggressiveness. This makes it difficult to design a single prefetcher that can handle all workloads effectively.
While software landscape evolves quickly, hardware architectures are also continually evolving to meet the demands of emerging workloads and new performance requirements. Hardware must be frequently redesigned, a costly and timeintensive process. In contrast, software exhibits significantly greater flexibility and is able to rapidly adapt to changing application demands, hardware configurations, and user require-ments through simple updates and reconfiguration. Leveraging software programmability to manage complexity allows for a more dynamic response to the shifting computing landscape, providing substantial advantages over purely hardware-driven solutions. Therefore, emphasizing software programmability in prefetcher design ensures adaptability and longevity, enabling systems to efficiently keep pace with ongoing technological advancements and workload diversification.
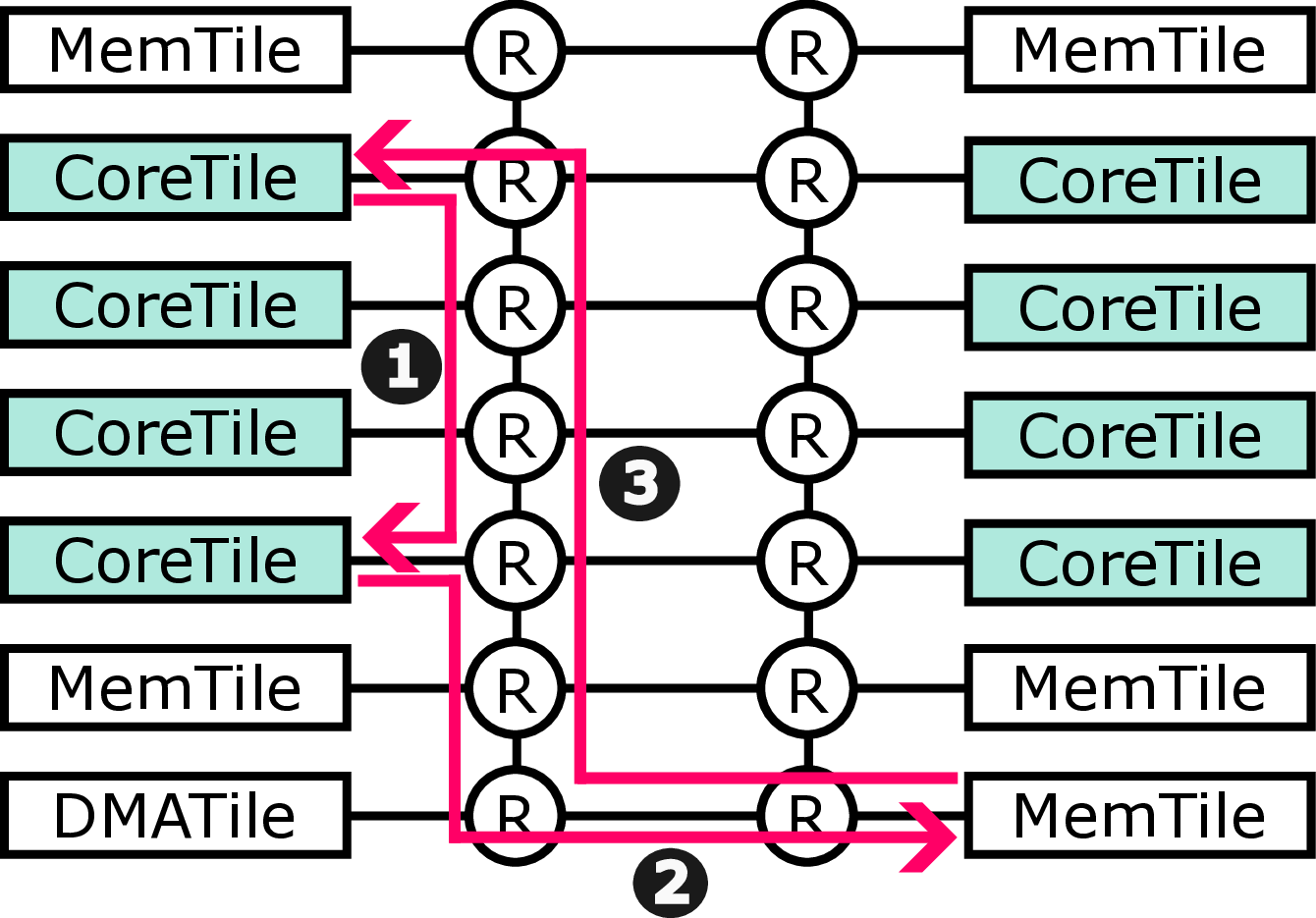
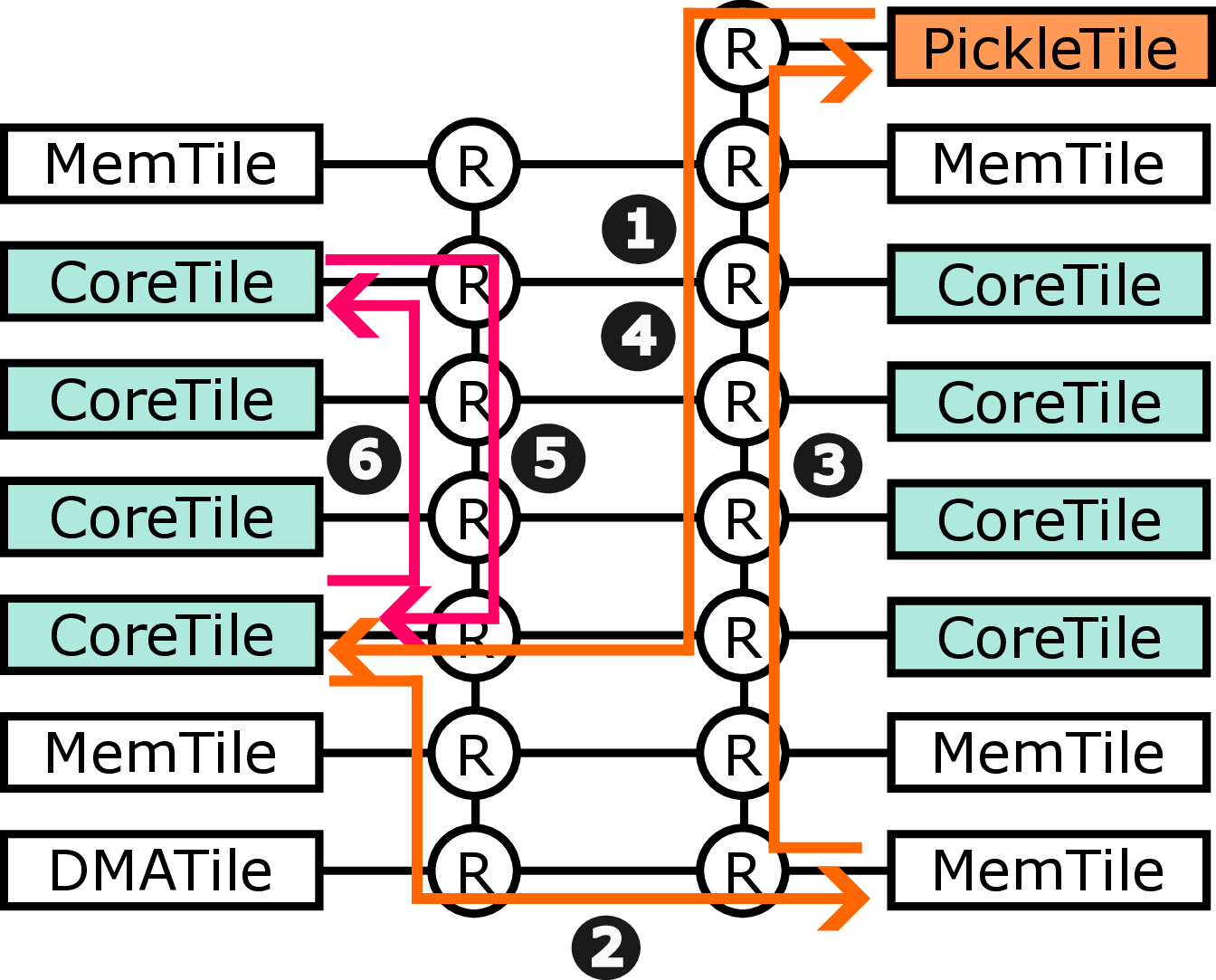
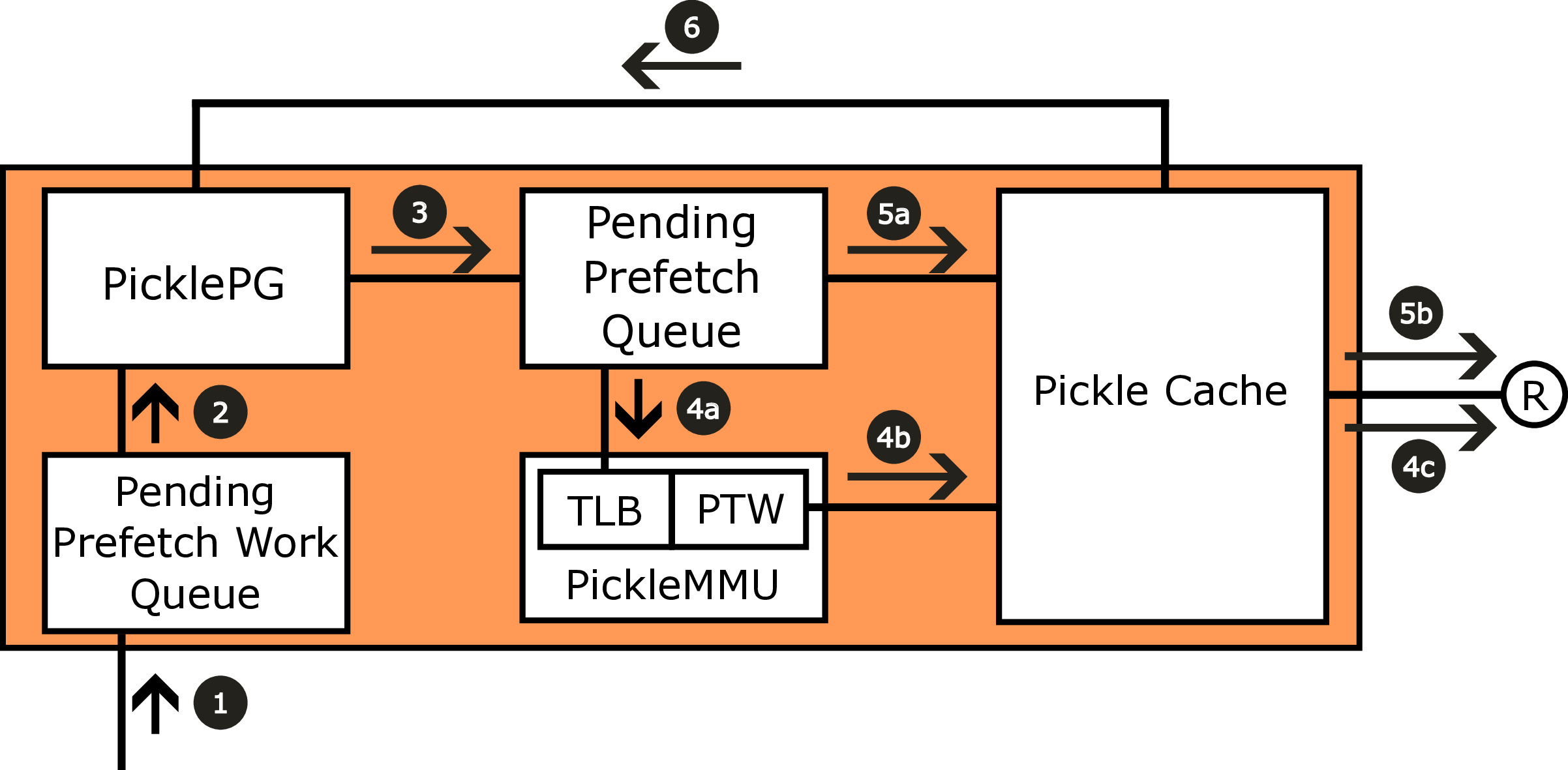
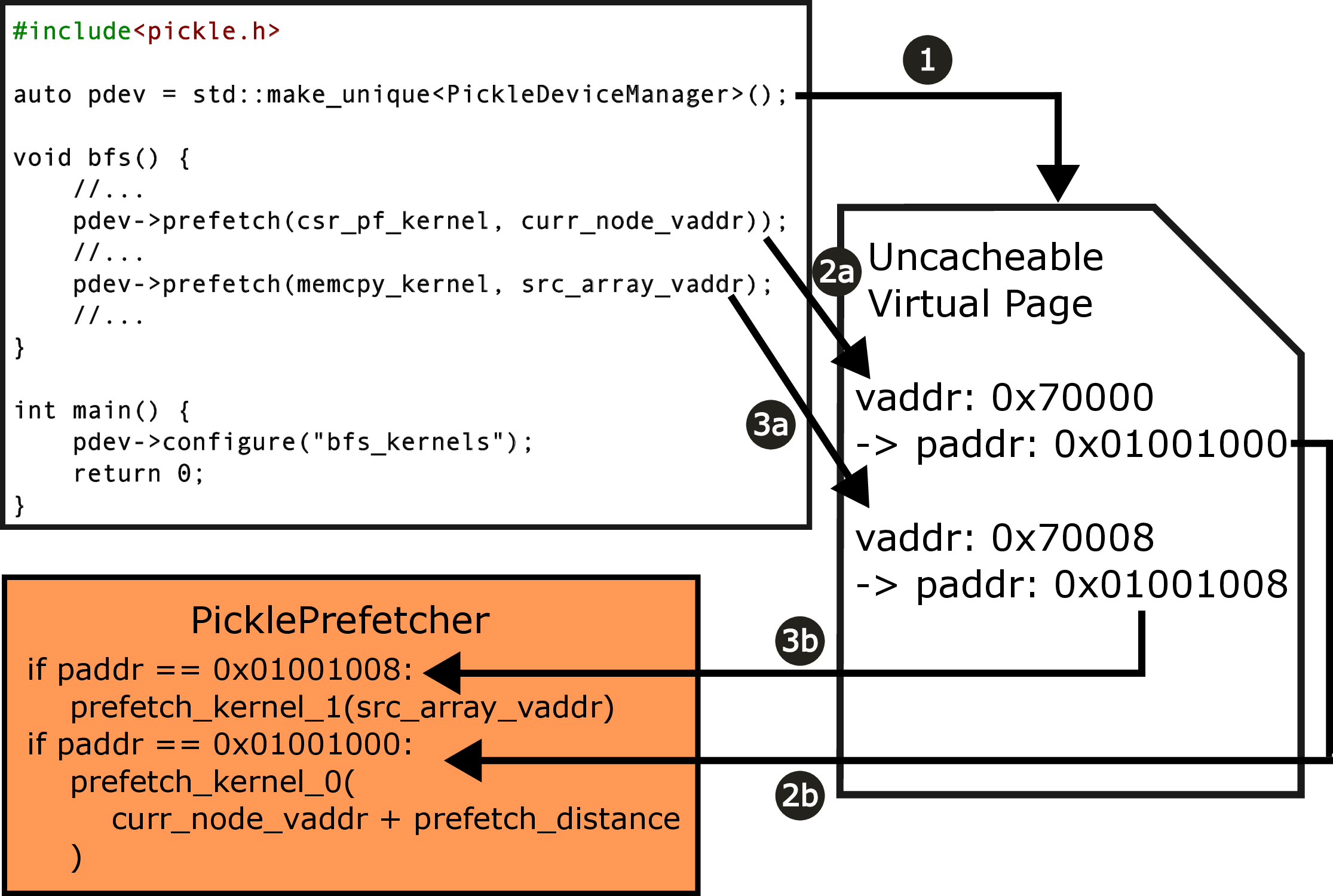
In this paper, we present the design of Pickle Prefetcher with the key idea of bringing flexibility to the prefetcher, allowing the prefetcher to adapt to different needs of different workloads. Instead of relying on complex hardware prediction logic and static heuristics, the Pickle Prefetcher uses programmable technology to let software define its own prefetching strategies, including prefetch logic and its parameters, using a simple programming interface without expanding the instruction set architecture (ISA). Pickle Prefetcher introduces the separation of concerns between prefetching logic and prefetch scheduling, fundamentally shifting the complexity of memory prefetching from memory access patterns prediction to managing the scheduling and issuing of prefetch requests. The prefetch logic is constructed entirely in software, allowing it to be easily modified and extended without requiring changes to the hardware. This approach enables finding the optimal prefetching strategy part of software development process, allowing users to iterate through different solutions quickly. We demonstrate that the Pickle Prefetcher effectively handles irregular memory access patterns, which are common in modern applications, by allowing software to define prefetching strategies that are tailored to specific workloads.
Our key contributions are as follows:
• We introduce the Pickle Prefetcher, a programmable and scalable LLC prefetcher that allows software to define prefetching strategies. • A programming interface allowing software to send prefetch requests to the Pickle Prefetcher without requiring changes to the instruction set architecture (ISA). • We evaluate the Pickle Prefetcher on modern workloads using the gem5 full-system simulator, demonstrating its effectiveness in handling irregular memory access patterns on existing systems, including systems with private cache prefetchers.
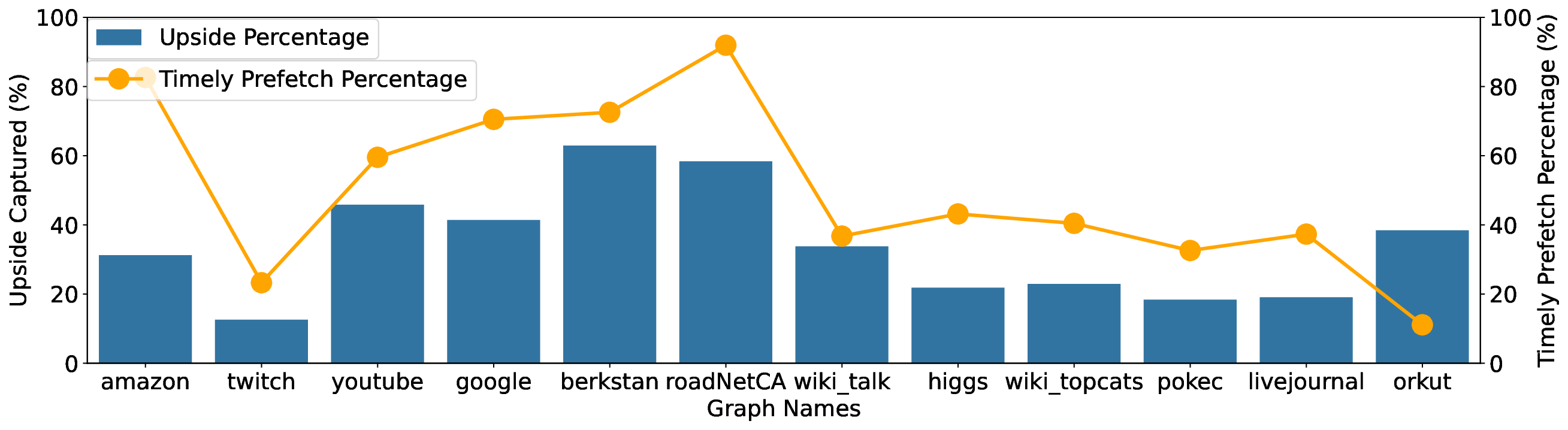
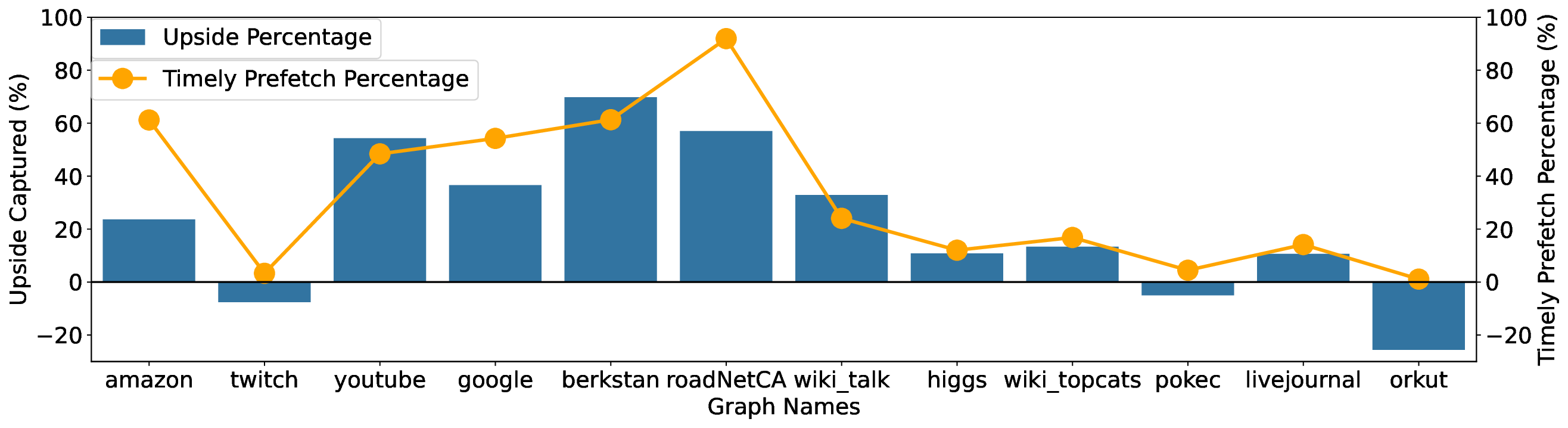
• We analyze the effect of the Pickle Prefetcher on performance, and on memory bandwidth and cache utilization.
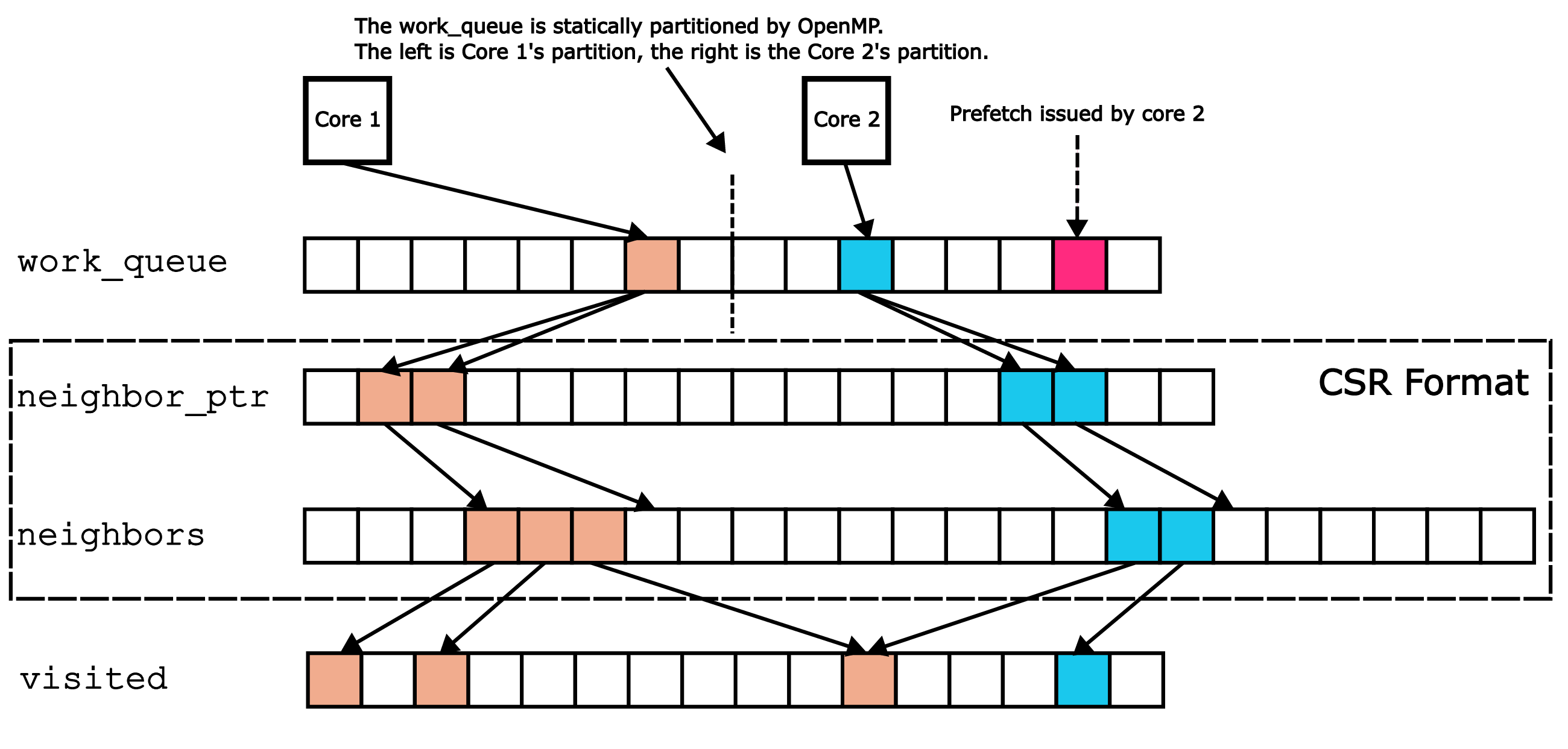
Breadth-first search (BFS) is a graph traversal algorithm that explores nodes level by level. In the CSR format, two arrays, neighbors_ptr and neighbors, store graph edges compactly. The i th entry of neighbors_ptr points to the start of node i’s neighbors in neighbors. BFS uses a work_queue for node
This content is AI-processed based on open access ArXiv data.