The rapid proliferation of Large Language Models (LLMs) has revolutionized AI-assisted code generation. This rapid development of LLMs has outpaced our ability to properly benchmark them. Prevailing benchmarks emphasize unit-test pass rates and syntactic correctness. Such metrics understate the difficulty of many real-world problems that require planning, optimization, and strategic interaction. We introduce a multi-agent reasoning-driven benchmark based on a real-world logistics optimization problem (Auction, Pickup, and Delivery Problem) that couples competitive auctions with capacity-constrained routing. The benchmark requires building agents that can (i) bid strategically under uncertainty and (ii) optimize planners that deliver tasks while maximizing profit. We evaluate 40 LLM-coded agents (by a wide range of state-of-the-art LLMs under multiple prompting methodologies, including vibe coding) against 17 human-coded agents developed before the advent of LLMs. Our results over 12 double all-play-all tournaments and $\sim 40$k matches demonstrate (i) a clear superiority of human(graduate students)-coded agents: the top 5 spots are consistently won by human-coded agents, (ii) the majority of LLM-coded agents (33 out of 40) are beaten by very simple baselines, and (iii) given the best human solution as an input and prompted to improve upon, the best performing LLM makes the solution significantly worse instead of improving it. Our results highlight a gap in LLMs' ability to produce code that works competitively in the real-world, and motivate new evaluations that emphasize reasoning-driven code synthesis in real-world scenarios.
Large Language Models (LLMs) have demonstrated an impressive ability to generate executable code, free of syntax errors [1,3,23]. Software engineers increasingly use LLMs for code generation, bug detection, code refactoring, and more [9,12,43]. 'Vibe-coding' has empowered users of all technical backgrounds to turn their ideas into code in seconds [33]. 1 As a result, there is significant interest in evaluating and improving the coding capabilities of LLMs. Recent literature has proposed a plethora of benchmarks evaluating various aspects of code generation such as functional correctness, reliability, robustness, execution time, code security, etc. [26,42,49]. Most Part of this work was conducted while P.D. was with Telenor Research. Code available at: https://panayiotisd.github.io/apdp_bench/.
You are given a positive integer array `nums'.
Return the total frequencies of elements in`nums’ such that those elements all have the maximum frequency.
Help me generate code for the following task: Remove rows with missing Product_ID, replace missing Price values with the median, forward-fill missing Quantity values, and save the cleaned dataset as cleaned_sales_data.csv. In addition, record the time you take to generate this code.
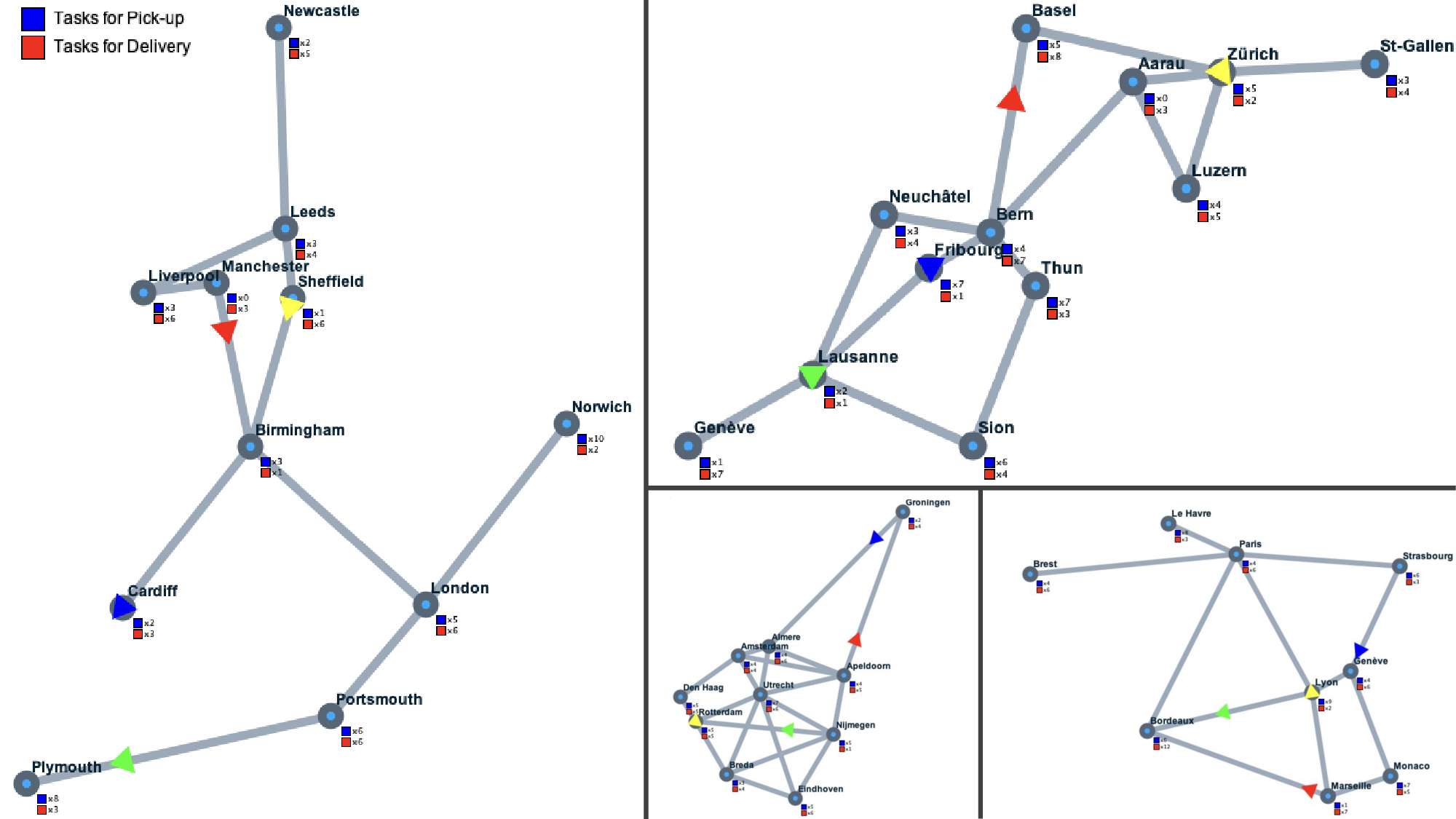
One company owns several vehicles that are used to optimally deliver a set of tasks. The company participates in a market where tasks are sold via an auction. After the auction, the company has to determine a delivery plan for each of its vehicles, given capacity constraints. Your goal is to complete the code provided below to implement an agent that maximizes the revenue of the company. The agent will participate in a tournament and compete with other agents.
Maximize your profit and win the competition! Others:
This Work (simplified):
Figure 1: Traditional benchmarks (top) focus on problems with clearly defined correct or incorrect solutions, typically verified through unit tests. In contrast, our benchmark (bottom) involves complex tasks such as planning, constraint optimization, modeling competitors, competitive strategy design, and advanced algorithm development -challenges that remain highly non-trivial even for experienced software engineers. Top from [27] (left) and [26] (right).
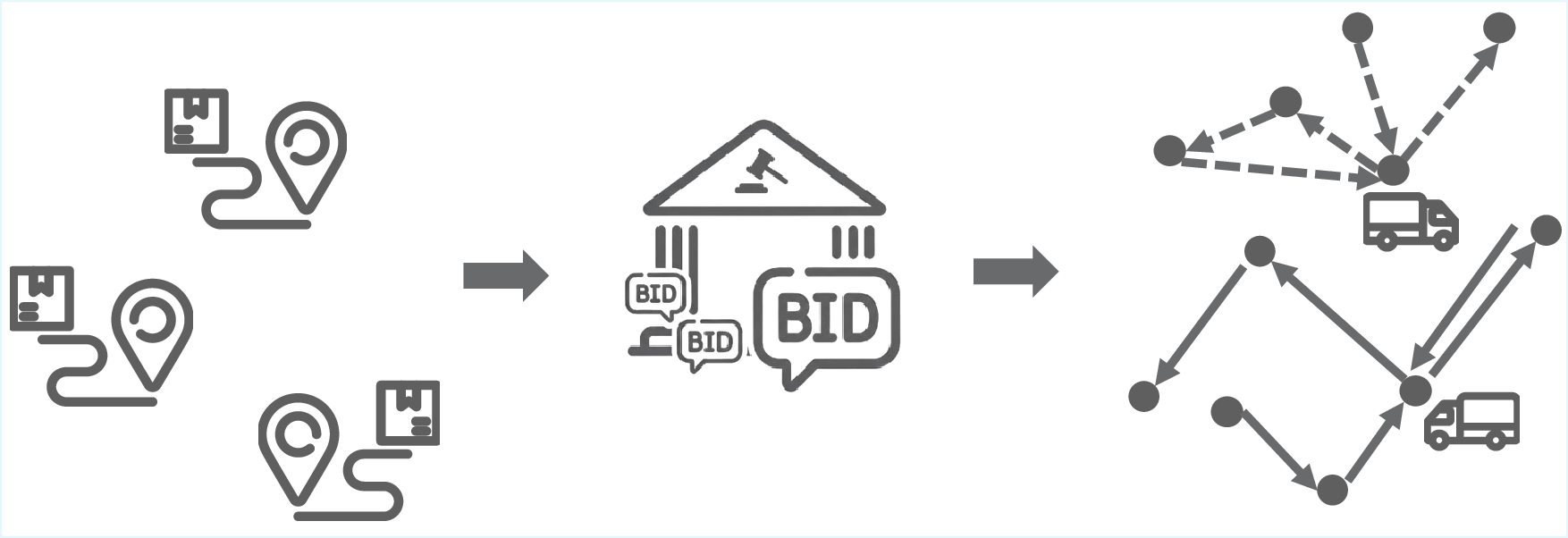
existing benchmarks are composed of problems whose solutions can be easily verified by running unit tests (e.g., see examples in Figure 1 (top)). Achieving state-of-art performance on these benchmarks is indeed an impressive milestone for AI. Yet, if we look beyond autocomplete, real-world software development is far more complex. We argue that it is time to expand the frontier in code generation even further by asking: Does high performance on existing coding benchmarks translate to the ability to solve real-world coding problems, ones requiring multi-agent strategic interaction, planning, optimization, and advanced algorithm design that can be highly non-trivial even for experienced human software engineers? We introduce a real-world optimization benchmark for LLM code generation. The proposed benchmark requires LLMs to complete code that optimizes the operations of a logistics company, specifically the pickup and delivery of parcels (see Figure 2), with the ultimate goal of maximizing profit. The LLMs need to implement an agent that competes against other agents, optimally bids for tasks (tasks are assigned via a reverse first-price sealed-bid auction), and optimally plans for the pickup and delivery of the won tasks. As such, the problem incorporates challenges from the domains of multi-agent systems (MAS), auctions, and constraint optimization.
Devising a suitable benchmark is one part of the research challenge addressed in this work; the second relates to evaluation metrics. The Auction, Pickup, and Delivery Problem (APDP) is an open ended problem, one that does not admit a closed-form solution (due to real-time constraints for bidding and planning, bounded rationality, etc.). Thus, pass/fail designations of the generated code are not feasible, nor can we estimate how close we are to the optimal solution. Instead, we compare against a wide range of human-coded agents, developed before the advent of LLMs (i.e., without any AIassisted programming). The APDP was given as an assignment in the postgraduate Intelligent Agents course at EPFL. Students had two to three weeks to develop an agent, which then competed in a single-elimination tournament for extra course credits. We selected 12 student agents from the class of 2020 and 5 baseline agents developed by members of the Artificial Intelligence Laboratory at EPFL.
Our work demonstrates that while state-of-the-art LLMs can generate code that runs (i.e., free of syntax errors), the generated solution is not competitive to human-designed solutions on dimensions such as strategic planning, optimization, or multi-agent competition. Thus, this work brings to the forefront this new frontier in code generation, and aims to facilitate the development
This content is AI-processed based on open access ArXiv data.