Directional Optimization Asymmetry in Transformers: A Synthetic Stress Test
Reading time: 5 minute
...
📝 Original Info
Title: Directional Optimization Asymmetry in Transformers: A Synthetic Stress Test
ArXiv ID: 2511.19997
Date: 2025-11-25
Authors: Mihir Sahasrabudhe
📝 Abstract
Transformers are theoretically reversal-invariant: their function class does not prefer left-to-right over right-to-left mappings. Yet empirical studies on natural language repeatedly report a "reversal curse," and recent work on temporal asymmetry in LLMs suggests that real-world corpora carry their own arrow of time. This leaves an unresolved question: do directional failures stem from linguistic statistics, or from the architecture itself? We cut through this ambiguity with a fully synthetic, entropy-controlled benchmark designed as a clean-room stress test for directional learning. Using random string mappings with tunable branching factor K, we construct forward tasks with zero conditional entropy and inverse tasks with analytically determined entropy floors. Excess loss above these floors reveals that even scratch-trained GPT-2 models exhibit a strong, reproducible directional optimization gap (e.g., 1.16 nats at K=5), far larger than that of an MLP trained on the same data. Pre-trained initializations shift optimization behavior but do not eliminate this gap, while LoRA encounters a sharp capacity wall on high-entropy inverse mappings. Together, these results isolate a minimal, semantics-free signature of directional friction intrinsic to causal Transformer training-one that persists even when linguistic priors, token frequencies, and corpus-level temporal asymmetries are removed. Our benchmark provides a controlled instrument for dissecting directional biases in modern sequence models and motivates deeper mechanistic study of why inversion remains fundamentally harder for Transformers.
💡 Deep Analysis
📄 Full Content
While Transformer-based Large Language Models (LLMs) excel at sequence modeling, they exhibit a fundamental directional asymmetry. Recent studies report that models trained on causal statements (A → B) often fail to infer the diagnostic inverse (B → A), a phenomenon termed the "reversal curse" [Berglund et al., 2024]. This raises a critical question: is this asymmetry an artifact of the training data, or an intrinsic inductive bias of the architecture itself?
Current analyses relying on natural language (e.g., “A is the parent of B”) are inherently confounded by three factors:
Semantic Priors: Causal relationships often appear more frequently than diagnostic ones in training corpora. 2. Linguistic Structure: Syntax and grammar impose directional dependencies (e.g., Subject-Verb-Object) that favor forward prediction. 3. Token Statistics: Entity frequencies and co-occurrence statistics are rarely symmetric. Consequently, it is difficult to disentangle whether the Reversal Curse arises from data distribution or from the autoregressive factorization mechanism.
The Arrow of Complexity. This directional puzzle is further complicated by inherent differences in computational complexity. As noted in recent work on the “Arrows of Time” in language models [Papadopoulos et al., 2024], forward generation often resembles a deterministic collapse of state space (analogous to multiplication), whereas inverse inference requires expanding state space to recover multiple potential inputs (analogous to factorization). In natural language, these entropic differences are inextricably linked to semantics. To isolate the architectural contribution to the Reversal Curse, we require a setting where this forward-inverse complexity asymmetry is explicitly tunable.
Goal: A Synthetic “Clean Room”. We introduce a controlled benchmark to measure directional training efficiency in the absence of linguistic or statistical confounds. We construct a dataset of random string mappings where the topology is strictly controlled by a branching factor K.
• Backward (B → A): Probabilistic one-to-many mapping (H = ln K), mimicking high-entropy inverse problems. This design creates a mathematically precise analogue of the complexity asymmetry described in prior work, stripped of all semantic priors.
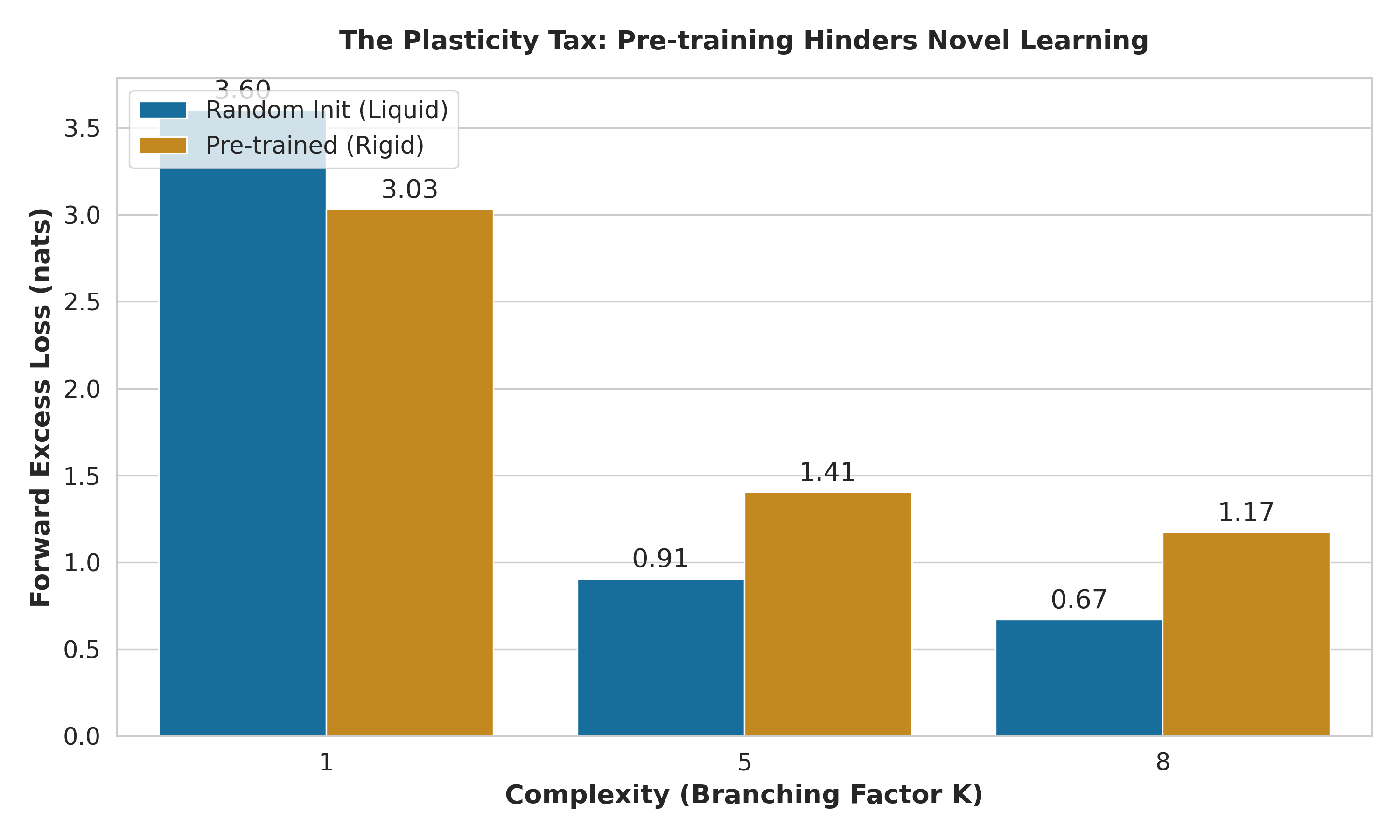
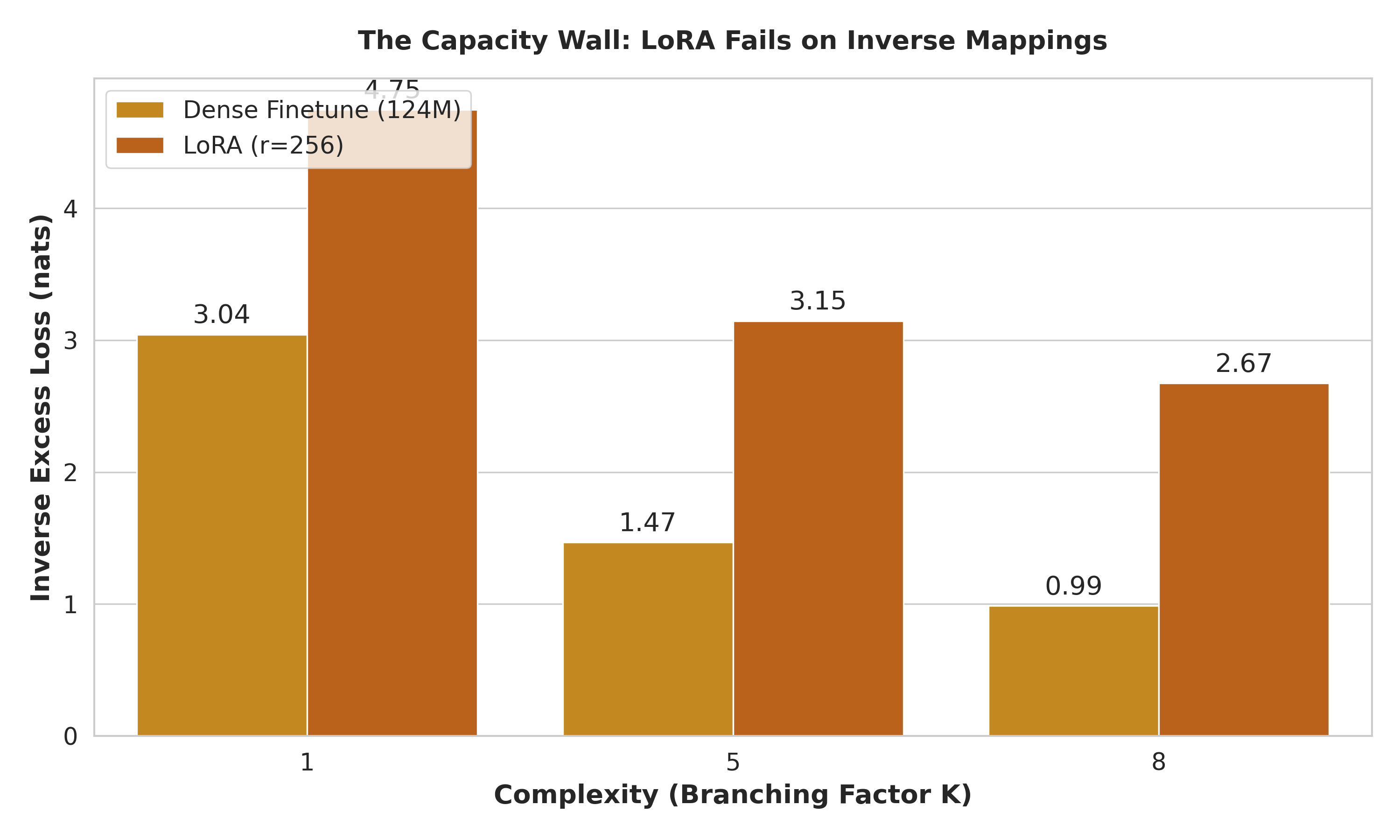
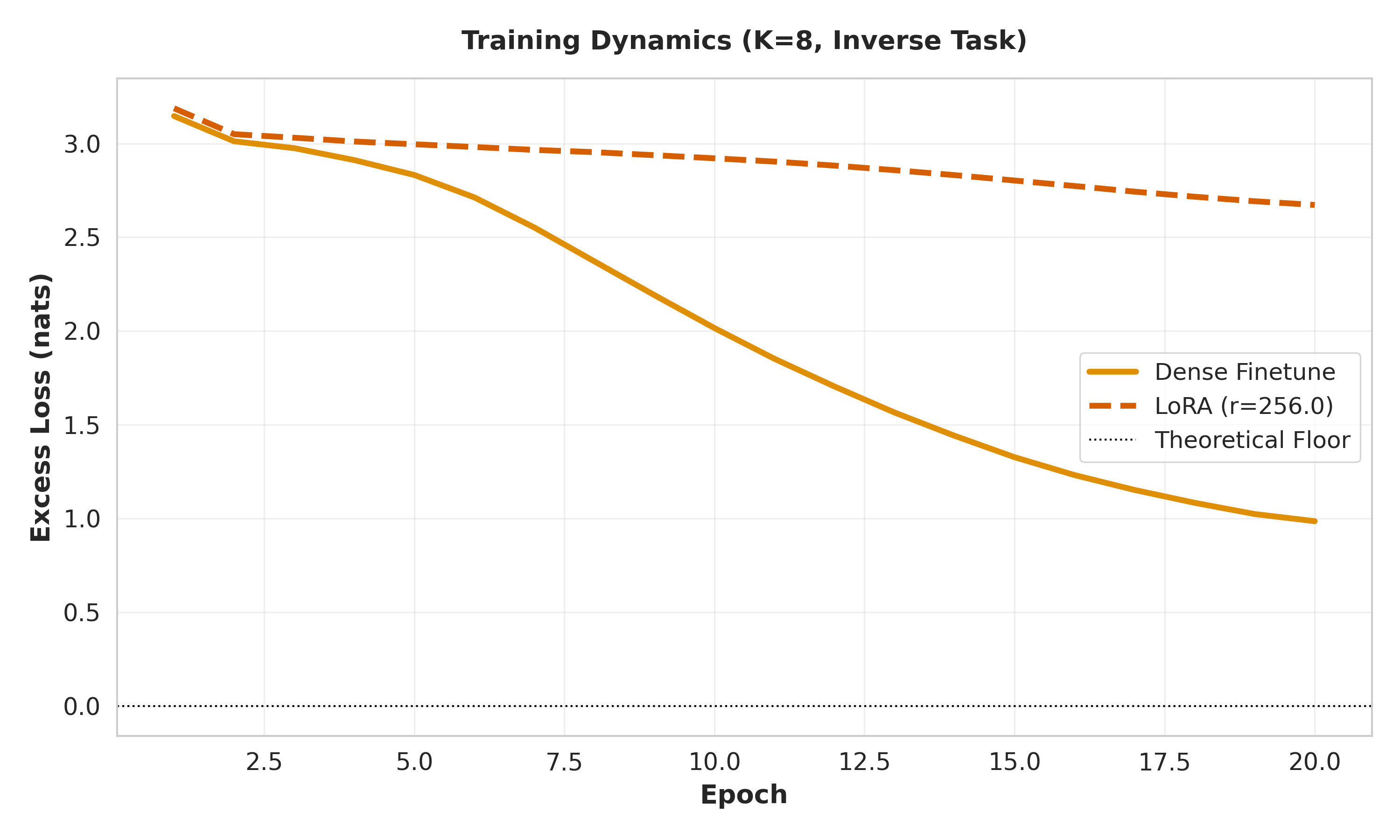
Approach. Within this framework, we benchmark the optimization dynamics of Causal Transformers (trained from scratch and pre-trained) against non-causal Multilayer Perceptrons (MLPs) and Low-Rank Adaptation (LoRA) methods [Hu et al., 2021]. Crucially, because the informationtheoretic floor of each task is known exactly, we report Excess Loss-the divergence of the model from the theoretical minimum. This metric allows us to rigorously decouple the inherent thermodynamic difficulty of the inverse task from the structural inefficiencies of the architecture. Code can be found at: https://github.com/mihirs-0/synass
2 A Synthetic “Clean Room” for Directional Analysis
To measure directional training behavior in the absence of linguistic or corpus-level confounds, we construct a minimal, fully synthetic environment. In this setting, both the data topology and the information-theoretic difficulty of the forward and inverse tasks are exactly known. This “Clean Room” isolates architectural and optimization effects from the semantic and statistical artifacts inherent to natural language.
We define a uniform alphabet Σ = {a–z, 0–9} of size |Σ| = 36. We sample fixed-length strings from Σ L (with L = 8), drawn i.i.d. from a uniform distribution. By design, no token, substring, or structural pattern appears with higher-than-random frequency.
We construct mappings using a controlled branching factor K:
• For each unique target B i , we sample K distinct inputs {A i,1 , . . . , A i,K }.
• Uniqueness constraint: Each A i,j appears exactly once globally.
• Support constraint: Each B i appears exactly K times. This construction yields two distinct tasks:
Inverse (B → A): Probabilistic. The mapping B i → {A i,j } is one-to-many. The optimal policy is a uniform distribution over the K pre-images, yielding an entropy floor H(A | B) = log K.
A common concern with many-to-one synthetic datasets is that target duplication (B i ) might induce a hidden directional bias. Our construction avoids this for three reasons: 1. Unique Forward Inputs. Every A i,j is sampled uniquely. There are no statistical shortcuts or frequency artifacts that privilege the forward direction. 2. Necessary Inverse Support. The repetition of B i is mathematically required to define the inverse conditional distribution. Without observing all pairs (B i , A i,j ), the model cannot learn the full support of the inverse mapping. 3. Empirical Symmetry at K=1. In our scratch baseline (see Section 5), Transformers trained on the bijective case K=1 exhibit matched forward and reverse convergence after accounti