AttackPilot: Autonomous Inference Attacks Against ML Services With LLM-Based Agents
Reading time: 5 minute
...
📝 Original Info
Title: AttackPilot: Autonomous Inference Attacks Against ML Services With LLM-Based Agents
ArXiv ID: 2511.19536
Date: 2025-11-24
Authors: Yixin Wu, Rui Wen, Chi Cui, Michael Backes, Yang Zhang
📝 Abstract
Inference attacks have been widely studied and offer a systematic risk assessment of ML services; however, their implementation and the attack parameters for optimal estimation are challenging for non-experts. The emergence of advanced large language models presents a promising yet largely unexplored opportunity to develop autonomous agents as inference attack experts, helping address this challenge. In this paper, we propose AttackPilot, an autonomous agent capable of independently conducting inference attacks without human intervention. We evaluate it on 20 target services. The evaluation shows that our agent, using GPT-4o, achieves a 100.0% task completion rate and near-expert attack performance, with an average token cost of only $0.627 per run. The agent can also be powered by many other representative LLMs and can adaptively optimize its strategy under service constraints. We further perform trace analysis, demonstrating that design choices, such as a multi-agent framework and task-specific action spaces, effectively mitigate errors such as bad plans, inability to follow instructions, task context loss, and hallucinations. We anticipate that such agents could empower non-expert ML service providers, auditors, or regulators to systematically assess the risks of ML services without requiring deep domain expertise.
💡 Deep Analysis
📄 Full Content
AttackPilot: Autonomous Inference Attacks Against ML Services With
LLM-Based Agents
Yixin Wu1 Rui Wen2 Chi Cui1 Michael Backes1 Yang Zhang1
1CISPA Helmholtz Center for Information Security
2Institute of Science Tokyo
Abstract
Inference attacks have been widely studied and offer a sys-
tematic risk assessment of ML services; however, their im-
plementation and the attack parameters for optimal esti-
mation are challenging for non-experts.
The emergence
of advanced large language models presents a promising
yet largely unexplored opportunity to develop autonomous
agents as inference attack experts, helping address this chal-
lenge.
In this paper, we propose AttackPilot, an au-
tonomous agent capable of independently conducting infer-
ence attacks without human intervention. We evaluate it on
20 target services. The evaluation shows that our agent, using
GPT-4o, achieves a 100.0% task completion rate and near-
expert attack performance, with an average token cost of only
$0.627 per run. The agent can also be powered by many other
representative LLMs and can adaptively optimize its strategy
under service constraints. We further perform trace analy-
sis, demonstrating that design choices, such as a multi-agent
framework and task-specific action spaces, effectively miti-
gate errors such as bad plans, inability to follow instructions,
task context loss, and hallucinations. We anticipate that such
agents could empower non-expert ML service providers, au-
ditors, or regulators to systematically assess the risks of ML
services without requiring deep domain expertise.
1
Introduction
The deployment of ML models in security-sensitive do-
mains calls for a comprehensive understanding of potential
risks during the inference phase.
Inference attacks (IA),
such as membership inference [41, 42, 45] and model steal-
ing [6,20,46], are pivotal for assessing a model’s robustness
by highlighting vulnerabilities that could lead to sensitive in-
formation leakage. These vulnerabilities not only threaten
privacy but also jeopardize the model owner’s intellectual
property [12]. Hence, ML service providers, third-party au-
ditors, and even regulators are increasingly expected to as-
sess the security and privacy risks of ML services. Despite
their importance, conducting risk assessment via inference
attacks remains challenging, as it requires detailed analysis,
such as selecting the most appropriate shadow datasets.
This complexity presents significant hurdles for those
without specialized expertise and demands considerable ef-
fort even from experienced practitioners. Recent progress
in large language models (LLM) has introduced autonomous
agents to automate complex tasks across various domains,
such as web interactions [49, 58], data analysis [5, 24], and
ML experimentation [19].
These agents have shown re-
markable potential to reduce manual labor and improve ef-
ficiency [19, 27, 32]. However, our evaluation later demon-
strates that current agent frameworks lack effectiveness in
conducting risk assessment (see Section 4.1).
To fill this gap, we propose AttackPilot, an autonomous
agent tailored to automate the risk assessment of vari-
ous inference attacks. Specifically, we focus on member-
ship inference [35, 41, 42, 45], model stealing [6, 20, 46],
data reconstruction [15, 53, 55], and attribute inference at-
tacks [34,43,44]. We present the details of each attack in Ap-
pendix C. The proposed agent acts as an independent ex-
pert in conducting risk assessments, dynamically adapting
its behavior based on the basic information of the given tar-
get service and real-time execution feedback. In this way,
it empowers non-experts to systematically assess the risks
of ML services with minimal input and without requiring
domain expertise.
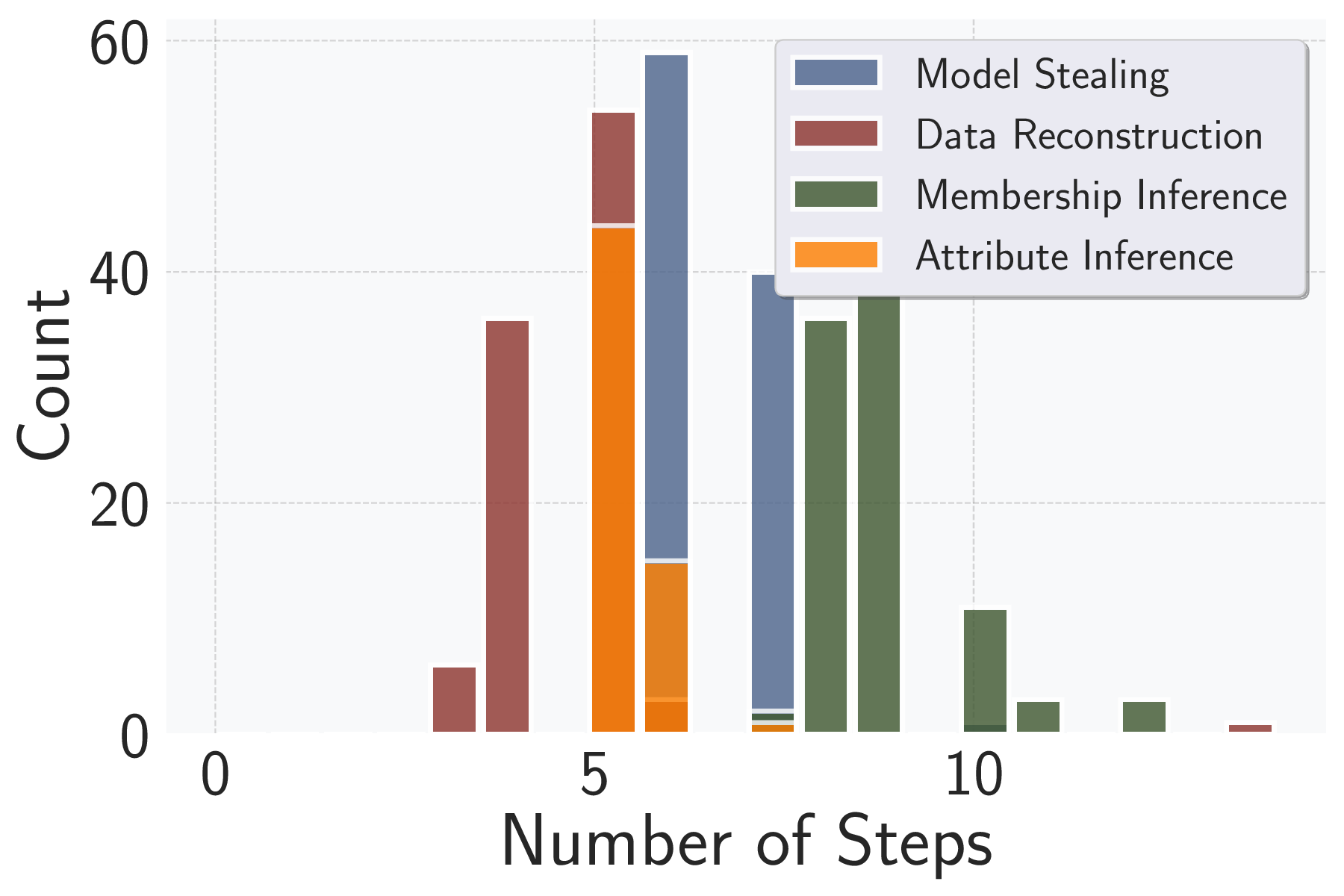
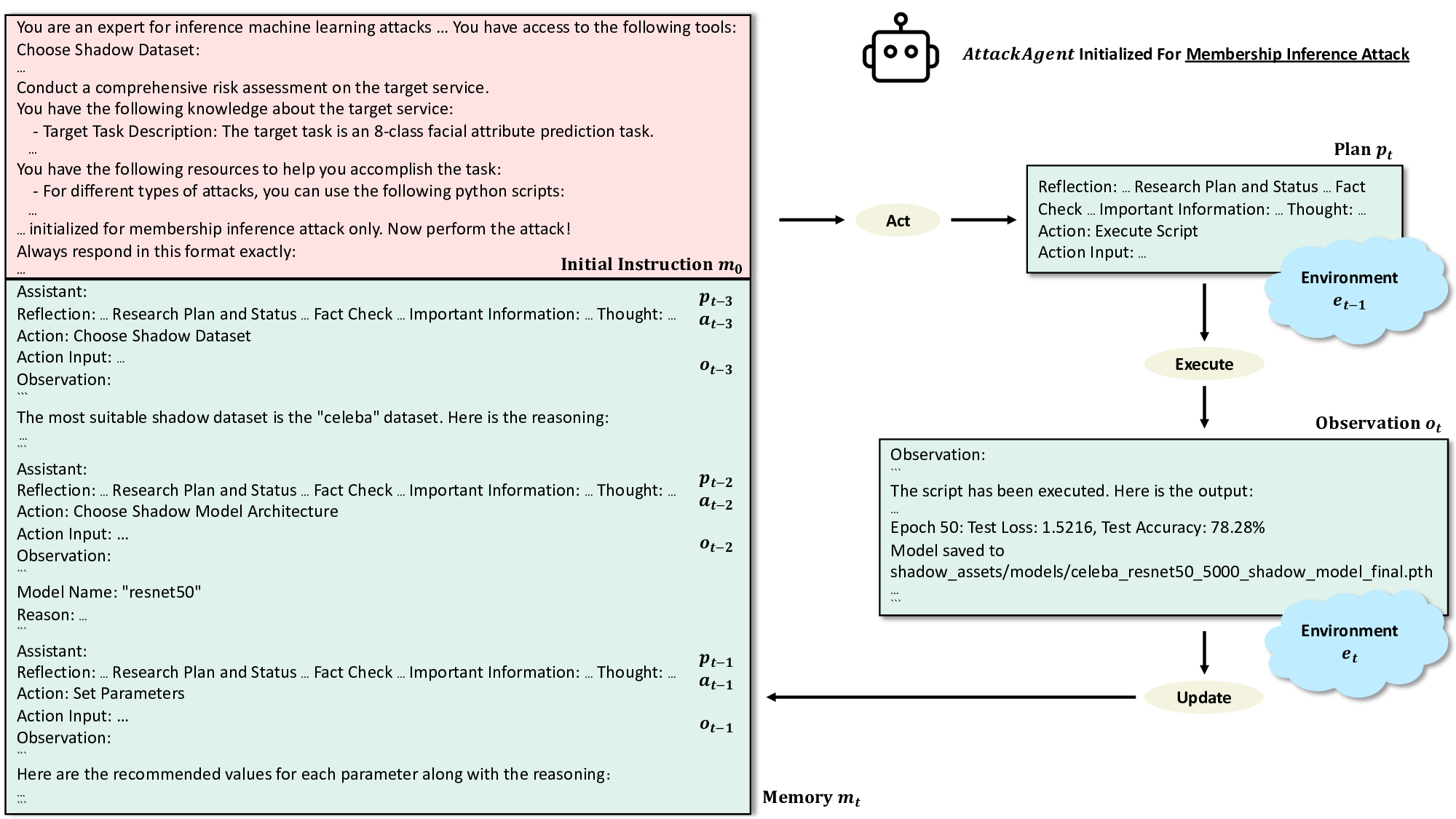
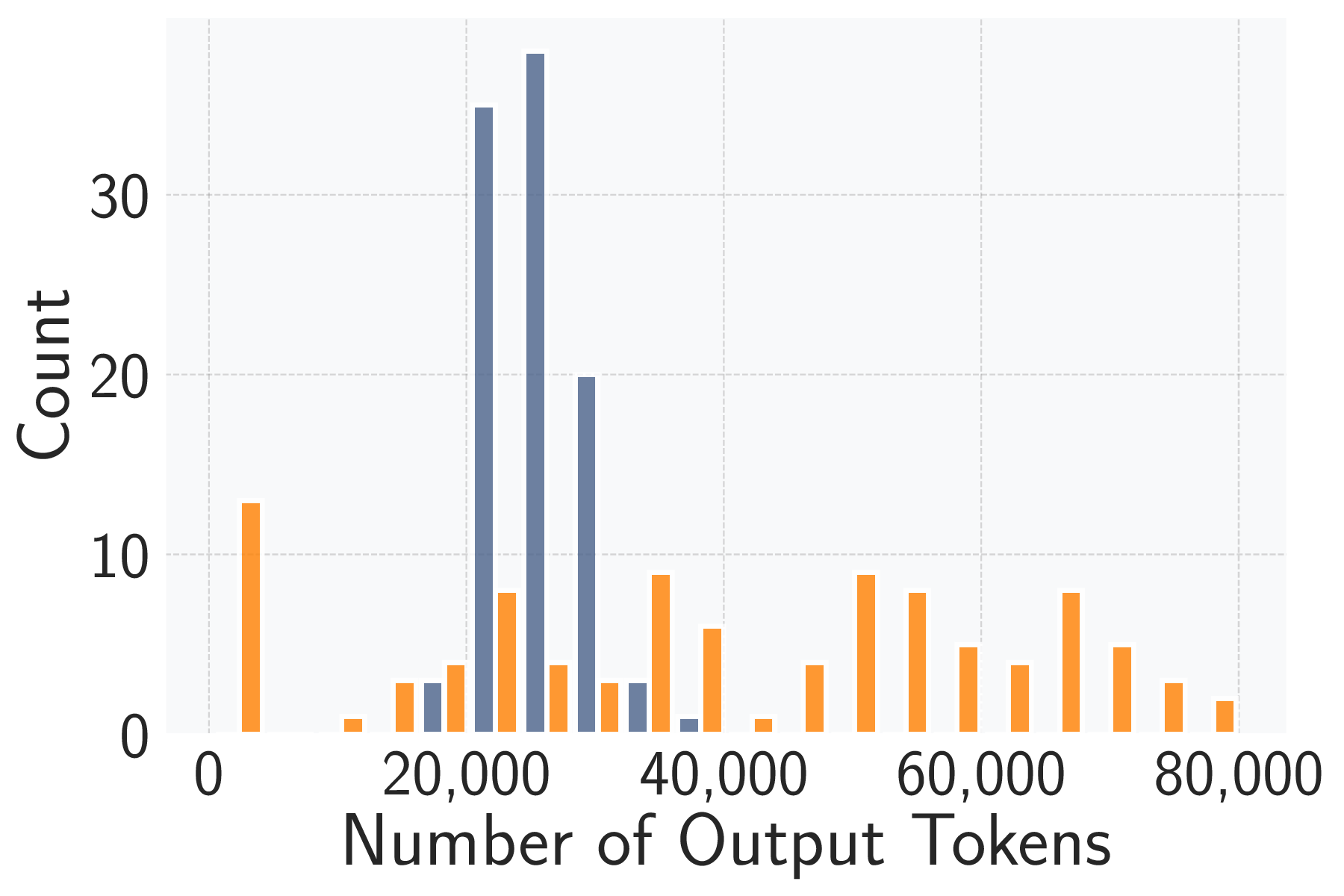
As shown in Figure 1, AttackPilot
comprises ControllerAgent, which manages attacks, and
AttackAgent, which executes them. We further manually
identify all critical steps in the assessment process and en-
capsulate each as a separate action with detailed guidelines to
construct task-specific action spaces for the two agents. The
environment is equipped with reusable resources, including
Linux shells, starter scripts with implementations for differ-
ent inference attacks, and datasets and models available.
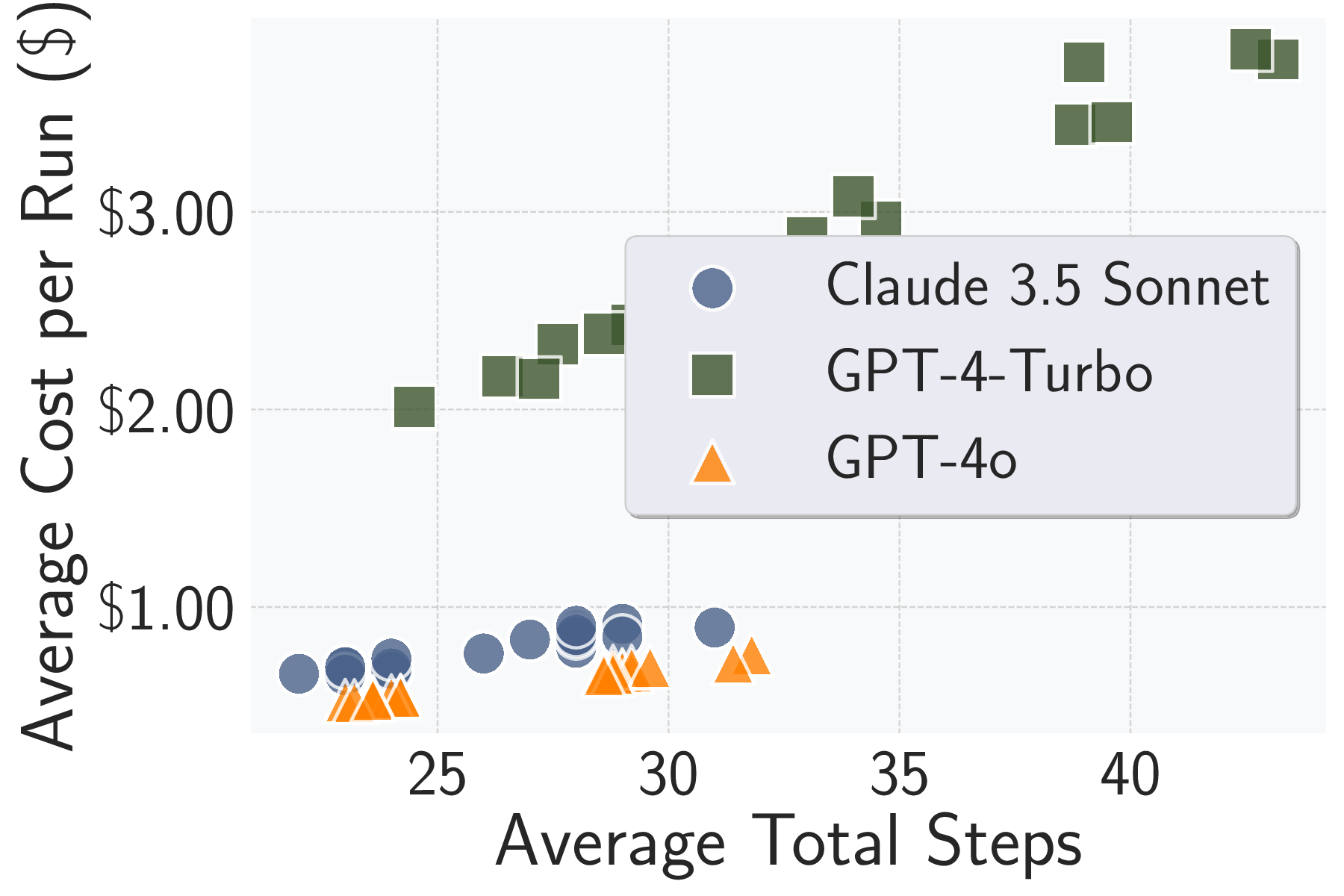
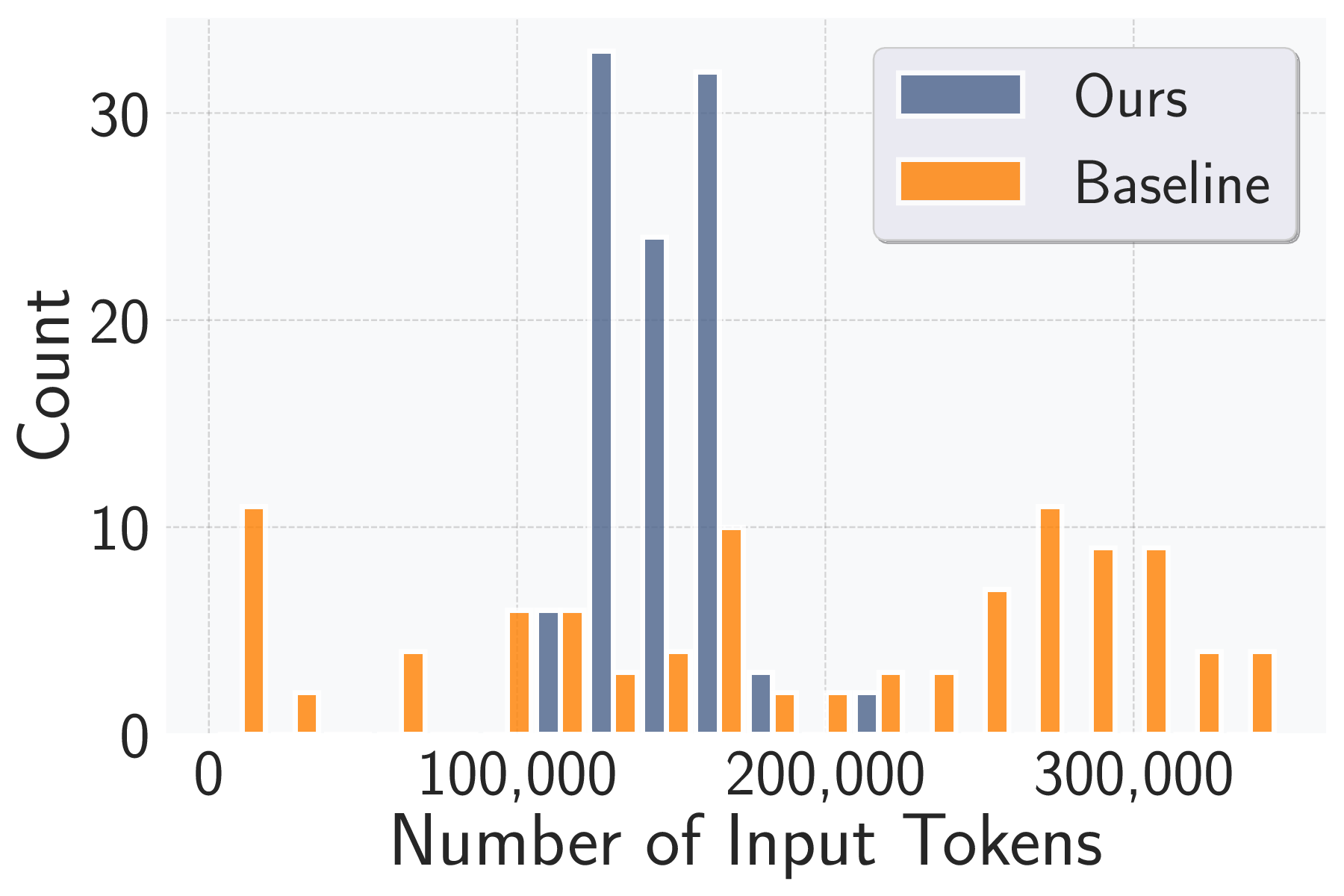
We evaluate AttackPilot on 20 target services.
Our
agent with GPT-4o achieves a 100.0% task completion rate,
defined as the percentage of five runs in which all possi-
ble attacks are successfully executed. For comparison, the
state-of-the-art MLAgentBench [19], originally designed for
ML experimentation but adaptable for risk assessment in the
same environment, achieves only a 26.3% completion rate.
We further compare it with a human expert. They use ML-
Doctor [29], an assessment framework, to conduct inference
attacks. We observe that AttackPilot achieves near-expert
performance. The average attack accuracy of AttackPilot
in conducting membership inference is only 1.0% lower than
that of a human