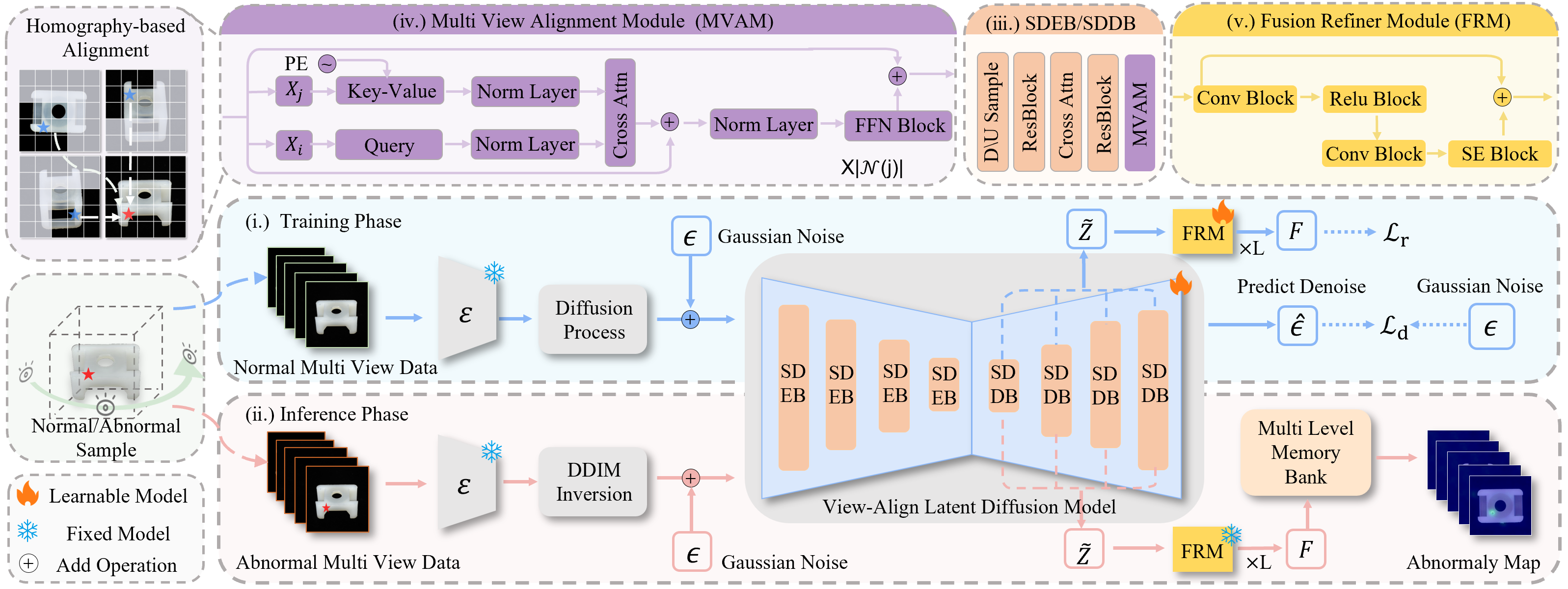
Unsupervised visual anomaly detection from multi-view images presents a significant challenge: distinguishing genuine defects from benign appearance variations caused by viewpoint changes. Existing methods, often designed for single-view inputs, treat multiple views as a disconnected set of images, leading to inconsistent feature representations and a high false-positive rate. To address this, we introduce ViewSense-AD (VSAD), a novel framework that learns viewpoint-invariant representations by explicitly modeling geometric consistency across views. At its core is our Multi-View Alignment Module (MVAM), which leverages homography to project and align corresponding feature regions between neighboring views. We integrate MVAM into a View-Align Latent Diffusion Model (VALDM), enabling progressive and multi-stage alignment during the denoising process. This allows the model to build a coherent and holistic understanding of the object's surface from coarse to fine scales. Furthermore, a lightweight Fusion Refiner Module (FRM) enhances the global consistency of the aligned features, suppressing noise and improving discriminative power. Anomaly detection is performed by comparing multi-level features from the diffusion model against a learned memory bank of normal prototypes. Extensive experiments on the challenging RealIAD and MANTA datasets demonstrate that VSAD sets a new state-of-the-art, significantly outperforming existing methods in pixel, view, and sample-level visual anomaly proving its robustness to large viewpoint shifts and complex textures.
Industrial anomaly detection is a critical task in modern manufacturing, where even minuscule defects can compromise product quality, lead to costly recalls and pose safety risks (Cao et al. 2024). While most unsupervised anomaly detection methods rely on single-view imagery, complex 3D objects often feature occlusions or intricate geometries that a single viewpoint cannot fully capture. Consequently, multiview imaging systems, which capture an object from several fixed perspectives, have become a practical and effective solution for ensuring comprehensive surface inspection.
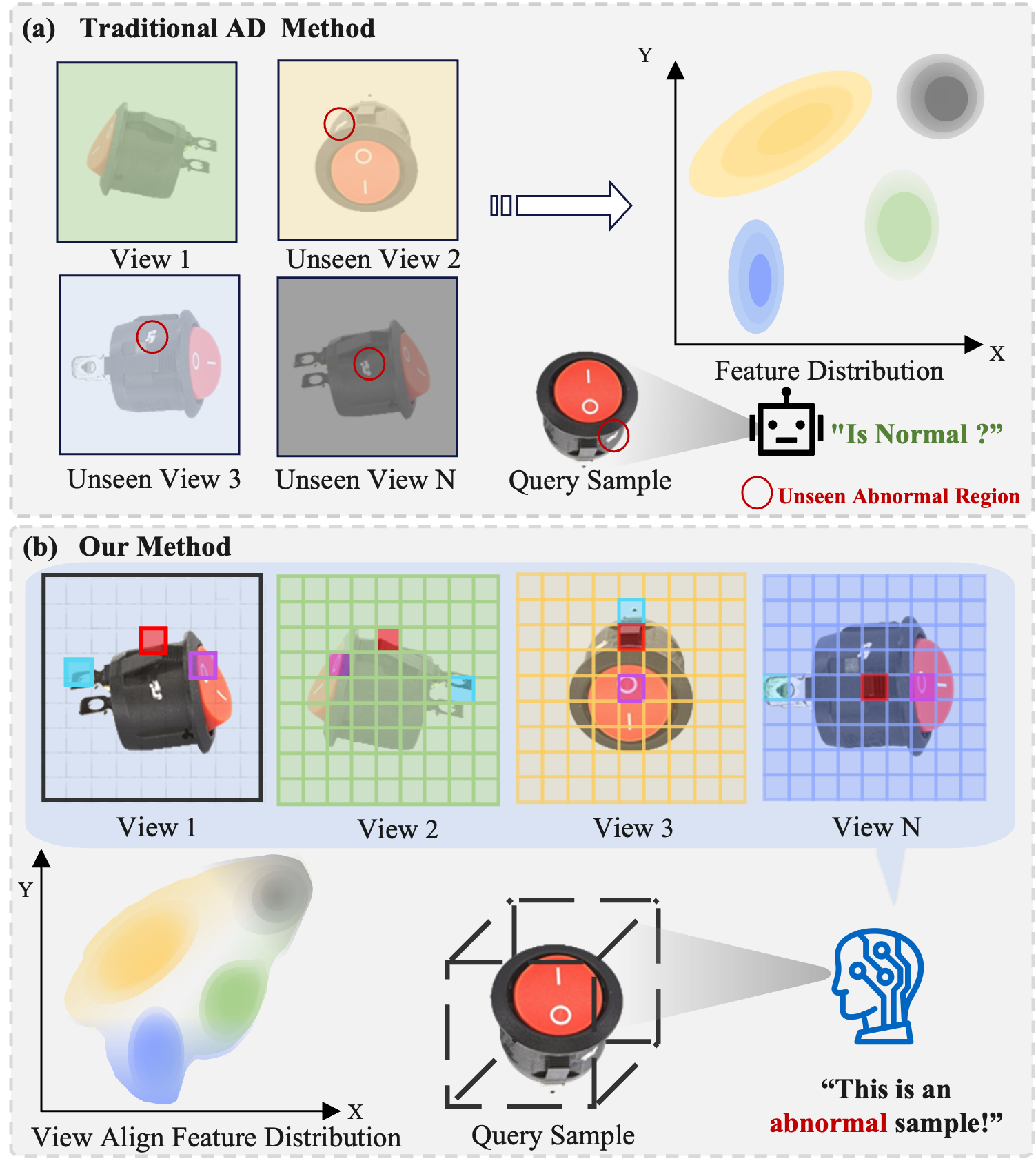
Figure 1: (a) Conventional methods process views independently, yielding discrete and inconsistent features that struggle to differentiate viewpoint changes from true defects. (b) Our method (VSAD) employs homography-based alignment to establish correspondences between views, learning a continuous and consistent representation that enables robust anomaly detection.
However, transitioning from single-view to multi-view settings introduces a fundamental challenge: distinguishing true anomalies from appearance shifts induced purely by changes in viewpoint (Fig. 1a). Existing unsupervised methods, whether reconstruction-based (e.g., DRAEM (Zavrtanik, Kristan, and Skočaj 2021)) or embedding-based (e.g., PatchCore (Roth et al. 2022)), typically process each view independently. This ‘bag-of-views’ approach ignores the underlying geometric relationships between images, resulting in feature representations that are fragmented and unaligned. As a result, these models are prone to misinterpreting normal geometric variations as anomalies, leading to poor performance and reliability in real-world scenarios.
To overcome these limitations, we propose ViewSense-AD (VSAD), an unsupervised framework designed to learn continuous and consistent cross-view representations (Fig. 1b). Our work is inspired by how human inspectors naturally operate: they mentally align different views of an object to build a holistic understanding of its surface, effortlessly distinguishing surface texture from geometric perspective shifts. VSAD mimics this reasoning process through a synergistic design. First, to determine where to look for corresponding information, we introduce a Multi-View Alignment Module (MVAM). It uses homographybased projection to explicitly match related feature patches across adjacent views. Second, to learn how to integrate this aligned information, the MVAM is embedded within a View-Align Latent Diffusion Model (VALDM). By performing alignment progressively during the denoising process, VALDM constructs a viewpoint-invariant representation. Finally, to refine the holistic alignment representation, a lightweight Fusion Refiner Module (FRM) explicitly models cross-view consistency to suppress noise and sharpen the distinction between normal and anomalous patterns.
During inference, we extract multi-level features from the DDIM inversion process and compare them against a memory bank of normal prototypes for fine-grained, multi-scale anomaly localization. Our extensive experiments on the Re-alIAD and MANTA datasets show that VSAD consistently outperforms state-of-the-art baselines across all evaluation levels. These results validate that by explicitly modeling geometric consistency, our framework effectively bridges the gap between fragmented image-level processing and holistic, human-like perception in multi-view anomaly detection.
Our contributions are summarized as follows:
• We propose VSAD, a novel unsupervised multi-view anomaly detection framework that learns continuous and consistent cross-view representations through homography-guided alignment. 2 Related Work
Unsupervised anomaly detection methods learn from anomaly-free data and are categorized as reconstructionbased or embedding-based. Reconstruction-based methods (Fan et al. 2025b), like autoencoders (Bergmann et al. 2019), VAE (Kingma, Welling et al. 2013) and GANs (Schlegl et al. 2017), identify anomalies as regions with high reconstruction error. More recent works have improved reconstruction fidelity using memory modules (Gong et al. 2019;Cai et al. 2021), pseudo-anomaly augmentation (Zavrtanik, Kristan, and Skočaj 2021;Hu et al. 2024;Sun et al. 2025), and diffusion models (Zavrtanik, Kristan, and Skočaj 2023;Kim et al. 2024;Yao et al. 2025). However, when applied to multi-view data, they typically reconstruct each view in isolation, failing to enforce cross-view consistency.
Embedding-based methods leverage powerful features from models pre-trained on large datasets like ImageNet (Deng et al. 2009). They model the distribution of normal features using memory banks (Roth et al. 2022;Bae, Lee, and Kim 2023;Liu et al. 2025), normalizing flows (Gudovskiy, Ishizaka, and Kozuka 2022;Yao et al. 2024), or student-teacher networks (Bergmann et al. 2020;Liu et al. 2024;Wang et al. 2025a). While highly effective for singleview tasks, these methods inherently lack a mechanism to account
This content is AI-processed based on open access ArXiv data.